2022春山东大学人工智能导论期末题库附答案
Posted timerring
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2022春山东大学人工智能导论期末题库附答案相关的知识,希望对你有一定的参考价值。
人工智能题目汇总
正向规则的一般形式是:如果前提则()
答案:结论
隐马尔可夫模型可以由五个元素来描述:隐含状态,可观测状态,初始状态概率矩阵,(),()
答案:隐含状态转移概率矩阵 观测状态转移概率矩阵
隐马尔可夫模型研究的基本问题不包括以下哪一种(B)
A、评估问题 B、计算问题
C、解码问题 D、学习问题
隐马尔可夫模型是一个双重随机过程——具有一定状态数的(B)和显示随机函数集
A、马尔可夫链 B、隐马尔可夫链
C、贝叶斯模型 D、可观测状态集合
- 可以解决无监督学习的隐马尔可夫问题
A、二分法 B、冒泡法 C、辗转相除法 D、Baum-Welch算法
人工智能在技术层面上存在如下6大瓶颈:数据瓶颈、泛化瓶颈、(能耗瓶颈)、语义鸿沟瓶颈、可解释性瓶颈、可靠性瓶颈
马尔可夫链(Markov Chain, MC)是概率论和数理统计中具有马尔可夫性质(Markov property)且存在于离散的指数集(index set)和状态空间(state space)内的(A)过程
A随机 B固定 C遍历 D确定
为了解决隐马尔科夫模型中的解码问题,我们提出了(Viterbi)算法。
填空题:
1.在隐马尔可夫模型(HMM)中,我们_______(知道/不知道)模型具体的状态序列,_______(知道/不知道)状态转移的概率。
答案:不知道,知道
2.隐马尔可夫模型在众多领域有广泛的使用,如____(举一例即可)。
答案:(语音识别、机器翻译、中文分词、命名实体识别、词性标注、基因识别)
3.EM算法用于无监督学习中时输入_______输出_______
答案:(观测数据)(隐马尔可夫模型参数)
4.( )和( )都离散的马尔科夫过程称为马尔科夫链。
答:时间 状态
5.EM算法是一种迭代优化策略,其基本思想是:首先根据_____,估计出模型参数的值;然后再依据上一步估计出的参数值估计____,然后反复迭代,直至最后收敛,迭代结束。
答案:己经给出的观测数据;缺失数据的值;
6.要解决隐马尔科夫链的三个基本问题之一的概率计算问题,即“给定模型λ=(A,B,π)λ=(A,B,π)和观测序列OO,计算在模型λλ下观测序列出现的最大概率P(O|λ)”,需要用到的算法是____。
答案:(前向、后向算法)
7.EM计算方法每一次迭代都分为()、()这两步。
答案:期望步 极大步
选择题:
1、请选择下面可以应用隐马尔科夫(HMM)模型的选项( )
A.基因序列数据集
B.电影浏览数据集
C.股票市场数据集
D.所有以上
答案:D
2.下列模型属于机器学习生成式模型的是()
A.朴素贝叶斯
B.隐马尔科夫模型(HMM)
C.马尔科夫随机场(Markov Random Fields)
D.深度信念网络(DBN)
答案:ABCD
3.EM算法用于无监督学习时执行流程为()
A初始化模型参数;迭代求解;迭代终止;模型参数收敛,得到模型参数
B初始化模型参数;模型参数收敛;迭代求解;迭代终止,得到模型参数
C迭代求解;初始化模型参数;迭代终止;模型参数收敛,得到模型参数
D迭代求解;迭代终止;初始化模型参数;模型参数收敛,得到模型参数
答案:A
- 给定一个模型,如何计算某个特定的输出序列的概率?
