filebeat es logstash kibana kafka zookeeper 集群 全链路调试
Posted gblfy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了filebeat es logstash kibana kafka zookeeper 集群 全链路调试相关的知识,希望对你有一定的参考价值。
文章目录
一、集群部署前期
1. 服务部署总览
| 服务器IP | 配置 | 部署内容 | 开放端口 |
|---|
| 192.168.122.128 | 2c/4g | filebeat
es+kafka+zookeeper
kibana | filebeat:5066
es:9200、9300
kafka:9092
zookeeper:2181、2888、3888
kibana:5601 |
| 192.168.122.130 | 2c/4g | es+kafka+zookeeper
logstash | es:9200、9300
kafka:9092
zookeeper:2181、2888、3888
logstash:9600 |
| 192.168.122.131 | 2c/4g | es+kafka+zookeeper
elasticsearch-head | es:9200、9300
kafka:9092
zookeeper:2181、2888、3888
eshead:9100 |
我们会发现在ElasticSearch启动时,会占用两个端口9200和9300。
他们具体的作用如下:
9200 是ES节点与外部通讯使用的端口。它是http协议的RESTful接口(各种CRUD操作都是走的该端口,如查询:http://localhost:9200/user/_search)。
9300是ES节点之间通讯使用的端口。它是tcp通讯端口,集群间和TCPclient都走的它。(java程序中使用ES时,在配置文件中要配置该端口)
2. 软件版本
| 软件 | 版本 |
|---|
| filebeat | 6.7.2 |
| elasticsearch | 6.7.2 |
| logstash | 6.7.2 |
| kibana | 6.7.2 |
| zookeeper | 3.4.10 |
| kafka | 2.11-2.3.0 |
| nodejs | 14.15.1 |
| jdk | 1.8.0_301 |
3. 软件下载
声明:所有的操作都在/app目录执行
以下创建用户目录的命令128节点、130节点、131节点依次执行,软件需要按照 服务部署总览提前下载到/app目录,所有的操作都需要切换到app用户执行,需要root用户我会提前说明
useradd app
passwd app
chwon app.app /app -R
su app
mkdir /app
zookeeper-3.4.10.tar.gz
wget http://archive.apache.org/dist/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
kafka_2.12-2.1.1.tgz
wget https://archive.apache.org/dist/kafka/2.3.0/kafka_2.11-2.3.0.tgz
filebeat-6.7.2-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.7.2-linux-x86_64.tar.gz
logstash-6.7.2.tar.gz
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.7.2.tar.gz
elasticsearch-6.7.2.tar.gz
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.7.2.tar.gz
