Hadoop的伪分布式安装
Posted Bug专员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop的伪分布式安装相关的知识,希望对你有一定的参考价值。
关闭防火墙
# 检查防火墙是否开启service iptables status# 临时关闭防火墙service iptables stop# 永久关闭防火墙(建议操作)chkconfig iptables off
配置主机名
注意:Hadoop的集群中的主机名不能有_。如果存在_会导致Hadoop集群无法找到这群主机,无法启动!
编辑network文件:vim /etc/sysconfig/network
将HOSTNAME属性改为指定的主机名,例如:HOSTNAME=hadoop01
让network文件重新生效:source /etc/sysconfig/network
配置hosts文件
将主机名和ip地址进行映射
编辑hosts文件:vim /etc/hosts
将主机名和ip地址对应,例如:192.168.27.103 hadoop01
以上更改完毕后,重启虚拟机
配置ssh进行免密互通
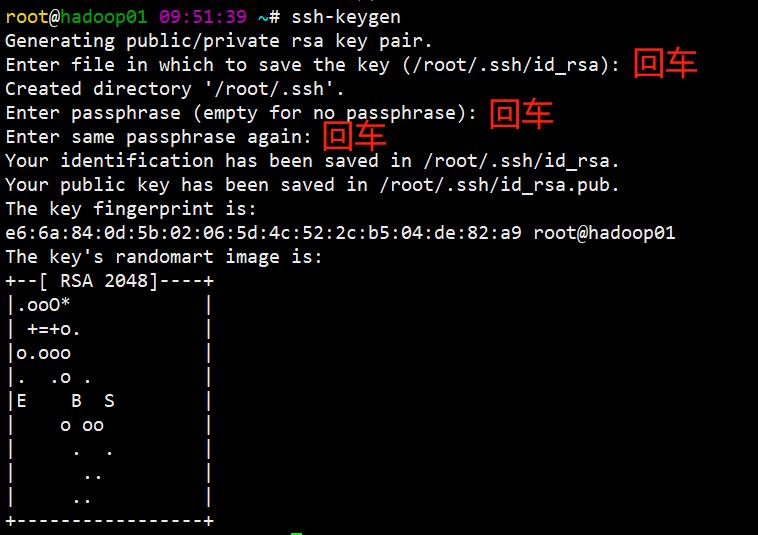
生成公钥和私钥:ssh-keygen

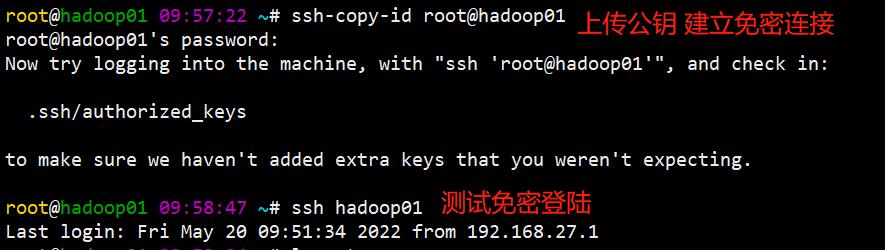
拷贝生成的公钥到远程连接机器(建立免密连接):ssh-copy-id root@hadoop01
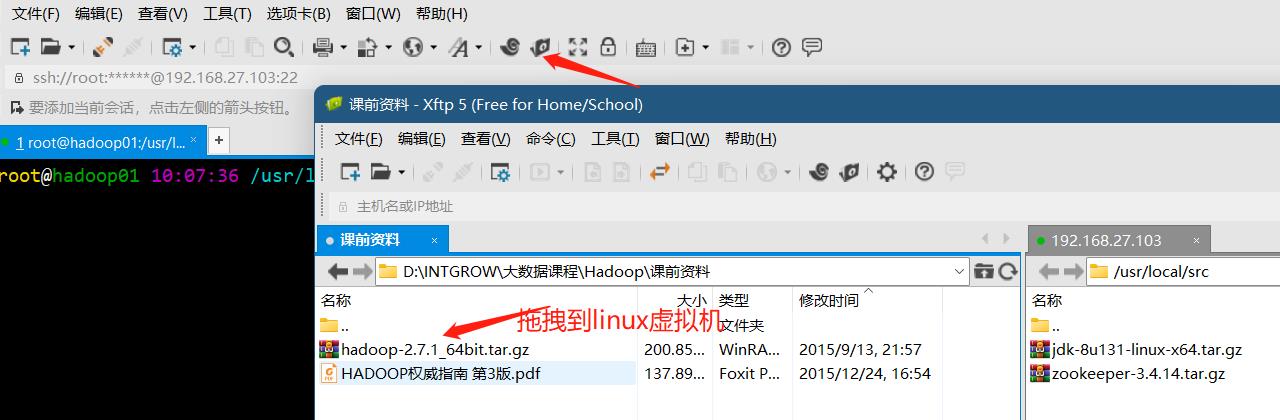
上传Hadoop安装包到Linux中
切换目录到第三方软件目录:cd /usr/local/software/
上传Hadoop安装包--hadoop-2.7.1_64bit.tar.gz
解压安装包:tar zxf hadoop-2.7.1_64bit.tar.gz -C ../software/