A.Forward-Backward算法
B.维特比算法
C.鲍姆-韦尔奇算法
D.CNN算法
答案:A
5.下列关于EM算法的说法中,不正确的是()。
A、EM算法是迭代求解最大值的算法,同时算法在每一次迭代时分为两步,E步和M步。
B、EM算法是为了解决数据缺失情况下的参数估计问题。
C、EM算法中的极大似然估计就是用来估计模型参数的统计学方法。
D、EM算法不可以保证收敛到一个稳定点,即EM算法不是收敛的。
答案:D
(解析:EM算法可以保证收敛到一个稳定点,即EM算法是一定收敛的。)
6.HMM由马尔科夫链和一般随机过程组成,他们分别由( )描述。
A.观察值概率、转移概率
B.转移概率、观察值概率
C.初始概率、转移概率
D、观察值概率、初始概率
答案:B
7.关于极大似然估计(Maximum Likelihood Estimate,MLE),说法正确的是?()
A. MLE 不存在
B. MLE 总是存在
C. 如果 MLE 存在,那么它的解可能不是唯一的
D. 如果 MLE 存在,那么它的解一定是唯一的
答案:C
- 孤立词识别中,使用隐马尔科夫模型时需要考虑的三个方面为_______、_______、_______、
答案:求值,解码,训练
- 通常来讲,一个隐马尔可夫模型可以用_______、_______、_______来简洁表示
答案:隐含状态转移概率矩阵 A、 观测状态转移概率矩阵 B、 初始状态概率矩阵 π
3:下面选项中,不是HMM语音系统的实现所需要求的是
A.语音信号预处理与特征提取
B.声学模型与模式匹配
C.语言模型与语言处理
D.文本建模与纹理建模
答案:D
- 设有N个缸,每个缸中装有很多彩球,球的颜色由一组概率分布描述。实验进行方式如下
根据初始概率分布,随机选择N个缸中的一个开始实验
根据缸中球颜色的概率分布,随机选择一个球,记球的颜色为O1,并把球放回缸中
根据描述缸的转移的概率分布,随机选择下一口缸,重复以上步骤。
上述材料中,与隐马尔可夫模型五大基本要素里,相对应错误的为()
A.状态数目 彩球的数目
B.与时间无关的状态转移概率矩阵 在选定某个缸的情况下,选择另一个缸的概率
C.给定状态下,观察值概率分布 每个缸中的颜色分布
D.初始状态空间的概率分布 初始时选择某口缸的概率
答案:A
试举出隐马尔可夫模型在生活中的应用:________、________。
答案:语音识别、人脸识别、蛋白质序列分析、分子结构预测
描述隐马尔可夫模型的五个元素有哪些?
A.隐含状态S
B.可观测状态O
C.初始状态概率矩阵Π
D.隐含状态转移概率矩阵A
E.观测概率转移概率矩阵B
答案:ABCDE
隐马尔可夫模型与马尔可夫模型的区别:正常的马尔可夫模型中,状态对观察者来说是____,但是隐马尔可夫模型中,状态是______,而需要通过受状态影响的变量进行观测。
答案:直接可见的、不直接可见的(无法直接观测)
- 隐马尔可夫模型要解决的三个问题:
- 评估问题:有效计算某一观测序列的概率
- 解码问题:寻找某种意义上最优的隐状态序列
- 学习问题:调整模型参数,使观测序列的可能性尽可能大
- 编程问题:实现模型的自主编程
答案是abc
现在回顾之前的内容。我们学到了:
- 大脑是有很多叫做神经元的东西构成,神经网络是对大脑的粗糙的数学表达。
- 每一个神经元都有输入、处理函数和输出。
- 神经元堆叠起来形成了网络,用作近似任何函数。
- 为了得到最佳的神经网络,我们用梯度下降方法不断更新模型
给定上述关于神经网络的描述,什么情况下神经网络模型被称为深度学习模型?
A.加入更多层,使神经网络的深度增加
B.有维度更高的数据
C.当这是一个图形识别的问题时
D.以上都不正确
答案:(A)
下列哪一项在神经网络中引入了非线性?
A.随机梯度下降
B.修正线性单元(ReLU)
C.卷积函数
D.以上都不正确
答案:(B)
假设目前的权重为w,偏置为b,下一时刻的权重为w',偏置为b',学习率为η,损失函数为C,请写出权重的更新规则为________,偏置的更新规则为________.
