目标检测从YOLOv1到YOLOX(理论梳理)
Posted zstar-_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测从YOLOv1到YOLOX(理论梳理)相关的知识,希望对你有一定的参考价值。
前言
YOLO系列应该是目标领域知名度最高的算法,其凭借出色的实时检测性能在不同的领域均有广泛应用。
目前,YOLO共有6个版本,YOLOv1-v5和YOLOX,除了YOLOv5外,其它都有相应的论文,5篇论文我已上传到资源中,可自行下载:https://www.aliyundrive.com/s/ofcnrxjzsFE
工程上使用最多的版本是YOLOv3和YOLOv5,Pytorch版本均由ultralytics公司开发,YOLOv5仍在进行维护,截至目前,已经更新到YOLOv5-6.1版本。
项目地址:https://github.com/ultralytics/yolov5
在上篇博文中,详细记录了如何用YOLOv5来跑通VOC2007数据集,本篇博文旨在对YOLO系列算法的演化进行简单梳理,更多详细的内容可以看文末的参考资料。
YOLOv1
YOLO全称Yolo Only Look Once,即只需看一次就能把目标识别出来。它由Joseph Redmon等人提出,论文成果发表在了CVPR 2016上。它的精度不及two-stage的Faster R-CNN,但做到更高的实时性。据原论文所述,它能够做到每秒45帧的检测速率,同时,作者还设计了一个深度更浅的小网络,能够做到每秒155帧的检测速率。
核心思想
如图所示,YOLO的核心思想是把原始图像分成SxS个网格,让每个网格负责预测类别。
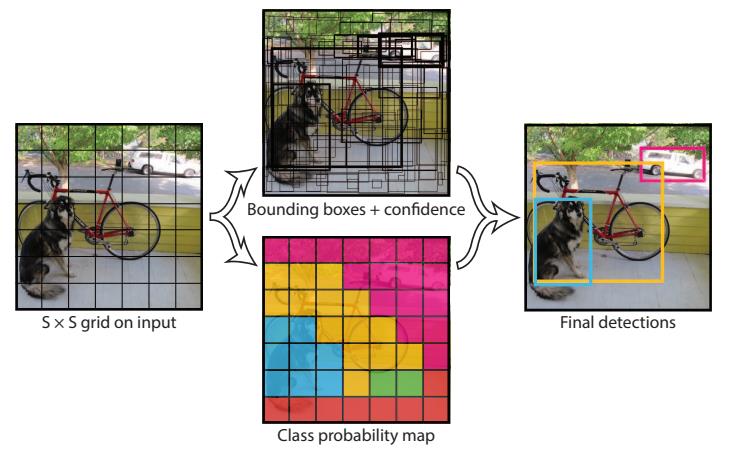
具体过程:
(1) 将一幅图像分成 S×S个网格(grid cell),如果某个 object 的中心落在这个网格中,则这个网格就负责预测这个object。
(2) 每个网格要预测 B 个bounding box,每个 bounding box 要预测 (x, y, w, h) 和 confidence 共5个值。
(3) 每个网格还要预测一个类别信息,记为 C 个类。
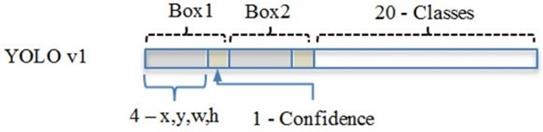
总的来说,S×S 个网格,每个网格要预测 B个bounding box ,还要预测 C 个类。网络输出就是一个 S × S × (5×B+C) 的张量。
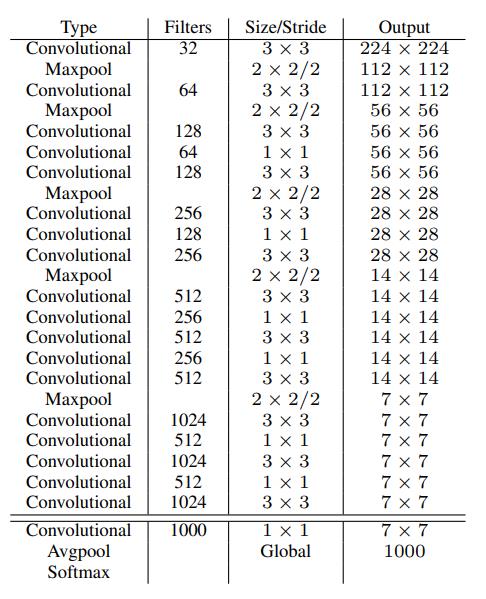
网络结构
YOLO受到GoogLeNet的启发,搭建了下图所示的网络结构。和GoogLeNet经典的inception结构不同,YOLOv1网络只是简单使用1x1+3x3卷积核的形式来提取特征。
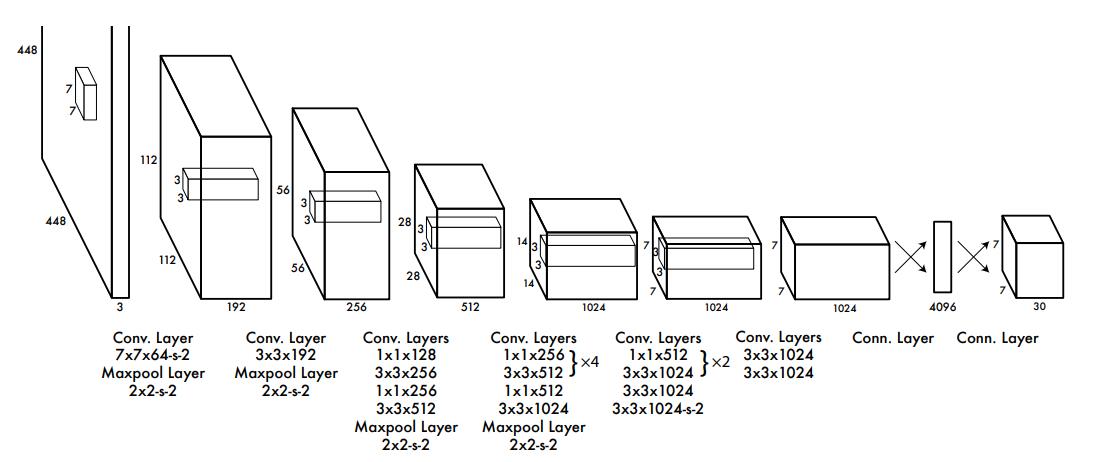
- 网络输入:448×448×3的彩色图片。
- 中间层:由若干卷积层和最大池化层组成,用于提取图片的抽象特征。
- 全连接层:由两个全连接层组成,用来预测目标的位置和类别概率值。
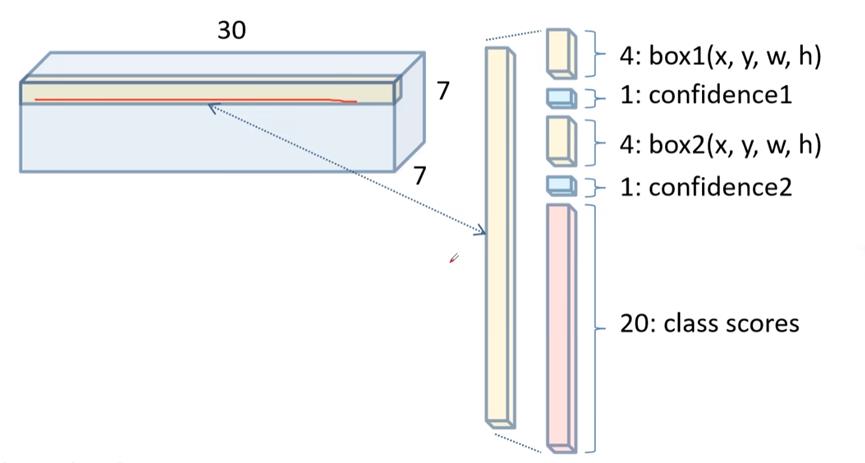
- 网络输出:7×7×30的预测结果。
网络输出的7x7即分割网格数,30即两个bounding box + 20个类别分数。
这个类别分数(有的文章称类别置信度)可以通过下面的公式进行计算:

Pr(Object)对应的是该格子中目标的概率,有目标为1,没目标为0,IOU即预测框和真实框的交并比,对每一类分别进行计算,即得到每一类的分数。
损失函数
损失函数由三部分构成:

定位损失(bounding box损失):衡量预测框和真实框的差异
置信度损失(confidence损失):衡量是否有目标
分类损失(classes损失):衡量目标的类别
- 定位误差比分类误差更大,所以增加对定位损失的惩罚,使 λ c o o r d = 5 \\lambda_coord=5 λcoord=5
