“众所周知,视频不能P”,GAN:是吗?
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了“众所周知,视频不能P”,GAN:是吗?相关的知识,希望对你有一定的参考价值。
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
见过用GAN来P图,见过用GANP视频吗?
瞧,原本一直在面无表情地讲话的人,全程露出了微笑;原本得4、50岁的人,直接变20几岁了:

另一边,正在微笑唱歌的“赫敏”一下子愤怒起来,还能换上一张几岁小孩的脸:

奥巴马也如此,4种版本的面部状态信手拈来,甚至连性别都给P成女的了:

不管人脸表情和状态如何变化,这些视频都没有给人任何违和感,全程如此的丝滑~
哦对,除了真人,动漫视频里的脸也可以P:

有点厉害了。
基于GAN的视频面部编辑
这个模型出自以色列特拉维夫大学。

众所周知,GAN在其潜空间内编码丰富语义的能力,已经被广泛用于人脸编辑。
不过将它用在视频中还是有点挑战性:一个是缺乏高质量数据集,一个是需要克服时间一致性 (temporal coherency)这一基本障碍。
不过研究人员认为,第二点这个障碍主要是人为的。
因为原视频本具备时间一致性,编辑后的视频却变了,部分原因就是在editing pipeline中对一些组件(component)处理不当。
而他们提出的这个视频人脸语义编辑框架,相对于当前技术水平做出了重大改进:
只采用了标准的非时序StyleGAN2,对GAN editing pipeline中的不同组件进行分析,确定哪些组件具备一致性,就用这些组件来操作。
整个过程不涉及任何用来维持时间一致性的额外操作。
具体流程一共分为六步:
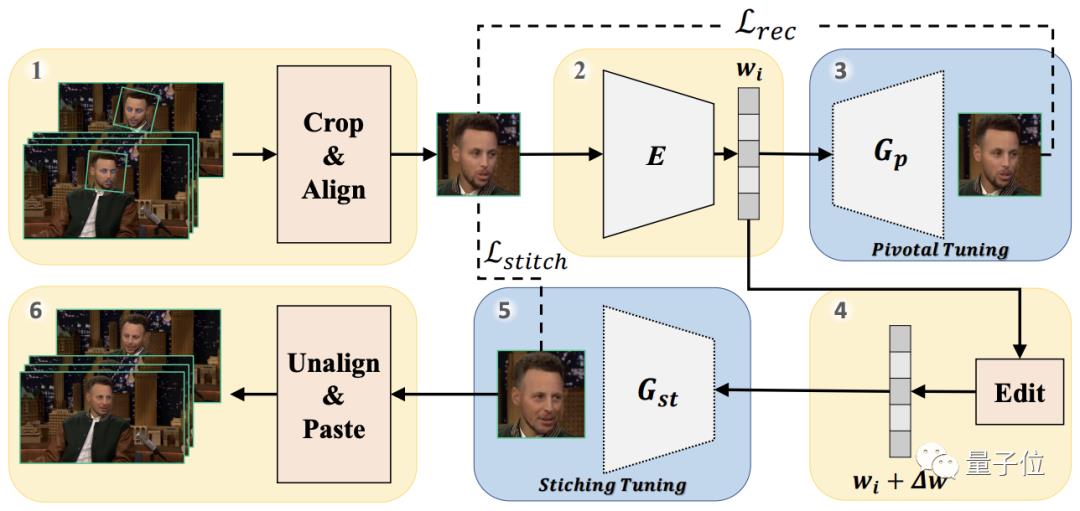
1、输入视频首先被分割成帧,每帧中的人脸都被裁剪下来并对齐;
2、使用预训练的e4e编码器,将每张已裁剪的人脸反演到预训练的StyleGAN2的潜空间中;
3、在所有并行帧中使用PTI(最新提出的一种视频人脸编辑方法)对生成器进行微调,纠正初始反演中的错误,恢复全局一致性;
4、所有帧通过使用固定的方向和步长,线性地操纵其轴心潜码(pivot latent codes)进行相应编辑;
5、再次微调生成器,将背景和编辑过的人脸“缝合”在一起;
6、反转对齐步骤,并将修改后的人脸粘贴回视频中。

△ 注意颈部曾产生了大量瑕疵,在最后一步完全修复好
和SOTA模型对比
这个模型效果到底有多好,来个对比就知道:



第一个是变年轻、第二、三个都是变老。
可以明显看到目前的SOTA模型(Latent Transformer)和PTI模型中的人脸会“抽巴”,并出现一些伪影,而这个新模型就避开了这些问题。
此外,研究人员还进行了时间一致性测试。
指标包含两个:
局部时间一致性(TL-ID),通过现成的一致性检测网络来评估相邻两帧之间的一致性。TL-ID分数越高,表明该方法产生的效果越平滑,没有明显的局部抖动。
全局时间一致性(TG-ID),同样使用一致性检测网络来评估所有可能的帧(不一定相邻)之间的相似性。得分为1表示该方法成功保持了和原视频的时间一致性。
结果如下:
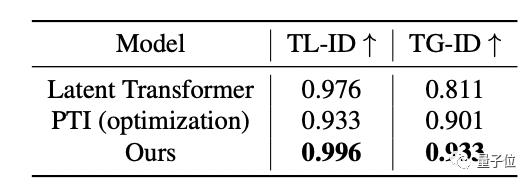
可以看到,这个新模型在两项指标中都略胜一筹。
最后,代码将于2月14号发布,感兴趣的朋友可以蹲一蹲了~
论文地址:
https://arxiv.org/abs/2201.08361
项目主页:
https://stitch-time.github.io/
以上是关于“众所周知,视频不能P”,GAN:是吗?的主要内容,如果未能解决你的问题,请参考以下文章
为什么对抗生成网络(GAN)被誉为过去20年来深度学习中最酷的想法?
ECCV 2018 | 给Cycle-GAN加上时间约束,CMU等提出新型视频转换方法Recycle-GAN