论文导读Self-Supervised Learning with Data AugmentationsProvably Isolates Content from Style
Posted ViviranZ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文导读Self-Supervised Learning with Data AugmentationsProvably Isolates Content from Style相关的知识,希望对你有一定的参考价值。
Ref33……
“考希克等人。 [33] 提出了一种通过人在循环过程中进行数据增强的方法,在该过程中,给定一些文档及其(初始)标签,人类必须通过足以翻转标签的编辑来修改文本,从而生成反事实样本。重要的是,禁止进行不足以翻转适用标签的编辑。因此,它们生成负样本和正样本,允许对比学习作为表示学习的一种方法”
找到一篇比较浅的导读https://www.cnblogs.com/TABball/p/15474725.html摘要 本文针对的话题是关于使用反事实增强数据来提高模型效果,使用简单的因果模型结构来分析观测噪音对模型表现的影响,并且研究了两种自动生成反事实数据的方法和人为去生成有什么区别。 本文提出了一个猜想:  https://www.cnblogs.com/TABball/p/15474725.html
https://www.cnblogs.com/TABball/p/15474725.html
不太够 细节还是研究一下吧。
【摘要】
【背景&靶子】为了使机器学习模型不那么依赖于NLP数据集中的虚假模式,研究人员最近提出通过一种人在循环过程来管理反事实增强数据(CAD),在这个过程中,给定一些文档和它们的(初始)标签,人类必须修改文本,使反事实标签适用。重要的是,禁止对适用的标签进行不必要的编辑。从经验上看,在扩充的(原始的和修正的)数据上训练的模型更少地依赖于语义上不相关的单词,并更好地在域外推广。虽然这项工作松散地借鉴了因果思维,但潜在的因果模型(甚至在抽象水平上)和所观察到的域外改进的原则仍然不清楚。
【贡献】
1.在这篇文章中,我们介绍了一个基于线性高斯模型的玩具模拟,观察了因果模型、测量噪声、域外泛化和对假信号的依赖之间有趣的关系。我们的分析提供了一些见解,有助于解释CAD的疗效
2.我们提出了在因果特征中加入噪声会降低域内和域外性能的假设,而在非因果特征中加入噪声会导致域外性能的相对改善。这一想法激发了一种推测性测试,以确定特征归因技术是否确定了因果范围。如果向突出显示的跨度添加杂音(例如,通过随机的单词切换)会降低挑战数据集的域内和域外性能,但向补充数据集添加杂音会提高域外性能,这表明我们已经确定了因果跨度。
3.我们提出了一项大规模的实证研究,比较了在创建CAD时编辑的范围和通过注意力和显著性地图选择的范围。在众多的挑战领域和模型中,我们发现这种假设现象在CAD中非常明显。
我们分析了因果设置(特征导致标签)。当特征共享一个共同的原因,并且预测器是明确指定的(线性的),它将为非因果特征分配零权重(预期)。然而,当因果特征受到观测噪声(测量误差)影响时,非因果特征被赋予非零权重。相反,当我们在非因果特征上注入噪声时,预测器更多地依赖于因果特征,我们希望这能产生更好的域外泛化。
However, when the causal features are subject to observation noise (measurement error), the non-causal features are assigned non-zero weight. Conversely, when we inject noise on non-causal features, predictors rely more on causal features, which we expect to result in better out-of-domain generalization.
我们表明,在Kaushik et al.(2020)的原始1.7k IMDb评论上训练的SVM情感分析模型在IMDb测试集上获得87.8%的准确率,在Yelp评论上获得79.9%的准确率,但当所有的理据都被噪声取代时,分类器的样本内准确率下降≈11%,在Yelp上下降更大,达≈28.7%。但是,当用噪声代替非理据时,域内精度下降≈10%,域外精度提高1.5%。同样,在NLI中,当基本原理被噪声取代时,在e-SNLI (DeYoung et al., 2020)的子样本上微调的BERT分类器的精度下降约20%,而在各种数据集上的域外精度下降了21.3-31.5%。如果用噪声代替非基本原理,样本内精度将下降6.2%,而域外精度仅下降2.3-5.5%。