「模块化安装」,定义你自己的CloudQuery
Posted BinTools图尔兹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「模块化安装」,定义你自己的CloudQuery相关的知识,希望对你有一定的参考价值。
众所周知,「用户体验」除了在UI上的高互动性、操作便捷性之外,更关键的是系统的性能体验。而性能的决定参数是系统吞吐量和响应速度。在 PC 机时代我们往往通过提升系统的硬件来强行拉高系统响应水平,但硬件不可能永无止境地扩展,早在 2005 年,芯片大厂因特尔 CEO 就提出仅依靠硬件垂直提升系统性能的时代早已经过去,「分布式」成为当前效率改革的主流。
「分布式系统」是指在单台服务器无法承受访问和数据处理压力的情况下,引申出的将应用系统进行服务拆解,利用更多服务器完成共同任务以处理巨量数据。故而分布式应用在面对高并发、大数据量的处理要求时往往比中心化服务表现的更加优秀,同时自身的高可扩展性支持水平和弹性伸缩,使应用系统在面对尖峰流量时也得心应手。
CloudQuery 作为企业数据库管控平台,除内部人员频繁的访问请求外,平台自身服务也有很大的资源需求。例如审计服务,在流式处理数据的同时还需要实时输出维度分析报表、预警风险信息等。而 1.4.0 版本新增的 DTS 服务则需要以更高的速度来处理用户数据导入、导出等操作。针对以上情景,我们采用了分布式部署方案,将高资源、高消耗、高计算的服务进行独立部署,在提高性能和响应速度的同时不影响主体标准服务的请求处理。
同时,安装方式由原来「一刀切」式的安装调整为「模块化」安装。所谓「模块化安装」就是封装细节、服务拆解,彼此互不影响,每个模块实现各自特定功能,极大降低了服务耦合度,以最少的模块和零部件快速满足个性化安装需求。
「模块化安装」方式已调整至 CloudQuery v1.4.1,以页面化的方式选择安装模块,下载解压安装包成功后使用命令行授权脚本执行权限。
chmod +x install //授权安装
授权成功后,执行命令启动预安装服务:
./install
预安装服务启动成功后会返回预安装页面地址,将该地址复制至浏览器即可进入「模块化安装」界面进行自定义配置安装,自定义配置主要包含四块:基础模块、可选模块、可选数据源和系统配置。
首先基础模块包括了用户、查询、任务中心、通知、web、以及平台持久层数据存储服务,可针对当前 CloudQuery 所有基础镜像进行自定义端口配置(如下图)。

对于「可选模块」,用户可根据自身场景进行选择,内容包括:审计、任务中心和终端。