kibana-6.7.2-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.7.2-linux-x86_64.tar.gz
nodejs
wget https://nodejs.org/dist/v14.15.1/node-v14.15.1-linux-x64.tar.xz
二、jdk安装配置
128节点、130节点、131节点依次执行,
使用root用户进行登录,创建用户
2.1. 解压jdk
cd /app
tar -zxvf jdk-8u301-linux-x64.tar.gz
vi /etc/profile
2.2. 修改环境变量
export JAVA_HOME=/app/jdk1.8.0_301
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
2.3. 服务验证
source /etc/profile
java -version
二、zk集群
2.1. 解压
tar -zxvf zookeeper-3.4.10.tar.gz
2.2. 创建data及logs目录
mkdir /app/zookeeper-3.4.10/data
mkdir /app/zookeeper-3.4.10/logs
2.3. 修改Zk的配置文件
cd /app/zookeeper-3.4.10/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
修改内容为:(此处三台服务器配置相同)
直接替换为以下内容即可
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2181
dataDir=/app/zookeeper-3.4.10/data
dataLogDir=/app/zookeeper-3.4.10/logs
server.1=192.168.122.128:2888:3888
server.2=192.168.122.130:2888:3888
server.3=192.168.122.131:2888:3888
2.4. 新建myid文件
第一台服务器128节点中添加myid文件
echo "1" > /app/zookeeper-3.4.10/data/myid
第二台服务器130节点中添加myid文件
echo "2" > /app/zookeeper-3.4.10/data/myid
第三台服务器131节点中添加myid文件
echo "3" > /app/zookeeper-3.4.10/data/myid
2.5. 依次启动zk
3个节点依次关闭防火墙,启动zk,监控运行状态
systemctl stop firewalld
cd /app/zookeeper-3.4.10/
bin/zkServer.sh start
bin/zkServer.sh status
zookeeper启动成功图片如下:无报错,Mode为leader或者follower都可以

三、kafka集群
登录app用户,3个节点依次执行
3.1. 解压
tar -zxvf kafka_2.11-2.3.0.tgz
3.2. 新建数据目录
mkdir /app/kafka_2.11-2.3.0/data
3.3. 修改集群配置
vim /app/kafka_2.11-2.3.0/config/server.properties
部分配置保持不变(有个印象)
默认部分保持不变
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.retention.bytes=10737420000
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
broker.id=1
host.name=192.168.122.128
listeners=PLAINTEXT://192.168.122.128:9092
