3-1 ES集群介绍
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3-1 ES集群介绍相关的知识,希望对你有一定的参考价值。
参考技术A a.无法在出现故障时,自动完成故障转移b.当整个网站中诮求数过于多时,导致单节点处理诸求速度变慢
c.当整个网站中索引数据超过单个节点物理最大值导致单个节点无法存储整个索引数据
一个集群就是由一一个或多个节点组织在一起,它们共同持有你整个的数据,并一起提供索引和搜索功能。
一个集群 由一个唯一的名字标识,这个名字默认就是elasticsearch。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。在产品环境中显式地设定这个名字是一个好习惯,但是使用默认值来进行测试/开发也是不错的。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一 个叫做"elasticsearch"的集群。
ES提供了将索引划分成多份的功能,称之为分片 默认创建1个索引会划分为5个主分片,1个副本 = 10个分片
分片的分布:由ES自动完成
分片解决了:索引未分片存储时,压力过大,响应慢的问题
分片应散布在多个节点中,否则仅1个节点毫无意义
对分片数据进行复制,保证了宕机时对数据的恢复,而搜索又可以在所有的复制上进行,提高了吞吐量
教你在Kubernetes中快速部署ES集群
摘要:ES集群是进行大数据存储和分析,快速检索的利器,本文简述了ES的集群架构,并提供了在Kubernetes中快速部署ES集群的样例;对ES集群的监控运维工具进行了介绍,并提供了部分问题定位经验,最后总结了常用ES集群的API调用方法。
本文分享自华为云社区《Kubernetes中部署ES集群及运维》,原文作者:minucas。
ES集群架构:
ES集群分为单点模式和集群模式,其中单点模式一般在生产环境不推荐使用,推荐使用集群模式部署。其中集群模式又分为Master节点与Data节点由同一个节点承担,以及Master节点与Data节点由不同节点承担的部署模式。Master节点与Data节点分开的部署方式可靠性更强。下图为ES集群的部署架构图: 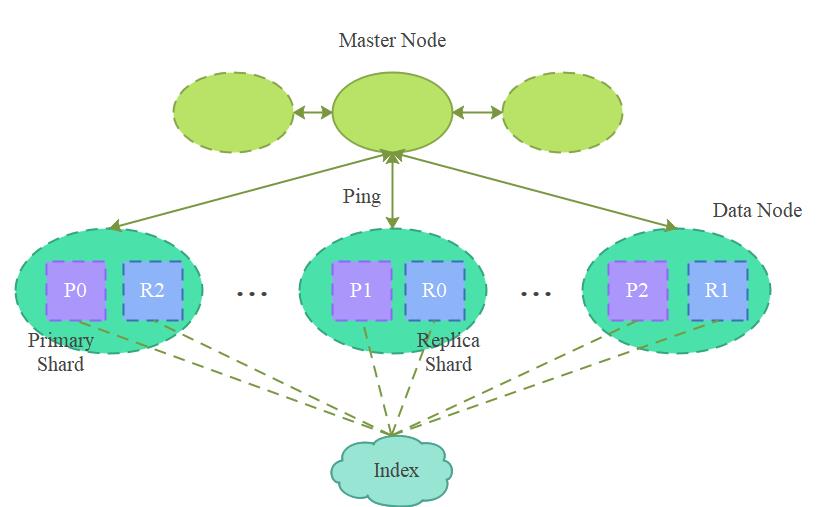
采用K8s进行ES集群部署:
1、采用k8s statefulset部署,可快速的进行扩缩容es节点,本例子采用 3 Master Node + 12 Data Node 方式部署
2、通过k8s service配置了对应的域名和服务发现,确保集群能自动联通和监控
kubectl -s http://ip:port create -f es-master.yaml
kubectl -s http://ip:port create -f es-data.yaml
kubectl -s http://ip:port create -f es-service.yamles-master.yaml:
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
k8s-app: es
kubernetes.io/cluster-service: "true"
version: v6.2.5
name: es-master
namespace: default
spec:
podManagementPolicy: OrderedReady
replicas: 3
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: es
version: v6.2.5
serviceName: es
template:
metadata:
labels:
k8s-app: camp-es
kubernetes.io/cluster-service: "true"
version: v6.2.5
spec:
containers:
- env:
- name: NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: ELASTICSEARCH_SERVICE_NAME
value: es
- name: NODE_MASTER
value: "true"
- name: NODE_DATA
value: "false"
- name: ES_HEAP_SIZE
value: 4g
- name: ES_JAVA_OPTS
value: -Xmx4g -Xms4g
- name: cluster.name
value: es
image: elasticsearch:v6.2.5
imagePullPolicy: Always
