pandas导出和复制excel的相关设置
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas导出和复制excel的相关设置相关的知识,希望对你有一定的参考价值。
参考技术A import pandas as pdimport glob
file=[ ]
file_location=glob.glob(r'./*.xlsx')
for filename in file_location:
file.append(filename)
print(filename)
res=pd.read_excel(file[0])
for i in range(1,len(file)):
a=pd.read_excel(file[i])
res=pd.concat([res,a],ignore_index=True,sort=False)
print(res.head())
writer=pd.ExcelWriter('all.xlsx') # 如果 all.xlsx存在,则打开;反之,新建all.xlsx,再打开
res.to_excel(writer,'sheet1',index=False,header=None) #忽略 index;忽略列名,不是 column=False
writer.save()
writer_1=pd.ExcelWriter('bll.xlsx') #创建新excel文件
b=pd.read_excel('all.xlsx',sheet_name='sheet1')
b.to_excel(writer_1,'sheet1') #写入'sheet1'中
t=pd.read_excel('test1.xlsx',sheet_name='Sheet1')
t.to_excel(writer_1,'sheet2',index=False,header=None) #写入'sheet2'中,设置参数
writer_1.save()
进阶学python之 pandas系列之导出为.csv文件
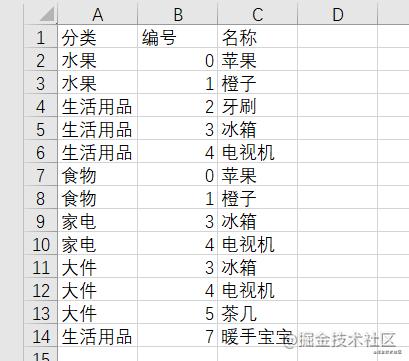
本文所用表格内容如下:
本文所用表格内容如下: 商品信息表
1.设置导出路径
和前面保存为.xlsx差不多,只是.csv文件的路径是通过path_or_buf参数设置的
import pandas as pd
goods_df = pd.read_excel(r'C:\\Users\\viruser.v-desktop\\Desktop\\商品信息表.xlsx')
goods_df.to_csv(path_or_buf='test.csv')
复制代码保存前:
保存后:
注意事项和导出.xlsx文件的注意事项一致.如果同一导出文件已经在本地打开,则不能再次运行导出代码,需要将本地文件关闭以后再次运行导出代码。
2.设置索引
上面导出文件中关于索引的参数都是默认的,也就是没有对索引有什么限制,但是我们可以看到index索引使用的是从0开始的默认自然数索引,这种索引可以通过设置参数index=False在导出时去掉该索引、
goods_df = pd.read_excel(r'C:\\Users\\viruser.v-desktop\\Desktop\\商品信息表.xlsx')
goods_df.to_csv(path_or_buf='test.csv', index=False)
复制代码设置前:
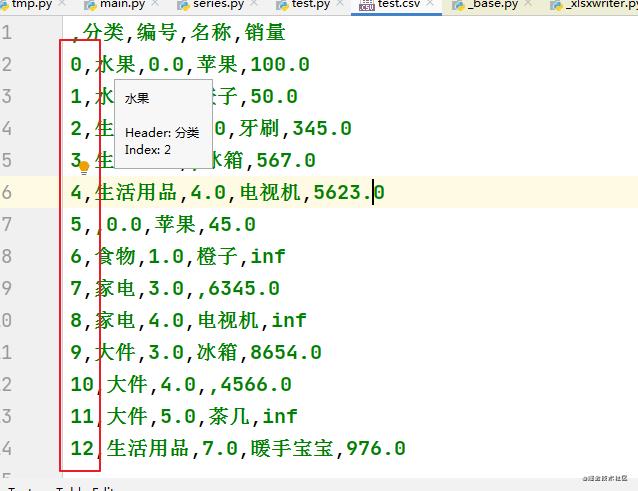
设置后:

3.设置要导出的列
有的时候一个表的列数很多,只需要导出部分列的内容。这个时候可以通过设置columns参数来指定要导出的列
goods_df = pd.read_excel(r'C:\\Users\\viruser.v-desktop\\Desktop\\商品信息表.xlsx')
goods_df.to_csv(path_or_buf='test.csv', index=False,columns=['分类', '名称'])
复制代码设置导出列之前:
设置导出列之后:

4.设置分隔符号
分隔符号就是用来指明导出文件中的字符之间是用什么来分隔的,默认使用逗号分隔,常用的分隔符号还有空格、制表符、分号等。分隔符号使用参数sep来指定
import pandas as pd
goods_df = pd.read_excel(r'C:\\Users\\viruser.v-desktop\\Desktop\\商品信息表.xlsx')
goods_df.to_csv(path_or_buf='test.csv', index=False,columns=['分类', '名称'], sep=';')
复制代码
5.缺失值处理
虽然数据预处理阶段已经有缺失值的处理了,但是数据分析过程中可能也会产生缺失值,所以导出时仍然需要处理缺失值。
goods_df = pd.read_excel(r'C:\\Users\\viruser.v-desktop\\Desktop\\商品信息表.xlsx')
goods_df.to_excel(excel_writer='test.xlsx', sheet_name='测试文件', index=False, columns=['分类', '名称'], encoding='utf-8',
na_rep=0)
复制代码原始表格

缺失值处理后:
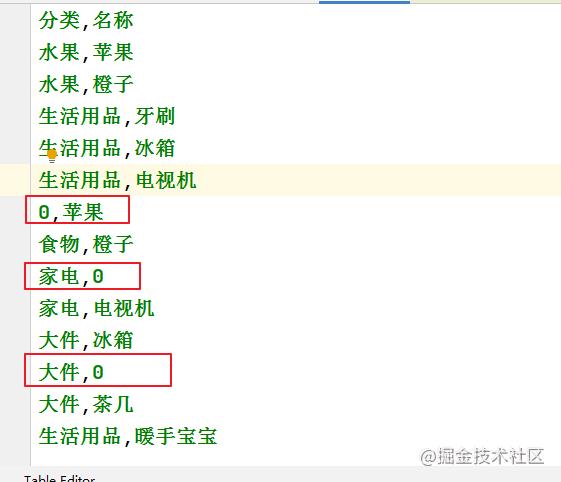
6.设置编码格式
python3中,导出为.csv文件时,默认编码为UTF-8.如果使用默认的utf-8编码格式,导出的文件在本地电脑打开以后中文会乱码,所以一般使用utf-8-sig或者gbk编码
goods_df = pd.read_excel(r'C:\\Users\\viruser.v-desktop\\Desktop\\商品信息表.xlsx')
goods_df.to_excel(excel_writer='test.xlsx', sheet_name='测试文件', index=False,columns=['分类', '名称'], enc参考文献
github.com/dothinking/…
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
需要相关资料的可以通过扫一扫

以上是关于pandas导出和复制excel的相关设置的主要内容,如果未能解决你的问题,请参考以下文章
django+uwsgi+nginx+pandas 导出excel超时问题
Python中将pandas的dataframe拷贝到剪切板并保持格式实战:to_clipboard()函数复制到Excel文件复制到文本文件(默认是tsv格式)复制到文本文件(设置逗号分隔符)