使用Python的线性回归问题,怎么解决
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Python的线性回归问题,怎么解决相关的知识,希望对你有一定的参考价值。
参考技术A本文中,我们将进行大量的编程——但在这之前,我们先介绍一下我们今天要解决的实例问题。
1) 预测房子价格

我们想预测特定房子的价值,预测依据是房屋面积。
2) 预测下周哪个电视节目会有更多的观众

闪电侠和绿箭侠是我最喜欢的电视节目。我想看看下周哪个节目会有更多的观众。
3) 替换数据集中的缺失值
我们经常要和带有缺失值的数据集打交道。这部分没有实战例子,不过我会教你怎么去用线性回归替换这些值。
所以,让我们投入编程吧(马上)
在动手之前,去把我以前的文章(Python Packages for Data Mining)中的程序包安装了是个好主意。
1) 预测房子价格
我们有下面的数据集:
输入编号
平方英尺
价格
1 150 6450
2 200 7450
3 250 8450
4 300 9450
5 350 11450
6 400 15450
7 600 18450
步骤:
在线性回归中,我们都知道必须在数据中找出一种线性关系,以使我们可以得到θ0和θ1。 我们的假设方程式如下所示:
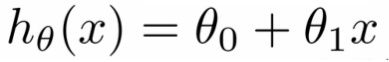
其中: hθ(x)是关于特定平方英尺的价格值(我们要预测的值),(意思是价格是平方英尺的线性函数); θ0是一个常数; θ1是回归系数。
那么现在开始编程:
步骤1
打开你最喜爱的文本编辑器,并命名为predict_house_price.py。 我们在我们的程序中要用到下面的包,所以把下面代码复制到predict_house_price.py文件中去。
Python
1
2
3
4
5
# Required Packages
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
运行一下你的代码。如果你的程序没错,那步骤1基本做完了。如果你遇到了某些错误,这意味着你丢失了一些包,所以回头去看看包的页面。 安装博客文章中所有的包,再次运行你的代码。这次希望你不会遇到任何问题。
现在你的程序没错了,我们继续……
步骤2
我把数据存储成一个.csv文件,名字为input_data.csv 所以让我们写一个函数把数据转换为X值(平方英尺)、Y值(价格)
Python
1
2
3
4
5
6
7
8
9
# Function to get data
def get_data(file_name):
data = pd.read_csv(file_name)
X_parameter = []
Y_parameter = []
for single_square_feet ,single_price_value in zip(data['square_feet'],data['price']):
X_parameter.append([float(single_square_feet)])
Y_parameter.append(float(single_price_value))
return X_parameter,Y_parameter
第3行:将.csv数据读入Pandas数据帧。
第6-9行:把Pandas数据帧转换为X_parameter和Y_parameter数据,并返回他们。
所以,让我们把X_parameter和Y_parameter打印出来:
Python
1
2
3
[[150.0], [200.0], [250.0], [300.0], [350.0], [400.0], [600.0]]
[6450.0, 7450.0, 8450.0, 9450.0, 11450.0, 15450.0, 18450.0]
[Finished in 0.7s]
脚本输出: [[150.0], [200.0], [250.0], [300.0], [350.0], [400.0], [600.0]] [6450.0, 7450.0, 8450.0, 9450.0, 11450.0, 15450.0, 18450.0] [Finished in 0.7s]
步骤3
现在让我们把X_parameter和Y_parameter拟合为线性回归模型。我们要写一个函数,输入为X_parameters、Y_parameter和你要预测的平方英尺值,返回θ0、θ1和预测出的价格值。
Python
1
2
3
4
5
6
7
8
9
10
11
12
# Function for Fitting our data to Linear model
def linear_model_main(X_parameters,Y_parameters,predict_value):
# Create linear regression object
regr = linear_model.LinearRegression()
regr.fit(X_parameters, Y_parameters)
predict_outcome = regr.predict(predict_value)
predictions =
predictions['intercept'] = regr.intercept_
predictions['coefficient'] = regr.coef_
predictions['predicted_value'] = predict_outcome
return predictions
第5-6行:首先,创建一个线性模型,用我们的X_parameters和Y_parameter训练它。
第8-12行:我们创建一个名称为predictions的字典,存着θ0、θ1和预测值,并返回predictions字典为输出。
所以让我们调用一下我们的函数,要预测的平方英尺值为700。
Python
1
2
3
4
5
6
X,Y = get_data('input_data.csv')
predictvalue = 700
result = linear_model_main(X,Y,predictvalue)
print "Intercept value " , result['intercept']
print "coefficient" , result['coefficient']
print "Predicted value: ",result['predicted_value']
脚本输出:Intercept value 1771.80851064 coefficient [ 28.77659574] Predicted value: [ 21915.42553191] [Finished in 0.7s]
这里,Intercept value(截距值)就是θ0的值,coefficient value(系数)就是θ1的值。 我们得到预测的价格值为21915.4255——意味着我们已经把预测房子价格的工作做完了!