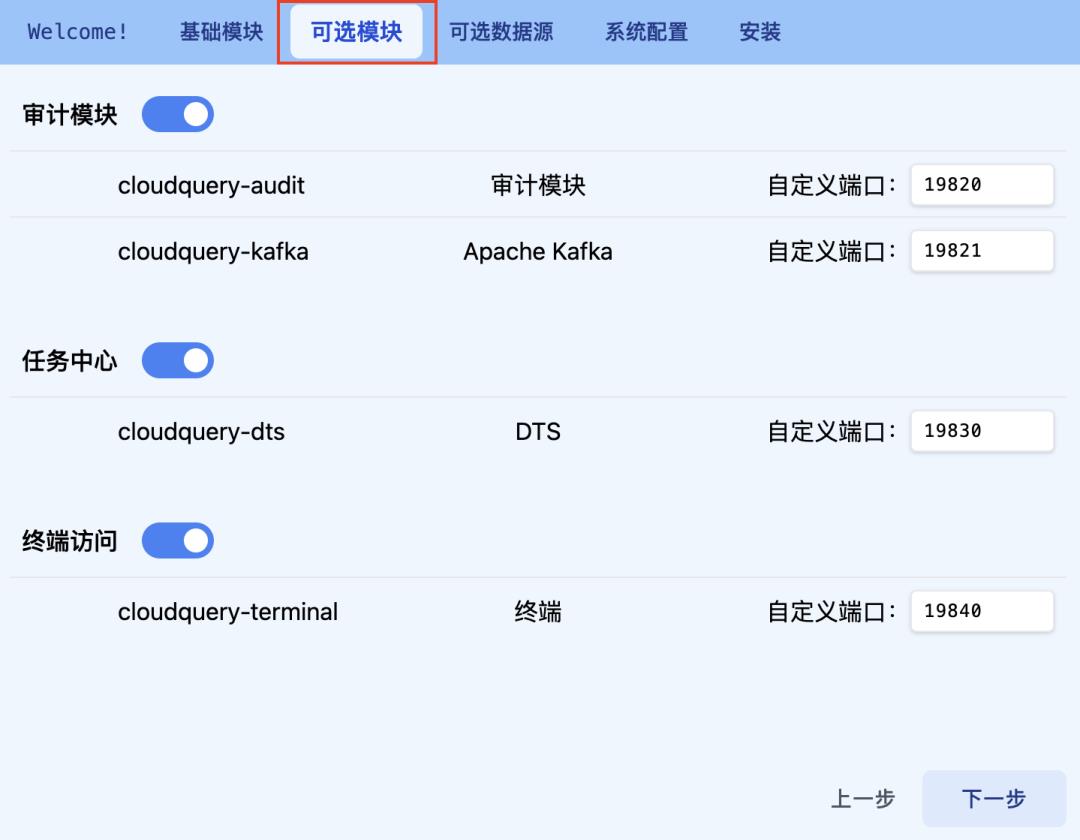
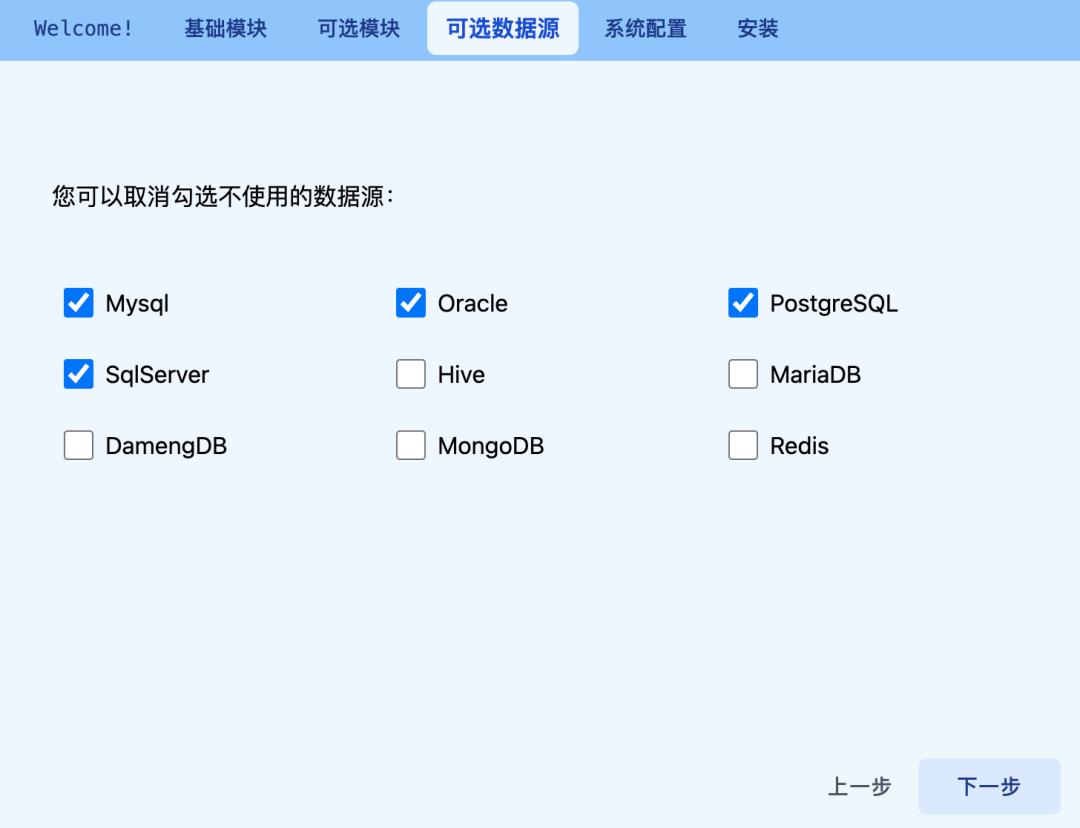
完成「可选模块」后可选择所需数据源类型。
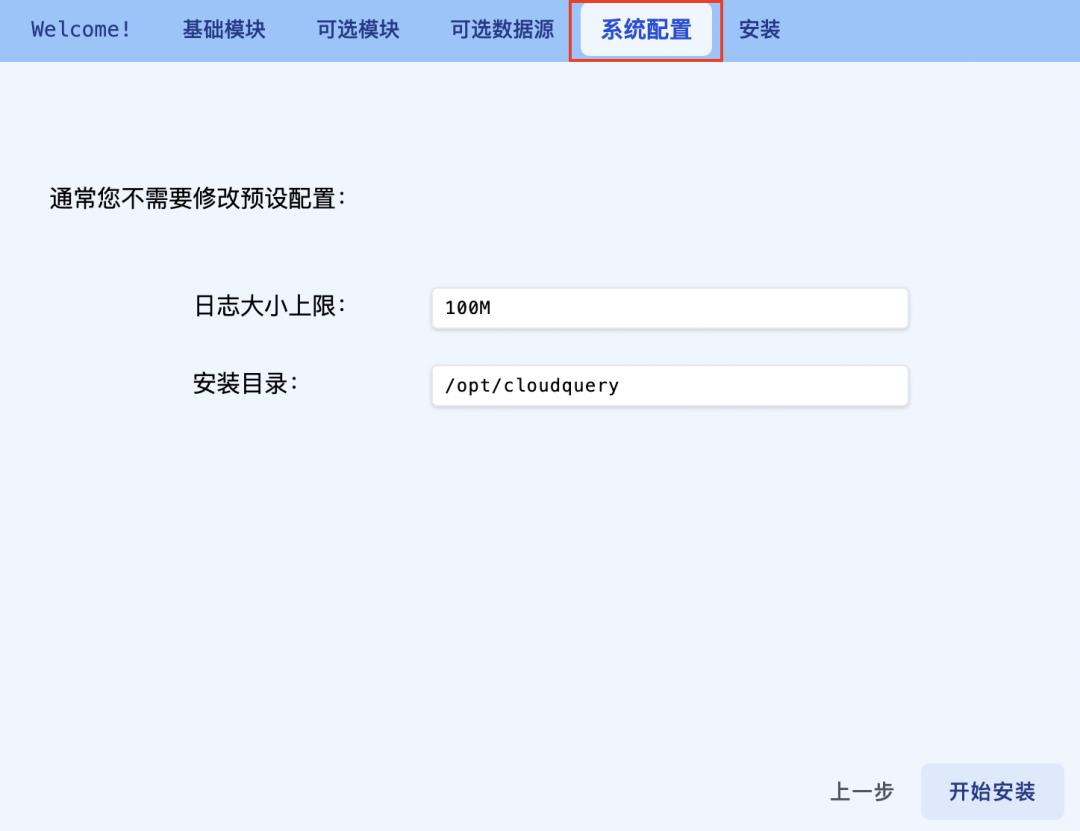
所有功能性配置完成后可进行「系统配置」,包括安装路径以及日志上限。
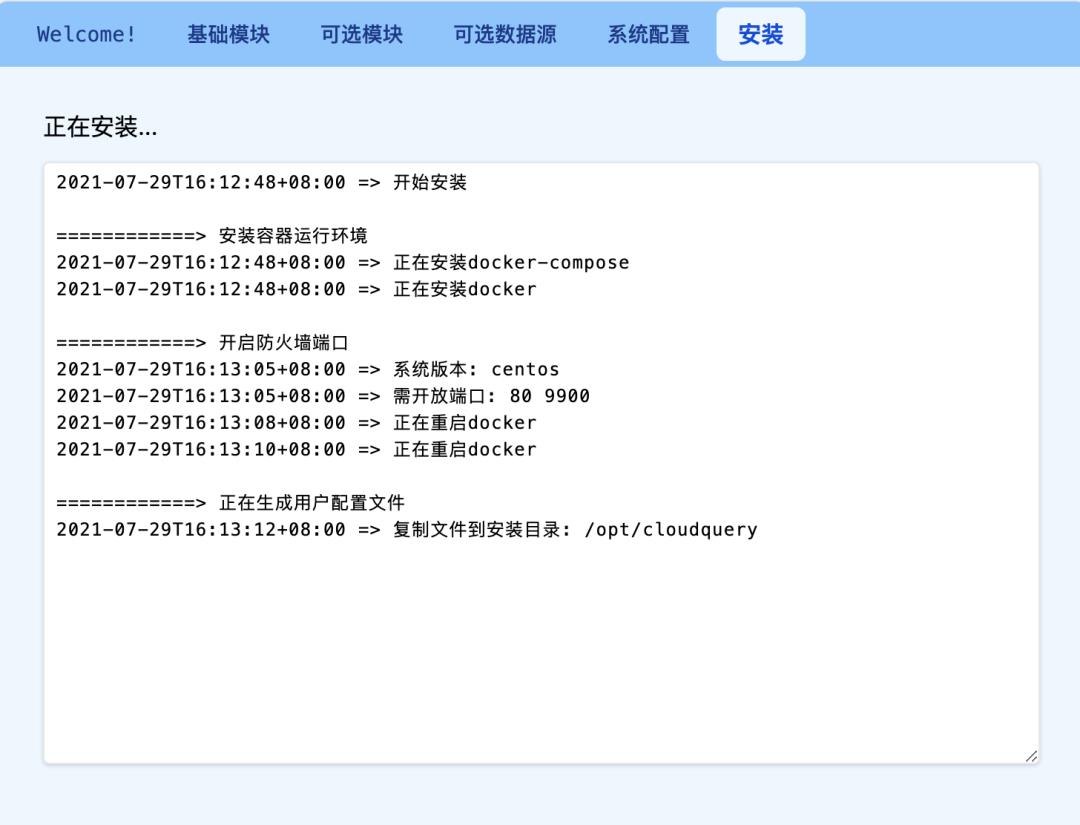
以上全部配置项配置完毕后即进入自动安装过程,进度框中可实时查看当前安装进度,过程中遇到问题可及时定位并解决。
此次安装方式升级后,CloudQuery 会在现有的标准服务上继续迭代。完善自身平台功能,不断推出更多数据相关模块,助力企业内部数据操作更加便捷化、自动化,使开发、运维人员效率提速。
BTW,8月31日,我们将进行 CloudQuery v1.4.2 答疑直播,为大家讲解演示近两个版本更新的核心功能,包括 OpenAPI、模块化安装、数据导入、新增数据源 PolarDB 等。同时,就近期社区同学提出较多的问题进行公开答疑,并排布迭代计划。


以上是关于「模块化安装」,定义你自己的CloudQuery的主要内容,如果未能解决你的问题,请参考以下文章