单机高性能网络模型
Posted lee_nacl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了单机高性能网络模型相关的知识,希望对你有一定的参考价值。
传统网络模型
PPC和prefork
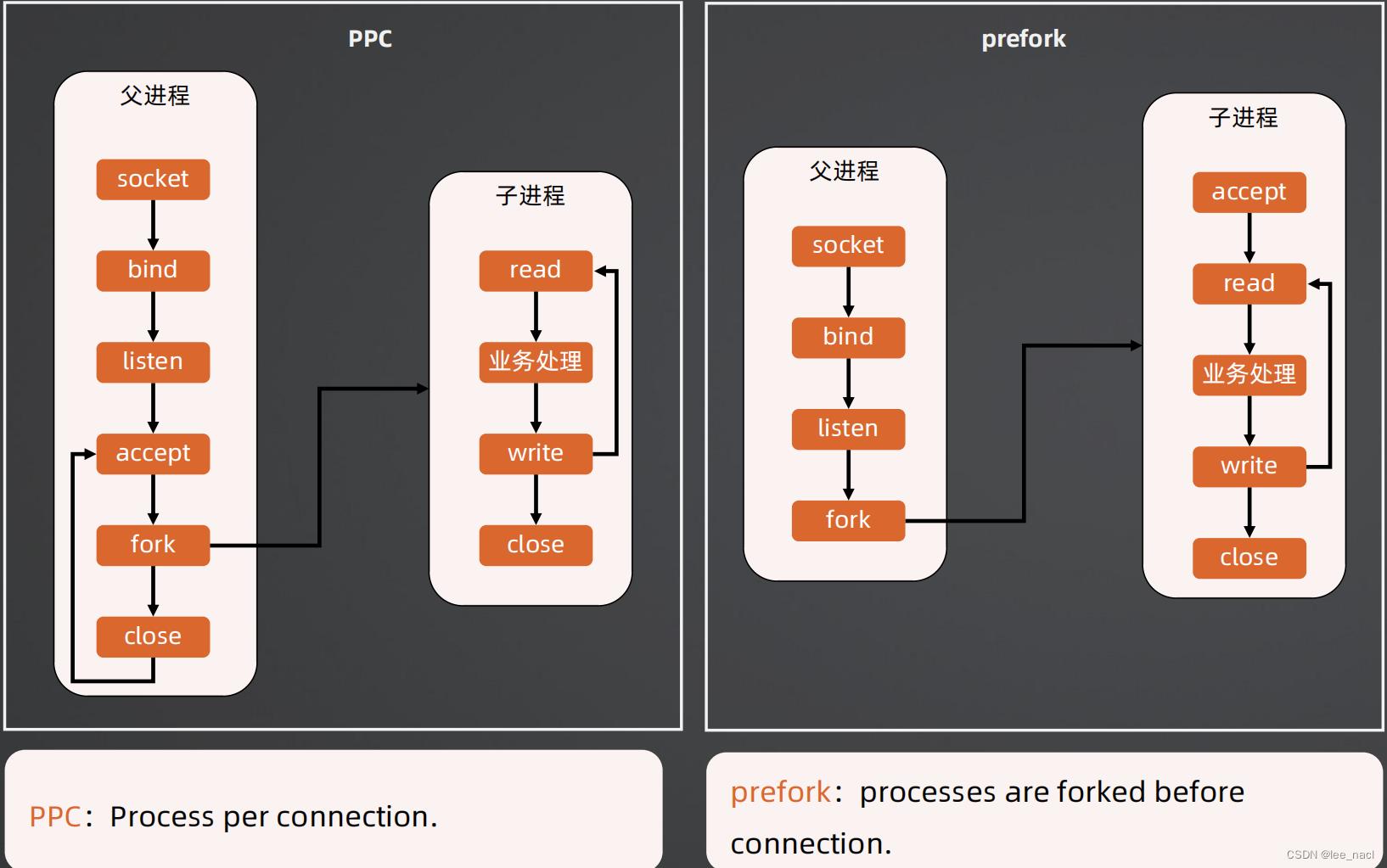
优点
实现简单
缺点
- PPC:fork代价高,性能低
- 父子进程通信要用IPC,监控统计等实现会比较复杂
- OS的上下文切换会限制并发连接数,一般几百
案例
- 世界上第一个Web服务器CERN httpd采用PPC模式
- Apache MPM prefork模式,默认256个连接
TPC和prethread
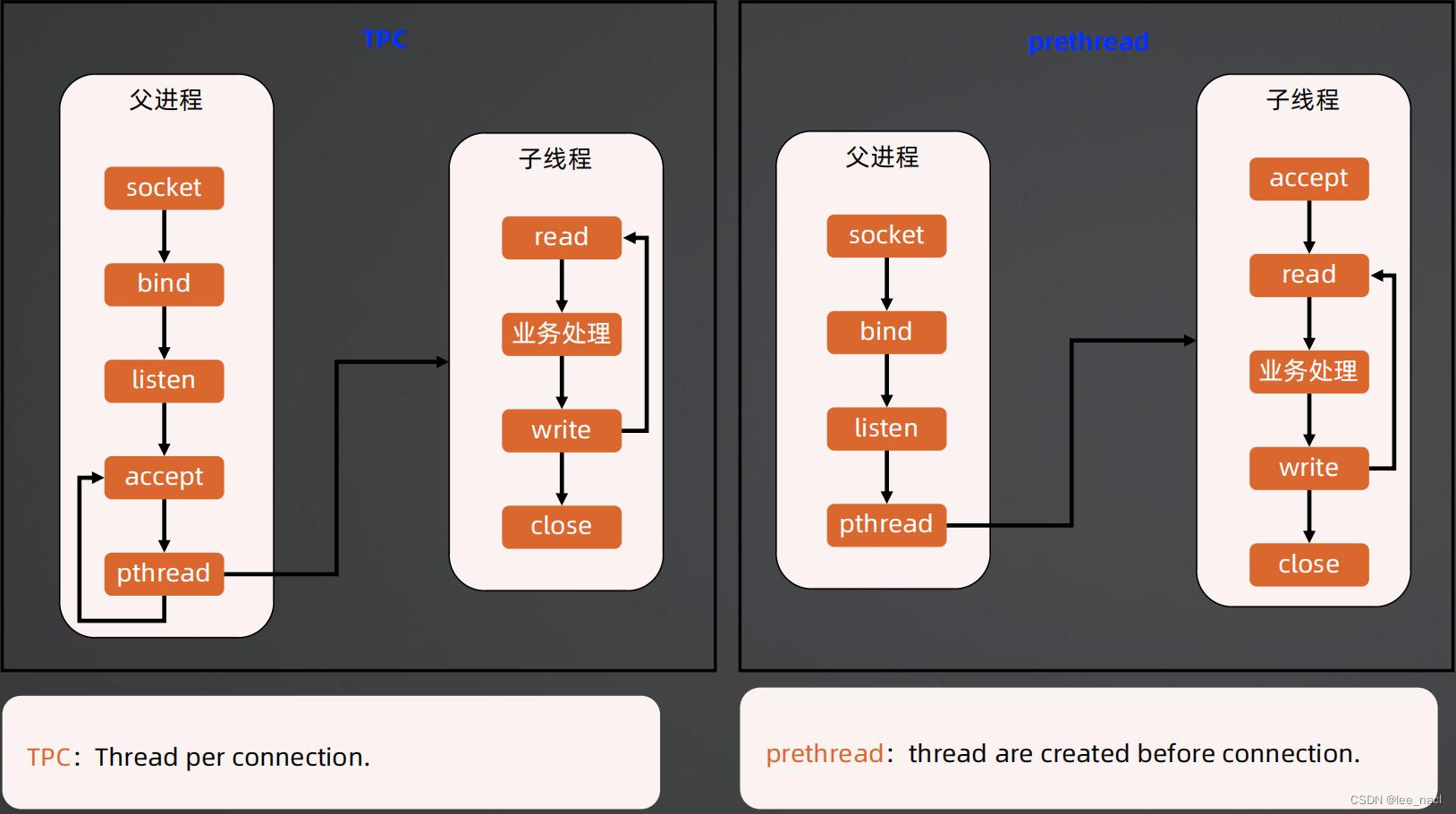
优点
- 实现简单
- 无需IPC,线程间通信即可
- 无需fork,线程创建代价低
缺点
- 线程互斥和共享比PPC/prefork要复杂
- 某个线程故障可能导致整个进程退出
- OS的上下文切换会限制并发连接数,一般几百,但比PPC/prefork要多
案例
Apache 服务器 MPM worker 模式就是 prethread模式的变种(多进程 + prethread),默认支持16 × 25= 400 个并发处理线程
Reactor网络模型
Reactor:基于多路复用的事件响应网络编程模型
多路复用
多个连接复用同一个阻塞对象,例如Java的Selector、epoll的epoll_fd(epoll_create函数创建)