advertised.listeners=PLAINTEXT://192.168.122.128:9092
log.dirs=/app/kafka_2.11-2.3.0/data/kafka-logs
zookeeper.connect=192.168.122.128:2181,192.168.122.130:2181,192.168.122.131:2181
auto.create.topics.enable = false
delete.topic.enable=true
log.cleanup.policy=delete
log.segment.delete.delay.ms=0
broker.id=2
host.name=192.168.122.130
listeners=PLAINTEXT://192.168.122.130:9092
advertised.listeners=PLAINTEXT://192.168.122.130:9092
log.dirs=/app/kafka_2.11-2.3.0/data/kafka-logs
zookeeper.connect=192.168.122.128:2181,192.168.122.130:2181,192.168.122.131:2181
auto.create.topics.enable = false
delete.topic.enable=true
log.cleanup.policy=delete
log.segment.delete.delay.ms=0
broker.id=3
host.name=192.168.122.131
listeners=PLAINTEXT://192.168.122.131:9092
advertised.listeners=PLAINTEXT://192.168.122.131:9092
log.dirs=/app/kafka_2.11-2.3.0/data/kafka-logs
zookeeper.connect=192.168.122.128:2181,192.168.122.130:2181,192.168.122.131:2181
auto.create.topics.enable = false
delete.topic.enable=true
log.cleanup.policy=delete
log.segment.delete.delay.ms=0
3.4. 依次启动3个kafka节点
cd /app/kafka_2.11-2.3.0/
nohup bin/kafka-server-start.sh config/server.properties &
3.5. 验证集群服务
验证集群是否安装成功
在其中一个节点上创建一个topic:
bin/kafka-topics.sh --zookeeper 192.168.122.128:2181,192.168.122.130:2181,192.168.122.131:2181 --create --topic app-log --partitions 3 --replication-factor 1
在其中一个节点上启动kafka生产者
bin/kafka-console-producer.sh --broker-list 192.168.122.128:9092 --topic app-log

在集群其他的节点上启动消费者
bin/kafka-console-consumer.sh --bootstrap-server 192.168.122.130:9092 --topic app-log

Kafka生产者发送一条消息,看能否在消费端能够接收到消息,如果都能接收到消息表示kafka集群可用。
四、安装filebeat
登录app用户,仅在128节点执行
4.1. 解压
tar -zxvf filebeat-6.7.2-linux-x86_64.tar.gz
4.2. 修改filebeat.yml配置