在所有数据集和模型上,在两个任务中都可以观察到类似的模式。然而,当使用注意力面具时,导致的模特表现的变化似乎并没有遵循这些趋势。在另一项测试中,我们用风格转移方法将正面评价转换为负面评价,以探究人类反馈是否确实需要生成带有观察到的CAD定量结果的数据集。与在styletransfer增强数据上训练的SVM分类器相比,在CAD上训练的准确率在Amazon上提高了5-16.4%,在Yelp上提高了3.7-17.8%。类似地,在CAD上微调的BERT分类器在Amazon上的性能比在样式转移增强数据上微调的同类分类器高出4.9-21.5%,在Yelp上高出1.9-9.5%。 【一些小实验,翻译成中文也感觉不是人话= =其实就是做了一些OOD泛化的实验,结果符合他们的假设——在因果特征加噪声影响样本内外的准确度,但是非因果特征增噪声只影响样本内准确度,样本外准确度还更高了】
重点看一下第四部分的实验吧……这篇感觉好计算机
4. Empirical experiment
如果人类通过编辑或突出显示标记为基本原理的跨度类似于因果特征,那么对这些跨度进行噪声处理会导致模型更多地依赖于非因果特征,从而在域外数据上表现更差,而对未标记的跨度(类似于非因果特征)进行噪声处理则会产生相反的行为。在本节中,我们将在真实世界的数据集上对这些假设进行实证检验。此外,我们还调查了来自人类工作者的反馈是否产生了与使用自动特征归因方法(如注意力和显著性)标记的跨度在质量上有所不同的结果。类似地,我们首先要问的是,CAD是否比通过文本样式转移算法实验实现的自动情感翻转方法具有定性优势。
我们对情感分析进行了实验(Zaidan等,2007;Kaushik等人,2020)和NLI (DeYoung等人,2020)。所有的数据集都伴随着人类的反馈(标记被认为与标签的适用性相关),我们称之为rationales。在第一组实验中,我们依赖于四种模型:支持向量机(SVMs)、带有自我注意的双向长短时记忆网络(BiLSTMs) (Graves & Schmidhuber, 2005)、BERT (Devlin等人,2019)和Longformer (Beltagy等人,2020)。对于第二组实验,我们依靠代表不同方法的4个最先进的风格转移模型,每个代表不同的方法来自动生成带有翻转标签的新示例(Hu等人,2017;Li等人,2018;Sudhakar等人,2019年;Madaan等人,2020年)。为了评估分类器在增强数据上的性能,我们考虑了支持向量机、朴素贝叶斯(NB)、带有自我注意的BiLSTMs和BERT。我们将实现细节放在附录B中。
对于情感分析,我们使用SVM, BiLSTM和Self - Attention, BERT和Longformer模型。在每个文档中,我们用从词汇表中抽样的随机标记替换一部分基本(或不基本)【rationale (or non-rationale)】标记,并训练我们的模型,重复这个过程5次。我们使用BERT对NLI进行了类似的实验。由于一个独立的前提-假设配对通常没有电影评论那么长,许多配对只有一两个词作为基本原理。为了观察逐渐向基本原理或非基本原理注入噪声的影响,我们只选择那些至少有10个标记为基本原理的前提-假设对。由于不存在具有10个或更多基本令牌的中性对,我们只考虑一个二元分类设置(暗含-矛盾),并对大多数类进行下采样,以确保50:50的标签分裂。
图2和3显示了5次运行后平均准确率的差异。对于所有分类器,随着基本原理噪声的增加,样本内精度相对于域外精度保持相对稳定。在Kaushik et al.(2020)的原始1.7k IMDb评论上训练的SVM分类器在IMDb测试集上获得87.8%的准确率,在Yelp评论上获得79.9%的准确率随着更大比例的基本原理被词汇表中的随机单词取代,当所有基本原理符号被噪声取代时,分类器体验到约11%的下降。然而,它在Yelp评论上的准确率下降了28.7%。类似地,在相同的数据集上,一个微调的BERT分类器发现它的样本内准确率下降了18.4%,在Yelp上下降了31.4%,因为基本代币被噪声取代,从0到100%。然而,随着更多的非理据被噪声取代,SVM的样本内准确率下降≈10%,但在Yelp上上升了1.5%。对于BERT,样本内准确率仅下降16.1%,Yelp上仅下降13.6%(参见附录表3和附录图4a)。
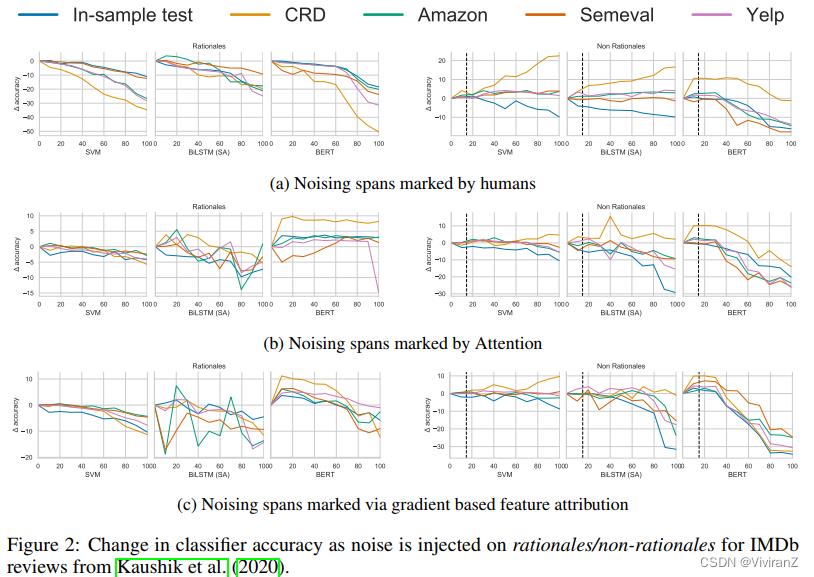

我们使用特征反馈识别的原理获得了类似的结果。根据Zaidan等人(2007)的评论训练的SVM分类器发现,当在基本原理中插入噪音时,样本内准确率下降了11%,在Yelp上的准确率下降了16.9%,但当在非基本原理中插入噪音时,准确率分别下降了17.3%和14.6%。对于Longformer来说,当在不合理的理由中插入噪音时,样本内准确率下降了14%,Yelp上的准确率下降了26.4%,而分别下降了17.3%和3.9%。在数据集和模型中可以观察到类似的模式(参见图3a、附录表6和附录图5a)。