- 在每个图像中,许多网格单元不包含任何目标。训练时就会把这些网格里的框的“置信度”分数推到零,这往往超过了包含目标的框的梯度。从而可能导致模型不稳定,训练早期发散。因此要减少了不包含目标的框的置信度预测的损失,使 λ n o o b j = 0.5 \\lambda_noobj=0.5 λnoobj=0.5
局限
论文中提到YOLOv1有以下三点局限:
- 对相互靠近的物体,以及很小的群体检测效果不好,这是因为一个网格只预测了2个框,并且都只属于同一类。
- 由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。(因为对于小的bounding boxes,small error影响更大)
- 对不常见的角度的目标泛化性能偏弱。
YOLOv2
2017年,YOLOv1的作者Joseph Redmon继续提出 YOLOv2,它在初代YOLO版本上进行了一系列改进,使其速度更快,效果更好,正如论文标题所述:YOLO9000: Better, Faster, Stronger。这里的9000指YOLO9000可以同时在COCO和ImageNet数据集中进行训练,训练后的模型可以实现多达9000种物体的实时检测。
它主要有以下几点改进:
网络结构
Yolov2采用了Darknet-19特征提取网络,网络结构图如下所示:
YOLOv2采用了一个新的基础模型(特征提取器),称为Darknet-19,包括19个卷积层和5个maxpooling层,网络结构图如下所示
加入BN层
对数据进行预处理(统一格式、均衡化、去噪等)能够大大提高训练速度,提升训练效果。因此,
在YOLOv2中,每个卷积层后面都添加了Batch Normalization层,并且不再使用droput。使用Batch Normalization后,YOLOv2的mAP提升了2.4%。
更高分辨率的预训练
由于历史原因,ImageNet分类模型基本采用大小为224x224的图片作为输入,分辨率相对较低,不利于检测模型。所以YOLOv1在采用224x224分类模型预训练后,将分辨率增加至448x448,并使用这个高分辨率在检测数据集上finetune。但是直接切换分辨率,检测模型可能难以快速适应高分辨率。所以YOLOv2增加了在ImageNet数据集上使用448x448输入来finetune分类网络这一中间过程(10 epochs),这可以使得模型在检测数据集上finetune之前已经适用高分辨率输入。使用高分辨率分类器后,YOLOv2的mAP提升了约4%。
引入锚框(Anchor)
在YOLOv1中,输入图片最终被划分为7x7网格,每个单元格预测2个边界框。YOLOv1最后采用的是全连接层直接对边界框进行预测,其中边界框的宽与高是相对整张图片大小的,而由于各个图片中存在不同尺度和长宽比的物体,YOLOv1在训练过程中学习适应不同物体的形状是比较困难的,这也导致YOLOv1在精确定位方面表现较差。
YOLOv2借鉴了RCNN系列的Anchor机制,改变YOLOv1的直接回归出每个box的坐标,YOLOv2对于每个box回归相对于Anchor的偏移量。有了Anchor,就像是站在巨人的肩膀上,比如以前预测值取值为[0,100],现在预测取值为50 + [0,1],输出的范围变小,从而更加稳定。
另外,RCNN系列的Anchor是通过人为经验进行设置。YOLOv2采取了一个比较新颖的方法,对于Voc和Coco数据集的box进行k-means聚类。
注意,这里聚类的距离指标并不是常见的欧氏距离,因为大检测框和小检测框的距离有差异,这样大检测框的误差会比小检测框的误差要大。因此作者选择box与聚类中心box之间的IOU值作为距离指标:
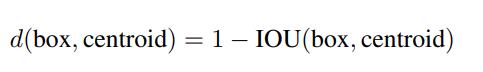
作者通过聚类最终得到5种anchor,其宽高分别如下:
# 注意,这个宽高是在Grid的尺度下的,不是在原图尺度上,在原图尺度上的话还要乘以步长32。
# 这个anchor尺寸不是固定值,对于不同数据集,重新聚类得到的anchor尺寸不一样。
[0.57273, 0.677385],
[1.87446, 2.06253],
[3.33843, 5.47434],
