三个月吃透腾讯T4推荐247页深度实践Spark机器学习pdf终入腾讯云
Posted javatiange
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了三个月吃透腾讯T4推荐247页深度实践Spark机器学习pdf终入腾讯云相关的知识,希望对你有一定的参考价值。
前言
大家先来看看入职腾讯云的要求:
岗位职责:
负责腾讯云公有云数据平台的建设
岗位要求:
1、统招本科及以上学历,计算机相关专业,3年及以上相关工作经验,有扎实的计算机理论基础;
2、精通Java程序开发,熟悉Linux/Unix开发环境;
3、对分布式系统以及资源竞争场景有实践经验,具有高扩展性、高性能和分布式系统的实践经验;
4、深入理解和熟练使用Hadoop生态,并有源码阅读经验的优先;
5.深入理解Spark机器学习,具有大数据平台开发和使用经验优先;
6、具有数据分析经验优先。

怎么样?是不是有一个简单的了解了?知道自己需要补充什么知识了么?
但是,本文最主要介绍的还是第五块内容,深度实践Spark机器学习,因为内容有点多,所以只把部分知识点拿出来粗略的介绍了一下,每个小节都有更加细化的内容,大家要耐心的品读,理解其中的真谛,希望能够帮助到大家!!!
目录
主要内容
本文系统讲解了Spark机器学习的技术、原理、组件、算法,以及构建Spark机器学习系统的方法、流程、标准和规范。此外,还介绍了Spark的深度学习框架TensorFlowOnSpark,以及如何借助它实现卷积神经网络和循环神经网络。
全文总共分为4个部分,14章的内容:
第一部分(第1~7章)
主要讲解了Spark机器学习的技术、原理和核心组件,包括Spark ML、Spark ML Pipeline、 Spark ML lib,,以及如何构建一个Spark机器学 习系统。
第1章了解机器学习
大数据、人工智能是目前大家谈论比较多的话题,它们的应用也越来越广泛,与我们的生活关系也越来越密切,影响也越来越深远,其中很多已进入寻常百姓家,如无人机、网约车、自动导航、智能家电、电商推荐、人机对话机器人等。
大数据是人工智能的基础,而使大数据转变为知识或生产力,离不开机器学习(Machine Learning),可以说机器学习是人工智能的核心,是使机器具有类似人的智能的根本途径。
本章主要介绍与机器学习有关的概念,机器学习与大数据、人工智能间的关系,机器学习常用架构及算法等,具体如下:
- 机器学习的定义
- 大数据与机器学习
- 机器学习与人工智能、深度学习
- 机器学习的基本任务
- 如何选择合适算法
- Spark在机器学习方面的优势
第2章,构建Spark机器学习系统
构建机器学习系统的方法,根据业务需求和使用工具的不同,可能会有些区别,不过主要流程差别不大,基本包括数据抽取、数据探索、数据处理、建立模型、训练模型、评估模型、优化模型、部署模型等阶段。在构建系统前,我们需要考虑系统的扩展性,与其他系统的整合,系统升级及处理方式等。本章我们主要介绍基于Spark机器学习的架构设计或系统构建的一般步骤,以及需要注意的一些问题。
第3章ML Pipeline原理与实战
