第二节:半监督聚类之AP(Affinity Propagation)聚类(近邻传播聚类)
Posted 快乐江湖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第二节:半监督聚类之AP(Affinity Propagation)聚类(近邻传播聚类)相关的知识,希望对你有一定的参考价值。
文章目录
一:基本思想
近邻传播聚类(Affinity Propagation Clustering, AP聚类):基本思想是将全部数据点都当作潜在的聚类中心(exemplar),然后数据点亮亮之间连线构成一个网络(相似度矩阵),再通过网络中各条边的消息(responsibility和availability)传递计算出各样本的聚类中心
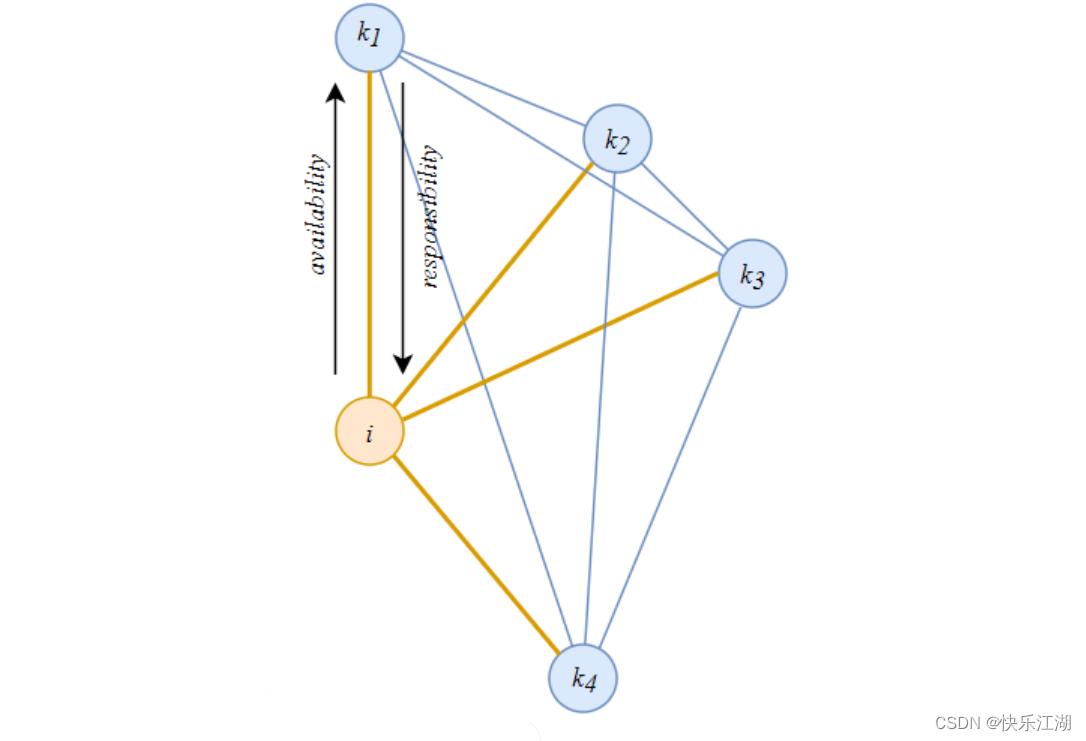
此过程中,共有如下两种消息在各节点之间传递
- 吸引度(responsibility):对于 r ( i , k ) r(i,k) r(i,k)而言,用于定量描述样本 k k k作为样本 i i i的聚类中心的程度
- 归属度(availability):对于 a ( i , k ) a(i,k) a(i,k)而言,用于定量描述样本 i i i支持样本 k k k作为其聚类中心的程度
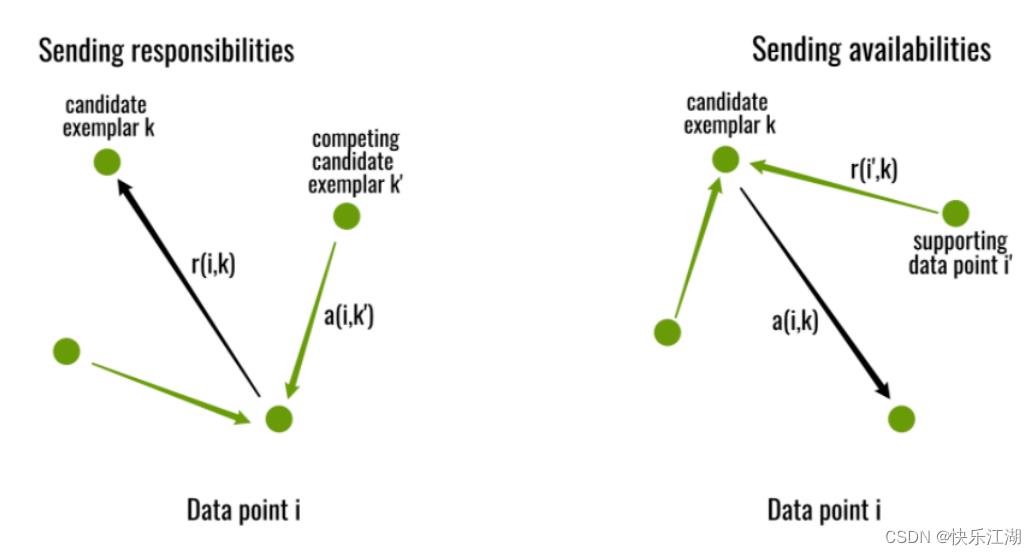
吸引度和归属度会分别形成吸引度矩阵和归属度的矩阵,然后算法会不断迭代更新两个矩阵
二:相关定义及术语
(1)相似度 Similarity
相似度(Similarity):对于数据点 i i i和 k k k,使用 s ( i , k ) s(i,k) s(i,k)描述两点之间的相似度,反映出了 j j j作为 i i i的聚类中心能力的大小,采用欧氏距离负值表示。 s ( i , k ) s(i,k) s(i,k)值越大就表示 i i i, j j j之间距离越近,也即 j j j作为 i i i的聚类中心的能力越强
s ( i , k ) = − ∣ ∣ x i − x k ∣ ∣ 2 s(i,k)=-||x_i-x_k||^2 s(i,k)=−∣∣xi−xk∣∣2
(2)相似度矩阵
相似度矩阵:作为算法的初始化矩阵, n n n个点就有由 n n n× n n n个相似度组成的矩阵
(3)偏好参数 Preference
偏好参数Preference:相似度矩阵中,主对角线上的值理论上为0,但是为了后续更好的应用相似度来更新吸引度和归属度,所以引入了该参数,用于定义相似度矩阵主对角线上的值。偏好参数越大说明各数据点成为聚类中心的能力越强,最终聚类中心的个数也就越多。偏好参数一般设置为相似度矩阵中所有值的最小值或中位数