[7.88282, 3.52778],
[9.77052, 9.16828].
关于这个总步长32,还有细节可以补充。前面提到YOLOv2训练模型输入的图片尺寸为448x448,但在检测模型中,输入图片的尺寸为416x416,这样通过网络的一系列运算,最后得到的特征图大小为13x13,维度是奇数,这样就恰好只有一个中心位置。对于一些大物体,它们中心点往往落入图片中心位置,此时使用特征图的一个中心点去预测这些物体的边界框相对容易些。
位置宽高计算
上面提到,YOLOv2输出的是对于锚框的相对位置,那么如何将这个输出结果转换成对应图中的实际位置。下图给出了转换公式和示例:
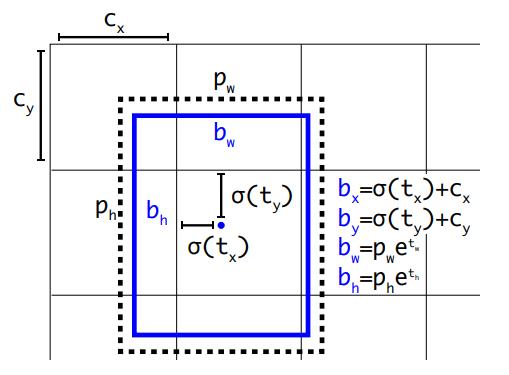
网络主要输出四个偏移量量(offset):
t
x
t_x
tx,
t
y
t_y
ty,
t
w
t_w
tw,
t
h
t_h
th,这里的(
c
x
c_x
cx,
c
y
)
c_y)
cy)指的是当前这个cell的左上角坐标(这里图中表示得并不清楚,容易产生误解),在计算时每个cell的尺度为1,因此对于
t
x
t_x
tx,
t
y
t_y
ty,添加了一个sigmoid函数,确保边界框的中心位置会约束在当前cell的内部,防止偏移过多。
式中的
p
w
p_w
pw,
p
h
p_h
ph分别为先验框的宽度与长度。
注意,这个
b
x
b_x
bx,
b
y
b_y
by,
b
w
b_w
bw,
b
h
b_h
bh是是相对于特征图大小的,在特征图中每个cell的长和宽均为1,特征图即最终输出的网格分布图。这里记特征图的大小为(W, H),文中是13x13,边界框相对于整张图片的位置和大小可由下面的公式进行计算。
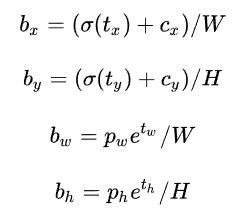
这样就得到了最终预测的输出值,可以和label做回归运算。
特征融合
YOLOv2最终的特种图的尺寸为13x13,下采样32倍,对于一些小目标来说,确实容易丢失。因此作者采用了一个很巧妙的方法,直接把前层的26x26的feature map 转换为13x13x4然后与13x13 通过channel叠加在一起,也是联合了高分辨率的feature map呀,提升了1%左右的map,类似经典的FPN。
动态尺寸调节
由于YOLOv2模型中只有卷积层和池化层,所以YOLOv2的输入可以不限于416x416大小的图片,因此作者提出了动态尺寸调节(multi-scale),即每经过一定的迭代次数,将网络输入的尺度进行次随机变换,让网络能够学习到不同尺度下的特征。这样的好处就在于,网络可以动态均衡速度和精度了,例如精度想高一点,那只要调大测试图的输入尺寸即可。
由于YOLOv2的下采样总步长为32,输入图片大小选择一系列为32倍数的值,输入图片最小为320x320,对应特征图大小为10x10;输入图片最大为608x608,对应特征图大小为19x19。在训练过程,每隔10个iterations随机选择一种输入图片大小,然后只需要修改对最后检测层的处理就可以重新训练。
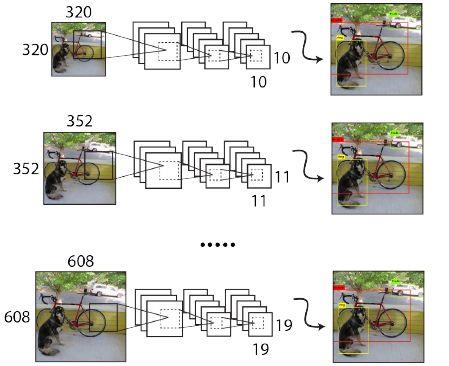
最后是损失函数,论文里没有具体提到,估计和YOLOv1差别不大。也有人通过分析源码发现其损失函数更加复杂,既然论文没详细涉及,这里也不做展开分析。YOLOv2的创新点基本就这些,论文里还有一些细节,可以去看原论文。
YOLOv3
YOLOv3的论文内容仅仅只有4页纸。一作同样是v1,v2的作者Joseph Redmon,它在论文中提到:“近一年时间都在沉迷推特,以至于工作时间不多,这不算是一篇正式的论文,更像是一个学术报告。”对于论文写得这么潇洒的作者,我去YOLO的官方主页找到了它的个人简历。

这么花哨的简历,只能感叹:牛人就是任性。在YOLOv3这篇论文发布之后,Joseph因看到自己发明的技术产生了负面影响,于是宣布退出CV领域。
回归正题,首先看YOLOv3的网络结构。
网络结构
YOLO v3在之前Darknet-19的基础上引入了残差模块,并进一步加深了网络,改进后的网络有53个卷积层,取名为Darknet-53,网络结构图如下所示:
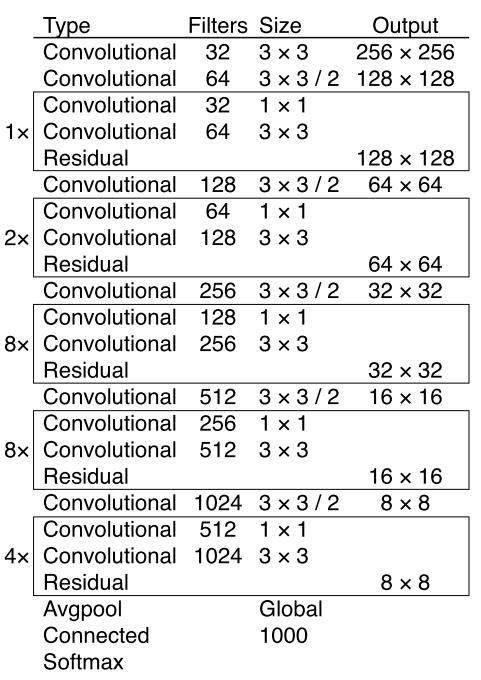
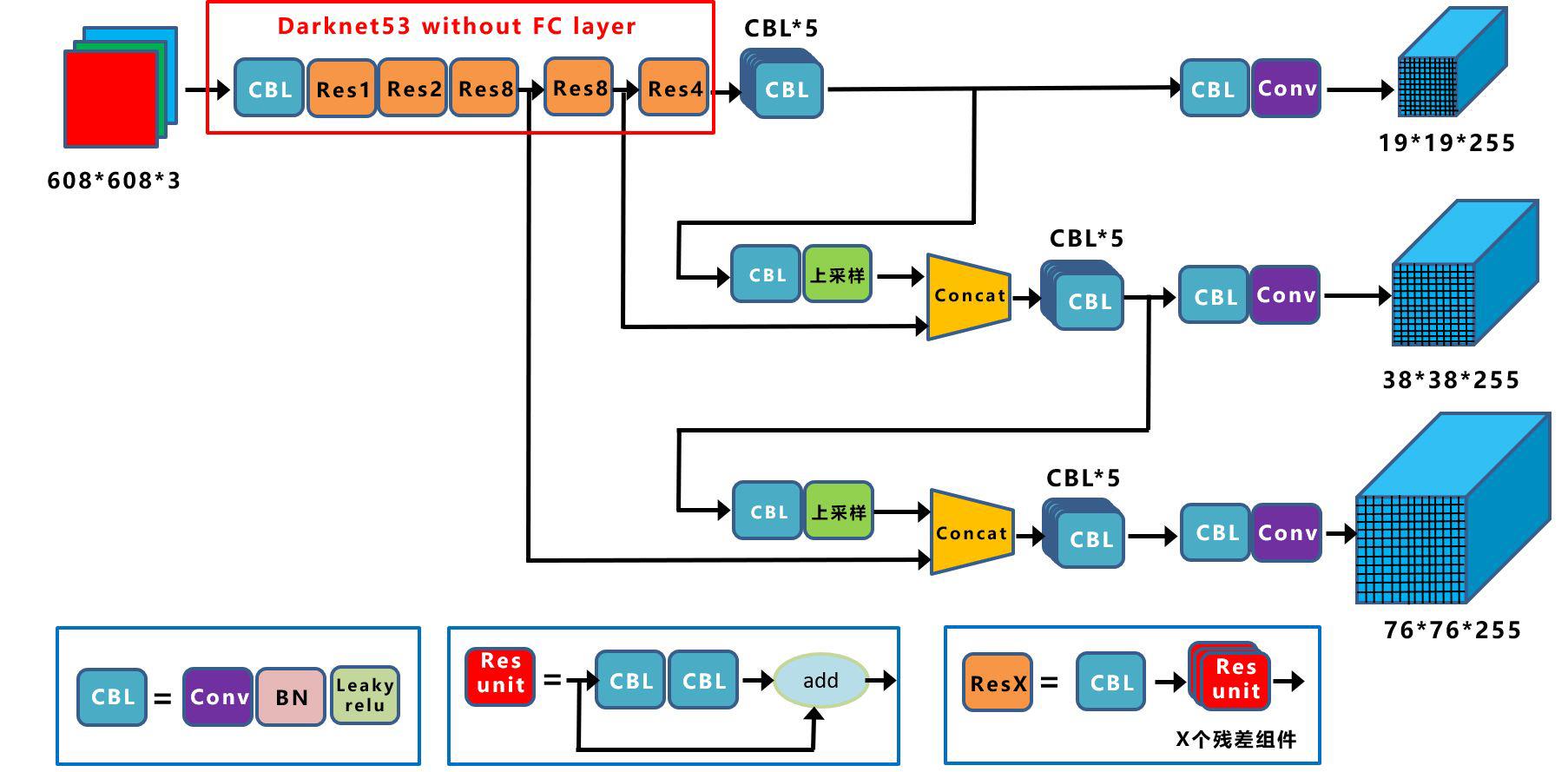
上图三个蓝色方框内表示Yolov3的三个基本组件:
(1)CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。
(2)Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
(3)ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。
其他基础操作:
(1)Concat:张量拼接,会扩充两个张量的维度,例如26×26×256和26×26×512两个张量拼接,结果是26×26×768。
(2)Add:张量相加,张量直接相加,不会扩充维度,例如104×104×128和104×104×128相加,结果还是104×104×128。
与Darknet-19对比可知,Darknet-53主要做了如下改进:
- 没有采用最大池化层,转而采用步长为2的卷积层进行下采样。
- 为了防止过拟合,在每个卷积层之后加入了一个BN层和一个Leaky ReLU。
- 引入了残差网络的思想,目的是为了让网络可以提取到更深层的特征,同时避免出现梯度消失或爆炸。
- 将网络的中间层和后面某一层的上采样进行张量拼接,达到多尺度特征融合的目的。
多尺度预测
YOLOv3借鉴了FPN的思想,从不同尺度提取特征。相比YOLOv2,YOLOv3提取最后3层特征图,不仅在每个特征图上分别独立做预测,同时通过将小特征图上采样到与大的特征图相同大小,然后与大的特征图拼接做进一步预测。用维度聚类的思想聚类出9种尺度的anchor box,将9种尺度的anchor box均匀的分配给3种尺度的特征图。
在COCO数据集上,这9个先验框是(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。
分配上,在最小的13x13特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326)适合检测较大的对象。
中等的26x26特征图上(中等感受野)应用中等大小的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。
较大的52x52特征图上(较小的感受野)应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。
多标签分类
在YOLOv2中,算法认定一个目标只从属于一个类别,根据网络输出类别的得分最大值,将其归为某一类。然而在一些复杂的场景中,单一目标可能从属于多个类别。比如在一个交通场景中,某目标的种类既属于汽车也属于卡车。
为实现多标签分类,YOLOv3使用了sigmoid函数,如果某一特征图的输出经过该函数处理后的值大于设定阈值(比如0.5),那么就认定该目标框所对应的目标属于该类。
同样,为了这一点,损失函数也做了相应调整,论文没写,不作细述。
YOLOv4
2020年,在YOLOv1-v3的作者Joseph Redmon退隐江湖之后,Alexey Bochkovskiy等人继续接棒研究,提出YOLOv4,论文发表在CVPR上。
相比于前面几个版本,YOLOv4没有做根本性的创新,只是将很多Tricks添加到了v3版本中,实现了检测速度和精度的最佳权衡。实验表明,在Tesla V100上,对MS COCO数据集的实时检测速度达到65 FPS,精度达到43.5%AP。
网络结构
YOLOv4把网络分成三个部分:Backbone(主干)、Neck(颈)、Head(头部)
- Backbone: CSPDarknet53
- Neck: SPP,PAN
- Head: YOLOv3
YOLOv4 = CSPDarknet53(主干)+ SPP附加模块(颈)+ PAN路径聚合(颈)+ YOLOv3(头部)
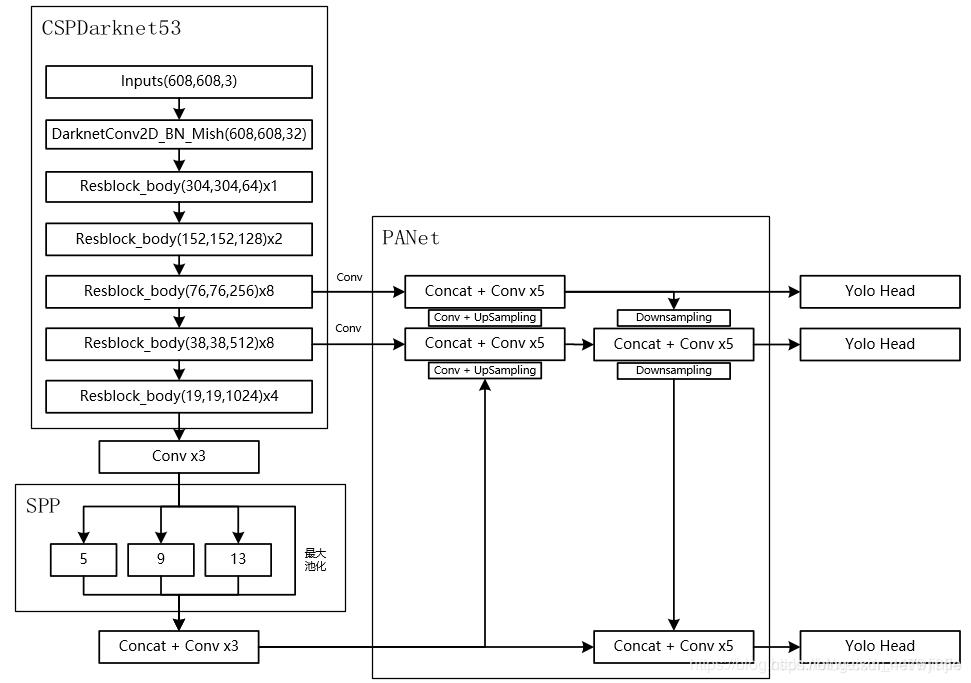