答案:
1.哪一类机器学习可以在未标注的数据中找出模式?
- 数据预言
- 有监督学习
- 无监督学习
- 监督逻辑
答案:C。
2.验证数据集的用途是什么?
- 测试模型是否对数据过度拟合
- 衡量模型的复杂度
- 在训练完成后评估模型拟合
- 测试模型在训练中的泛化程度
答案:D。
生成对抗网络通常与合成图像相关联。
4. 迁移学习描述了“获取预训练神经网络并重新训练该网络以对一组新图像进行分类”的过程。
1、(对测试样本的识别准确率)是评价一个分类器好坏的最主要指标,如何提高分类器对测试样本的分类能力是近年来机器学习研究的一个重要内容。
2、SVM 是一种两类分类模型,其基本模型定义为特征空间上的(间隔最大) 的线性分类器。
下列哪个不是人工智能的研究领域(D)
A、机器证明
B、模式识别
C、人工生命
D、编译原理
4、人工智能是知识与智力的综合,其中下列不是智能的特征的是(A)
A、具有自我推理能力
B、具有感知能力
C、具有记忆与思维的能力
D、具有学习能力以及自适应能力
- CNN中()是局部连接,所以提取的是局部信息。 答案:卷积层
2.神经网络的一次误差反向传播算法可以()
答案:修改网络中所有神经元的参数
1.物联网为人工智能的( B )提供了基础设施环境,同时带来了多维度、及时全面的海量训练数据。
A.应用层 B.感知层 C.数据层 D.以上都是
2.无人超市采用了( A )等多种智能技术,消费者在购物流程中将依次体验自动身份识别、自助导购服务、互动式营销、商8品位置侦测、线上购物车清单自动生成和移动支付。
A.计算机视觉、深度学习算法、传感器定位、图像分析
B.虚拟技术,传感器定位、图像分析
C.声纹识别技术、计算机视觉、深度学习算法、
D.图像识别、人脸识别、物体检测、图像分析
1、因为池化层不具有参数,所以它们不影响反向传播的计算。
【A】 正确
【B】 错误
答案:B
2、“参数共享”是使用卷积网络的好处。关于参数共享的下列哪个陈述是正确的?
【A】 它减少了参数的总数,从而减少过拟合。
【B】 它不允许在整个输入值的多个位置使用特征检测器。
【C】 它允许为一项任务学习的参数即使对于不同的任务也可以共享(迁移学习)。
【D】 它允许梯度下降将许多参数设置为零,从而使得连接稀疏。
答案:D
3、由于卷积神经网络在计算机视觉领域应用更广些,所以大多数人在谈及CNN时,默认输入的是图片。
4、CNNs作为深度学习框架是基于(最小化预处理)数据要求而产生的。
1、下列关于SVM的应用场景说法正确的是(多选):(ABCD)
A. SVM在二分类问题上表现突出
B. SVM能够解决多分类问题
C. SVM能够解决回归问题
D. SVM能够完成异常值检测
2、根据机器智能水平由低到高,正确的是(A)
A.计算智能、感知智能、认知智能
B计算智能、感应智能、认知智能
C.机器智能、感知智能、认知智能
D机器智能、感应智能、认知智能
- 3、隐马尔可夫模型的三个基本问题是:_、_和学习模型参数(估值问题、寻找状态序列)
- 卷积神经网中,如果输入图像是32×32矩阵,卷积核心是5×5的矩阵,步长为1,那么卷积操作后的特征图是 (D)的矩阵
A. 34×34
B. 32×32
C. 30×30
D. 28×28
1/9 1/9 1/9
1/9 1/9 1/9
1/9 1/9 1/9
卷积核的卷积效果:(B)
A. 没有任何效果
B.均值滤波
C.高斯滤波
D.梯度
3.在卷积神经网络中,通常利用一个局部区域去扫描整张图象,在这个局部区域作用下,图像中所有的像素点会被线性变换组合,形成下一层的神经元节点。这个局部区域被称为卷积核
4.输入数据矩阵为 卷积核为
1 1 1 0 0 1 0 1
0 1 1 0 1 0 1 0
0 0 1 1 1 1 0 1
0 0 1 1 0
0 1 1 0 0
计算输出数据的第一行结果4 3 4.