事件响应
不同的事件分发给不同的对象处理,Java的事件有OP_ACCEPT、OP_CONNECT、OP_READ、OP_WRITE
优缺点
- 实现比传统网络模型要复杂
- 支持海量连接
Reactor模式
模式1-单 Reactor 单进程/单线程
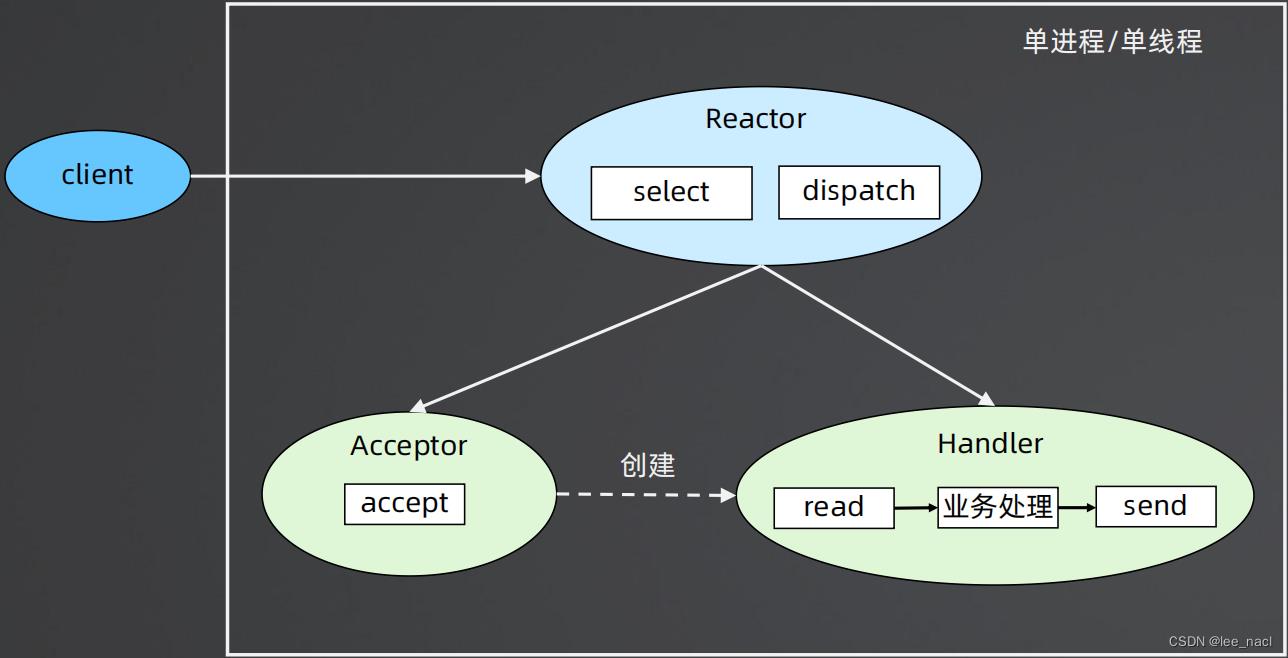
- Reactor 对象通过 select 监控连接事件,收到事件后通过 dispatch 进行分发
- 如果是连接建立的事件,则由 Acceptor 处理,Acceptor 通过 accept 接受连接,并创建一个 Handler 来处理连接后续的各种事件
- 如果不是连接建立事件,则 Reactor 会调用连接对应的 Handler(第2步中创建的 Handler)来进行响应。Handler 会完成 read → 业务处理 → send 的完整业务流程
优点
- 实现简单,无进程通信,无线程互斥和通信
- 无上下文切换,某些场景下性能可以做到很高
缺点
- 只有一个进程,无法发挥多核CPU的性能;只能采取部署多个系统来利用多核CPU,但这样会带来运维复杂度
- Handler在处理某个连接上的业务时,整个进程无法处理其他连接的事件,可能导致性能瓶颈
案例
Redis
模式2-单 Reactor 多线程
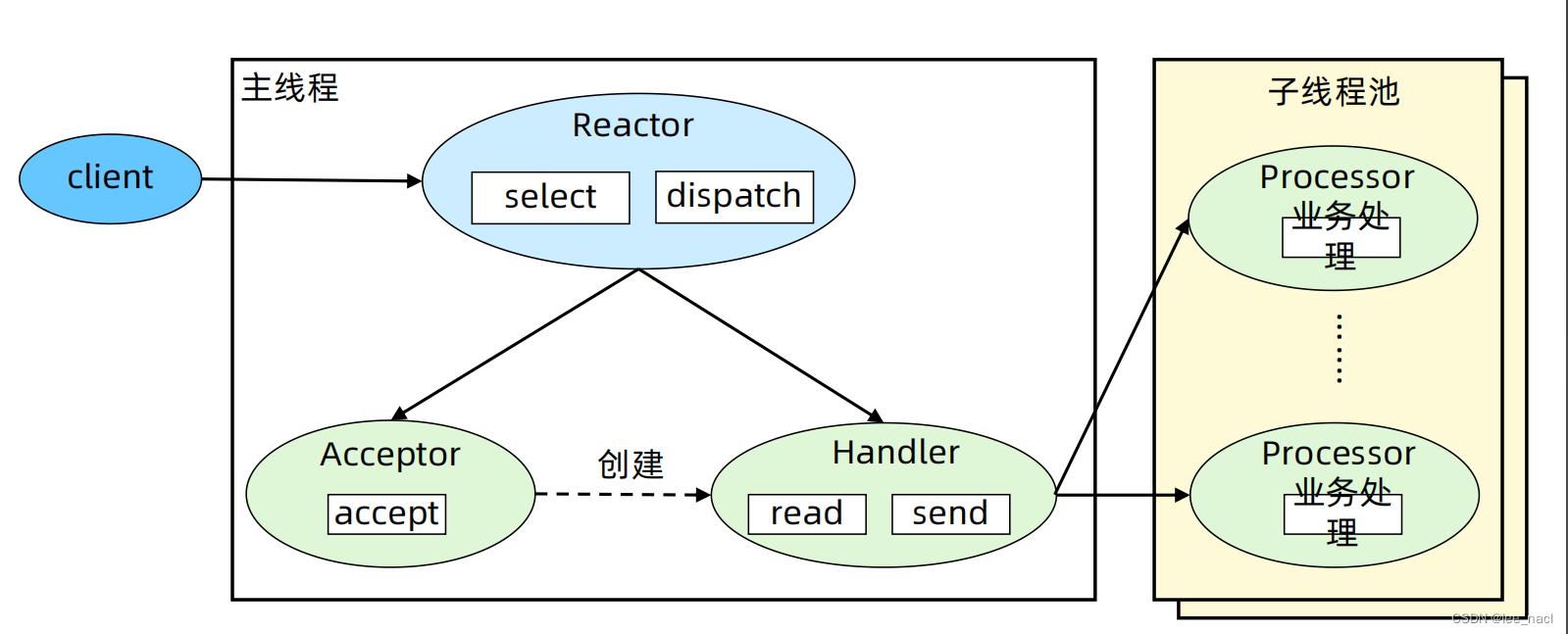
- 主线程中,Reactor 对象通过 select 监控连接事件,收到事件后通过 dispatch 进行分发