(1)CSPDarknet53
CSPDarknet53主要改进自CSPNet。CSPNet全称是Cross Stage Partial Network,在2019年由Chien-Yao Wang等人提出,用来解决以往网络结构需要大量推理计算的问题。
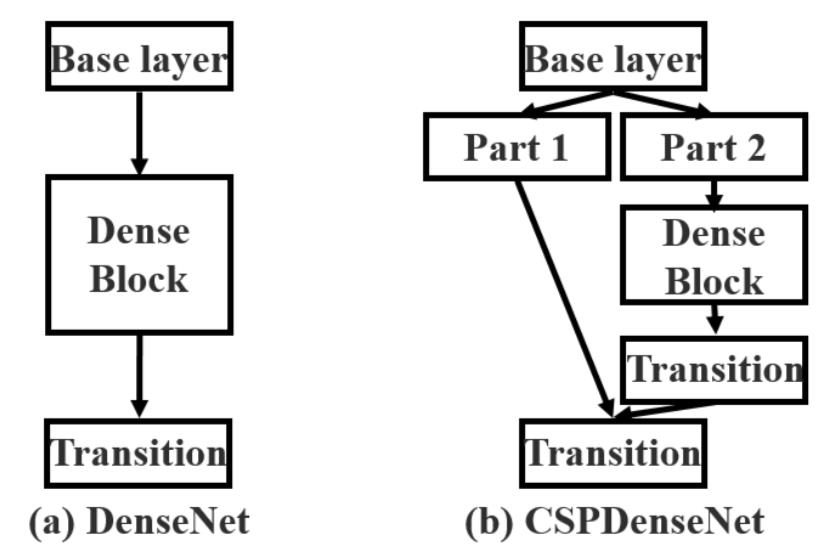
在YOLOv4中,将原来的Darknet53结构换为了CSPDarknet53,这在原来的基础上主要进行了两项改变:
- 将原来的Darknet53与CSPNet进行结合。
进行结合后,CSPnet的主要工作就是将原来的残差块的堆叠进行拆分,把它拆分成左右两部分:主干部分继续堆叠原来的残差块,支路部分则相当于一个残差边,经过少量处理直接连接到最后。具体结构如下:
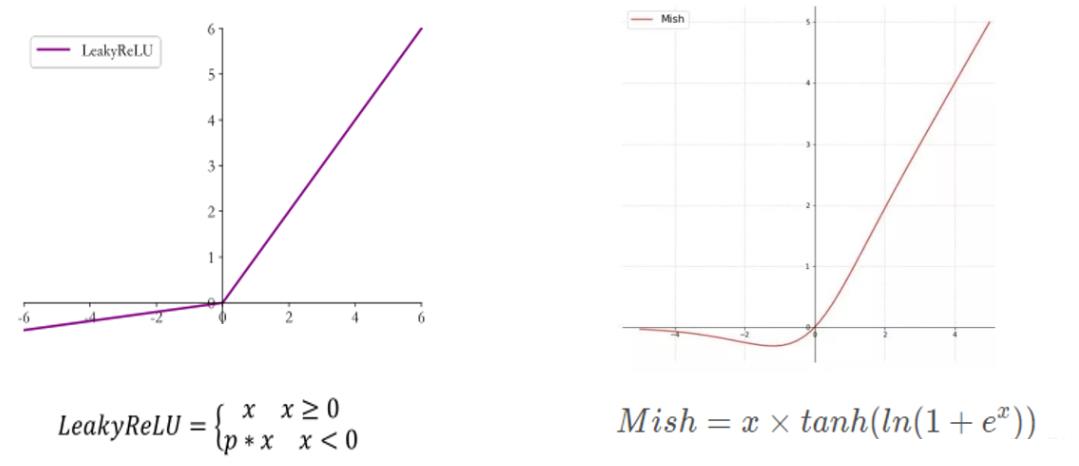
- 使用MIsh激活函数代替了原来的Leaky ReLU
在YOLOv3中,每个卷积层之后包含一个批量归一化层和一个Leaky ReLU。而在YOLOv4的主干网络CSPDarknet53中,使用Mish代替了原来的Leaky ReLU。Leaky ReLU和Mish激活函数的公式与图像如下:
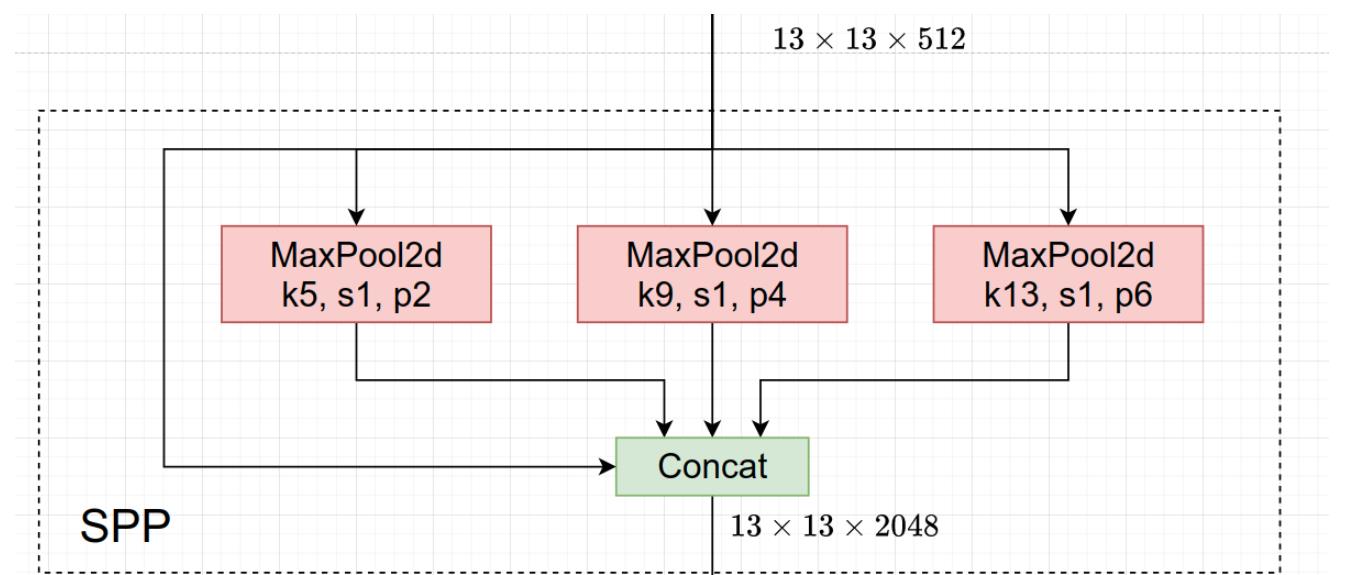
(2)SPP
SPP来源于ResNets作者何恺明的论文:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
SPP就是将特征层分别通过一个池化核大小为5x5、9x9、13x13的最大池化层,然后在通道方向进行concat拼接在做进一步融合,这样能够在一定程度上解决目标多尺度问题,如下图所示。
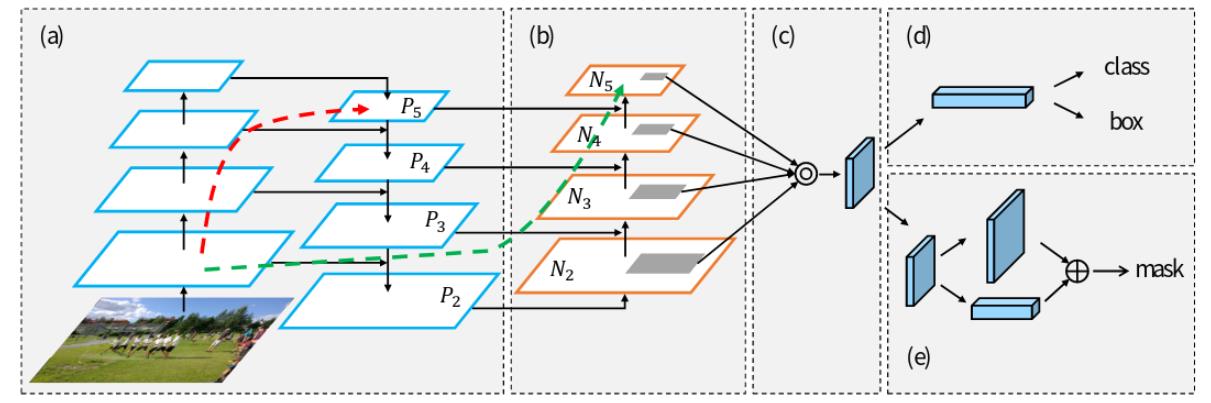
(3)PAN
PAN(Path Aggregation Network)结构其实就是在FPN(从顶到底信息融合)的基础上加上了从底到顶的信息融合,如下图所示,和原始PAN论文有所区别的是,YOLOv4更改了融合的计算方式,并非直接进行相加,而是在通道方向进行Concat拼接。
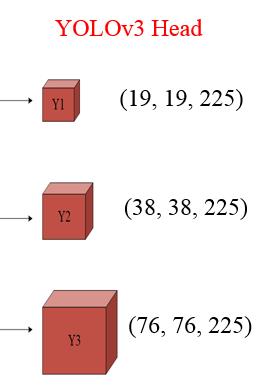
(4)YOLOv3 Head
在YOLOv4中,继承了YOLOv3的Head进行多尺度预测,提高了对不同size目标的检测性能。
位置宽高计算优化
在前面的YOLOv2位置宽高计算那里提到了目标的计算方式。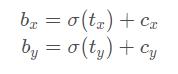
其中:
- t x t_x tx是网络预测的目标中心x坐标偏移量(相对于网格的左上角)
- t y t_y ty是网络预测的目标中心y坐标偏移量(相对于网格的左上角)
- c x c_x cx是对应网格左上角的x坐标
- c y c_y cy是对应网格左上角的y坐标
- σ \\sigma σ是sigmoid激活函数,将预测的偏移量限制在0到1之间,即预测的中心点不会超出对应的Grid Cell区域\\
但在YOLOv4的论文中作者认为这样做不太合理,比如当真实目标中心点非常靠近网格的左上角点(
σ
(
t
x
)
\\sigma(t_x)
σ(tx)和
σ
(
t
y
)
\\sigma(t_y)
σ(ty)应趋近于0)或右下角点(
σ
(
t
x
)
\\sigma(t_x)
σ(tx)和
σ
(
t
y
)
\\sigma(t_y)
σ(ty)应趋近于1)时,网络的预测值需要负无穷或者正无穷时才能取到,而这种很极端的值网络一般无法达到。为了解决这个问题,作者引入了一个大于1的缩放系数。
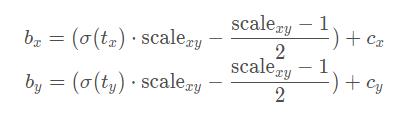
这样做可以扩大纵轴范围,换言之让函数更加”陡峭“。
数据增强Mosaic
为了扩充样本的丰富性,YOLOv4采用了很多数据增强的方法,比如下面这些:
- 随机缩放
- 翻转、旋转
- 图像扰动、加噪声、遮挡
- 改变亮度、对比对、饱和度、色调
- 随机裁剪(random crop)
- 随机擦除(random erase)
- Cutout