name: es
ports:
- containerPort: 9200
hostPort: 9200
name: db
protocol: TCP
- containerPort: 9300
hostPort: 9300
name: transport
protocol: TCP
resources:
limits:
cpu: "6"
memory: 12Gi
requests:
cpu: "4"
memory: 8Gi
securityContext:
capabilities:
add:
- IPC_LOCK
- SYS_RESOURCE
volumeMounts:
- mountPath: /data
name: es
- command:
- /bin/elasticsearch_exporter
- -es.uri=http://localhost:9200
- -es.all=true
image: elasticsearch_exporter:1.0.2
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /health
port: 9108
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
name: es-exporter
ports:
- containerPort: 9108
hostPort: 9108
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /health
port: 9108
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
resources:
limits:
cpu: 100m
memory: 128Mi
requests:
cpu: 25m
memory: 64Mi
securityContext:
capabilities:
drop:
- SETPCAP
- MKNOD
- AUDIT_WRITE
- CHOWN
- NET_RAW
- DAC_OVERRIDE
- FOWNER
- FSETID
- KILL
- SETGID
- SETUID
- NET_BIND_SERVICE
- SYS_CHROOT
- SETFCAP
readOnlyRootFilesystem: true
dnsPolicy: ClusterFirst
initContainers:
- command:
- /sbin/sysctl
- -w
- vm.max_map_count=262144
image: alpine:3.6
imagePullPolicy: IfNotPresent
name: elasticsearch-logging-init
resources: {}
securityContext:
privileged: true
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
volumes:
- hostPath:
path: /Data/es
type: DirectoryOrCreate
name: eses-data.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
k8s-app: es
kubernetes.io/cluster-service: "true"
version: v6.2.5
name: es-data
namespace: default
spec:
podManagementPolicy: OrderedReady
replicas: 12
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: es
version: v6.2.5
serviceName: es
template:
metadata:
labels:
k8s-app: es
kubernetes.io/cluster-service: "true"
version: v6.2.5
spec:
containers:
- env:
- name: NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: ELASTICSEARCH_SERVICE_NAME
value: es
- name: NODE_MASTER
value: "false"
- name: NODE_DATA
value: "true"
- name: ES_HEAP_SIZE
value: 16g
- name: ES_JAVA_OPTS