vim /app/filebeat-6.7.2-linux-x86_64/filebeat.yml
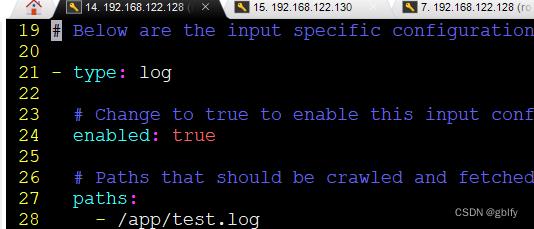
第1处开启enabled为true
enabled: true

第2处开启paths指定log日志文件路径,真实场景是微服务应用的日志目录下的很多log日志文件,可以用*.log,
演示paths路径为/app目录下新创建的test.log日志文件
/app/test.log
第3处
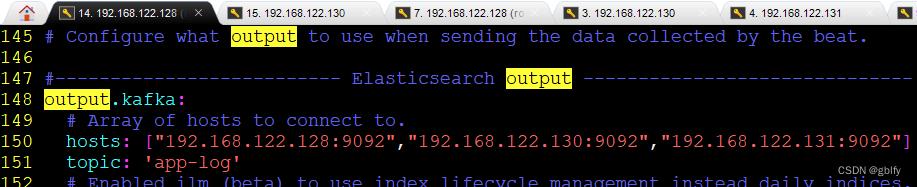
将默认的 output.elasticsearch调整为 output.kafka
hosts置为kafka集群地址
topic是监听的主题
output.kafka:
hosts: ["192.168.122.128:9092","192.168.122.130:9092","192.168.122.131:9092"]
topic: 'app-log'
4.3. 启动filebeat
第一次启动建议选择前台启动,便于监控日志
前台启动
cd /app/filebeat-6.7.2-linux-x86_64
filebeat -e -c /app/filebeat-6.7.2-linux-x86_64/filebeat.yml
ps -ef|grep filebeat
后台启动
cd /app/filebeat-6.7.2-linux-x86_64
nohup filebeat -e -c /app/filebeat-6.7.2-linux-x86_64/filebeat.yml &
ps -ef|grep filebeat

五、安装logstash
登录app用户,仅在130节点执行
5.1. 解压
tar -zxvf logstash-6.7.2.tar.gz
5.2. 新建配置
vim /app/logstash-6.7.2/config/kafkaInput_esOutPut.conf
新增内容如下:
input
kafka
bootstrap_servers => "192.168.122.128:9092,192.168.122.130:9092,192.168.122.131:9092"
group_id => ["elk"]
topics => ["app-log"]
auto_offset_reset => "latest"
consumer_threads => 5
decorate_events => true
output
stdout codec => rubydebug
elasticsearch
hosts => ["192.168.122.128:9200","192.168.122.130:9200","192.168.122.131:9200"]
index => "kafka-logs-%+YYYY-MM-dd"
sniffing => true
template_overwrite => true
5.3. 启动logstash
cd /app/logstash-6.7.2/
nohup bin/logstash -f config/kafkaInput_esOutPut.conf --config.reload.automatic &
ps -ef|grep logstash
–config.reload.automatic 选项的意思是启用自动配置加载,以至于每次修改完配置文件以后无需停止然后重启Logstash
六、安装es集群
登录app用户,128节点、130节点、131节点依次执行
6.1. 解压
tar -zxvf elasticsearch-6.7.2.tar.gz
6.2. 集群配置
tar -zxvf elasticsearch-6.7.2.tar.gz
标签说明(有个印象):
network.host: 0.0.0.0