- MixUp
- CutMix
此外,YOLOv4还提出一种独特的数据增强方式Mosaic,即将四张图片拼接成一张图片,如图所示:

正则化方式Dropblock
Yolov4中使用的Dropblock,其实和常见网络中的Dropout功能类似,也是缓解过拟合的一种正则化方式。
Dropblock在2018年提出,论文地址:https://arxiv.org/pdf/1810.12890.pdf
Dropout是随机的删减丢弃一些信息,然而随机丢弃,卷积层仍然可以从相邻的激活单元学习到相同的信息。
Dropblock则是整块(block)进行丢弃,两者的区别如下图所示:
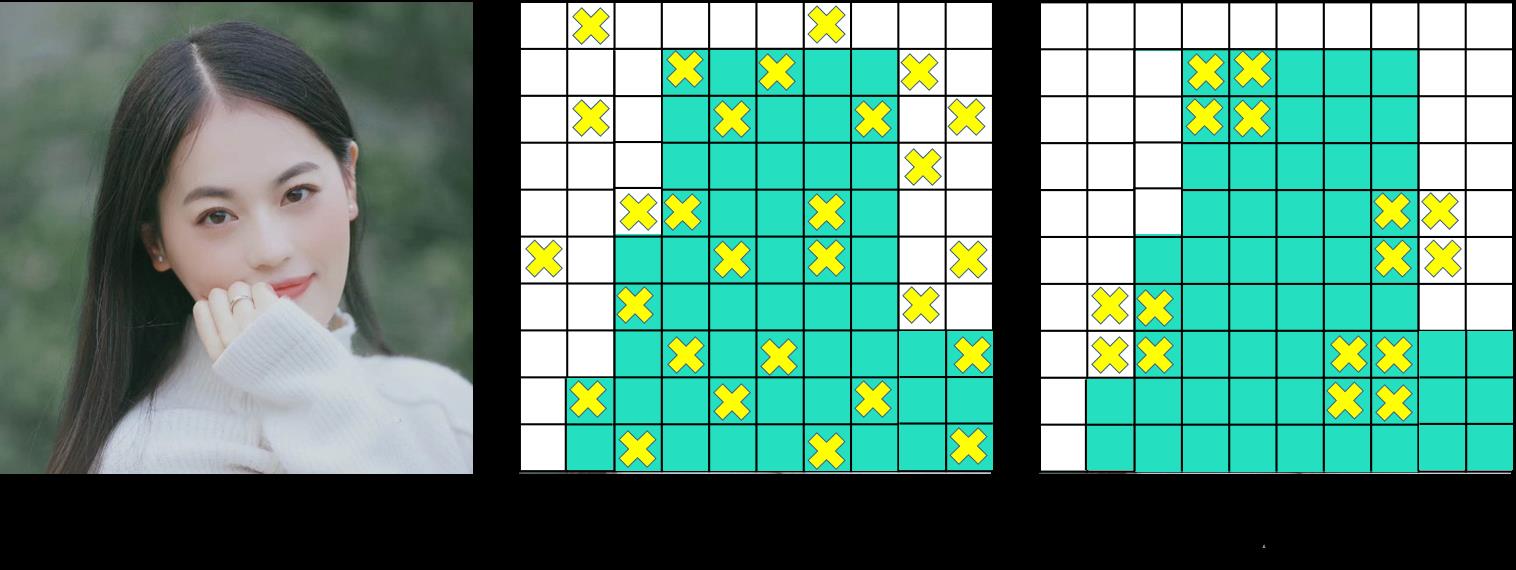
锚框优化
在YOLOv3中使用anchor模板是:
| 目标类型 | Anchors模板 |
|---|---|
| 小尺度 | (10×13),(16×30),(33×23) |
| 中尺度 | (30×61),(62×45),(59×119) |
| 大尺度 | (116×90),(156×198),(373×326) |
在YOLOv4中作者针对512×512尺度的图片,优化了anchor模板,尺寸如下:
| 目标类型 | Anchors模板 |
|---|---|
| 小尺度 | (12×16),(19×36),(40×28) |
| 中尺度 | (36×75),(76×55),(72×146) |
| 大尺度 | (142×110),(192×243),(459×401) |
回归损失优化
目标检测任务的损失函数一般由Classificition Loss(分类损失函数)和Bounding Box Regeression Loss(回归损失函数)两部分构成。
Bounding Box Regeression的Loss近些年的发展过程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020)
这些损失的主要区别是:
- IOU Loss:主要考虑检测框和目标框重叠面积。
- GIOU Loss:在IOU的基础上,解决边界框不重合时的问题。
- DIOU Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
- CIOU Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
首先看看起初提出的IOU损失有什么问题:
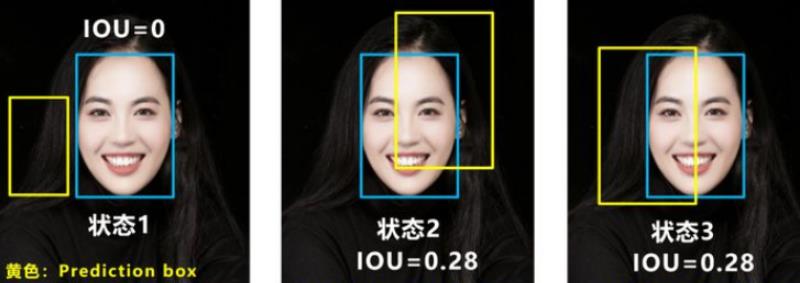
上图展示了IOU Loss的两个问题:
问题1:即状态1的情况,当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近,此时损失函数不可导,IOU Loss无法优化两个框不相交的情况。
问题2:即状态2和状态3的情况,当两个预测框大小相同,两个IOU也相同,IOU Loss无法区分两者相交情况的不同。
为了解决这两个问题,后续的一系列Loss对其进行改进,考虑更多因素,从而让定位更加准确。YOLOv4采用的是CIOU Loss,其计算公式如下:
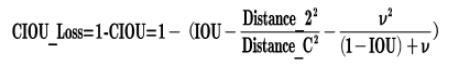
其中v是衡量长宽比一致性的参数,定义为:
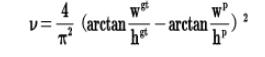
这样CIOU Loss综合考虑重叠面积、中心点距离,长宽比,解决了之前IOU Loss存在的问题。
总结
YOLOv4的内容很多,基本上都是将别人论文里提出的一些经验/技巧加入到YOLO网络中,并做了大量实验对比。上面只是一些比较经典的技巧,论文中还提到的内容还包括以下这些:
平衡正负样本的方法有:
- Focal loss
- OHEM(在线难分样本挖掘)
增大感受野技巧:
- SPP
- ASPP
- RFB
回归损失方面的改进:
- GIOU
- DIOU
- CIoU
注意力机制:
- Squeeze-and-Excitation (SE)
- Spatial Attention Module (SAM)