Spark MLib是Spark的重要组成部分,也是最早推出的库之一,其基于RDD的API,算法比较丰富,比较稳定,也比较好用。但是如果目标数据集结构复杂需要多次处理,或者是对新数据需要结合多个已经训练好的单个模型进行综合计算时,使用MLlib将会让程序结构复杂,甚至难于理解和实现。为改变这一- 局限性,从Spark 1.2 版本之后引入了MLPipeline,经过多个版本的发展,Spark ML克服了MLlib在处理复杂机器学习问题的一些不足(如工作比较复杂,流程不清晰等),向用户提供基于DataFrame之上的更加高层次的API库,以更加方便的构建复杂的机器学习工作流式应用,使整个机器学习过程变得更加易用、简洁、规范和高效。Spark 的Pipeline与Scikit中Pipeline的功能相近、理念相同。本章主要介绍Spark ML中Pipeline的有关内容。
第4章特征提取、转换和选择
在实际机器学习项目中,我们获取的数据往往是不规范、不一致的,有很多缺失数据,甚至不少错误数据,这些数据有时又称为脏数据或噪声,在模型训练前,务必对这些脏数据进行处理,否则,再好的模型,也只能脏数据进,脏数据出。
第5章模型选择和优化
本章主要介绍如何使用Spark ML提供的方法及自定义函数等方法来对模型进行调优。
我们可以通过SparkML内建的交叉验证、训练验证拆分法、网格参数等方法进行模型调优,当然也可以自定义函数进行模型优化。
第6章Spark MLlib基础
传统的机器学习算法,由于技术和单机存储的限制,只能在少量数据上使用。一旦数据量过大,往往需要采用数据抽样的方法。但这种抽样很难保证不走样。近些年随着HDFS等分布式文件系统出现,存储海量数据已经成为可能。在全量数据上进行机器学习变得可能或必要,通过MapReduce计算框架虽然可以实现分布式计算,但中间结果需要存在到磁盘,这对于计算过程中需要多次迭代的机器学习(因为通常情况下机器学习算法参数学习的过程都是迭代计算的)来说不很理想。
用Spark的出现正好弥补了MapReduce的不足,它立足于内存计算,所以特别适合机器学习的迭代式计算。同时Spark提供了一个基于海量数据的分布式运算的机器学习库,同时提供了很多特征选取、特征转换等内嵌函数,大大降低了大家学习和使用Spark的门槛。
对开发者来说只需有一定 Spark基础、了解机器学习算法的基本原理及相关参数的含义和作用,都可以比较顺利地使用Spark进行基于大数据的机器学习。
第7章构建Spark ML推荐模型
本章主要介绍Spark机器学习中的协同过滤( Collaborative Filtering, CF)模型。协调过滤简单来说就是利用某个兴趣相投、拥有共同经验之群体的喜好来为使用户推荐其感兴趣的资讯,个人通过合作的机制给予资讯相当程度的回应(如评分)并记录下来以达到过滤的目的,进而帮助别人筛选资讯。回应不一-定局限于特别感兴趣的,特别不感兴趣资讯的记录也相当重要。在日常生活中,人们实际上经常使用这种方法,如你哪天突然想看个电影,但你不知道具体看哪部,你会怎么做?大部分人会问周围的朋友,而我们一般更倾向于从兴趣或观点相近的朋友那里得到推荐。这就是协同过滤的思想。换句话说,就是借鉴和你相关的人群的观点来进行推荐。