(4)吸引度和归属度
吸引度(responsibility):对于 ( i , k ) (i,k) (i,k)而言,用于定量描述样本 k k k作为样本 i i i的聚类中心的程度
r ( i , k ) ← s ( i , k ) − m a x k 丶 s . t . k 丶 ≠ k a ( i , k 丶 ) + s ( i , k 丶 ) r(i,k)\\leftarrow s(i,k)-\\mathopmax\\limits_k^丶s.t. k^丶\\not=k\\a(i,k^丶)+s(i,k^丶)\\ r(i,k)←s(i,k)−k丶s.t.k丶=kmaxa(i,k丶)+s(i,k丶)
- a ( i , k 丶 ) a(i,k^丶) a(i,k丶)表示除 k k k外其他点对 i i i的归属度,初始值为0
- s ( i , k 丶 ) s(i,k^丶) s(i,k丶)表示除 k k k外其他点对 i i i的相似度
- r ( i , k ) r(i,k) r(i,k)值大于0,表示数据点 k k k成为聚类中心的能力强。但是注意此时只考虑哪个点 k k k成为点 i i i的聚类中心可能性最大,但是没有考虑整个吸引度最大的 k k k是否也经常成为其他点的聚类中心
归属度(availability):对于 a ( i , k ) a(i,k) a(i,k)而言,用于定量描述样本 i i i支持样本 k k k作为其聚类中心的程度
a ( i , k ) ← m i n 0 , r ( k , k ) + ∑ i 丶 s . t . i 丶 ∉ i , k m a x 0 , r ( i 丶 , k ) a(i,k)\\leftarrow min\\0,r(k,k)+\\sum\\limits_i^丶s.t. i^丶\\notin\\i,k\\max\\0,r(i^丶,k)\\ a(i,k)←min0,r(k,k)+i丶s.t.i丶∈/i,k∑max0,r(i丶,k)
a ( k , k ) ← ∑ i 丶 ≠ k m a x ( 0 , r ( i 丶 , k ) a(k,k) \\leftarrow \\sum\\limits_i^丶\\not=kmax(0,r(i^丶,k) a(k,k)←i丶=k∑max(0,r(i丶,k)
- r ( i 丶 , k ) r(i^丶,k) r(i丶,k)表示点 k k k作为除 i i i外其他点的聚类中心的相似度值,取所有大于等于0的吸引度值,加上 k k k作为聚类中心的可能程度。即点 k k k在这些吸引度值大于0的数据点的支持下,数据点 i i i选择 k k k作为其聚类中心的累积证明