特征融合集成:
- FPN
- SFAM
- ASFF
- BiFPN (出自EfficientDet)
更好的激活函数:
- ReLU
- LReLU
- PReLU
- ReLU6
- SELU
- Swish
- hard-Swish
后处理非极大值抑制算法:
- soft-NMS
- DIoU NMS
YOLOv5
在YOLOv4刚提出来时,GitHub上就出现了YOLOv5仓库,但是其作者Glenn Jocher并没有发表相应论文,且YOLOv5至今仍在不断迭代新的内容。
代码仓库:https://github.com/ultralytics/yolov5
网络结构
网络结构主要由以下三部分组成[13]:
- Backbone: New CSP-Darknet53
- Neck: SPPF, New CSP-PAN
- Head: YOLOv3 Head
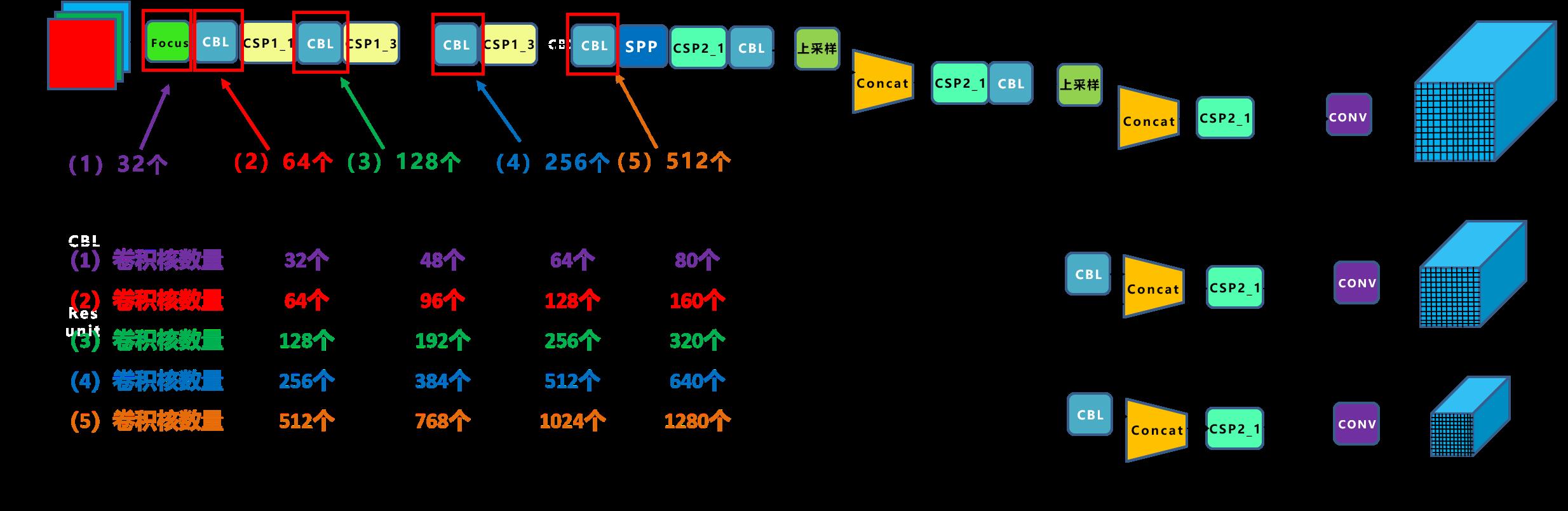
除此之外,仓库中n, s, m, l, x,n6, s6, m6, l6, x6共10种模型版本。我专业课程设计答辩时就被问道:yolov5s,yolov5m,yolov5l分别是用来检测小样本、中样本、大样本吗?错,这五个字母代表的是模型不同的宽度和深度。
在models/.yaml文件中,这几个模型的结构基本一样,不同的是depth_multiple和width_multiple这两个参数。
后面n6,s6那几个是6.0版本之后开始提出的,主要是应对更大分辨率的图片,对模型结构进行了调整。原先仍是32倍下采样,这几个是64倍下采样。
Neck部分由原先的SPP更新为SPPF,能够保证结果一致的情况下,让运算速度提升,其结构如下:
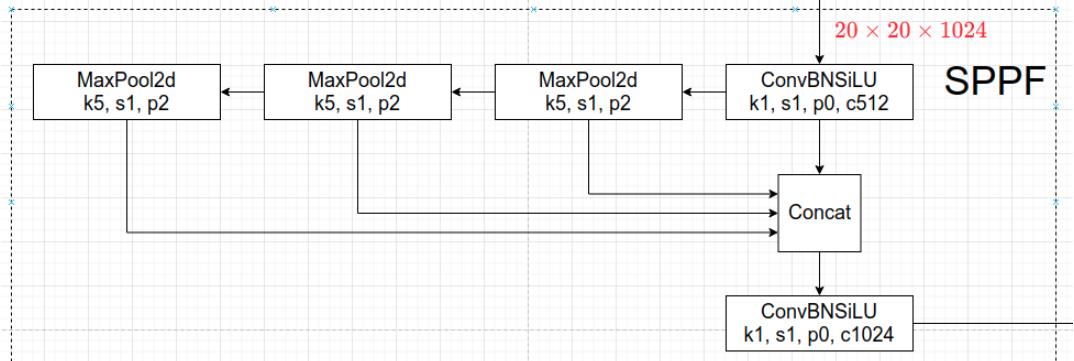
YOLOv4的PAN结构在YOLOv5中更换成CSP-PAN,添加了CSP结构。这个结构在YOLOv4的骨干部分也出现过。
头部部分,YOLOv3,v4,v5均保持一致。
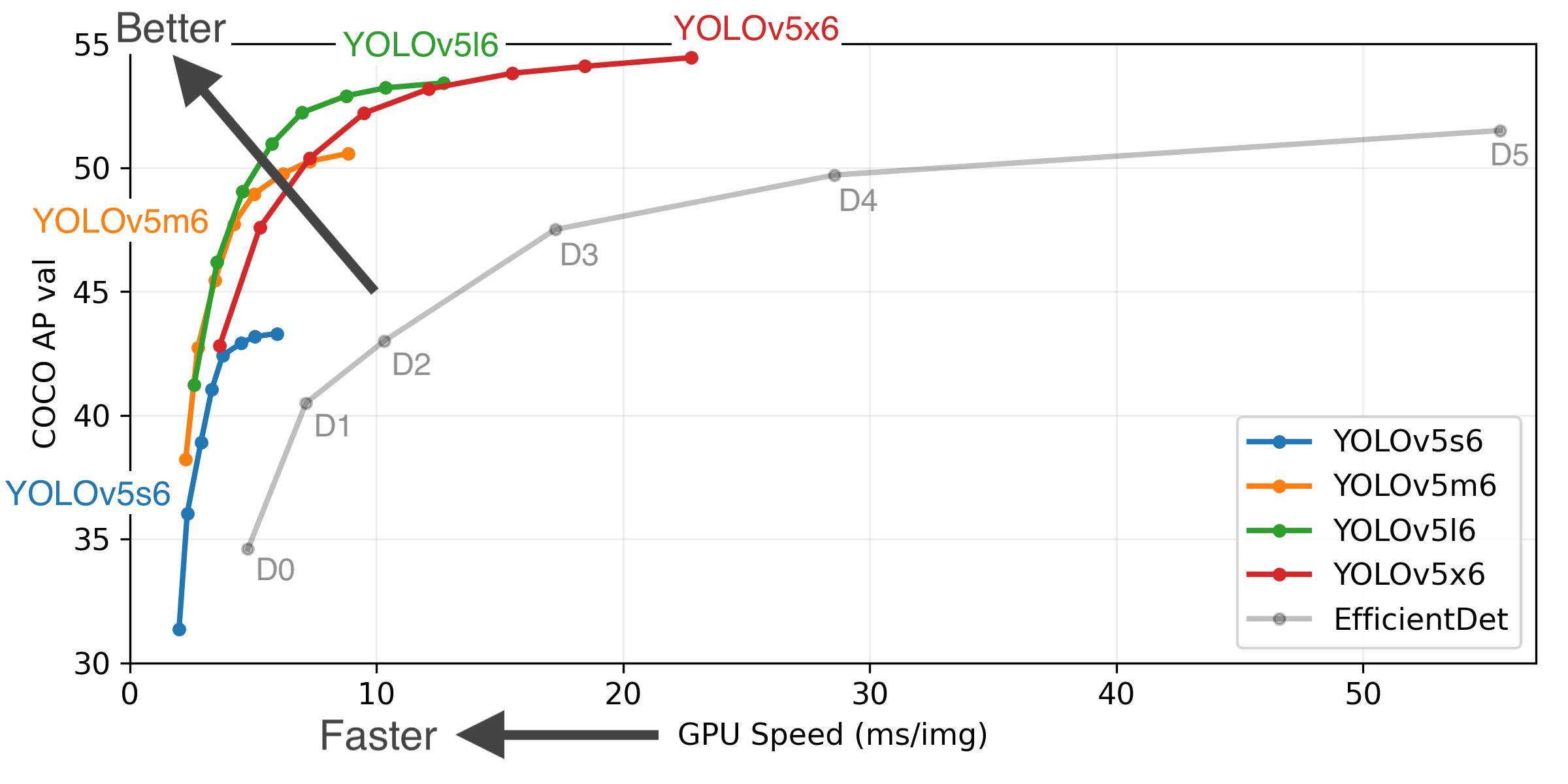
性能方面,根据官方出示的实验结果,可以发现YOLOv5 l系列在速度和准确率上面平衡的不错,YOLOv5 x系列准确率更高但舍弃了部分速度。因此,看到YOLOv5l被用的最频繁。
数据增强
YOLOv5采用了更多数据增强方式,具体设置hyp.scratch.yaml这个文件中进行设置,各参数的意义注释如下:
# 优化器相关
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3) 初始学习率
lrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf) 余弦退火超参数
momentum: 0.937 # SGD momentum/Adam beta1 学习率动量
weight_decay: 0.0005 # optimizer weight decay 5e-4 权重衰减系数
# 预热学习相关
warmup_epochs: 3.0 # warmup epochs (fractions ok) 预热学习epoch
warmup_momentum: 0.8 # warmup initial momentum 预热学习率动量
warmup_bias_lr: 0.1 # warmup initial bias lr 预热学习率
# 不同损失函数权重,以及其他损失函数相关内容
box: 0.05 # box loss gain giou损失的系数
cls: 0.5 # cls loss gain 分类损失的系数
cls_pw: 1.0 # cls BCELoss positive_weight 分类BCELoss中正样本的权重
obj: 1.0 # obj loss gain (scale with pixels) 有无物体损失的系数
obj_pw: 1.0 # obj BCELoss positive_weight 有无物体BCELoss中正样本的权重
