ElasticSearch 学习笔记总结
Posted IT_Holmes
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch 学习笔记总结相关的知识,希望对你有一定的参考价值。
文章目录
- 一、ES 相关名词 专业介绍
- 二、ES 系统架构
- 三、ES 创建分片副本 和 elasticsearch-head插件
- 四、ES 故障转移
- 五、ES 应对故障
- 六、ES 路由计算 和 分片控制
- 七、ES集群 数据写流程
- 八、ES集群 数据读流程
- 九、ES集群 更新流程 和 批量操作
- 十、ES 相关重要 概念 和 名词
- 十一、ES集群 文档刷新 文档刷写 文档合并
- 十二、ES集群 文档分析
- 十三、ES集群 文档控制
- 十四、ES Kibana
一、ES 相关名词 专业介绍
Elasticsearch 索引(index):一切设计都是为了提高搜索的性能。
Elasticsearch 类型(type):7.X版本以上的都已经不再支持索引类型了(默认类型为:_doc)。
Elasticsearch 文档(Document):

Elasticsearch 文档(Field):相当于数据表的字段,对文档数据根据不同属性进行的分类标识。
Elasticsearch 映射(Mapping):

Elasticsearch 分片(Shards):可以理解为分表效果,将不同的分片放到不同的集群节点上。


