DeepFake 入门了解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DeepFake 入门了解相关的知识,希望对你有一定的参考价值。
参考技术A Deepfake,是由“deep machine learning”(深度机器学习)和“fake photo”(假照片)组合而成,本质是一种深度学习模型在图像合成、替换领域的技术框架,属于深度图像生成模型的一次成功应用。其实该技术最早版本在2018年初就被提出了,当时在构建模型的时候使用了Encoder-Decoder自编解码架构,在测试阶段通过将任意扭曲的人脸进行还原,整个过程包含了:获取正常人脸照片=>扭曲变换人脸照片=> Encoder编码向量 => Decoder解码向量 => 还原正常人脸照片五个步骤。而ZAO在Encoder-Decoder的框架之上,又引入了GAN(生成对抗网络)技术,不但降低了同等条件下的模型参数量和模型复杂度,同时使生成的人脸更为清晰,大大降低了对原图的依赖,显著提升了换脸的效果,而且基于GAN技术的Deepfake改进版已经在Github开源。
尽管「Deepfake」这类应用非常吸引人,但落到实处还是会引发很多的问题,不论是伦理还是隐私。后面我们将介绍生成对抗网络和变分自编码器两种换脸的解决方案,也许大规模应用还能进一步催生效果更好、算力更少的解决方案。
直观而言,GAN 这类生成模型可以生成非常逼真的人脸图像,那么现在需要将某个人的特点迁移到另一张人脸上,这就需要更多的模块来定义需要迁移的位置与特点。
总体上,「Deepfakes」换脸主要分为以下过程:
其中人脸定位已经非常成熟了,一般定位算法可以生成人脸的特征点,例如左右眉毛、鼻子、嘴和下巴等等。人脸转换也就是采用 GAN 或 VAE 等生成模型,它的目标是生成拥有 A 表情的 B 脸。最后的图像拼接则是将人脸融合原图的背景,从而达到只改变人脸的效果。
当然,如果生成 ZAO 这种小视频,那么还需要一帧帧地处理图像,然后再将处理后的结果重新拼接成小视频。
人脸定位也就是抽取原人脸的表情特征,这些特征点大致描述了人脸的器官分布。我们可以直接通过 dlib 和 OpenCV 等主流的工具包直接抽取,但它们一般采用了经典的 HOG 的脸部标记算法。这种算法根据像素亮度差确定一些「箭头」,从而找到人脸显著的特征点。
如上是一些人脸特征点,如果我们想换脸的表情更加真实和准确,那么也可以使用目前主流的人脸识别算法,它利用卷及网络能生成更完美的特征点。但是这类深度模型需要更大的算力,尤其是在处理高分辨率图像时。
首先对于变分自编码器(VAE),我们知道它希望通过无监督的方式将人脸图像压缩到短向量,再由短向量恢复到人脸图像。这样短向量就包含了人脸图像的主要信息,例如该向量的元素可能表示人脸肤色、眉毛位置、眼睛大小等等。
所以如果我们用某个编码器学习所有人,那么它就能学习到人脸的共性;如果再用某个解码器学习特定的某个人,那么就能学习到他的特性。简单而言,当我们用通用编码器编码人脸 A,再使用特定解码器 B 解码隐藏向量,那么就能生成出拥有 A 的人脸表情,但却是 B 人脸的图像。
这就是 VAE 的解决方案,对于 GAN 来说,它会利用抽取的人脸特征点,然后根据生成器生成对应的目标人脸图像。这时候,编码器同样也会将真实的目标人脸编码,并和生成的目标人脸混合在一起。因此,如果判别器不能区分根据某人特征点生成的人脸和真实人脸有什么区别,那么生成的人脸就非常真实了。
如上所示为论文 Few-Shot Adversarial Learning of Realistic Neural Talking Head Models 的解决方案,它只需要几张目标人脸图,就能根据原人脸的特征点生成极其逼真的效果。
知道了如何制作换脸视频,我们还要掌握一些识别换脸视频的技术,因为这些换脸技术给大众带来欢乐的同时,也在被不少人滥用。这种滥用不仅给公众人物造成了困扰,甚至还威胁到了普通大众。
