数据结构与算法什么是链表?并用代码手动实现一个单向链表
Posted 逆流°只是风景-bjhxcc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法什么是链表?并用代码手动实现一个单向链表相关的知识,希望对你有一定的参考价值。
文章目录
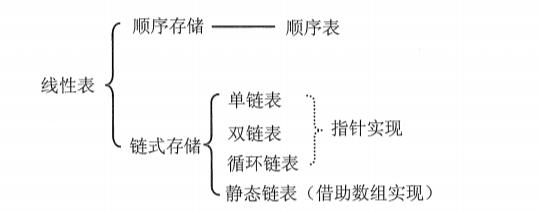
一、链表是什么
-
链表是物理存储单元上非连续的、非顺序的存储结构,数据元素的逻辑顺序是通过链表的指针地址实现,有一系列结点(地址)组成,结点可动态的生成。
-
结点包括两个部分:
(1)存储数据元素的数据域(内存空间)
(2)存储指向下一个结点地址的指针域。 -
相对于线性表顺序结构,操作复杂。
-
链表分为 :
(1)单链表
(2)双链表
(3)单向循环链表
(4)双向循环链表
二、链表的作用
-
实现数据元素的存储按一定顺序储存,允许在任意位置插入和删除结点。
-
包括单向结点,双向结点,循环接点。
三、链表与数组的区别
说到链表那肯定要聊一下数组,为什么会出现链表呢?
-
数组:使用一块连续的内存空间地址去存放数据,但
例如:
int a[5]=1,2,3,4,5 突然我想继续加两个数据进去,但是已经定义好的数组不能往后加,只能通过定义新的数组
int b[7]=1,2,3,4,5,6,7 这样就相当不方便比较浪费内存资源,对数据的增删不好操作。 -
链表:使用多个不连续的内存空间去存储数据, 可以 节省内存资源(只有需要存储数据时,才去划分新的空间),对数据的增删比较方便。
四、如何理解链表
理论的东西我就不说太多了,下面我将以代码+图形的方式让大家很通俗易懂的理解链表。
- 单链表的结构体
struct node
int data;//存放数据
struct node *next; //地址域 (与节点的类型地址相匹配)
可以把这个结构体理解成这个样子
- 创建链表的新节点
struct node *creat_node(int data)
struct node *new = malloc(sizeof(struct node));
new->data = data;
new->next = NULL;
return new;

- 插入节点
struct node* insert_node(struct node*p,struct node*new)
p->next = new;
- 显示链表
void show(struct node *p)
while(1)
if(p== NULL) //假设p已经为NULL则返回
return ;
printf("p=%d\\n",p->data);
p = p->next; //链表的重要知识点!!! 遍历节点向下走
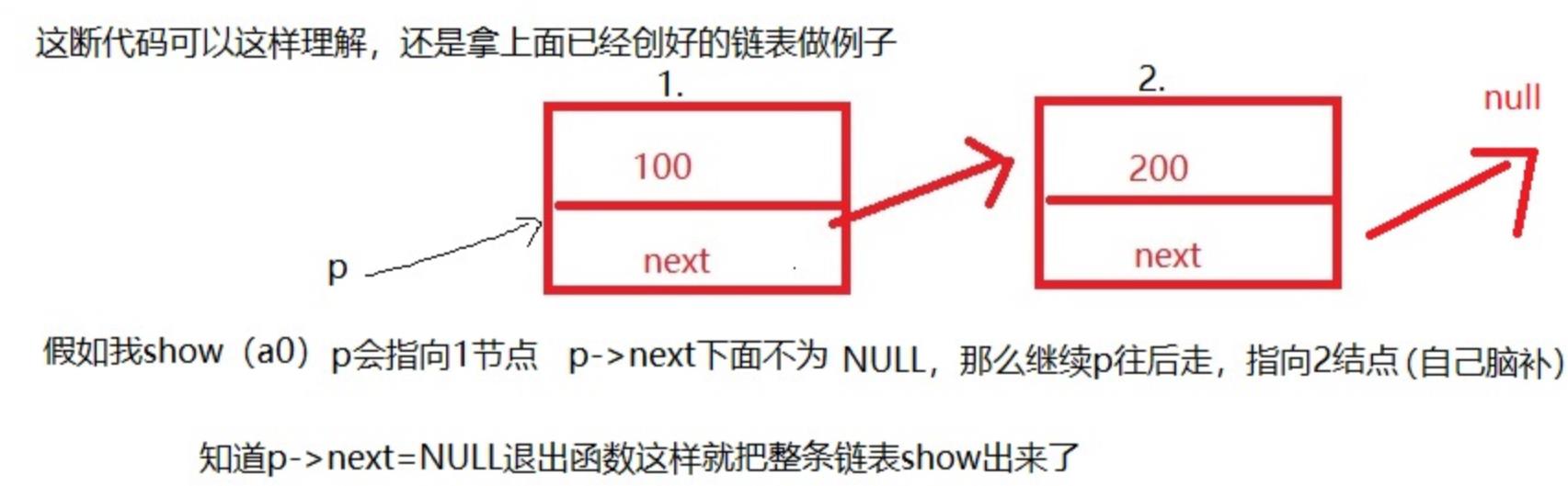
有了以上三个步骤我们就可以做出一条简单的单链表。
五、单链表完整代码
list.c
#include <stdio.h>
#include <stdlib.h>
//设计链表的节点
struct node
int data;//存放数据
struct node *next; //存放地址 (与节点的类型地址相匹配)
;
//创建节点
struct node *creat_node(int data)
struct node *new = malloc(sizeof(struct node));
new->data = data;
new->next = NULL;
return new;
//插入节点 (链接节点)
struct node* insert_node(struct node*p,struct node*new)
p->next = new;
//显示节点数据 (遍历节点)
void show(struct node *p)
while(1)
if(p== NULL) //假设p已经为NULL则返回
return ;
printf("p=%d\\n",p->data);
p = p->next; //链表的重要知识点!!! 遍历节点向下走
int main()
//1.分配节点空间
struct node *a0 = creat_node(100);
struct node *a1 = creat_node(200);
struct node *a2 = creat_node(300);
inser_node(a0,a1);
inser_node(a1,a2);
//通过a0 访问a0 a1 a2的数据 //3.访问节点中的数据
//printf("a0=%d,a1=%d,a2=%d\\n",a0.data,a0.next->data,a0.next->next->data);
show(a0);
算法入门(七,数据结构,单向链表与双链表)