Elasticsearch 副本(Replicas):备份的效果。

Elasticsearch 分配(Allocation):就是如何分配的效果。

二、ES 系统架构
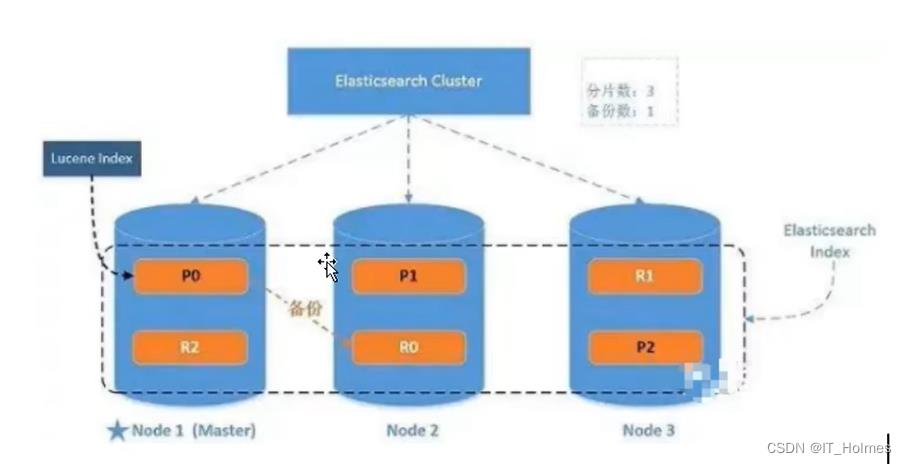
三、ES 创建分片副本 和 elasticsearch-head插件
启动三台es节点服务器。
创建索引users 分配 3个主分片和一份副本(每个主分片拥有一个副本分片)。
// put方法:http://127.0.0.1:1001/users
"settings" :
"number_of_shards" : 3,
"number_of_replicas" : 1
// get方法:http://127.0.0.1:1001/users
// 进行查看
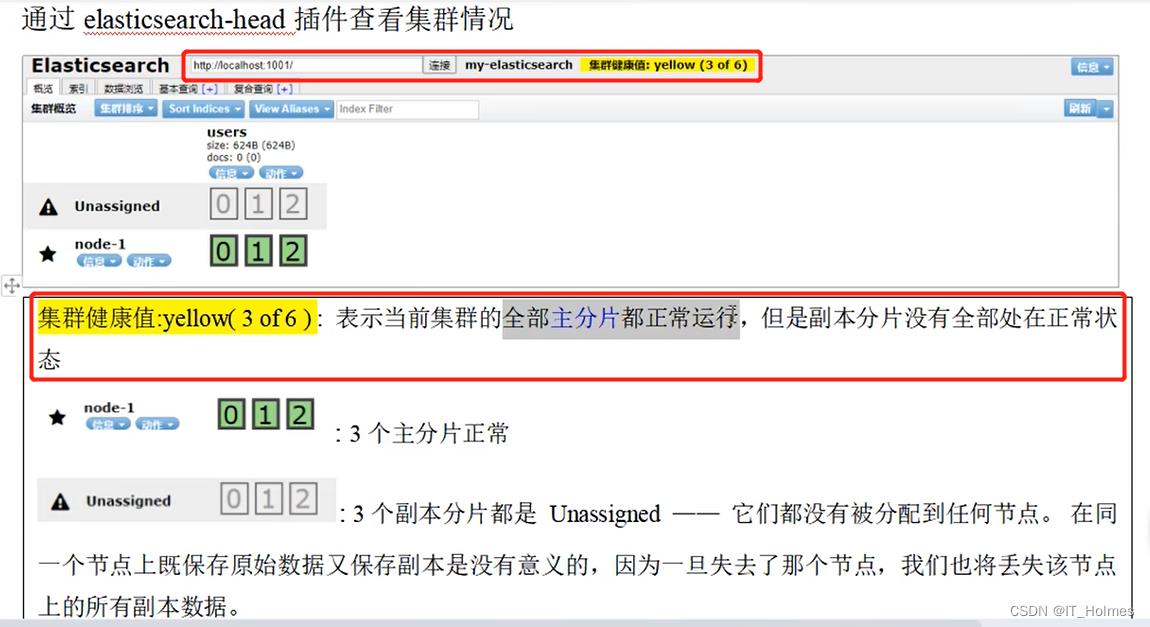
elasticsearch-head是一个浏览器插件,专门来监控es集群的相关内容信息。
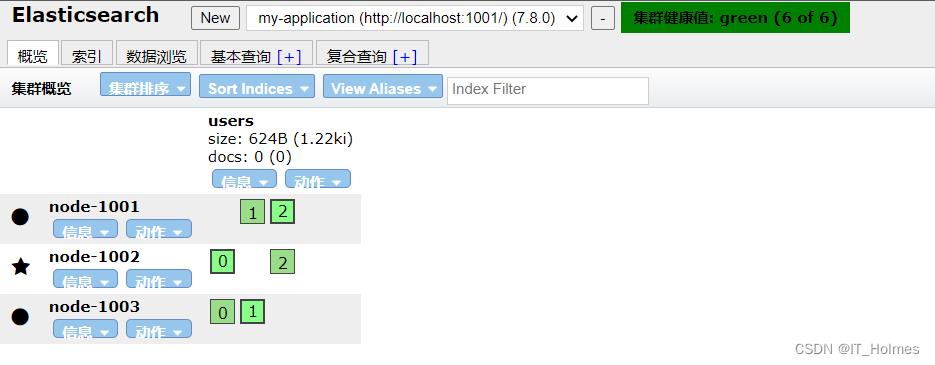
正常启动后的效果:
四、ES 故障转移
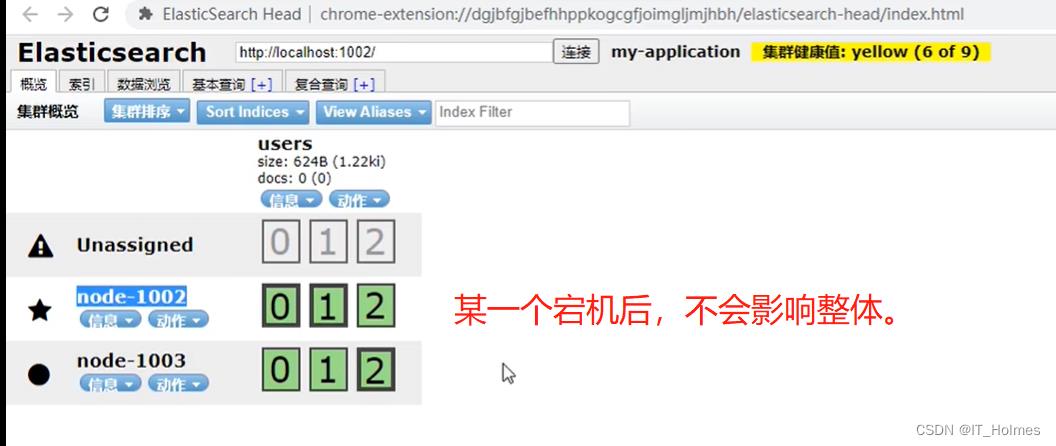
单点集群故障问题:其实单点了就不算是集群了,自身宕机后三个主分片的数据和副本就没了。
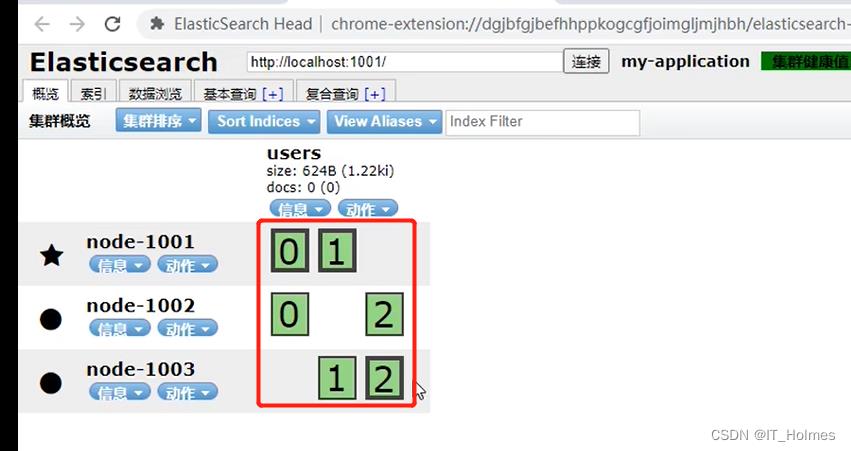
多个节点集群时,就避免了上面的问题出现:
- 粗框的就是主分片,其他的就是副本。