- 如果是连接建立的事件,则由 Acceptor 处理,Acceptor 通过 accept 接受连接,并创建一个 Handler 来处理连接后续的各种事件
- 如果不是连接建立事件,则 Reactor 会调用连接对应的 Handler(第2步中创建的 Handler)来进行响应
- Handler 只负责响应事件,不进行业务处理;Handler 通过 read 读取到数据后,会发给 Processor 进行业务处理
- Processor 会在独立的子线程中完成真正的业务处理,然后将响应结果发给主进程的 Handler 处理;Handler 收到响应后通过 send 将响应结果返回给 client
优点
充分利用了多核CPU的优势,性能高
缺点
- 多线程数据共享和访问比较复杂
- Reactor承担了所有事件的监听和响应,只在主线程中运行,瞬时高并发时会成为性能瓶颈
模式3-多 Reactor 多进程/线程
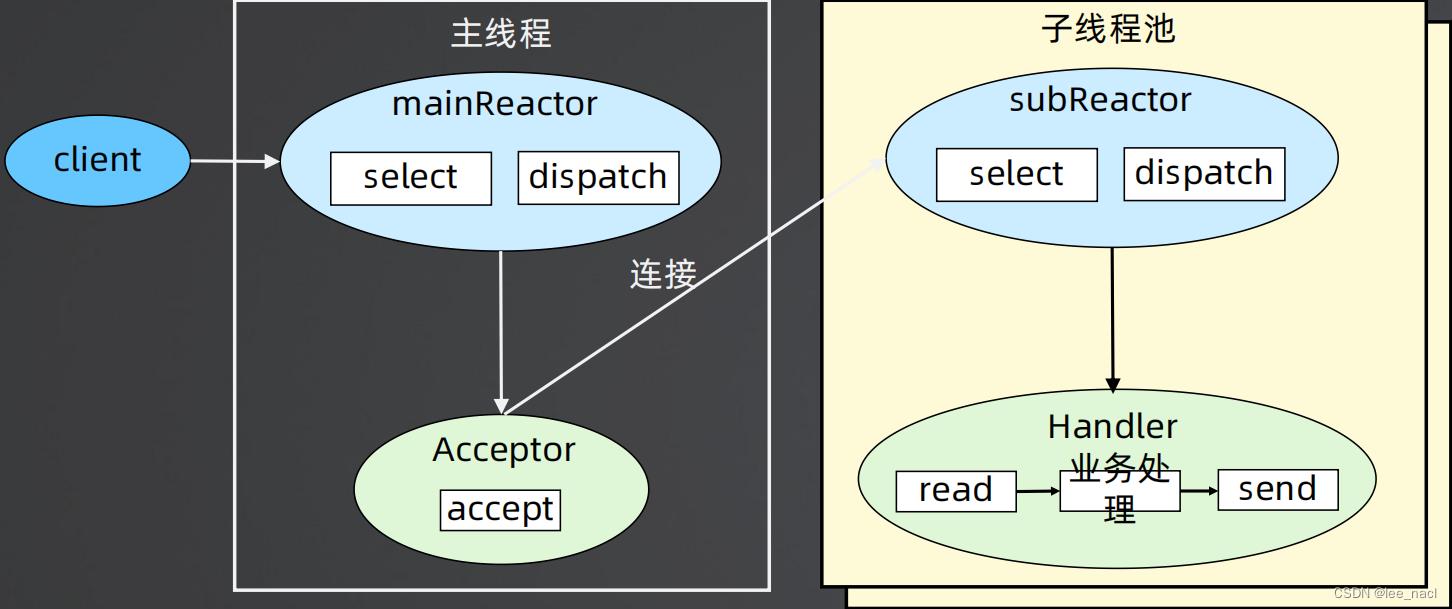
- 父进程中 mainReactor 对象通过 select 监控连接建立事件,收到事件后通过 Acceptor 接收,将新的连接分配给某个子进程
- 子进程的 subReactor 将 mainReactor 分配的连接加入连接队列进行监听,并创建一个 Handler 用于处理连接的各种事件
- 当有新的事件发生时,subReactor 会调用连接对应的 Handler(即第2步中创建的 Handler)来进行响应