对于NLI,当基本理论被噪声取代时,在SNLI子样本上微调的BERT的样本内精度下降约20%,在各种数据集上的域外精度下降21.3-31.5%(表10)。然而,如果用噪声代替非基本原理,样本内精度下降6.2%,而域外精度仅下降2.3-5.5%。这些结果支持了我们的假设,即被人类标记为引起标签的跨度与因果变量类似。
有趣的是,在我们的NLI实验中,对于各种模型,当在基本原理中注入噪声时,与在非基本原理中注入噪声相比,样本内和域外精度的下降幅度更大。这与我们在情感分析中观察到的情况相反。我们推测这些结果是由于在我们的NLI实验设计中,我们只保留那些包含至少10个标记作为基本原理的前提-假设对,这样我们就可以观察到随着噪声量的增加准确度的差异。这种选择的一个结果是,许多被选中的配对有更多标记为理性的代币,而不是非理性的代币,然而,在情绪分析中,这是相反的。因此,在NLI中,当一些比例的基本原理被噪声取代时,这比当相应比例的非基本原理被噪声取代时对应更多的编辑标记。
为了将人类反馈与自动特征归因方法(如注意(Bahdanau等,2015)和基于梯度的显著性方法(Li等,2016))进行比较,我们进行了相同的一组实验,假设标记被基于注意的分类器(带有自我注意的BiLSTM)关注(或不关注),或被基于梯度的特征归因方法(显著性分数)识别为具有重要影响的新依据(或非依据)。在这种情况下,与我们对人类反馈的发现不同,我们观察到的行为明显不同于我们对玩具因果模型的分析所预测的行为(参见图2b、2c、3b和3c;和附录表4、5、7、8)。
虽然我们可能不期望伪信号在域外同样可靠,但这并不意味着它们总是会失败。例如,虽然从书评数据集中获得的类型和情感之间的联系可能无法在厨房电器数据集中得到,但在有声书评数据集中仍然存在。在这种情况下,即使噪声化的非因果特征会导致模型更多地依赖于因果特征,这可能不会导致更好的域外性能。
我们还会考虑是否真的需要通过收集CAD(或人类注释的原理)的过程,或者自动生成“反事实”的方法是否可能在域外性能方面获得类似的收益,因为前者可能是一个昂贵的过程。我们尝试使用最先进的风格转换方法,将正面评价转换为负面评价,反之亦然。理想情况下,我们期望这些方法在修改与情感相关的属性(如果它们在特征空间中获得完美解纠缠)时保留文档的“内容”。与只训练相同大小的原始数据(表2)相比,在使用风格转移方法生成的原始评论和情感翻转评论上训练的情感分类器往往能给出更好的域外性能(表2)。然而,在CAD上训练的模型在所有数据集上的表现甚至更好,这暗示了人类反馈的价值。
5、结论
虽然之前的工作提供了通过人在循环机制生成CAD的好处的有希望的线索,但之前的工作缺乏思考该技术的正式框架,或与可信的替代方案的比较。在本文中,通过对玩具线性高斯模型的简单分析,以及对情感分析和NLI任务的大规模实证调查,我们将CAD形式化,并对理解其实际功效采取了一些初步步骤。我们的分析表明,将噪声添加到基本区间(类似于将噪声添加到因果特征)会损坏数据,将降低域外性能,而将噪声添加到非因果特征可能会使模型在域外更健壮。我们的实证研究侧重于情感分析和NLI,我们的发现在不同的数据集和模型中保持一致。此外,这两个任务在主观上是非常不同的,因为情感分析需要强烈考虑表达的意见比陈述的事实,而NLI是相反的。我们还表明,模型训练的原始数据和修订数据生成的扩大
【这一篇重点在于验证自己的假设:在因果特征中加入噪声会降低域内和域外性能的假设,而在非因果特征中加入噪声会导致域外性能的相对改善。但是没有给出相对完整的方法,怎么找到因果特征?域外性能改善的认为是因果特征吗?……】
以上是关于论文导读Self-Supervised Learning with Data AugmentationsProvably Isolates Content from Style的主要内容,如果未能解决你的问题,请参考以下文章
《PackNet:3D Packing for Self-Supervised Monocular Depth Estimation》论文笔记
《MonoDepth2:Digging Into Self-Supervised Monocular Depth Estimation》论文笔记
经典图推荐系统论文Self-supervised Graph Learning for Recommendation算法及代码简介
论文解读:SuperPoint: Self-Supervised Interest Point Detection and Description
《MonoIndoor:Towards Good Practice of Self-Supervised Monocular Depth Estimation...》论文笔记