水平扩容:当添加第三个节点的时候,就会重新分配,更加均衡提高吞吐量。
注意:如何分配的 以及 最大扩容多少。

如果超过预期的扩容节点怎么办?
扩容实现:
// put方法:http://127.0.0.1:1001/users/_settings
"number_of_replicas" : 2
五、ES 应对故障
六、ES 路由计算 和 分片控制
路由计算:就是数据放到哪里,应该从哪里取数据。
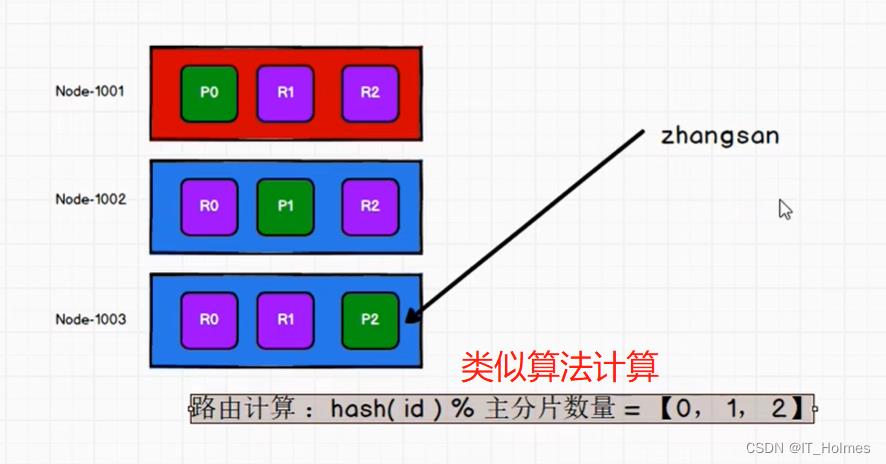
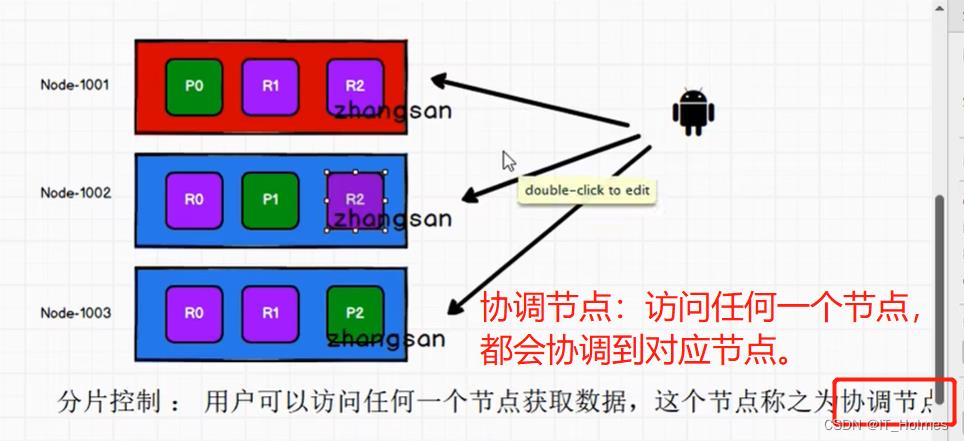
分片控制:
- 虽说,每一个节点都有备份,有数据,但是并不是访问哪个节点就会直接获取该节点数据。
- 每个节点都可以是协调节点,协调节点的效果,如下。
七、ES集群 数据写流程
1. 客户端请求集群节点(任意节点)。
2. 协调节点将请求转换到指定的节点。
3. 主分片将数据保存。
4. 主分片将数据发送给副本。
5. 副本保存后,反馈给主分片。
6. 主分片收到反馈后,再反馈给客户端。
7. 客户端接收到反馈。