链表结构
什么是链表?
链表是一种物理存储单元上非连续,非顺序的存储结构(数据元素的逻辑顺序是通过链表中的指针链就=接次序实现的)链表由一系列结点组成,结点可以在运行时动态生成。
什么是结点?
结点由二部分组成,一个是存储数据单元的数据域,一个是存储下一个节点的指针(连接区)。
python创建一个元素为节点,使用类改变数据类型。
#定义为结点对象
class Node:
def __init__(self,val):
#val存放数据元素
self.val=val
#next存放下一个节点的标识符
self.next=None
链表的作用
链表结构可以充分利用计算机的内部空间,实现灵活的内存动态管理。
链表与顺序表的操作复杂度对比
链表失去了顺序表随机读取的优点,同时链表增加了结点的指针域。空间开销大,但是对存储空间的使用相对灵活。
| 操作 | 链表 | 顺序表 |
| 访问元素 | O(n) | O(1) |
| 在头部插入/删除 | O(1) | O(n) |
| 在末部插入/删除 | O(n) | O(1) |
| 在中间插入/删除 | O(n) | O(n) |
单向链表
理解:单向的,指针头指向尾部

实现方式:(python)
'''
单链表的实现
'''
#创建结点对象
class Node:
def __init__(self,val):
self.val=val
self.next=None
class Singly_linked_list():
#数组头节点创建,node=None声明没有元素
def __init__(self,node=None):
#__head私有化属性,不被外界访问
self.__head=node
#判断是否为空
def is_empty(self):
#判断头是否为空
return self.__head==None
#查看链表有多少个元素
def length(self):
#cur指向头
cur=self.__head
#记录有多少元素
count=0
#判断链表是否为空
while cur != None:
#不是加一
count+=1
#指针cur向后移动
cur=cur.next
return count
#头部插入
def headadd(self,val):
#构建节点(将插入数值换成结点类型,)
node=Node(val)
#设置关联,头指向下一个,不能交换位置,交换位置会改变原本链表的连接关系
#先改变元素next区域,在指向头
node.next=self.__head
self.__head=node
#中间插入
def middleadd(self,pos,val):
if pos == 0:
# 当pos=o是就是头部添加
self.headadd(val)
elif pos >=self.length()-1:
# 当 pos大于链表长度就是尾部部添加
self.tailadd(val)
else:
pre = self.__head
#构建pre指针指向头节点的值
count=0
while count < (pos-1):
count+=1
pre=pre.next
node=Node(val)
node.next=pre.next
pre.next=node
#尾部插入
def tailadd(self,val):
node = Node(val)
cur=self.__head
#如果链表中没有元素
if cur is None:
self.headadd(val)
else:
while cur.next is not None:
cur=cur.next
cur.next=node
#删除节点
def remove(self,item):
cur=self.__head
pre=None
while cur !=None:
#遍历一遍
if cur.val==item:
#判断是否存在目标
if cur== self.__head:
#如果是头节点,
self.__head=cur.next
break
else:
#跳过这个节点
pre.next=cur.next
break
else:
#二个游标必须相隔一个节点
pre=cur
cur=cur.next
#遍历链表
def walk(self):
cur=self.__head
while cur is not None:
print(cur.val,end= ' ')
cur=cur.next
#查看节点是否存在
def search(self,item):
cur=self.__head
while cur != None:
if cur.val == item:
return True
else:
#如果不存在就向后移动一位
cur=cur.next
return False
if __name__ == '__main__':