- Handler 完成 read → 业务处理 → send 的完整业务流程
优点
- 充分利用了多核CPU的优势,性能高
- 实现简单,父子进程(线程)交互简单,subReactor子进程(线程)间无互斥共享或通信
缺点
没有明显的缺点,虽然自己实现会很复杂,但是目前已经有非常成熟的开源方案
案例
Memcached、Netty、nginx等
注意:实现细节都有一些差异,例如Memcached用了事件队列、Nginx是子进程accept
Proactor网络模型
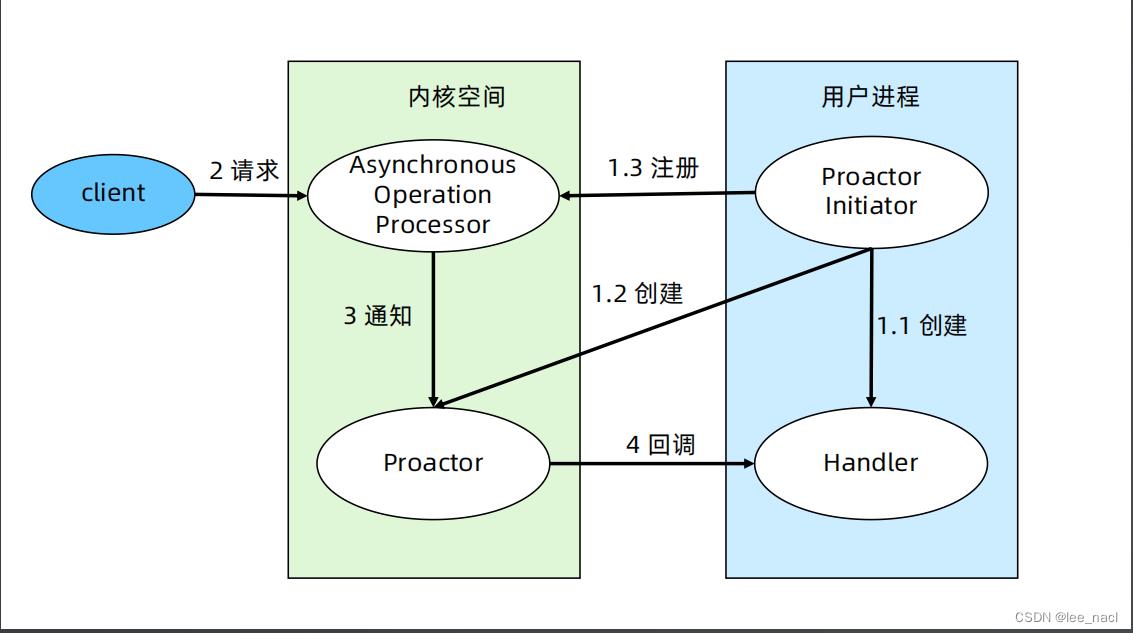
- Proactor Initiator 负责创建 Proactor 和 Handler,并将Proactor和 Handler 都通过 Asynchronous Operation Processor 注册到内核
- Asynchronous Operation Processor 负责处理注册请求,并完成I/O 操作
- Asynchronous Operation Processor 完成 I/O 操作后通知Proactor
- Proactor 根据不同的事件类型回调不同的 Handler 进行业务处理
- Handler 完成业务处理,Handler 也可以注册新的Handler 到内核进程
优点
理论上性能要比Reactor更高一些,但实测性能差异不大,大约10%以内
缺点
- 操作系统实现复杂,Linux目前对Proactor模式支持并不成熟
- 程序调试复杂
案例