consistency 一致性参数:


timeout 超时参数:

八、ES集群 数据读流程
1. 客户端发送查询请求到协调节点。
2. 协调节点计算数据所在的分片以及全部的副本位置。
3. 为了能够负载均衡,可以轮询所有节点。
4. 将请求转发给具体的节点。
5. 节点返回查询结果,将结果反馈给客户端。

九、ES集群 更新流程 和 批量操作
更新流程:与新增相同,更新主片,更新副本。
批量操作:其实批量操作也可以分批到每个节点,进行单节点相关操作。

十、ES 相关重要 概念 和 名词
分片原理:就是倒排索引。
分片是Elasticsearch最小的工作单元。

Elasticsearch 使用一种称为倒排索引的结构,它适用于快速的全文搜索。
倒排索引就是 反向索引(inverted index)。与之对应的是正派索引(forward index)。
其实就是分词的效果:
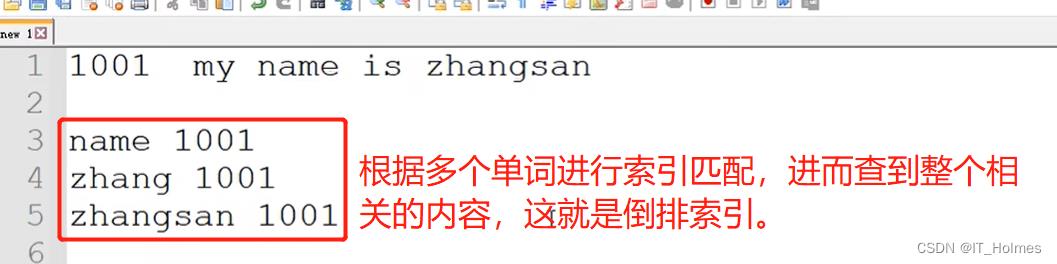
还有一个分词器的概念:因此,有中文、英文等不同情况,所以要用到分词器。
还有能分词,不能分词的: text 和 keyword 。
ik_max_word:最细粒度的拆分。
ik_smart:最粗力度的拆分。
索引名词:
- 词条:索引中最小的存储和查询单元。
- 词典:字典,词条的集合,B+,HashMap。
- 倒排表:存在好多倒排项,效果就是倒排索引解释一样。
倒排索引写入磁盘后是不可变的,好处:


坏处:不可变!

如何保留不变性的前提下实现倒排索引的更新?