第二部分(第8~12章)
主要以实例为主,讲解了Spark ML的各种机器学习算法,包括推荐模型、分类模型、聚类模型、回归模型,以及PySpark决策树模型和Spark R朴素贝叶斯模型。
第8章构建Spark ML分类模型
这章就Spark中的分类模型为例,进一步说明如何使用Spark ML中特征选取、特征转换、流水线、模型选择或优化等方法,简化、规范化、流程化整个机器学习过程。
分类、回归和聚类是机器学习中重要的几个分支,也是日常数据处理与分析中最常用的手段。这几类算法有着较高的成熟度,原理也较容易理解,且有着不错的效果,深受数据分析师们的喜爱。
第9章构建Spark ML回归模型
回归模型属于监督式学习,每个个体都有一个与之相关联的实数标签,并且我们希望在给出用于表示这些实体的数值特征后,所预测出的标签值可以尽可能接近实际值。
回归算法是试图采用对误差的衡量来探索变量之间关系的一-类算法。回归算法是统计机器学习的利器。在机器学习领域,人们说起回归,有时候是指一类问题,有时候是指一类算法,这一点常常会使初学者感到困惑。
本章主要介绍Spark ML中的回归模型,以回归分析中常用决策树回归、线性回归为例,对共享单车租赁的情况进行预测,其中介绍了-些特征转换、特征选择、交叉验证等方法的具体使用。
第10章构建Spark ML聚类模型
聚类是一种无监督学习,它与分类不同,聚类所要求划分的类是未知的。
聚类算法的思想就是物以类聚的思想,相同性质的点在空间中表现得较为紧密和接近,主要用于数据探索与异常检测。
聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,它能够从样本数据出发,自动进行分类。聚类分析也有很多方法,使用不同方法往往会得到不同的结论。从实际应用的角度看,聚类分析是数据挖掘的主要任务之一。
而且聚类能够作为一个独立的工具获得数据的分布状况,观察每一族数据的特征,集中对特定的族集合作进一步地分析。聚类分析还可以作为其他算法(如分类和推荐等算法)的预处理步骤。
聚类是机器学习中一种重要方法,一般机器学习中都有,当然Spark也不例外。
第11章PySpark 决策树模型
Python作为机器学习中的利器,一直被很多开发者和学习者所推崇。除了开源、易学,以及简洁的代码风格的特性之外,Python 当中还有很多优秀的第三方库,为我们对数据进行处理、探索和模型的构建提供很大的便利,如Pandas、Numpy、Scipy 、Matplotib 、StatsModels、Scikit-Learn、 Keras等。Python 的强大还体现在它的与时俱进,它与大数据计算平台Spark的结合,可谓是强强联合、优势互补、相得益彰,这就有了现如今Spark 当中一个重要分支——PySpark。
本章就机器学习中的决策树模型,使用PySpark中的ML库,以及IPython交互式环境行讲解。
第12章SparkR朴素贝叶斯模型
前一章我们介绍了PySpark,就是用Python 语言操作Spark大数据计算框架上的任务,这样就自然把Python的优点与Spark的优势进行叠加。Spark提供了Python的API,也提供了R语言的API,其组件名称为SparkR。