为了验证,我们需要看看我们的数据怎么拟合线性回归。所以我们需要写一个函数,输入为X_parameters和Y_parameters,显示出数据拟合的直线。
Python
1
2
3
4
5
6
7
8
9
10
# Function to show the resutls of linear fit model
def show_linear_line(X_parameters,Y_parameters):
# Create linear regression object
regr = linear_model.LinearRegression()
regr.fit(X_parameters, Y_parameters)
plt.scatter(X_parameters,Y_parameters,color='blue')
plt.plot(X_parameters,regr.predict(X_parameters),color='red',linewidth=4)
plt.xticks(())
plt.yticks(())
plt.show()
那么调用一下show_linear_line函数吧:
Python
1
show_linear_line(X,Y)
脚本输出:
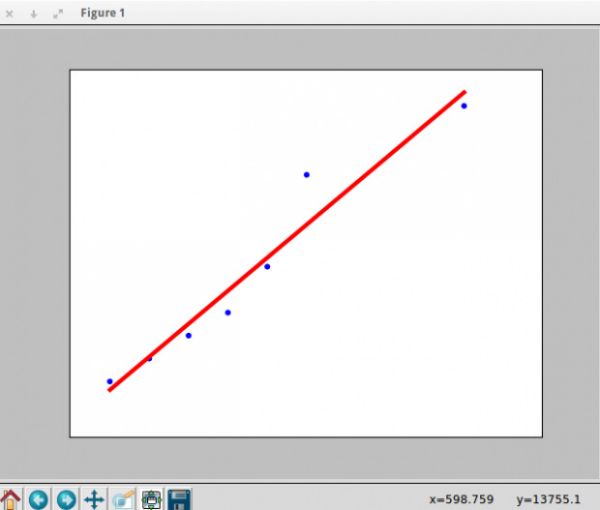
2)预测下周哪个电视节目会有更多的观众

闪电侠是一部由剧作家/制片人Greg Berlanti、Andrew Kreisberg和Geoff Johns创作,由CW电视台播放的美国电视连续剧。它基于DC漫画角色闪电侠(Barry Allen),一个具有超人速度移动能力的装扮奇特的打击犯罪的超级英雄,这个角色是由Robert Kanigher、John Broome和Carmine Infantino创作。它是绿箭侠的衍生作品,存在于同一世界。该剧集的试播篇由Berlanti、Kreisberg和Johns写作,David Nutter执导。该剧集于2014年10月7日在北美首映,成为CW电视台收视率最高的电视节目。
绿箭侠是一部由剧作家/制片人 Greg Berlanti、Marc Guggenheim和Andrew Kreisberg创作的电视连续剧。它基于DC漫画角色绿箭侠,一个由Mort Weisinger和George Papp创作的装扮奇特的犯罪打击战士。它于2012年10月10日在北美首映,与2012年末开始全球播出。主要拍摄于Vancouver、British Columbia、Canada,该系列讲述了亿万花花公子Oliver Queen,由Stephen Amell扮演,被困在敌人的岛屿上五年之后,回到家乡打击犯罪和腐败,成为一名武器是弓箭的神秘义务警员。不像漫画书中,Queen最初没有使用化名”绿箭侠“。
由于这两个节目并列为我最喜爱的电视节目头衔,我一直想知道哪个节目更受其他人欢迎——谁会最终赢得这场收视率之战。 所以让我们写一个程序来预测哪个电视节目会有更多观众。 我们需要一个数据集,给出每一集的观众。幸运地,我从维基百科上得到了这个数据,并整理成一个.csv文件。它如下所示。
闪电侠
闪电侠美国观众数
绿箭侠
绿箭侠美国观众数
1 4.83 1 2.84
2 4.27 2 2.32
3 3.59 3 2.55
4 3.53 4 2.49
5 3.46 5 2.73
6 3.73 6 2.6
7 3.47 7 2.64
8 4.34 8 3.92
9 4.66 9 3.06
观众数以百万为单位。
解决问题的步骤:
首先我们需要把数据转换为X_parameters和Y_parameters,不过这里我们有两个X_parameters和Y_parameters。因此,把他们命名为flash_x_parameter、flash_y_parameter、arrow_x_parameter、arrow_y_parameter吧。然后我们需要把数据拟合为两个不同的线性回归模型——先是闪电侠,然后是绿箭侠。 接着我们需要预测两个电视节目下一集的观众数量。 然后我们可以比较结果,推测哪个节目会有更多观众。
步骤1
导入我们的程序包:
Python
1
2
3
4
5
6
7
# Required Packages
import csv
import sys
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
步骤2
写一个函数,把我们的数据集作为输入,返回flash_x_parameter、flash_y_parameter、arrow_x_parameter、arrow_y_parameter values。
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
# Function to get data
def get_data(file_name):
data = pd.read_csv(file_name)
flash_x_parameter = []
flash_y_parameter = []
arrow_x_parameter = []
arrow_y_parameter = []
for x1,y1,x2,y2 in zip(data['flash_episode_number'],data['flash_us_viewers'],data['arrow_episode_number'],data['arrow_us_viewers']):
flash_x_parameter.append([float(x1)])
flash_y_parameter.append(float(y1))
arrow_x_parameter.append([float(x2)])
arrow_y_parameter.append(float(y2))
return flash_x_parameter,flash_y_parameter,arrow_x_parameter,arrow_y_parameter