a=Singly_linked_list()
a.headadd(3)
a.headadd(4)
a.tailadd(6)
a.headadd(7)
a.middleadd(2,8)
print(a.search(4))
a.walk()
a.remove(7)
a.walk()双向链表
理解:双向的,指针头指向尾部,尾部也指向头部

实现方式:(python,与单链表不同的是插入,删除,遍历)
'''
双链表的实现
'''
#创建结点对象
class Node(object):
def __init__(self,val):
#定义节点
self.val=val
#前节点
self.prev=None
#后节点
self.next=None
class Double_linked_list(object):
#数组头节点创建,node=None声明没有元素
def __init__(self,node=None):
#__head私有化属性,不被外界访问
self.__head=node
#判断是否为空
def is_empty(self):
#判断头是否为空
return self.__head is None
#查看链表有多少个元素
def length(self):
#cur指向头
cur=self.__head
#记录有多少元素
count=0
#判断链表是否为空
while cur != None:
#不是加一
count+=1
#指针cur向后移动
cur=cur.next
return count
#头部插入
def headadd(self,val):
#构建节点(将插入数值换成结点类型,)
node=Node(val)
node.next=self.__head
self.__head=node
node.next.prev=node
#中间插入
def middleadd(self,pos,val):
if pos == 0:
# 当pos=o是就是头部添加
self.headadd(val)
elif pos >=self.length()-1:
# 当 pos大于链表长度就是尾部部添加
self.tailadd(val)
else:
cur=self.__head
count=0
while count < pos:
count+=1
cur=cur.next
#退出循环cur指向pos位置
node=Node(val)
node.next=cur
node.prev=cur.prev
cur.prev.next=node
cur.prev=node
#尾部插入
def tailadd(self,val):
node = Node(val)
cur=self.__head
#如果链表中没有元素
if cur is None:
self.__head=node
else:
while cur.next is not None:
cur=cur.next
cur.next=node
node.prev=cur
#删除节点
def remove(self,item):
cur=self.__head
while cur !=None:
#遍历一遍
if cur.val==item:
#判断是否存在目标
if cur == self.__head:
#如果是头节点,
self.__head=cur.next
if cur.next:
#判断链表是否只有一个节点
cur.next.prev=None
break
else:
#跳过这个节点
cur.prev.next=cur.next
if cur.next:
cur.next.prev=cur.prev
break
else:
#二个游标必须相隔一个节点
cur=cur.next
#遍历链表
def walk(self):
cur=self.__head
while cur is not None:
print(cur.val,end= ' ')
cur=cur.next
#查看节点是否存在
def search(self,item):
cur=self.__head
while cur != None:
if cur.val == item:
return True
else:
#如果不存在就向后移动一位
cur=cur.next
return False
if __name__ == '__main__':
a=Double_linked_list()
a.tailadd(6)
a.headadd(7)
a.headadd(3)
a.headadd(4)
a.middleadd(2,8)
print(a.search(4))
a.walk()
a.remove(7)
a.walk()
以上是关于数据结构与算法什么是链表?并用代码手动实现一个单向链表的主要内容,如果未能解决你的问题,请参考以下文章