第三部分(第13章)
与之前的批量处理不同,本章以在线数据或流式数据为主,讲解了Spark的流式计算框架Spark
Streaming.
第13章使用Spark Streaming构建在线学习模型
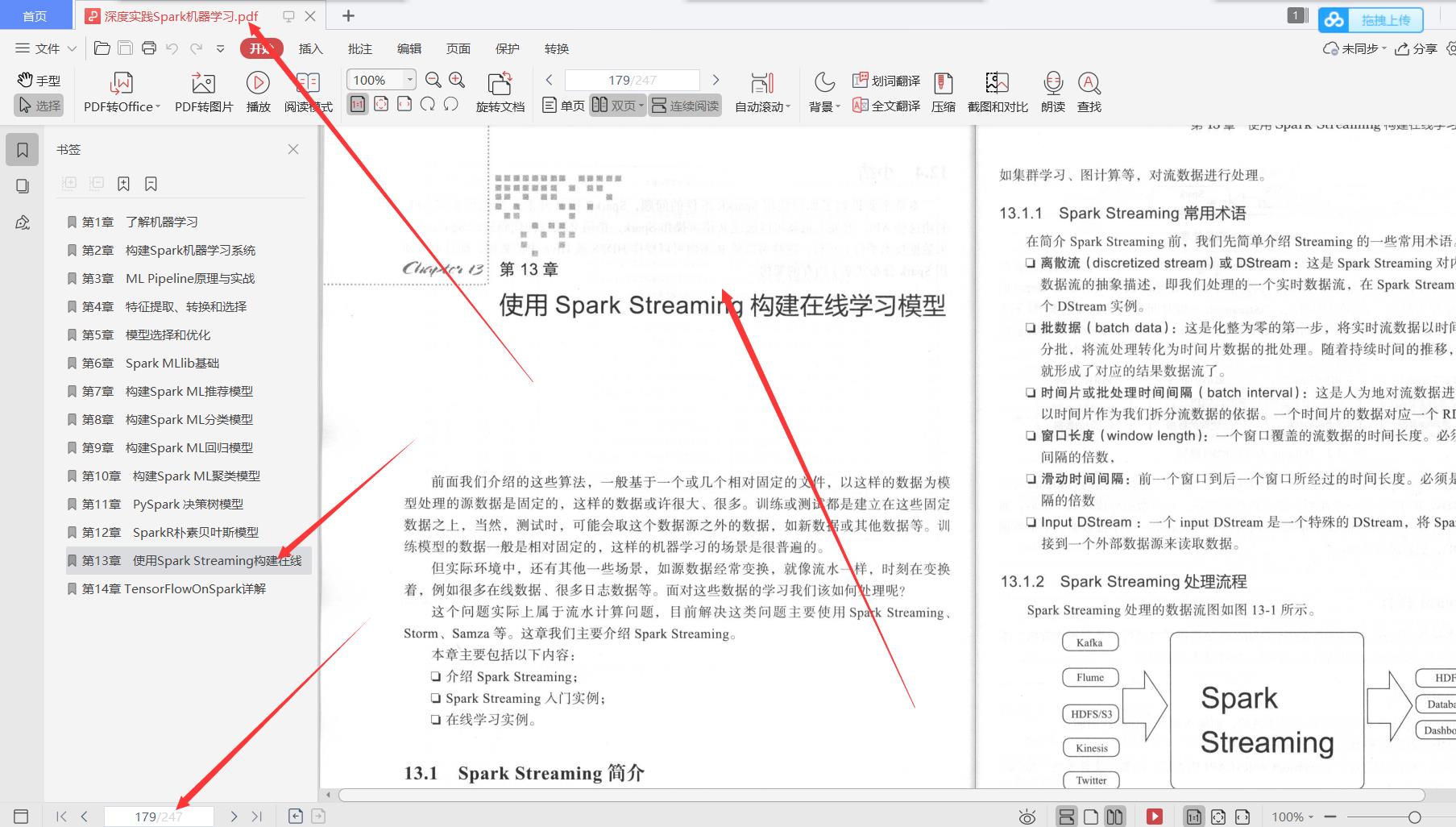
前面我们介绍的这些算法,一般基于一个或几个相对固定的文件,以这样的数据为模型处理的源数据是固定的,这样的数据或许很大、很多。训练或测试都是建立在这些固定数据之上,当然,测试时,可能会取这个数据源之外的数据,如新数据或其他数据等。训练模型的数据一般是相对固定的,这样的机器学习的场景是很普遍的。
但实际环境中,还有其他一.些场景,如源数据经常变换,就像流水一样,时刻在变换着,例如很多在线数据、很多日志数据等。面对这些数据的学习我们该如何处理呢?
这个问题实际上属于流水计算问题,目前解决这类问题主要使用SparkStreaming、Storm、Samza 等。这章我们主要介绍Spark Streaming。
第四部分(第14章)
介绍了Spark深度学习,主要包括TensorFlow的基础知识及它与Spark的整合框架TensorFlowOnSpark。
第14章TensorFlowOnSpark详解
前面我们介绍了Spark MLib的多种机器学习算法,如分类、回归、聚类、推荐等,Spark目前还缺乏对神经网络、深度学习的足够支持,但近几年市场对神经网络,尤其对深度学习热情高涨,成了当下很多企业的研究热点,缺失神经网络的支持,这或许也算是Spark MLlib尚欠不足之处吧。
不过好消息是TensorFlow这个深度学习框架,已经有了Spark 接口,即TensorFlowOnSpark。
TensorFlow是目前很热门的深度学习框架,是Google于2015年11月9日开源的第二代深度学习系统,也是AlphaGo的基础程序。
本章我们将介绍深度学习最好框架TensorFlow及TensorFlowOnSpark。
这份【 深度实践Spark机器学习】共有247页,已经整理打包好,需要完整版内容的朋友,可以在文末获取免费领取方式!!!
得到专家高度评价

本文系统讲解Spark机器学习的技术、原理、算法和组件,以及构建Spark机器学习系统的方法、流程、标准和规范!!!
称之为spark界的一股清流,为大数据人才打下了坚实的基础,为祖国未来的发展提供了优秀人才!!
希望大家能够理解其中的真谛,为了自己和祖国的未来,好好提升自己!!!
乘风破浪会有时,直挂云帆济沧海!!
书山有路勤为径,学海无涯苦作舟!
因为这份文档包含的内容实在是太多了 ,不能够很详细地给大家展示出来全部的内容。需要完整版文档的小伙伴,可以看向下面来获取!
需要完整版文档的小伙伴,可以一键三连,下方获取免费领取方式!

以上是关于三个月吃透腾讯T4推荐247页深度实践Spark机器学习pdf终入腾讯云的主要内容,如果未能解决你的问题,请参考以下文章
两个月吃透阿里P9推荐260页SpringBoot2企业应用实战pdf入职定P6+
花两个月吃透京东T8推荐的178页京东基础架构建设之路,入职定T5
当Spark遇上TensorFlow分布式深度学习框架原理和实践