discovery.zen.ping.unicast.hosts: ["192.168.122.128:9300", "192.168.122.130:9300", "192.168.122.131:9300"]
discovery.zen.minimum_master_nodes: 2
vim /app/elasticsearch-6.7.2/config/elasticsearch.yml
cluster.name: es-application
node.name: node-1
path.data: /app/elasticsearch-6.7.2/data
path.logs: /app/elasticsearch-6.7.2/logs
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.122.128:9300", "192.168.122.130:9300", "192.168.122.131:9300"]
discovery.zen.minimum_master_nodes: 2
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE

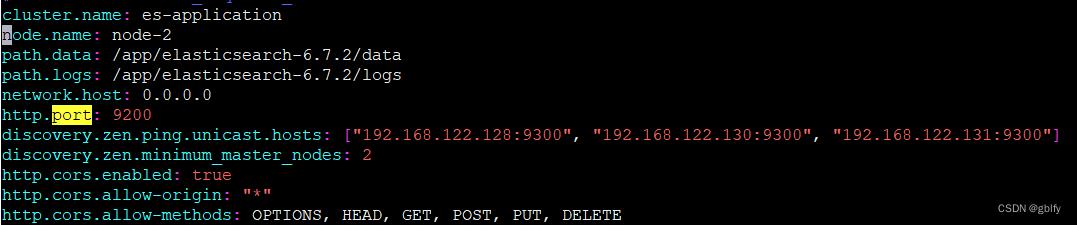
cluster.name: es-application
node.name: node-2`在这里插入代码片`
path.data: /app/elasticsearch-6.7.2/data
path.logs: /app/elasticsearch-6.7.2/logs
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.122.128:9300", "192.168.122.130:9300", "192.168.122.131:9300"]
discovery.zen.minimum_master_nodes: 2
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE
cluster.name: es-application
node.name: node-3
path.data: /app/elasticsearch-6.7.2/data
path.logs: /app/elasticsearch-6.7.2/logs
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.122.128:9300", "192.168.122.130:9300", "192.168.122.131:9300"]
discovery.zen.minimum_master_nodes: 2
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE

6.3. 修改系统参数
切换root用户修改系统参数,执行如下命令
- 解决:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
su - root
echo "vm.max_map_count=655360" >> /etc/sysctl.conf && /sbin/sysctl -p
- 解决:max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
vim /etc/security/limits.conf
新增配置以下内容
app hard nofile 65536
app soft nofile 65536
6.4. 依次启动es服务
第一次建议前台启动便于监控日志,快速定位
前台启动
cd /app/elasticsearch-6.7.2
bin/elasticsearch
后台启动
cd /app/elasticsearch-6.7.2
bin/elasticsearch -d
6.5. 监控es