r ( i , k ) + a ( i , k ) r(i, k)+a(i,k) r(i,k)+a(i,k)越大,则 k k k点作为聚类中心的可能性就越大,并且 i i i点隶属于以 k k k点为聚类中心得的聚类可能性也就越大
(5)阻尼系数 Damping factor
阻尼系数 Damping factor:为防止数据振荡,引入阻尼系数,每个信息值等于前一次更新的信息值的 λ \\lambda λ倍加上此轮更新值的 1 − λ 1-\\lambda 1−λ倍( λ \\lambda λ位于0-1之间,默认为0.5)
三:算法流程
(1)专业描述
- 给定数据集 D D D
- 计算相似度矩阵,并且设置偏好参数 Preference(这里设置为中值)
- 计算吸引度矩阵 R R R
- 计算归属度矩阵 A A A(注意开始计算时 R R R和 A A A需要进行初始化)
- 迭代更新 R R R和 A A A,直至聚类中心在一定程度上不再更新或者达到最大的迭代次数
- 根据得到的聚类中心,对数据进行聚类
(2)类比
近邻传播聚类算法中涉及的参数较多,尤其是在吸引度和归属度的计算公式,所以这里我们可以将该聚类算法比作一个选举过程进行理解
- 数据集中的所有点都会参加选举,它们既是选民也是参选人,聚类的目标是要选出几个人作为代表
- s ( i , k ) s(i,k) s(i,k)是指 i i i对选 k k k这个人有一个固定的偏好程度
- r ( i , k ) r(i,k) r(i,k)是指 k k k在对 i i i这个选民的竞争中的优势程度(用 s ( i , k ) s(i,k) s(i,k)减去最强竞争者的评分)
- r ( i , k ) r(i,k) r(i,k)的更新过程就是选民 i i i对各个参选人的挑选
- 从
a
(
i
,
k
)
←
m
i
n
0
,
r
(
k
,
k
)
+
∑
i
丶
s
.
t
.
i
丶
∉
i
,
k
m
a
x
0
,
r
(
i
丶
,
k
)
a(i,k)\\leftarrow min\\0,r(k,k)+\\sum\\limits_i^丶s.t. i^丶\\notin\\i,k\\max\\0,r(i^丶,k)\\
a(i,k)←min0,r(k,k)+i丶以上是关于第二节:半监督聚类之AP(Affinity Propagation)聚类(近邻传播聚类)的主要内容,如果未能解决你的问题,请参考以下文章
R语言Affinity Propagation+AP聚类实战
均值漂移(MeanShift)谱聚类(Spectral clustering)AP聚类(Affinity propagation)聚类应用(客户分群)聚类应用(睡眠分析)