Windows IOCP
网络模型对比

| 复杂度 | 连接数量 | 应用场景 | |
|---|---|---|---|
| PPC | 低 | 常量连接,几百 | 内部系统、中间件 |
| prefork | 低 | 常量连接,几百 | 内部系统、中间件 |
| TPC | 低 | 常量连接,几百 | 内部系统、中间件 |
| prethread | 低 | 常量连接,几百 | 内部系统、中间件 |
| Reactor | 中,程序复杂 | 海量连接,上万 | 互联网、物联网、中间件 |
| Proactor | 高,OS内核复杂 | 海量连接,上万 | 互联网、物联网、中间件 |
三种网络模型实战技巧
“多Reactor多线程”是目前已有技术中接近完美的技术方案:
- 所有场景
- 所有平台
- 性能和Proactor接近
直接用开源框架,千万不要自己去实现,例如Netty、libevent(Memcached网络框架)、libuv(node.js底层网络框架)
linux性能优化单机同时处理1000w请求C1000K
Linux网络基于TCP/IP模型构建了其网络协议栈,把繁杂的网络功能划分为应用层、传输层、网络层、网络接口层等四个不同的层次,既解决了网络环境中设备异构的问题,也解耦了网络协议的复杂性
C1000K的首字母C是Client 的缩写
C10K就是单机同时处理1万个请求(并发连接1万)的问题,而C1000K也就是单机支持处理100万个请求(并发连接100万)的问题
一、C10K
怎么在这样的系统中支持并发 1 万的请求呢?