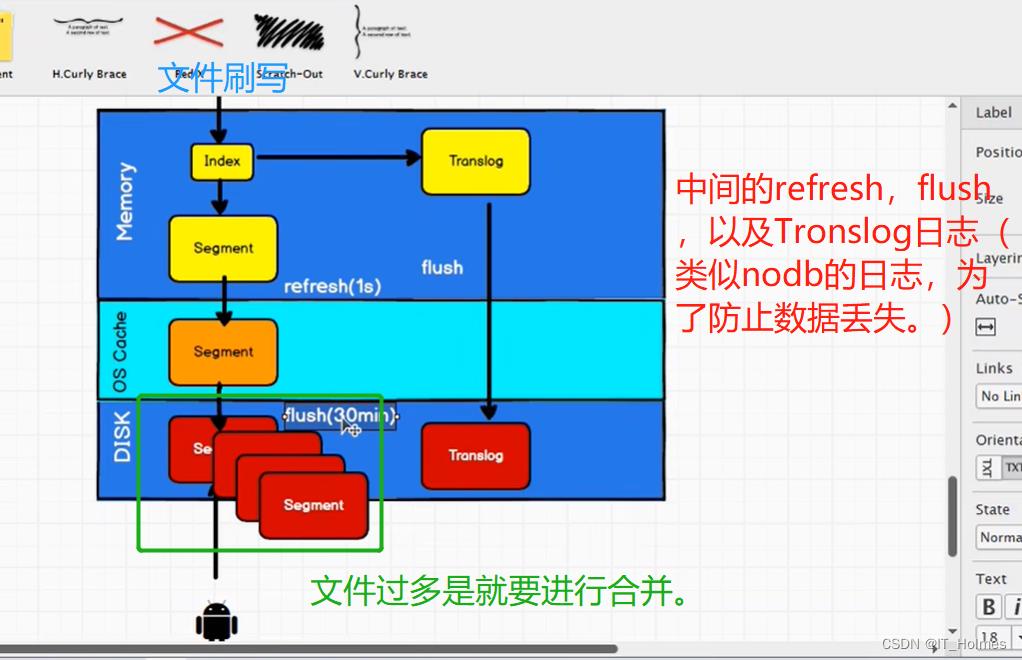
十一、ES集群 文档刷新 文档刷写 文档合并
ES是 近实施搜索的,原理如下:
十二、ES集群 文档分析
分析 原理过程:
- 将一块文档分成适合于倒排索引的独立的 词条。
- 将这些词条统一化为标准格式以提高它们的 可搜索性,或者 recall分析器执行上面的工作。
分析器包含三个主要功能:字符过滤器、分词器、Token过滤器。


ES有一些内置分析器:标准分析器、简单分析器、空格分析器、语言分析器。
标准分析器 的使用:
// get方法:http://127.0.0.1:1001/_analyze
"analyzer":"standard", // 标准分析器
"text":"Text to analyze"
IK 中文分析器:
将解压后的文件夹放入ES根目录下的plugins目录下,重启ES即可使用。