tail -f logs/es-application.log
或者
ps -ef|grep es
七、安装nodejs
登录root用户,仅在131节点执行
7.1. nodejs下载解压重命名
wget https://nodejs.org/dist/v14.15.1/node-v14.15.1-linux-x64.tar.xz
tar -xvf node-v14.15.1-linux-x64.tar.xz
mv node-v14.15.1-linux-x64 nodejs
7.2. 建立软连接
ln -s /app/nodejs/bin/node /usr/local/bin/
ln -s /app/nodejs/bin/npm /usr/local/bin/
验证版本
node -v
7.3. 配置镜像仓库
npm install -g cnpm --registry=https://registry.npm.taobao.org
sudo ln -s /app/nodejs/bin/cnpm /usr/bin/cnpm
八、安装elasticsearch-head
仅在131节点执行
8.1. 下载
wget https://github.com/mobz/elasticsearch-head/archive/master.zip
8.2. 解压
unzip elasticsearch-head-master.zip
8.3. 拉取依赖
cnpm i
8.4. 配置
登录root用户,app.js配置文件
cd /app/elasticsearch-head-master/_site/
vim app.js
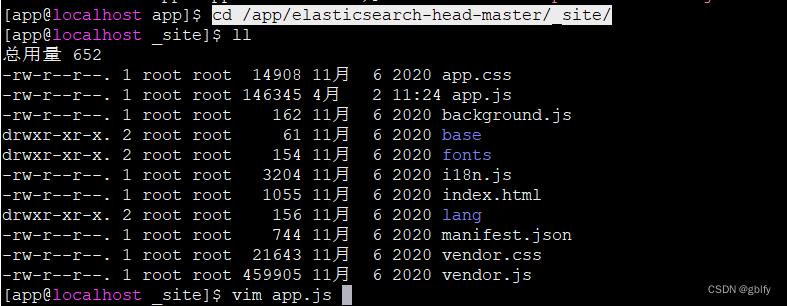
将localhost改成本机ip地址
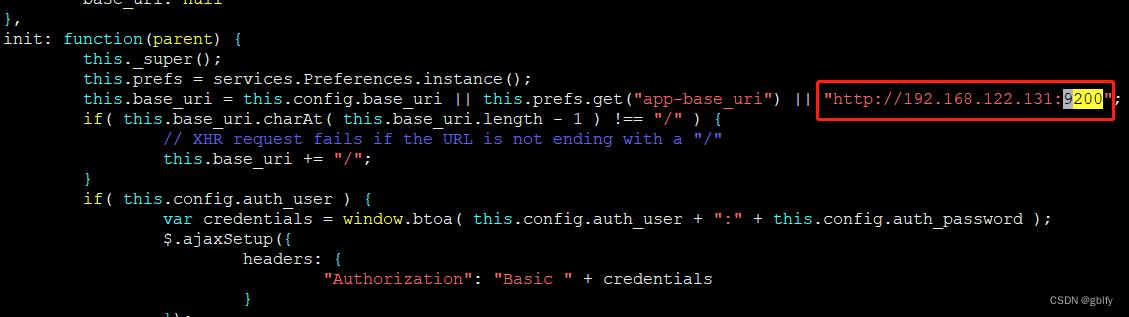
app.js配置文件
cd /app/elasticsearch-head-master/
vim Gruntfile.js
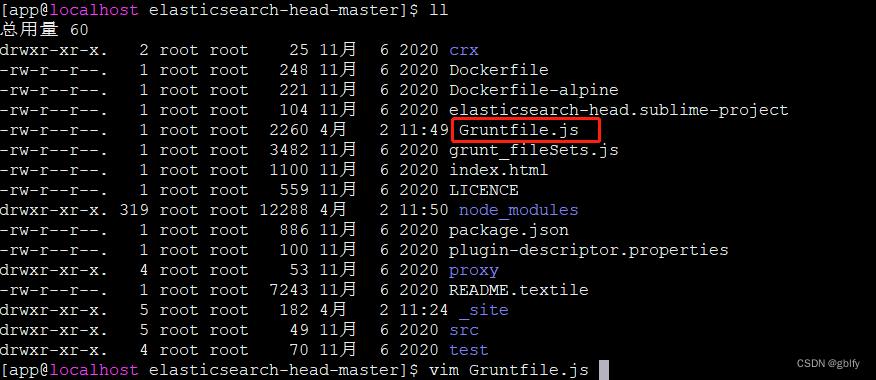
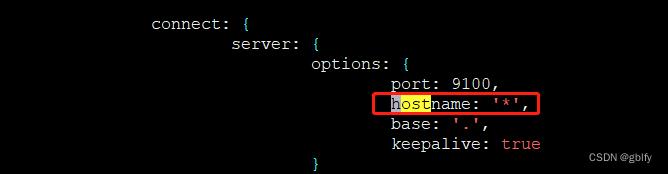
新增配置属性
hostname: '*',
8.5. 启动elasticsearch-head
cd到app/elasticsearch-head-master目录下,执行npm start或者grunt server启动,如果没有grunt则npm命令安装即可
cd /app/elasticsearch-head-master/
npm install -g grunt
ln -s /app/nodejs/bin/grunt /usr/local/bin/grunt
grunt server
8.6. 服务验证
http://192.168.122.131:9100/
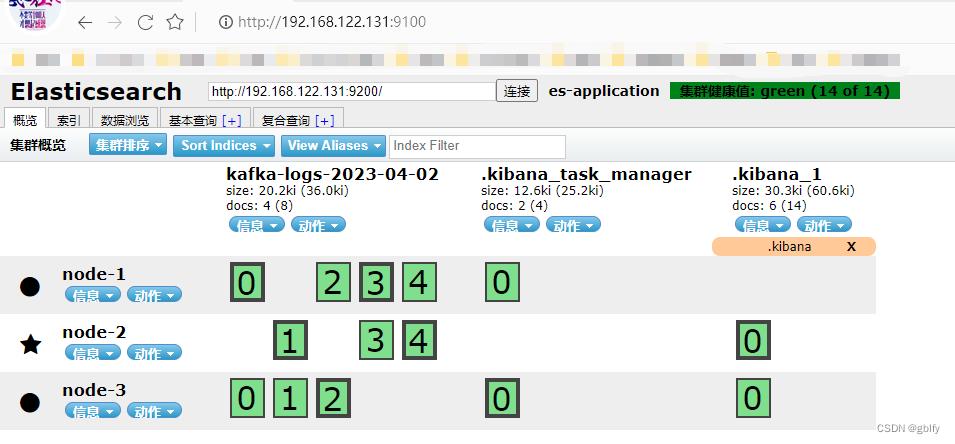
九、安装kibana
登录app用户,仅在128节点执行
9.1. 解压
tar -zxvf kibana-6.7.2-linux-x86_64.tar.gz
9.2. 修改配置
vim /app/kibana-6.7.2-linux-x86_64/config/kibana.yml
末尾添加如下配置:
server.port: 5601
server.host: "192.168.122.128"
elasticsearch.hosts: ["http://192.168.122.128:9200","http://192.168.122.130:9200","http://192.168.122.131:9200"]
elasticsearch.requestTimeout: 300000

9.3. 启动kibana
cd /app/kibana-6.7.2-linux-x86_64/
nohup bin/kibana &
验证kibana进程是否启动成功