iou_t: 0.20 # IoU training threshold 标签与anchors的iou阈值iou training threshold
# anchor锚框
anchor_t: 4.0 # anchor-multiple threshold 标签的长h宽w/anchor的长h_a宽w_a阈值, 即h/h_a, w/w_a都要在(1/4.0, 4.0)之间
# anchors: 3 # anchors per output layer (0 to ignore)
# 数据增强相关 - 色彩转换
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction) 色调
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction) 饱和度
hsv_v: 0.4 # image HSV-Value augmentation (fraction) 明度
# 数据增强相关:旋转、平移、扭曲等
degrees: 0.0 # image rotation (+/- deg) 旋转角度
translate: 0.1 # image translation (+/- fraction) 水平和垂直平移
scale: 0.5 # image scale (+/- gain) 缩放
shear: 0.0 # image shear (+/- deg) 剪切
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001 透视变换参数
# 数据增强相关 - 翻转
flipud: 0.0 # image flip up-down (probability) 上下翻转概率
fliplr: 0.5 # image flip left-right (probability) 左右翻转概率
# 数据增强相关 - mosaic/mixup
mosaic: 1.0 # image mosaic (probability) 进行mosaic的概率(一幅图像融合四幅图像)
mixup: 0.0 # image mixup (probability) 进行mixup的概率(对两个样本-标签数据对按比例相加后生成新的样本-标签数据)
数据增强中最后两个mosaic和mixup可能一下子没看明白,mosaic其实就是YOLOv4中的那种数据增强方案,mixup和cutmix差不多,看到一幅图[13]画的比较直观,放置如下:
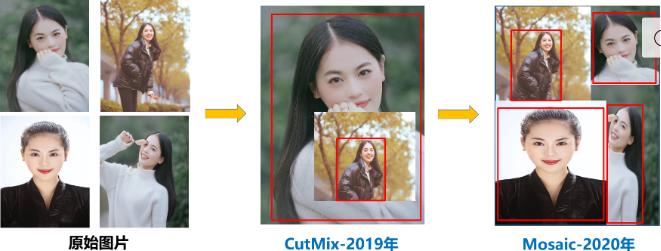
这样数据增强的好处是,可以加强小样本的检测效果。
自适应锚框计算
在YOLOv3、YOLOv4中,训练不同的数据集时,计算初始锚框的值是通过单独的K-means聚类得到,在YOLOv5中,这个功能被嵌入到训练过程中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
在train.py中,有个noautoanchor参数可用来控制是否开启自适应锚框计算,默认是开启状态,如果想要关闭,可以设为False。
自适应图片缩放
因为YOLO需要下采样32倍,因此输入图片通常为32的倍数,比如416×416,608×608。对于不同长宽的原始图片,通常采用的方式是将原始图片统一缩放到一个标准尺寸,比如这样:

这里我初看时产生了一个疑问:为什么不直接Resize进行缩放呢?因为直接Resize的后果是图片会被拉伸变形,这样检测出的框就是不准确的。因此缩放填充必须等比例的缩放,多余部分用黑边(图示是黑色,实际是灰色)填充。
但是,如果黑边较多,则存在信息冗余,影响推理速度。于是YOLOv5代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。
首先要明确的是,YOLOv5不要求输入必须是正方形图片,只需要满足长宽均是32的倍数即可。因此,可以先通过计算,得到一个较小的缩放系数,然后原始长宽
以上是关于目标检测从YOLOv1到YOLOX(理论梳理)的主要内容,如果未能解决你的问题,请参考以下文章