value: -Xmx16g -Xms16g
- name: cluster.name
value: es
image: elasticsearch:v6.2.5
imagePullPolicy: Always
name: es
ports:
- containerPort: 9200
hostPort: 9200
name: db
protocol: TCP
- containerPort: 9300
hostPort: 9300
name: transport
protocol: TCP
resources:
limits:
cpu: "8"
memory: 32Gi
requests:
cpu: "7"
memory: 30Gi
securityContext:
capabilities:
add:
- IPC_LOCK
- SYS_RESOURCE
volumeMounts:
- mountPath: /data
name: es
- command:
- /bin/elasticsearch_exporter
- -es.uri=http://localhost:9200
- -es.all=true
image: elasticsearch_exporter:1.0.2
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /health
port: 9108
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
name: es-exporter
ports:
- containerPort: 9108
hostPort: 9108
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /health
port: 9108
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
resources:
limits:
cpu: 100m
memory: 128Mi
requests:
cpu: 25m
memory: 64Mi
securityContext:
capabilities:
drop:
- SETPCAP
- MKNOD
- AUDIT_WRITE
- CHOWN
- NET_RAW
- DAC_OVERRIDE
- FOWNER
- FSETID
- KILL
- SETGID
- SETUID
- NET_BIND_SERVICE
- SYS_CHROOT
- SETFCAP
readOnlyRootFilesystem: true
dnsPolicy: ClusterFirst
initContainers:
- command:
- /sbin/sysctl
- -w
- vm.max_map_count=262144
image: alpine:3.6
imagePullPolicy: IfNotPresent
name: elasticsearch-logging-init
resources: {}
securityContext:
privileged: true
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
volumes:
- hostPath:
path: /Data/es
type: DirectoryOrCreate
name: eses-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
k8s-app: es
kubernetes.io/cluster-service: "true"
kubernetes.io/name: Elasticsearch
name: es
namespace: default
spec:
clusterIP: None
ports:
- name: es
port: 9200
protocol: TCP
targetPort: 9200
- name: exporter
port: 9108
protocol: TCP
targetPort: 9108
selector:
k8s-app: es
sessionAffinity: None
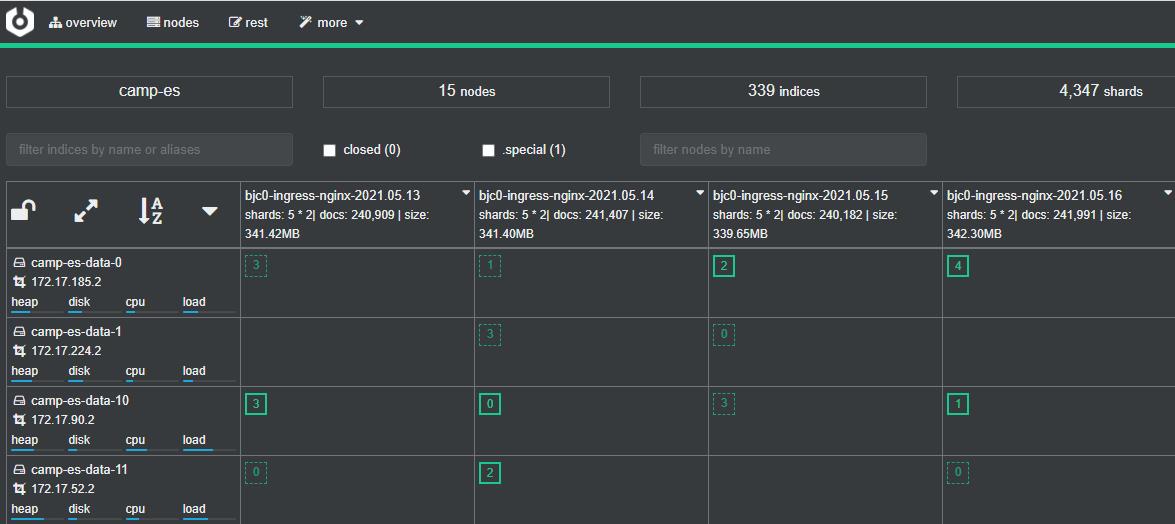
type: ClusterIPES集群监控
工欲善其事必先利其器,中间件的运维首先要有充分的监控手段,ES集群的监控常用的三种监控手段:exporter、eshead、kopf,由于ES集群是采用k8s架构部署,很多特性都会结合k8s来开展
Grafana监控