http://192.168.122.128:5601/
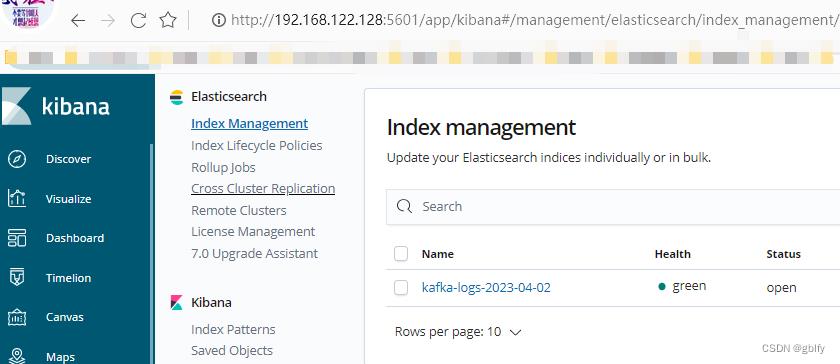
十、全链路调试
10.1. 添加日志内容
往128节点机器/app/test.log文件写入一行数字,之后查看es中是否可以查询到
echo "gblfy.com 6666" >> test.log
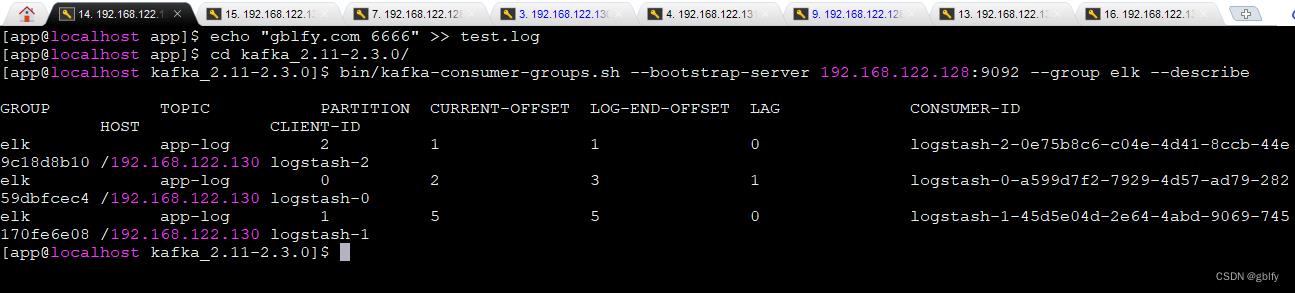
10.2. 查看消费者消费进展
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.122.128:9092 --group elk --describe
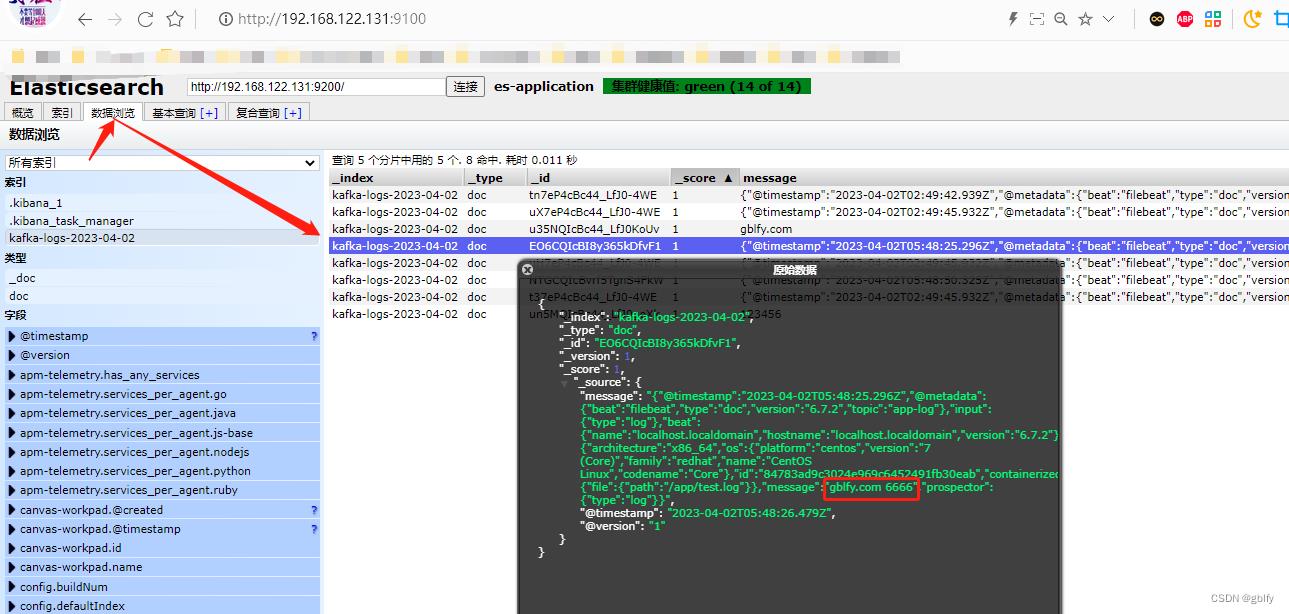
10.3. es查询日志信息
10.4. kibana查询日志信息
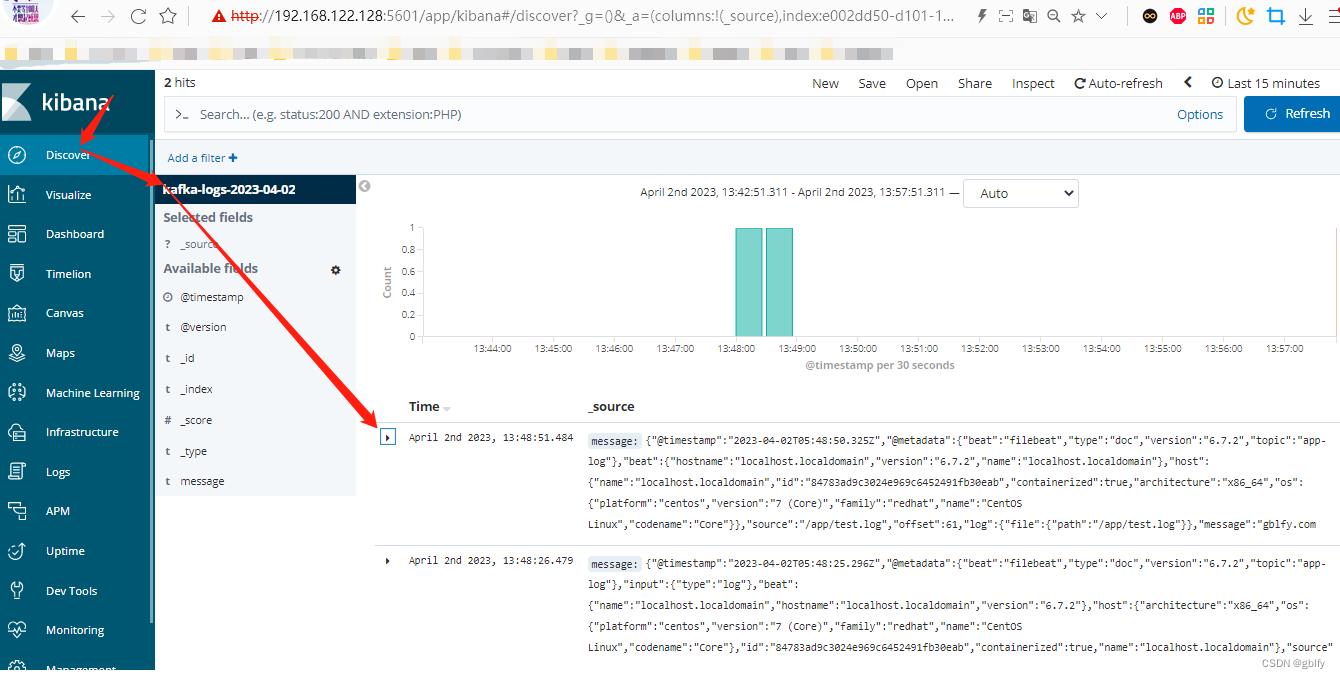
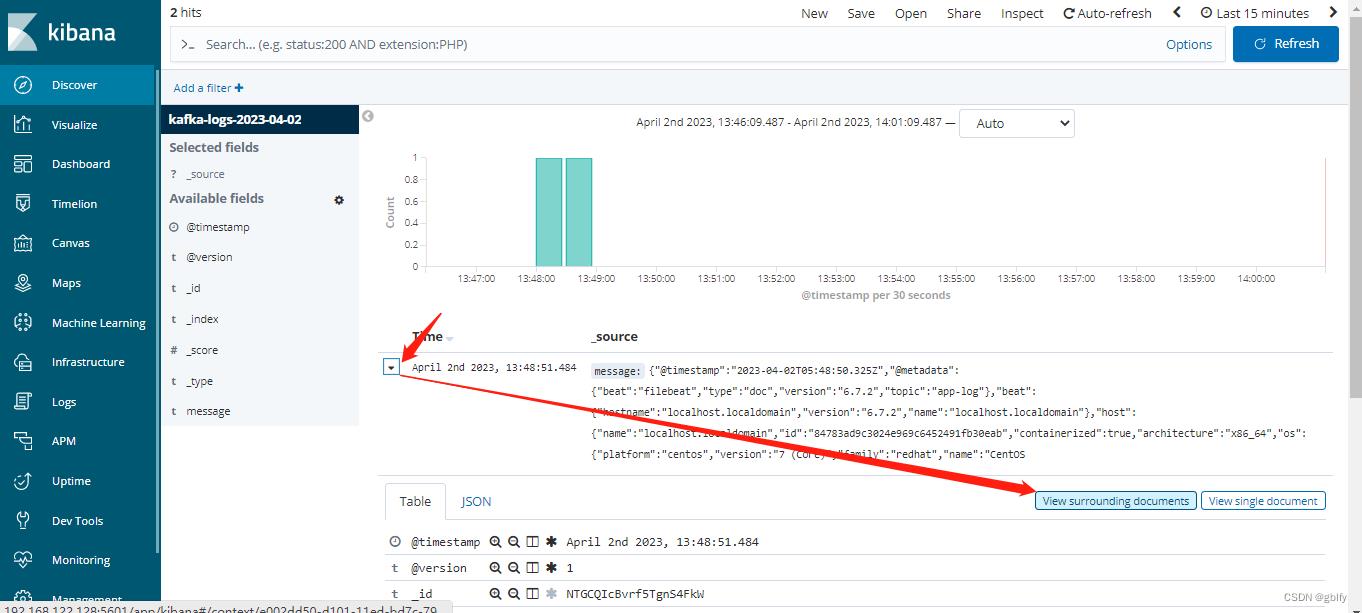
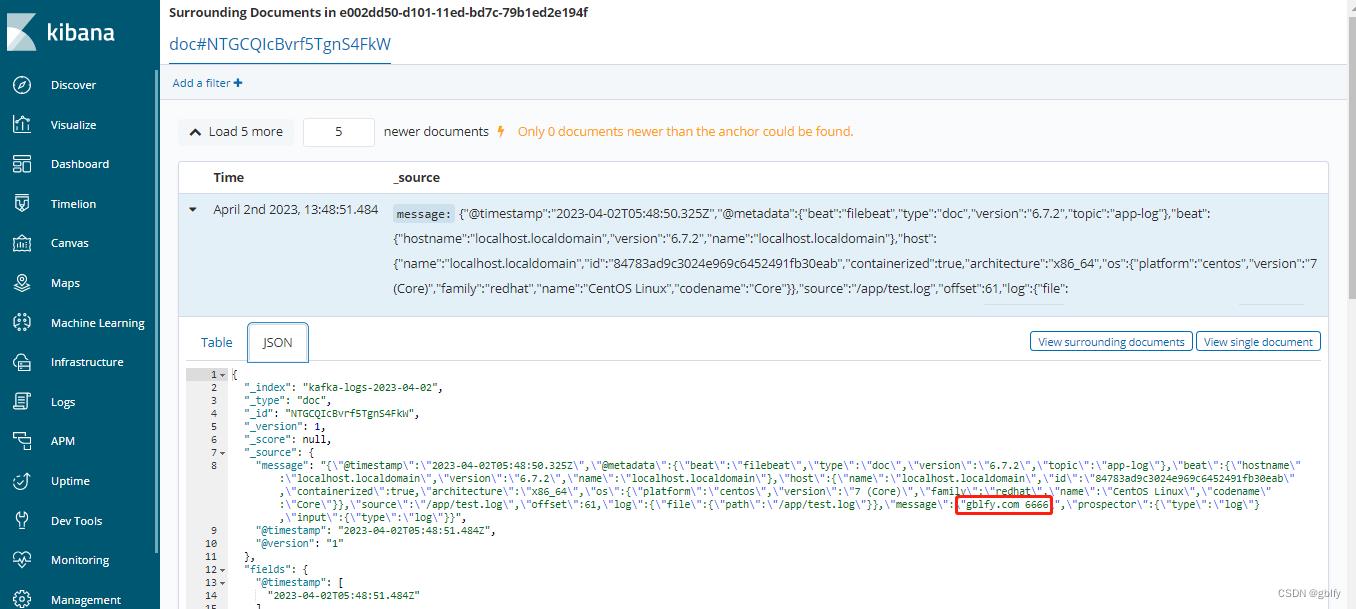
json格式化后
"_index": "kafka-logs-2023-04-02",
"_type": "doc",
"_id": "NTGCQIcBvrf5TgnS4FkW",
"_version": 1,
"_score": null,
"_source":
"message": "\\"@timestamp\\":\\"2023-04-02T05:48:50.325Z\\",\\"@metadata\\":\\"beat\\":\\"filebeat\\",\\"type\\":\\"doc\\",\\"version\\":\\"6.7.2\\",\\"topic\\":\\"app-log\\",\\"beat\\":\\"hostname\\":\\"localhost.localdomain\\",\\"version\\":\\"6.7.2\\",\\"name\\":\\"localhost.localdomain\\",\\"host\\":\\"name\\":\\"localhost.localdomain\\",\\"id\\":\\"84783ad9c3024e969c6452491fb30eab\\",\\"containerized\\":true,\\"architecture\\":\\"x86_64\\",\\"os\\":\\"platform\\":\\"centos\\",\\"version\\":\\"7 (Core)\\",\\"family\\":\\"redhat\\",\\"name\\":\\"CentOS Linux\\",\\"codename\\":\\"Core\\",\\"source\\":\\"/app/test.log\\",\\"offset\\":61,\\"log\\":\\"file\\":\\"path\\":\\"/app/test.log\\",\\"message\\":\\"gblfy.com 6666\\",\\"prospector\\":\\"type\\":\\"log\\",\\"input\\":\\"type\\":\\"log\\"",
"@timestamp": "2023-04-02T05:48:51.484Z",
"@version": "1"
,
"fields":
"@timestamp": [
"2023-04-02T05:48:51.484Z"
]
,
"sort": [
1680414531484,
1
]
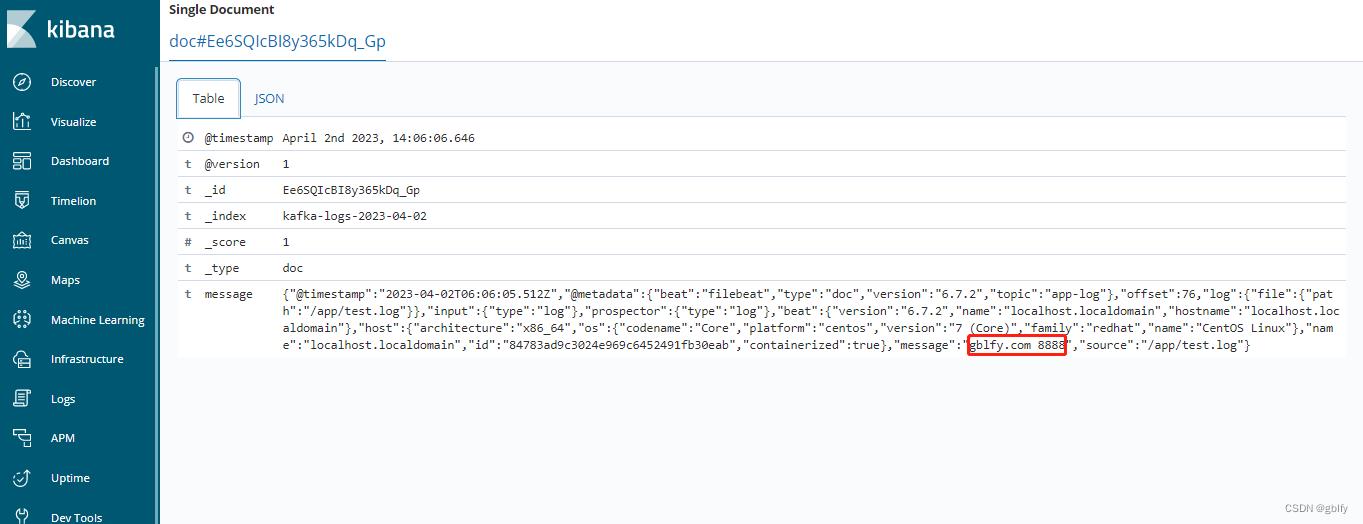
10.5. kibana查询日志信息2
往128节点机器/app/test.log文件写入一行数字,之后查看es中是否可以查询到