由于用来训练神经网络的图像数据往往是睁着眼睛的,因此 Deepfake 视频中人物的眨眼或不眨眼的方式通常是不自然的。
去年,奥尔巴尼大学(University of Albany)的研究人员发表了一篇论文,提出了一种可以检测这种不自然眨眼的技术。有趣的是,这项技术使用的也是深度学习,和制作假视频的技术是一样的。研究人员发现,利用眨眼视频训练出的神经网络可以在视频中定位眨眼片段,找出非自然眨眼运动的一系列帧。结果发现,Deepfake 视频中人物的眨眼不符合正常的生理学规律,由此可以识别出哪些是原始视频,哪些是 Deepfakes 视频。
每个人都有独特的头部运动(如开始陈述事实时点头)和面部表情(如表达观点时得意得笑),但 Deepfakes 中人物的头部动作和面部表情都是原人物而非目标人物的。
基于此,加州大学伯克利分校的研究者提出了一种检测换脸的 AI 算法。其基本原理是:利用一个人的头部动作和面部表情视频训练一个神经网络,然后拿这个神经网络去检测另一个视频中的人物动作和表情是否属于这个人。模型准确率达到 92%。
(a)原始人物;(b,c)分别是 Deepfake 人物。
论文地址: http://openaccess.thecvf.com/content_CVPRW_2019/papers/Media%20Forensics/Agarwal_Protecting_World_Leaders_Against_Deep_Fakes_CVPRW_2019_paper.pdf
制作换脸视频和识别换脸就像一场猫鼠游戏,造假技术日新月异,打假技术也在不断迭代。但仅在技术层面打击这一技术的滥用是不够的,我们还需要法律的支持。
参考链接: https://www.jiqizhixin.com/articles/2019-08-31-3?from=synced&keyword=deepfake
可以提高DeepFaceLab(DeepFake)合成最终视频速度的方法
DeepFaceLab相关文章
一:《简单介绍DeepFaceLab(DeepFake)的使用以及容易被忽略的事项》
二:《继续聊聊DeepFaceLab(DeepFake)不断演进的2.0版本》
三:《如何翻译DeepFaceLab(DeepFake)的交互式合成器》
四:《想要提高DeepFaceLab(DeepFake)质量的注意事项和技巧(一)》
五:《想要提高DeepFaceLab(DeepFake)质量的注意事项和技巧(二)》
六:《友情提示DeepFaceLab(DeepFake)目前与RTX3080和3090的兼容问题》
七:《高效使用DeepFaceLab(DeepFake)提高速度和质量的一些方法》
八:《支持DX12的DeepFaceLab(DeepFake)新版本除了CUDA也可以用A卡啦》
九:《简单尝试DeepFaceLab(DeepFake)的新AMP模型》
十:《非常规的DeepFaceLab(DeepFake)小花招和注意事项》
文章目录
(一)合成最终视频
合成所有帧图片后,可以选择:
8) merged to avi.bat
8) merged to mov lossless.bat
8) merged to mp4 lossless.bat
8) merged to mp4.bat
我通常都用的是8) merged to mp4.bat,
输入目标码率,将合成后的图片帧加原始视频的音频,合成最终的视频。
如果视频需要进一步处理,则可以在这里输入非常大的码率。
至于不用lossless是因为试过但结果视频有些问题。
(二)合成视频加速
相对整个学习过程,以及对比合成目标图片帧的速度,合成视频这步并不算慢。但蚊子肉也是肉,依然可以加速⭕️。
(2.1)取消遮罩视频合成
合成最终视频时,其实还合成了一个遮罩视频。
如果用不到,可以注释掉这部分内容,或者存入一个新的批处理(需要时再执行)。
也就是将8) merged to mp4.bat下半部分语句前面加上@REM注释掉,如下:
@echo off