1.1 资源分析
- 物理资源
从资源上来说,对2GB内存和千兆网卡的服务器来说,同时处理10000个请求只要每个请求处理占用不到200KB(2GB/10000)的内存和100Kbit(1000Mbit/10000)的网络带宽就可以
因此,物理资源是足够的
接下来自然是软件的问题,特别是网络的I/O模型问题
- I/O模型
说到I/O的模型,在C10K以前Linux 中网络处理都用同步阻塞的方式,也就是每个请求都分配一个进程或者线程,请求数只有100个时这种方式自然没问题,但增加到10000个请求时,10000个进程或线程的调度、上下文切换乃至它们占用的内存都会成为瓶颈
1.2 需要解决的问题
既然每个请求分配一个线程的方式不合适,那么为了支持10000个并发请求,这里就有两个问题需要解决:
- 非阻塞I/O或异步I/O
怎样在一个线程内处理多个请求,也就是要在一个线程内响应多个网络I/O
在同步阻塞方式下一个线程只能处理一个请求,到这里不再适用,那是不是可以用非阻塞I/O或异步I/O来处理多个网络请求呢?
- 更少的线程处理
怎么更节省资源地处理客户请求,也就是要用更少的线程来服务这些请求
是不是可以继续用原来的100个或者更少的线程来服务现在的10000个请求呢?
当然,事实上现在关于C10K的两个问题早已解决,接下来看看关于这两个问题的解决方式
二、I/O模型优化
异步、非阻塞I/O的解决思路经常被提及,其实就是在网络编程中经常用到的I/O多路复用(I/O Multiplexing)
I/O多路复用是什么意思呢?