echo "gblfy.com 8888" >> test.log
登录kibana查询日志信息
使用Filebeat和Logstash集中归档日志
方 案
- Filebeat->Logstash->Files
- Filebeat->Redis->Logstash->Files
- Nxlog(Rsyslog、Logstash)->Kafka->Flink(Logstash->ES-Kibana)
- 其他方案(可根据自己需求,选择合适的架构,作者选择了第二种方案)
注释: 由于Logstash无法处理输出到文件乱序的问题,可通过不同的文件使用不同的Logstash;或者直接写入ES(不存在乱序问题)、通过Flink输出到文件
部 署
系统环境
- Debian8 x64
- logstash-6.1.1
- filebeat-6.1.1-amd64
- Redis-3.2
Filebeat配置
/etc/filebeat/filebeat.yml
filebeat.prospectors:
- type: log
paths:
- /home/data/log/*
- /home/data/*.log
scan_frequency: 20s
encoding: utf-8
tail_files: true
harvester_buffer_size: 5485760
fields:
ip_address: 192.168.2.2
env: qa
output.redis:
hosts: ["192.168.1.1:6379"]
password: "geekwolf"
key: "filebeat"
db: 0
timeout: 5
max_retires: 3
worker: 2
bulk_max_size: 4096
Logstash配置
input {
#Filebeat
# beats {
# port => 5044
# }
#Redis
redis {
batch_count => 4096
data_type => "list"
key => "filebeat"
host => "127.0.0.1"
port => 5044
password => "geekwolf"
db => 0
threads => 2
}
}
filter {
ruby {
code => ‘event.set("filename",event.get("source").split("/")[-1])‘
}
}
output {
if [filename] =~ "nohup" {
file {
path => "/data/logs/%{[fields][env]}/%{+YYYY-MM-dd}/%{[fields][ip_address]}/%{filename}"
flush_interval => 3
codec => line { format => "%{message}"}
}
} else {
file {
path => "/data/logs/%{[fields][env]}/%{+YYYY-MM-dd}/%{[fields][ip_address]}/logs/%{filename}"
flush_interval => 3
codec => line { format => "%{message}"}
}
}
#stdout { codec => rubydebug }
}
生产日志目录
├── prod
│ └── 2018-01-13
│ └── 2.2.2.2
│ ├── logs
│ │ ├── rpg_slow_db_.27075
│ └── nohup_service.log
└── qa
├── 2018-01-12
│ ├── 192.168.3.1
└── 2018-01-13
├── 192.168.3.2
以上是关于filebeat es logstash kibana kafka zookeeper 集群 全链路调试的主要内容,如果未能解决你的问题,请参考以下文章