有些时候,ik分词器并不知道有些词汇是一个单词,所以还要告诉ik分词器,哪些是一个单词。

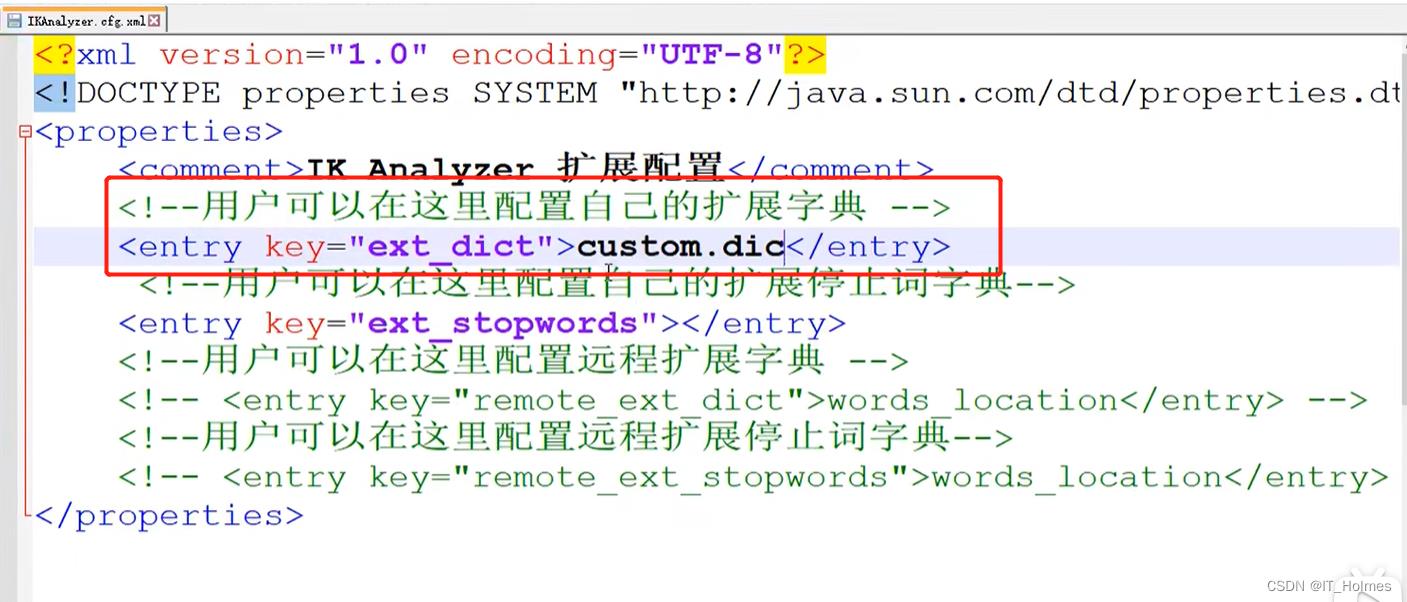
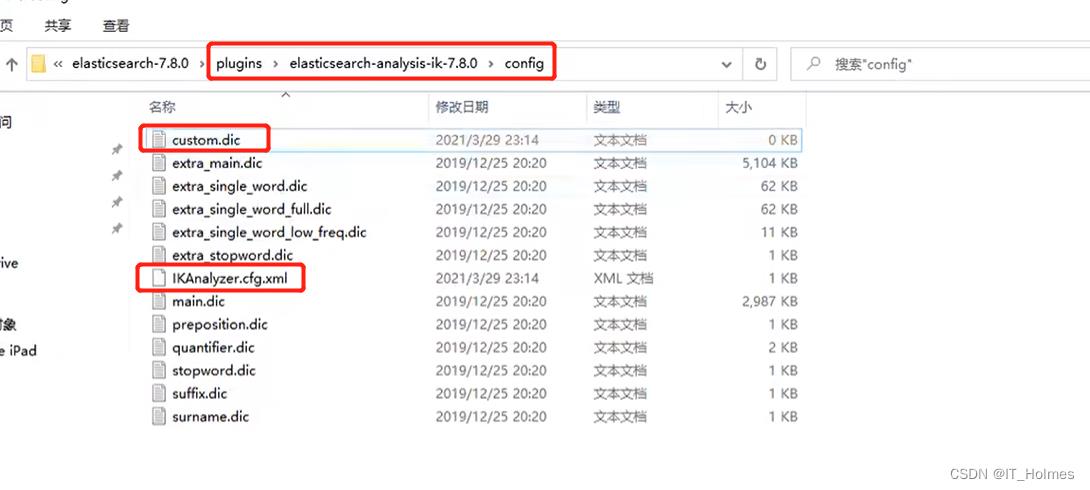
文件目录如下:
自定义分析器:
- 创建索引的时候,通过参数来自定义分析器。
// put方法:http://127.0.0.1:1001/my_index
"settings":
"analysis":
"char_filter":
"&_to_and":
"type": "mapping",
"mappings": [
"&=> and "
]
,
"filter":
"my_stopwords":
"type": "stop",
"stopwords": [
"the",
"a"
]
,
"analyzer":
"my_analyzer":
"type": "custom",
"char_filter": [
"html_strip",
"&_to_and"
],
"tokenizer": "standard",
"filter": [
"lowercase",
"my_stopwords"
]
查询验证分析器:
# GET http://127.0.0.1:9200/my_index/_analyze
"text":"The quick & brown fox",
"analyzer": "my_analyzer"
十三、ES集群 文档控制
场景多个人并发进行处理操作文档时,最后一个人操作的肯定覆盖掉了其他人操作的,理论上应该是这样,但实际会出现一个乱序的情况(不确定谁先完成),那么这种情况应该如何避免。
使用悲观锁 和 乐观锁来处理类似问题:

ES 乐观锁:

效果如下:
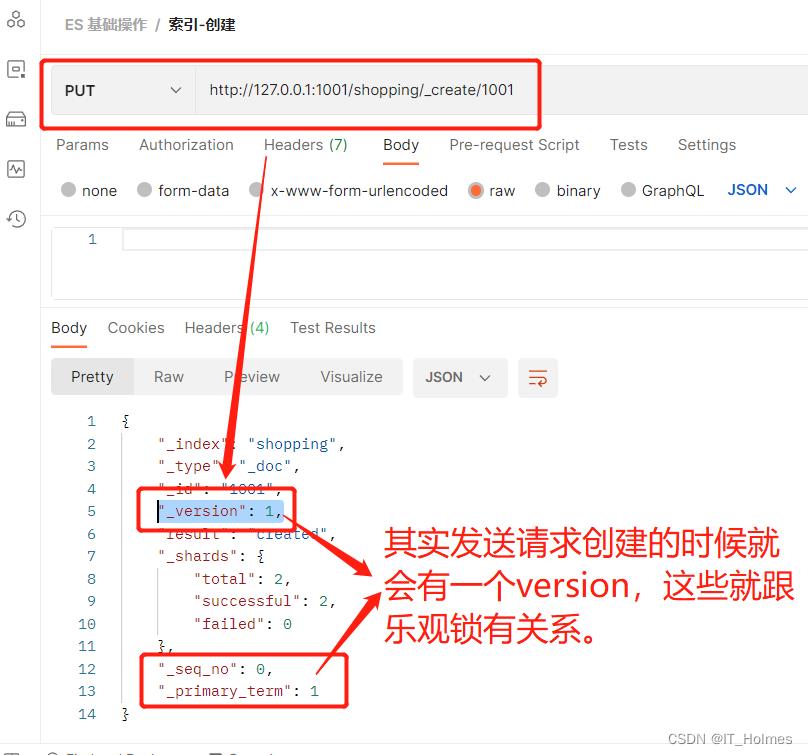

// post方法:http://127.0.0.1:1001/shopping/_update/1001?if_seq_no=1&if_primary_term=1
// 通过if_seq_no=1&if_primary_term=1来操作乐观锁
"doc":
"title":"华为手机"
外部系统版本控制:

例如:就是想通过version来进行判别操作:
// post方法:http://127.0.0.1:1001/shopping/_doc/1001?version=3&version_type=external
// 通过声明version_type=external参数。
"title": "测试手机"
版本必须相同或者大于该版本才能进行修改!
十四、ES Kibana

kibana配置文件:
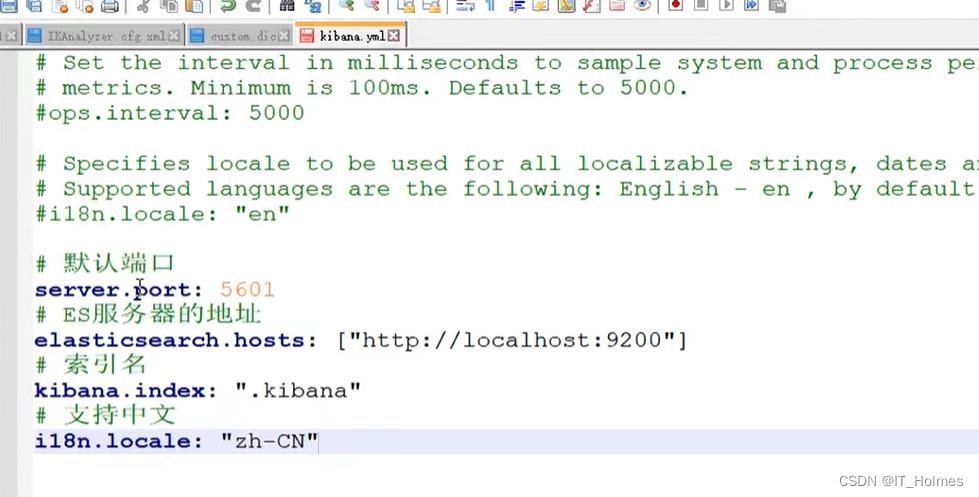
类似如下可视化页面:

以上是关于ElasticSearch 学习笔记总结的主要内容,如果未能解决你的问题,请参考以下文章