现在我们有了我们的参数,来写一个函数,用上面这些参数作为输入,给出一个输出,预测哪个节目会有更多观众。
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Function to know which Tv show will have more viewers
def more_viewers(x1,y1,x2,y2):
regr1 = linear_model.LinearRegression()
regr1.fit(x1, y1)
predicted_value1 = regr1.predict(9)
print predicted_value1
regr2 = linear_model.LinearRegression()
regr2.fit(x2, y2)
predicted_value2 = regr2.predict(9)
#print predicted_value1
#print predicted_value2
if predicted_value1 > predicted_value2:
print "The Flash Tv Show will have more viewers for next week"
else:
print "Arrow Tv Show will have more viewers for next week"
把所有东西写在一个文件中。打开你的编辑器,把它命名为prediction.py,复制下面的代码到prediction.py中。
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# Required Packages
import csv
import sys
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
# Function to get data
def get_data(file_name):
data = pd.read_csv(file_name)
flash_x_parameter = []
flash_y_parameter = []
arrow_x_parameter = []
arrow_y_parameter = []
for x1,y1,x2,y2 in zip(data['flash_episode_number'],data['flash_us_viewers'],data['arrow_episode_number'],data['arrow_us_viewers']):
flash_x_parameter.append([float(x1)])
flash_y_parameter.append(float(y1))
arrow_x_parameter.append([float(x2)])
arrow_y_parameter.append(float(y2))
return flash_x_parameter,flash_y_parameter,arrow_x_parameter,arrow_y_parameter
# Function to know which Tv show will have more viewers
def more_viewers(x1,y1,x2,y2):
regr1 = linear_model.LinearRegression()
regr1.fit(x1, y1)
predicted_value1 = regr1.predict(9)
print predicted_value1
regr2 = linear_model.LinearRegression()
regr2.fit(x2, y2)
predicted_value2 = regr2.predict(9)
#print predicted_value1
#print predicted_value2
if predicted_value1 > predicted_value2:
print "The Flash Tv Show will have more viewers for next week"
else:
print "Arrow Tv Show will have more viewers for next week"
x1,y1,x2,y2 = get_data('input_data.csv')
#print x1,y1,x2,y2
more_viewers(x1,y1,x2,y2)
可能你能猜出哪个节目会有更多观众——但运行一下这个程序看看你猜的对不对。
3) 替换数据集中的缺失值
有时候,我们会遇到需要分析包含有缺失值的数据的情况。有些人会把这些缺失值舍去,接着分析;有些人会用最大值、最小值或平均值替换他们。平均值是三者中最好的,但可以用线性回归来有效地替换那些缺失值。
这种方法差不多像这样进行。
首先我们找到我们要替换那一列里的缺失值,并找出缺失值依赖于其他列的哪些数据。把缺失值那一列作为Y_parameters,把缺失值更依赖的那些列作为X_parameters,并把这些数据拟合为线性回归模型。现在就可以用缺失值更依赖的那些列预测缺失的那一列。
一旦这个过程完成了,我们就得到了没有任何缺失值的数据,供我们自由地分析数据。
为了练习,我会把这个问题留给你,所以请从网上获取一些缺失值数据,解决这个问题。一旦你完成了请留下你的评论。我很想看看你的结果。
个人小笔记:
我想分享我个人的数据挖掘经历。记得在我的数据挖掘引论课程上,教师开始很慢,解释了一些数据挖掘可以应用的领域以及一些基本概念。然后突然地,难度迅速上升。这令我的一些同学感到非常沮丧,被这个课程吓到,终于扼杀了他们对数据挖掘的兴趣。所以我想避免在我的博客文章中这样做。我想让事情更轻松随意。因此我尝试用有趣的例子,来使读者更舒服地学习,而不是感到无聊或被吓到。
谢谢读到这里——请在评论框里留下你的问题或建议,我很乐意回复你。
以上是关于使用Python的线性回归问题,怎么解决的主要内容,如果未能解决你的问题,请参考以下文章