call _internal\\setenv.bat
"%PYTHON_EXECUTABLE%" "%DFL_ROOT%\\main.py" videoed video-from-sequence ^
--input-dir "%WORKSPACE%\\data_dst\\merged" ^
--output-file "%WORKSPACE%\\result.mp4" ^
--reference-file "%WORKSPACE%\\data_dst.*" ^
--include-audio
@REM "%PYTHON_EXECUTABLE%" "%DFL_ROOT%\\main.py" videoed video-from-sequence ^
@REM --input-dir "%WORKSPACE%\\data_dst\\merged_mask" ^
@REM --output-file "%WORKSPACE%\\result_mask.mp4" ^
@REM --reference-file "%WORKSPACE%\\data_dst.*" ^
pause
(2.2)视频编码用硬件加速
对于合成MP4视频这一步,DeepFaceLab使用的是🔗ffmpeg 1 的命令行(当然)。
目前最新的🔗DFL版本:DeepFaceLab_NVIDIA_RTX3000_series_build_11_20_2021.exe(此处例子是RTX3000以上版本),
用的是🔗https://www.gyan.dev/构建的Windows版本ffmpeg(release 构建 v5.0)。
我更新成了最新的 git master 2 构建。但瞟了眼编译参数,似乎不更新也行。
可能作者考虑到并不是所有人都在用N卡吧,使用的视频编码方式是软编码。
因此我们可以改为硬件加速的编码方式,节约时间。
(2.2.1)NVIDIA显卡
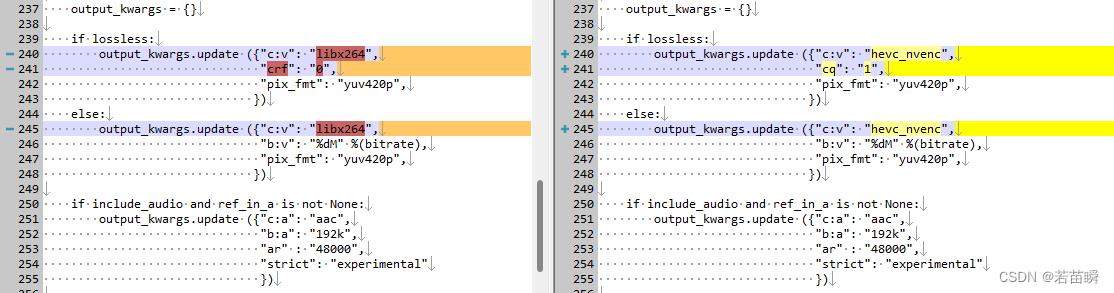
找到并编辑【%DFL所在目录%\\_internal\\DeepFaceLab\\mainscripts\\VideoEd.py】,
参考下图中高亮的部分,把libx264改为hevc_nvenc或h264_nvenc。
至于lossless那边也顺手改了,我不明白cq=0是指【最高画质】还是【自动】,所以实测后改为cq=1了。
(2.2.2)Intel核显
确定有人用Intel核显玩DFL么……
管它的,理论也可以对比一下。
同理如上图,把libx264改为h264_qsv。
PS:这里如果改为h265编码(hevc)的qsv,在我的笔记本上比较慢。而我的台式机没有Intel核显,测不了。
PS2:我也不清楚最新的Intel独显Arc系列会有怎样的效果。
(三)速度对比
可以看出3060显卡硬件加速效果明显(7-8倍)。
厉害的是N卡的硬件加速,对于编码为h264 / h265的效率差异不会太大。
而Intel方面Arc独显没有条件测试,核显有一定的加速效果,但h265依然慢太多。
- CPU软编码(i7-10870):libx264:fps= 241 (默认)
- CPU软编码(i7-10870):libx265:fps= 37
- Intel核显(i7-10870):h264_qsv:fps= 540
- Intel核显(i7-10870):hevc_qsv:fps= 185
- N卡(移动RTX-3060):h264_nvenc:fps= 1828
- N卡(移动RTX-3060):hevc_nvenc:fps= 1677
因为我没有A卡,没法测试也不清楚A卡情况。
与此同时,除非谁能送我一块4090显卡😄,否则目前软编码av1看起来也不是很快的样子,导致此处缺少实用性。
- CPU软编码(i7-10870):libsvtav1:fps=121
~ this is the end ~
以上是关于DeepFake 入门了解的主要内容,如果未能解决你的问题,请参考以下文章