2.1 I/O事件通知的方式
在了解I/O多路复用前,先了解两种I/O事件通知的方式:水平触发和边缘触发,它们常用在套接字接口的文件描述符中
- 水平触发
只要文件描述符可以非阻塞地执行I/O ,就会触发通知
也就是说,应用程序可以随时检查文件描述符的状态,然后再根据状态进行I/O操作
- 边缘触发
只有在文件描述符的状态发生改变(也就是I/O请求达到)时,才发送一次通知
这时候,应用程序需要尽可能多地执行I/O,直到无法继续读写才可以停止
如果I/O没执行完,或者因为某种原因没来得及处理,那么这次通知也就丢失了
2.2 I/O多路复用的实现方法
接下来,再回过头来看I/O多路复用的方法。这里其实有很多实现方法,逐个进行分析:
2.2.1 第一种,使用非阻塞I/O和水平触发通知**
比如使用 select或者poll
根据刚才水平触发的原理,select和poll需要从文件描述符列表中找出哪些可以执行I/O,然后进行真正的网络I/O读写
由于I/O是非阻塞的,一个线程中就可以同时监控一批套接字的文件描述符,这样就达到了单线程处理多请求的目的
所以,这种方式的最大优点是对应用程序比较友好,它的API非常简单
同样这种方式存在一些不足点:
- 轮询耗时
但是,应用软件使用select和poll时,需要对这些文件描述符列表进行轮询,这样请求数多的时候就会比较耗时。并且,select和poll还有一些其他的限制
- select和poll的限制
select使用固定长度的位相量表示文件描述符的集合,因此会有最大描述符数量的限制
比如,在 32 位系统中默认限制是1024。并且,在select内部检查套接字状态是用轮询的方法,再加上应用软件使用时的轮询就变成了一个 O(n^2) 的关系
而poll改进了select的表示方法,换成了一个没有固定长度的数组,这样就没有了最大描述符数量的限制(当然还会受到系统文件描述符限制)
但应用程序在使用poll时,同样需要对文件描述符列表进行轮询,这样,处理耗时跟描述符数量就是O(N)的关系
- 空间切换成本
除此之外,应用程序每次调用 select 和 poll 时,还需要把文件描述符的集合,从用户空间传入内核空间,由内核修改后再传出到用户空间中。这一来一回的内核空间与用户空间切换也增加了处理成本
有没有什么更好的方式来处理呢?答案自然是肯定的
2.2.2 第二种,使用非阻塞 I/O 和边缘触发通知
比如epoll
既然select和poll有那么多的问题,就需要继续对其进行优化,而epoll就很好地解决了这些问题:
- epoll使用红黑树在内核中管理文件描述符的集合,这样就不需要应用程序在每次操作时都传入、传出这个集合
- epoll使用事件驱动的机制,只关注有I/O事件发生的文件描述符,不需要轮询扫描整个集合
2.2.3 第三种,使用异步I/O
异步I/O(Asynchronous I/O,简称为 AIO)
异步I/O与同步I/O的区别在于:
- 异步I/O允许应用程序同时发起很多I/O操作而不用等待这些操作完成
- 在I/O完成后系统会用事件通知(比如信号或者回调函数)的方式告诉应用程序
这时,应用程序才会去查询I/O操作的结果
三、工作模型优化
了解I/O模型后请求处理的优化就比较直观了,使用I/O多路复用后就可以在一个进程或线程中处理多个请求
其中,有下面两种不同的工作模型:
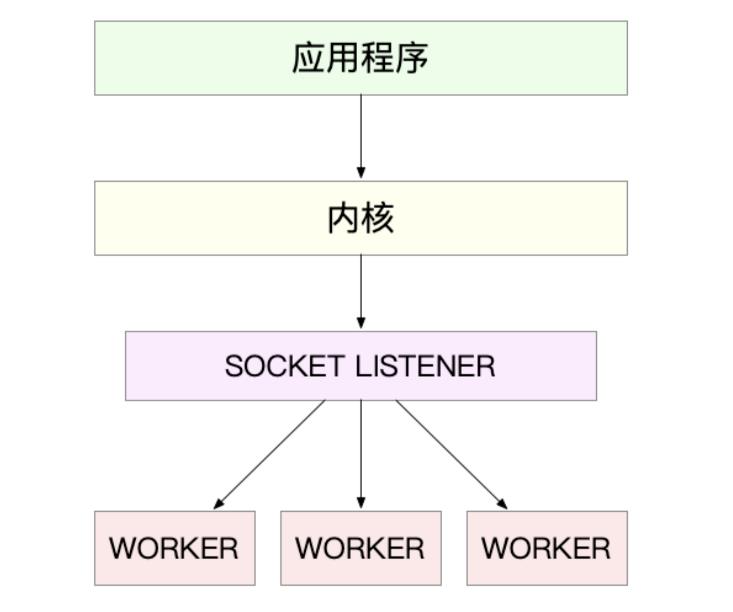
3.1 第一种,主进程+多个worker子进程
这也是最常用的一种模型
这种方法的一个通用工作模式就是:
- 主进程执行bind()+listen()后创建多个子进程
- 然后,在每个子进程中都通过accept()或epoll_wait()来处理相同的套接字
- Nginx实例
最常用的反向代理服务器Nginx就是这么工作的
它也是由主进程和多个worker进程组成:
- 主进程主要用来初始化套接字并管理子进程的生命周期
- worker进程负责实际的请求处理
组成的相互关系图:
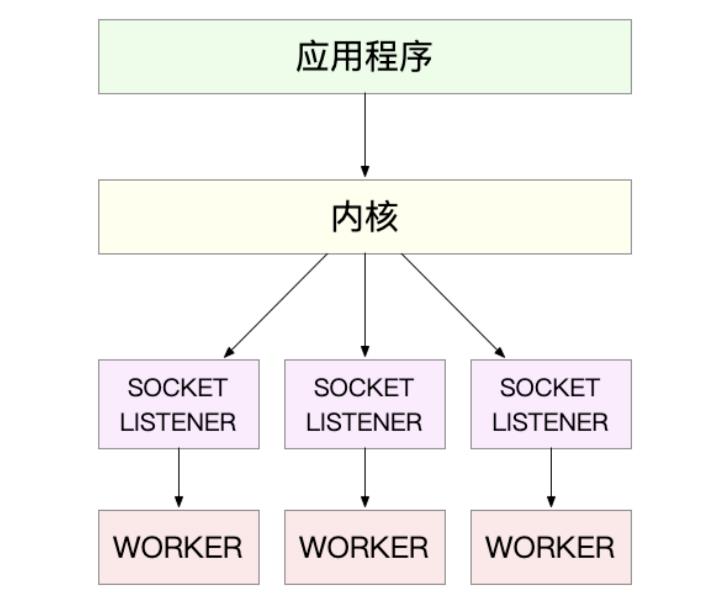
3.2 第二种,监听到相同端口的多进程模型
在这种方式下,所有的进程都监听相同的接口并且开启SO_REUSEPORT选项,由内核负责将请求负载均衡到这些监听进程中去
对应过程如下图:
四、C1000K
基于I/O多路复用和请求处理的优化,C10K问题很容易就可以解决
不过,随着摩尔定律带来的服务器性能提升,以及互联网的普及,新兴服务会对性能提出更高的要求
很快,原来的C10K已经不能满足需求,所以又有了C100K 和C1000K,也就是并发从原来的1万增加到10万、乃至100万
从1万到10万其实还是基于C10K的这些理论,epoll配合线程池,再加上 CPU、内存和网络接口的性能和容量提升,大部分情况下C100K很自然就可以达到
那么,再进一步C1000K是不是也可以很容易就实现呢?这其实没有那么简单了
4.1 物理资源
首先从物理资源使用上来说,100万个请求需要大量的系统资源,比如:
- 内存
假设每个请求需要16KB内存的话,那么总共就需要大约15GB内存
- 带宽
而从带宽上来说,假设只有20%活跃连接,即使每个连接只需要1KB/s的吞吐量,总共也需要1.6Gb/s的吞吐量
千兆网卡显然满足不了这么大的吞吐量,所以还需要配置万兆网卡,或者基于多网卡Bonding承载更大的吞吐量
4.2 软件资源
其次,从软件资源上来说,大量的连接也会占用大量的软件资源,比如:
- 文件描述符的数量
- 连接状态的跟踪(CONNTRACK)
- 网络协议栈的缓存大小(比如套接字读写缓存、TCP 读写缓存)
4.3 中断处理
最后,大量请求带来的中断处理也会带来非常高的处理成本
需要优化的硬件和软件:
- 多队列网卡
- 中断负载均衡
- CPU 绑定
- RPS/RFS(软中断负载均衡到多个CPU 核上)
- 网络包的处理卸载(Offload)
- 网络设备(如TSO/GSO、LRO/GRO、VXLAN OFFLOAD)
C1000K的解决方法,本质上还是构建在epoll的非阻塞I/O模型上
不过,除了I/O模型之外,还需要从应用程序到Linux 内核、再到CPU、内存和网络等各个层次的深度优化,特别是需要借助硬件来卸载那些原来通过软件处理的大量功能
五、小结
C10K问题的根源,一方面在于系统有限的资源,另一方面也是更重要的因素,是同步阻塞的 I/O 模型以及轮询的套接字接口,限制了网络事件的处理效率
引入的epoll ,完美解决了C10K的问题,现在的高性能网络方案都基于epoll
从C10K到C100K,可能只需要增加系统的物理资源就可以满足,但从C100K到C1000K,就不仅仅是增加物理资源就能解决的问题了
这时需要多方面的优化工作,从硬件的中断处理和网络功能卸载、到网络协议栈的文件描述符数量、连接状态跟踪、缓存队列等内核的优化,再到应用程序的工作模型优化都是考虑的重点
当然了,实际上在大多数场景中,并不需要单机并发1000万的请求。通过调整系统架构把这些请求分发到多台服务器中来处理,通常是更简单和更容易扩展的方案
以上是关于单机高性能网络模型的主要内容,如果未能解决你的问题,请参考以下文章