超详细C语言版数据结构:图的深度优先遍历(推荐收藏)
Posted 刘一哥GIS
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了超详细C语言版数据结构:图的深度优先遍历(推荐收藏)相关的知识,希望对你有一定的参考价值。
文章目录
一、邻接矩阵存储图的深度优先遍历过程分析
对图1这样的无向图,要写成邻接矩阵,则就是下面的式子:

一般要计算这样的问题,画成表格来处理是相当方便的事情,实际中计算机处理问题,也根本不知道所谓矩阵是什么,所以画成表格很容易帮助我们完成后面的编程任务。在我们前面介绍的内容中,有不少是借助着表格完成计算任务的,如Huffman树。
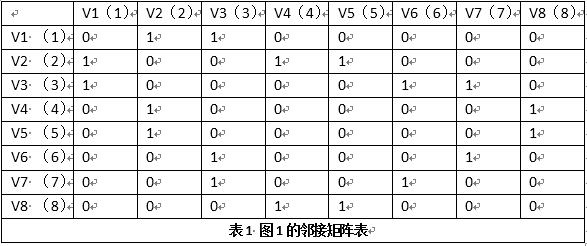
为了记录那些顶点是已经走过的,还要设计一个表来标记已经走过的顶点,在开始,我们假设未走过的是0,走过的是1,于是有:

深度优先遍历过程如下:
(1)从第1行开始,寻找和V1相连的第1个顶点,首先在Visited表中标记V1被访问到,就是:

在该行,我们找到的第一个连接顶点是V2,找到V2顶点后,记录:V1->V2,意味着我们已经抵达V2,注意修改邻接矩阵表;

(2)然后则转向V2顶点所在的行,意味着我们已经抵达V2,再次在Visited表中标记V2顶点已经被访问,就是:

然后,寻找连接V2的、并且是未被访问过的第一个顶点,就是V4:记录V2->V4;

(3)然后则转向V4顶点所在的行,意味着我们已经抵达V4,再次在Visited表中标记V4顶点已经被访问,就是:

然后则转向V4顶点所在的行,寻找连接V4的、并且是未被访问过的第一个顶点,就是V8:记录V4->V8;

(4)然后则转向V8顶点所在的行,意味着我们已经抵达V8,再次在Visited表中标记V8顶点已经被访问,就是:

然后则转向V8顶点所在的行,寻找连接V8的、并且是未被访问过的第一个顶点,就是V5:记录V8->V5;

(5)然后则转向V5顶点所在的行,意味着我们已经抵达V5,再次在Visited表中标记V5顶点已经被访问,就是:

寻找连接V5的、并且是未被访问过的第一个顶点,此处未找到,注意V2、V8顶点已经在Visited表中标记已访问过。

(5)这个地方一定注意:V5上找不到未访问过的顶点,说明此路到此就算走死了。
此时看Visited表:其中还有顶点没有抵达过,于是要按原路返回,所谓原路就是从表12、表10、表9走过的路线返回、然后逐个查找这些顶点上有无未抵达过的顶点。过程如下:再次从V5返回到V8,查找V8上有无未抵达过的顶点,结果是无;
再次从V8返回到V4,查找V4上有无未抵达过的顶点,结果是无;
再次从V4返回到V2,查找V2上有无未抵达过的顶点,结果是无;
再次从V2返回到V1,查找V1上有无未抵达的顶点,结果是V3,于是重复第(1)步,首先标记V3访问到:
标记V1->V3,标记Visited表V3被访问:

到V3,就是这样的情况:

(6)到达V3后,寻找第一个未被访问过的顶点:V6,首先标记Visited表,说明已经抵达V6,就是:

再从V6开始找下一个顶点就是V7:
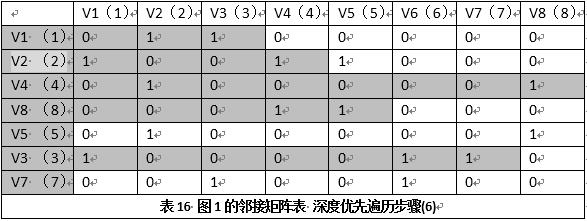
(7)在Visited表中标注V7已经访问到,就是:

至此,图1的深度优先遍历完成。
二、结果分析
从上面的过程可以看出:仅仅就顶点访问到的次序而言,图1的深度优先遍历结果是:
V1->V2->V4->V8->V5->V3->6->V7
但实际执行过程中我们可以发现:所谓图的遍历、其结果应该是一个树:

在C语言中,显示这个结果并不容易,所以大多教材中并不会给出这样的结果。
三、C语言编程实现图的深度优先遍历
图1只有8个顶点,可在实际中,一个图的顶点个数是不确定的,在编程中要保存顶点数据、邻接矩阵,首先就要考虑动态数组;其次,为了方便邻接矩阵的输入和修改,最好是把数据保存在文本文件中。在我们的教材中、程序使用了键盘输入的方式,而在实际操作中、在图的顶点个数比较多的情况下,手工无差错输入很多数据、几乎是无法办到的事情,为此,我们在文件p176G719.txt中保存了图1的邻接矩阵数据。这个文件的名称含义是:教材176页图7.19的顶点名称和邻接矩阵数据。有了这样的数据文件,在记事本程序中可以很方便的修改和补充数据。这个文件的内容如下:
8
V1
V2
V3
V4
V5
V6
V7
V8
0 1 1 0 0 0 0 0
1 0 0 1 1 0 0 0
1 0 0 0 0 1 1 0
0 1 0 0 0 0 0 1
0 1 0 0 0 0 0 1
0 0 1 0 0 0 1 0
0 0 1 0 0 1 0 0
0 0 0 1 1 0 0 0
这个文件第一行是8,说明这个图有8个顶点,随后在第2行到第9行,则是图的顶点名称,第10行到末尾,则是该图的邻接矩阵。
根据不同的图,在记事本程序中完成这样的数据是非常简单的事情,哪怕错了再修改也是很容易做到。
1 设计图的存储结构以及数据文件读取
图的存储、无论哪种方法,都是由两部分组成的,一个是顶点名称集合,一个是顶点关系集合,在邻接矩阵方式中,顶点名称是一个字符串数组,而顶点关系则是一个矩阵、这个矩阵在C语言中是一个二维数组。于是图的结构可以是:
struct Graph
int A[100][100]; //邻接矩阵
char V[100][20]; //顶点名称矩阵,100行,每个名称字符串不超过20字节
int num; //顶点个数
int Visited[100]; //访问记录表
;
但这样的定义很死板,它假设程序最大是100个顶点,实际我们的教材中就是这么定义的。但幸好我们前面已经知道该怎么处理二维数组,于是这里我们可以动态申请内存,以保证在很多顶点的情况也能使用,对二维数组,则上述定义变为:
struct Graph
int **pA; //邻接矩阵指针
char **pV; //顶点名称指针
int num; //顶点个数
int *Visited;//访问记录表指针
;
对这样数组的构造,参见第5部分:数组,好在我们前面有过介绍。
回忆一下,如有数组:
int A[3][3]=1,2,3,4,5,6,7,8,9;
则A[0]、A[1]、A[2]则代表每一行的地址,一般称为行首地址,比如这三行行首地址分别是[100]、[200]、[300],这三个地址数据分别存储在地址[2000]、[2001]、[2002]的存储空间里,则地址[2000]就是这个数组A的含义,就是所谓行首地址数组的首地址。
反过来,如:
int *p[3];
p[0]=A[0];p[1]=A[1];p[2]=A[2];
上面的式子里,如p[0]地址为[3000]、[3001]、[3002],其中的内容保存的是100、200、300,这样就相当于保存了A数组的行首地址,所以p就是个二维数组行首指针数组,只不过它仅仅是三行的二维数组。如把p[0]的地址给另外一个指针变量pA,则pA就是:
int **pA;
假如这个变量的地址在[5000],给这个变量赋值:
pA=&p[0];
于是地址[5000]中将存储3000,这里pA和A的含义是一致的。实际数组A本身就是地址[5000],如有以下语句:
X=A[1][2];
就是从A的地址[5000] 、读到内容3000、再从3001读到200、再从200后取第1个数,过程如下图3所示:

针对n个顶点,则初始化一个图的函数就是:
#define VLENGTH 20 //定义每个顶点名称不超过20字节
struct Graph *GraphInit(int n)
int i;
struct Graph *g;
if(n<=0) return NULL;
g=(struct Graph *)malloc(sizeof(struct Graph));
g->num=n;
g->pA=(int **)malloc(sizeof(int )*n);
g->pV=(char **)malloc(sizeof(char)*n);
for(i=0;i<n;i++)
g->pA[i]=(int *)malloc(sizeof(int)*n);
g->pV[i]=(char *)malloc(sizeof(char)*VLENGTH);
g->Visited=(int *)malloc(sizeof(int )*n);
for(i=0;i<n;i++)
g->Visited[i]=0;
return g;
注意第9行,是为行首地址数组申请内存;
注意第13行,是为每行数据申请存储空间;
注意第14行,前面定义每个顶点的名称是VLENGTH长度,这里是20字节。
由于C语言的指针可以用下标法读写内容,所以完全可以把pA、pV当做普通的二维数组来处理,此处不再叙述。
2 从文件中读数据到邻接矩阵和顶点名称矩阵
这个过程在链表的处理中已经介绍过了,只不过数据格式有差异而已。针对我们前面介绍的数据格式,读数据文件并构造图的函数如下:
struct Graph * GraphCreat(char FileName[20])
int i,j,n;
FILE *fp,*fopen();
struct Graph *G;
fp=fopen(FileName,"r");
if(fp==NULL) return NULL;
fscanf(fp,"%d",&n);
G=GraphInit(n);
for(i=0;i<n;i++)
fscanf(fp,"%s",G->pV[i]);
for(i=0;i<n;i++)
for(j=0;j<n;j++)
fscanf(fp,"%d",&G->pA[i][j]);
fclose(fp);
return G;
第8行首先读文件中顶点个数,然后根据顶点个数、使用GraphInit()申请内存并构造这个图的存储空间,然后在第10行读n个顶点名称、在第12行按二维数组的组织读邻接矩阵。最后,返回G就是包含有顶点名称、邻接矩阵的图的存储空间。
有了这两个函数后,就可以编写main()来测试它们,就是:
main()
int i,j;
struct Graph *G;
G=GraphCreat("p176G719.txt");
//打印顶点名称
for(i=0;i<G->num;i++)
printf("%s ",G->pV[i]);
printf("\\n");
//打印邻接矩阵
for(i=0;i<G->num;i++)
for(j=0;j<G->num;j++)
printf("%d ",G->pA[i][j]);
printf("\\n");
这个程序第5行,你可以修改成用scanf()来读到一个文件名称字符串,然后,就可以使用任何格式符合要求的数据文件了。
G0.C中还包含有GraphFirstAdj()、GraphNextAdj()、GraphDestory()三个函数,这些函数的意义你能看懂么?
2 深度优先遍历的编程实现
从前面算法分析过程可知:对一个图的深度优先遍历,实际就是从第n个顶点开始、标记该顶点已被访问,然后查找该顶点上第一个和它相连、并且未被访问到的顶点、比如是第i个顶点,再去第i个顶点,如此繁琐的说这些,实际就是:
void DFS(struct Graph *G,int n)
int i;
if(G==NULL) return;
if(n<0||n>G->num) return;
G->Visited[n]=1;
printf("%s ",G->pV[n]);
for(i=0;i<G->num;i++)
if(G->pA[n][i]!=0&&G->Visited[i]!=1) DFS(G,i);
第6行是标记该顶点被访问;
第9行就是:查找第n个顶点上、未被访问到的顶点,如找到该顶点、且顶点编号是i,则再次DSF(G,i);
有了这个函数后,构造main()开始从第0个顶点遍历图1,就是:
main()
int i,j;
struct Graph *G;
G=GraphCreat("p176G719.txt");
for(i=0;i<G->num;i++)
printf("%s ",G->pV[i]);
printf("\\n");
for(i=0;i<G->num;i++)
for(j=0;j<G->num;j++)
printf("%d ",G->pA[i][j]);
printf("\\n");
DFS(G,0);
printf("\\n");
进一步测试该函数,按图1的数据仔细分析下它的执行过程,如有图的连接分量不为1,则会在第一个连接分量遍历完成后终止。如下图4,在G1.C中是无法全部遍历完成的。这个图的文件在G4.TXT,修改表23中第5行,从G4.TXT中读数据,则会发现这个程序仅仅遍历了A、B、C、D,而没有到达过E、F、G这三个顶点。

为确保多个分量的图都能顺利遍历完成,则该函数退出后还需要判断是有顶点是否确保全部遍历完成、并确保每次遍历开始的时候、其访问数组Visited[]中全部是0,就是:
void DFSTraverse(struct Graph *G)
int i;
if(G==NULL) return;
for(i=0;i<G->num;i++)
G->Visited[i]=0;
for(i=0;i<G->num;i++)
if(G->Visited[i]==0) DFS(G,i);
表24中函数,很容易修改成计算图的连接分量的函数,这个工作就由同学们自己完成。如果你遇到困难无法完成,参见G3.C
略加修改main()函数,补充:
DFSTraverse(G);
即可完成图4的深度优先遍历。到此,C语言的深度优先遍历到此结束。
四、图的遍历及其应用
1 图的关节点
图的关节点、在图上或许仅仅是个理论或者方法,但对GIS而言,却绝对是个重要意义的理论、尽管目前还没见到这类应用。
求解图的关节点、是典型的深度优先遍历应用,首先我们从教材中找到G5的图,其邻接矩阵如下:

从A点开始、进入A点后由邻接矩阵右端向左遍历,其结果就是:ALMJBHKGIDECF
仔细根据上述结果、可以得到图5这样的深度遍历生成树。
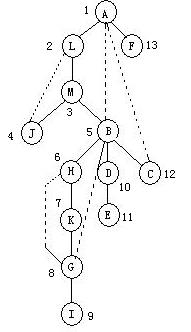
注意图5:每个结点上标注的数字是在深度优先遍历上抵达的次序。
对这个邻接矩阵,我们从右向左做了深度优先遍历,这代表着一个方向,然后,我们要从左到右、在遍历的时候、逐个结点寻找与当前结点相连的最小次序结点(这里一直没想好个比较恰当的措辞来描述这个概念),而这个结点、则构成了所谓的回边路径,如图5中虚线所指的线路,如J-L、B-A等线路。这种线路很关键:它的物理意义是:你可以通过B直接抵达A、或者C直接抵达A、G直接抵达B等等,这些回边路径,则立刻喻示着你炸毁K点、对I点则没什么影响。
从右向左深度优先遍历,这里的现实意义就是说:从其他各个顶点回到A的情况。
相连最小次序结点序号,通常用Low[ ]数组来表示,比如J结点,这个值就是2,它代表着J可以抵达第2个遍历到的结点L,这就是所谓的回边路径。同理,对于C,这个值是1,它代表着在C点,可以直接到A。
如果当前结点下标是v,而在Visited[v]代表这个结点深度遍历中的次序,w代表v顶点在生成树上的孩子结点下标,k代表v的祖先结点下标,则:
Low[v]=minVisited[v],Low[w],Visited[k]
当然,这个式子很简洁,要真正计算出来Low[ ]的值、显然要在程序上说了算。而要在编程中体现这些,还要首先是能手工计算出这个值来。
2 关节点的计算
首先我们设计表格如下:

(1) 顶点A,步骤1
对于A,它就是来自步骤1,就是A,于是Low为1。
(2) 顶点L,步骤2
现在,根据遍历的次序,我们抵达L这个顶点,注意L的邻接矩阵:

从表27可知:深度优先遍历经过的顶点里有A、J、M,其中只有A是深度优先遍历访问过的顶点、所以最小次序号是1,也就是A是L能直接抵达的回边路径上的顶点,所以,表26就是以下结果:


(3) 顶点M,步骤3
现在,我们根据表28抵达顶点M,这个顶点的邻接矩阵表如下:

这个地方可以看到:M可以和B、J、L相连,但B、J尚未被访问过,而M又从L而来,所以此时M的回边就是L的回边,于是有:

(4) 顶点J,步骤4
根据遍历的次序,我们进入顶点J,此时邻接矩阵如下:

对于顶点J,这里可知与L、M相连,从表30知道L是步骤2到达、M是步骤3到达,取步骤次序最小、即为2,它意味着在顶点J上可以抵达深度遍历次序为2的顶点、就是L,于是有:

从这个表第4步,我们回头看图5,就相当于J与L之间的连接虚线。在L、M之间找最小连接次序的意义是:把M炸掉、J依然能回到L。
(5) 顶点B,步骤5
依然要看邻接矩阵,B顶点是:

在这里,我们发现B与A、C、D、G、H、M相连,其中:A、M是深度优先遍历已经遍历过得顶点,找最小次序的、就是A,也就是第一步就抵达的顶点,所以有:

(6) 顶点H,步骤6
再次看邻接矩阵表,H顶点就是:

可以发现H与B、G、K连接,其中B是深度优先遍历访问过的顶点,注意到B的是在第5步访问的,所以有:

对于顶点H,该顶点是由邻接矩阵这种硬性连接造成的回边路径只能是5、就是说它只能通过B回到A,这就非常麻烦,立刻喻示着B是一个关节点。
(7) 顶点K,步骤7
同样要仔细看邻接矩阵,K就是:

我们看到K与G、H相连,但这两个顶点目前都没有被深度优先遍历访问到,此时的情况、立刻说明从邻接矩阵中无法得到Low,同表28的顶点M情况一致,就是说从H顶点来,而H顶点又来自B,所以K的Low也是5。

这现实意义也很明确:如果把B炸毁了、K就是受害者,当然H也是。
(8) 顶点G,步骤8
还是看G的邻接矩阵:

在这个表中可知:G连接有B、H、I、K,其中B、H、K是深度优先遍历都访问过的,这3个顶点里,以访问B的步骤最小,就是5,于是:

对这个结果还能说什么?意味着B炸掉后又多了个受害者。
(9) 顶点I,步骤9
同样要看邻接矩阵,对于I就是:

这个顶点更不幸,它仅仅与G相连,对于这样的顶点,我们知道访问到G的步骤:8,就是这个顶点的Low,就是:

回忆我们对B-H路径的分析,我们知道此时的G同样是I的关节点,I回到A,必须经过G。如果炸掉G、B这样的顶点,I城市就算没救了。
(10) 顶点D,步骤10
还是先看邻接矩阵,对于D,就是:

可知顶点D与B、E相连,对于D,此时最先抵达的顶点是B,在步骤5,所以有:

这个结果说明B依然是控制着D的生命线。
(11) 顶点E,步骤11
还是看E的邻接矩阵,就是:

可以知道E与D直接相连,于是回边上另一个顶点D、也就是在步骤D,于是:

总结下:设当前顶点为v,下一个顶点是w,其步骤都在Visited[ ]中保存,则:
Low[w]>= Visited[v]
则v必然是关节点,比如此时v是顶点D,而w代表E;或者v是顶点B,而w代表H、K等顶点。
从图5中我们不难发现炸掉D确实能孤立E。
(12) 顶点C,步骤12
还是看邻接矩阵,在顶点C有:

从这个地方可知C与A、B相连,这两个顶点都在第1、5步骤访问过,显然回到A最直接,于是此时Low为1。

由于有这个回边线路,所以看图5我们就知道:炸掉B对这个结点不起任何作用。
最后一个顶点F,看邻接矩阵表可知与A相连,所以表46中自行写入1即可,不再重复计算。
到此,G5图中各个顶点回到A顶点路径上、各个回边和关节点计算完毕,我们回顾这个过程不难发现:A、B、G、D是这个图的关节点。
在关节点上分割图,立刻可以将一个图分割成若干个不相连的子图,这就是图论中对关节点的要求。
2 关节点计算的编程实现
根据上面计算的过程,我们可以总结如下:
关节点的计算首先要获得Low[ ],如设图为G,则计算过程分两种情况:
(1) 深度遍历过程中,如到当前顶点v,如该顶点邻接顶点没有被深度优先遍历访问过,如前面的M、K这两个顶点,则此时该顶点最早回边顶点值(Low)等同前一节点值,也就是:G->Low[v]=G->Low[w];
(2) 在遍历过程中,如到当前顶点v,该结点邻接矩阵中可以找到已经遍历过的邻接顶点,则G->Low[v]= min(G->Visited[w]);,如B、J等。
而关节点的判断条件则是:
遍历过程中,如当前顶点为v,邻接顶点为w,如满足:
G->Low[w]>=G->Visited[v]
如v是顶点B、w是顶点H,则v是关节点。
为了满足上述计算要求,我们首先修改Graph的定义,补充内容如下:
struct Graph
int **pA;
char **pV;
int num;
int *Visited;
int Count;
int *Low;
;
新补充的变量Count是一个计数器,用来计算深度优先遍历的步骤,有这个步骤,我们才能在图5上标注每个结点在深度优先遍历中是在哪一步到达的。而对于Low[ ],我们知道这里是最小回边的次序号,定义为指针是准备按顶点个数来动态申请内存,由此,我们图的初始化函数就是表27。
同表19的程序实际没什么差别,仅仅是初始化了Low[ ]这个数组。
深度优先遍历的过程,同前面的过程实际完全一致,但此时Visited[ ]中将不是简单的把已经访问过得顶点如v设置成1,而是要标记步骤,标记步骤,就是让深度优先遍历的过程中,每次都要进行:
++G->Count;
然后把这个结果赋值给:
G->Visited[v]=Count;
其中v是遍历到当前结点的下标。
所以能标记步骤的深度优先遍历就是表28,运行下这个程序,你会看到遍历结果,逐个将Visited[ ]中的值打印出来,就有了深度优先遍历到每个顶点的步骤。
struct Graph *GraphInit(int n)
int i;
struct Graph *g;
if(n<=0) return NULL;
g=(struct Graph *)malloc(sizeof(struct Graph));
g->num=n;
g->pA=(int **)malloc(sizeof(int )*n);
g->pV=(char **)malloc(sizeof(char)*n);
for(i=0;i<n;i++)
g->pA[i]=(int *)malloc(sizeof(int)*n);
g->pV[i]=(char *)malloc(以上是关于超详细C语言版数据结构:图的深度优先遍历(推荐收藏)的主要内容,如果未能解决你的问题,请参考以下文章
图的深度优先遍历DFS和广度优先遍历BFS(邻接矩阵存储)超详细完整代码进阶版