通过k8s部署es-exporter将监控metrics导出,prometheus采集监控数据,grafana定制dashboard展示
ES-head组件
github地址:https://github.com/mobz/elasticsearch-head
ES-head组件可通过谷歌浏览器应用商店搜索安装,使用Chrome插件可查看ES集群的情况 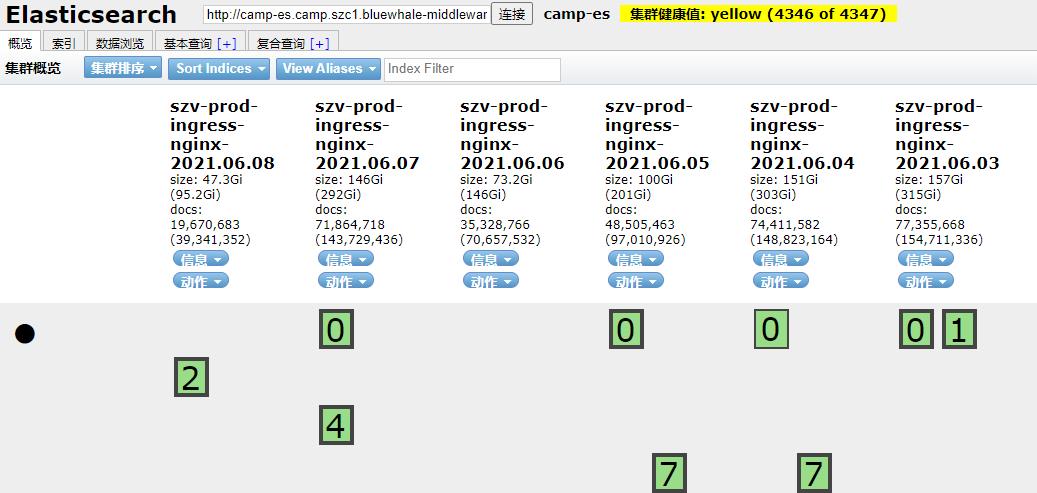
Cerebro(kopf)组件
github地址:https://github.com/lmenezes/cerebro
ES集群问题处理
ES配置
资源配置:关注ES的CPU、Memory以及Heap Size,Xms Xmx的配置,建议如机器是8u32g内存的情况下,堆内存和Xms Xmx配置为50%,官网建议单个node的内存不要超过64G
索引配置:由于ES检索通过索引来定位,检索的时候ES会将相关的索引数据装载到内存中加快检索速度,因此合理的对索引进行设置对ES的性能影响很大,当前我们通过按日期创建索引的方法(个别数据量小的可不分割索引)
ES负载
CPU和Load比较高的节点重点关注,可能的原因是shard分配不均匀,此时可手动讲不均衡的shard relocate一下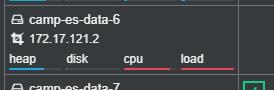
shard配置
shard配置最好是data node数量的整数倍,shard数量不是越多越好,应该按照索引的数据量合理进行分片,确保每个shard不要超过单个data node分配的堆内存大小,比如数据量最大的index单日150G左右,分为24个shard,计算下来单个shard大小大概6-7G左右
副本数建议为1,副本数过大,容易导致数据的频繁relocate,加大集群负载
删除异常index
curl -X DELETE "10.64.xxx.xx:9200/szv-prod-ingress-nginx-2021.05.01"索引名可使用进行正则匹配进行批量删除,如:-2021.05.*
节点负载高的另一个原因
在定位问题的时候发现节点数据shard已经移走但是节点负载一直下不去,登入节点使用top命令发现节点kubelet的cpu占用非常高,重启kubelet也无效,重启节点后负载才得到缓解
ES集群常规运维经验总结(参考官网)
查看集群健康状态
ES集群的健康状态分为三种:Green、Yellow、Red。
- Green(绿色):集群健康;
- Yellow(黄色):集群非健康,但在负载允许范围内可自动rebalance恢复;
- Red(红色):集群存在问题,有部分数据未就绪,至少有一个主分片未分配成功。
可通过API查询集群的健康状态及未分配的分片:
GET _cluster/health
{
"cluster_name": "camp-es",
"status": "green",
"timed_out": false,
"number_of_nodes": 15,
"number_of_data_nodes": 12,
"active_primary_shards": 2176,
"active_shards": 4347,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}查看pending tasks:
GET /_cat/pending_tasks其中 priority 字段则表示该 task 的优先级
查看分片未分配原因
GET _cluster/allocation/explain其中reason 字段表示哪种原因导致的分片未分配,detail 表示详细未分配的原因
查看所有未分配的索引和主分片:
GET /_cat/indices?v&health=red查看哪些分片出现异常
curl -s http://ip:port/_cat/shards | grep UNASSIGNED重新分配一个主分片:
POST _cluster/reroute?pretty" -d '{
"commands" : [
{
"allocate_stale_primary" : {
"index" : "xxx",
"shard" : 1,
"node" : "12345...",
"accept_data_loss": true
}
}
]
}其中node为es集群节点的id,可以通过curl ‘ip:port/_node/process?pretty’ 进行查询
降低索引的副本的数量
PUT /szv_ingress_*/settings
{
"index": {
"number_of_replicas": 1
}
}
以上是关于3-1 ES集群介绍的主要内容,如果未能解决你的问题,请参考以下文章