配置Hadoop:cd /usr/local/software/hadoop-2.7.1/etc/hadoop/
配置hadoop-env.sh
编辑hadoop-env.sh:vim hadoop-env.sh
修改JAVA_HOME的路径,修改成具体的路径。例如:export JAVA_HOME=/usr/local/java/jdk1.8.0_131
修改HADOOP_CONF_DIR的路径,例如:export HADOOP_CONF_DIR=/usr/local/software/hadoop-2.7.1/etc/hadoop
保存退出文件
重新加载生效:source hadoop-env.sh
配置 core-site.xml
编辑core-site.xml:vim core-site.xml
在configuration 中添加如下内容:
<property> <!-- 指定HDFS中的主节点 - namenode --> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000</value></property><property> <!-- 执行Hadoop运行时的数据存放目录 --> <name>hadoop.tmp.dir</name> <value>/usr/local/software/hadoop-2.7.1/tmp</value></property>
保存退出
配置 hdfs-site.xml
编辑hdfs-site.xml:vim hdfs-site.xml
添加如下配置:
<property> <!-- 设置HDFS中的复本数量 --> <!-- 在伪分布式下,值设置为1 --> <name>dfs.replication</name> <value>1</value></property>
保存退出
配置 mapred-site.xml
将mapred-site.xml.template复制为mapred-site.xml:cpmapred-site.xml.template mapred-site.xml
编辑mapred-site.xml:vim mapred-site.xml
添加如下配置:
<property> <!-- 指定将MapReduce在Yarn上运行 --> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
保存退出
配置 yarn-site.xml
编辑yarn-site.xml:vim yarn-site.xml
添加如下内容:
<!-- 指定Yarn的主节点 - resourcemanager --><property><name>yarn.resourcemanager.hostname</name><value>hadoop01</value></property><!-- NodeManager的数据获取方式 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
保存退出
配置slaves
编辑slaves:vim slaves
添加从节点信息,例如:hadoop01
保存退出
配置hadoop的环境变量
编辑profile文件:vim /etc/profile
添加Hadoop的环境变量,例如:
export HADOOP_HOME=/usr/local/software/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
保存退出
重新生效:source /etc/profilecd
格式化namenode:hadoop namenode -format

启动hadoop:start-all.sh
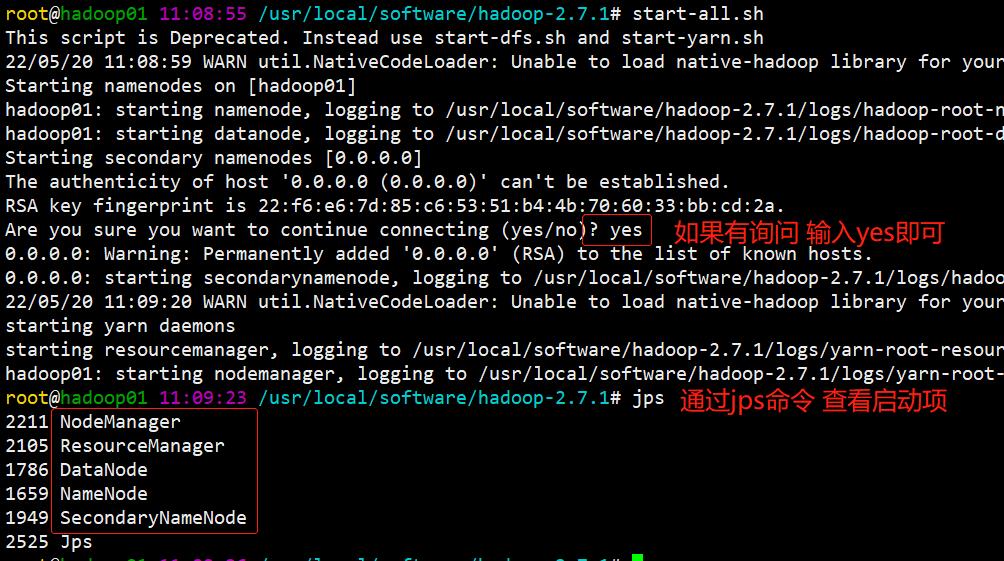
Hadoop如果启动成功,会出现5个进程:Namenode,Datanode,Secondarynamenode,ResourceManager,NodeManager
Hadoop启动成功后,可以通过浏览器访问HDFS的页面,访问地址为:IP地址:50070,例如:192.168.27.103:50070
全分布式安装:http://t.csdn.cn/yPAOM
以上是关于Hadoop的伪分布式安装的主要内容,如果未能解决你的问题,请参考以下文章