- 在如下公式
s(t)=f(t)*g(t)
中,星号表示卷积,把函数f称为输入函数,把g称为卷积核或滤波器,这两个函数叠加起来的结果叫做特征图或特征图谱。
5.有时候希望得到的特征图向量和长向量等长,在长向量两边都扩充一个”0“,这个操作叫做补零。
1. 通常情况下,一个典型的卷积神经网络通常由输入层、若干个(卷积层)、激活层、池化层及全连接层组成。
2.卷积层设计有两个核心概念,分别是局部连接和(权值共享)。
3.卷积层的核心参数有很多,下列选项中哪个不是卷积层的核心参数之一(D)。
A:卷积核的深度
B:卷积核的步幅
C:卷积核的补零
D:卷积核的参数共享
4.卷积层的作用是(C)。
A:增强图像
B:简化图像
C:特征提取
D:图像处理
一:选择题
1.池化,也称“亚采样”,就是将小区域的特征,整合得到新特征的过程,将下面的特征图矩阵采用最大池化后,得到的结果为()
| 1 | 2 | 2 | 5 |
| 0 | 4 | 1 | 6 |
| 1 | 1 | 2 | 3 |
| 1 | 5 | 1 | 4 |
A.
| 4 | 6 |
| 5 | 4 |
B.
| 1 | 5 |
| 2 | 6 |
C.
| 5 | 6 |
| 3 | 5 |
D.
| 5 | 3 |
| 6 | 5 |
答案:A
2.sigmoid 函数是一种传统的非线性激活函数,函数形式为sigmoid(x)=1/(1+e-x)。作为激活函数,它有很多优良特质,而缺点是容易产生梯度消失现象。以下对sigmoid函数的说法中不正确的是()
A.单调递增
B.反函数形式简单
C.相对于零点中心对称
D.可以将任意变量均映射在(0,1)区间,因此常被用作神经网络的阈值函数。
答案:C
二:填空题
标准Relu函数如下图,对于它构成的神经网络来说,当x=-3时,神经元处于---状态。(激活/抑制)
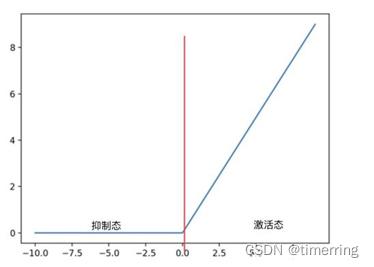
在CNN中,经过了卷积层、激活层、池化层后,进入____层,它将前面各个层预学习到的特征图,重新映射到样本标记空间,最后给出对象的分类预测。
(全连接层)
1.在CNN中,分类的工作是由(全连接层)完成的。
2.LSTM设计的关键是(神经元的状态)。
关于卷积神经网络叙述何者正确?()
A.池化层会出现在每个隐藏层
B.池化层目的是做特征的题曲
C.池化层可以取代卷积层
D.第一层的卷积运算是在做图像边缘或纹理的特征提取
答案:D
关于AlexNet卷积神经网络的说法正确的是
A、从开始的层到后面的层,经过变换得到的特征图的尺寸逐渐变大
B、从开始的层到后面的层,经过变换得到的特征图的尺寸逐渐变小
C、从开始的层到后面的层,经过变换得到的特征图的尺寸大小不变
D、从开始的层到后面的层,经过变换得到的特征图的尺寸开始变小,后来变大
答案:B
填空题:
1.循环神经网络是一种基于(时间)的反向传播算法
2.在循环神经网络“展开”的前馈网络中,所有层的参数是(共享)的,因此参数的 真实梯度是所有“展开层”的参数梯度之和
选择题:
- 循环神经网络的主要用途是处理和预测(C)数据 A.连续时间信号 B.模拟信号 C.序列 D.数字信号
- 基于时间的反向传播算法BPTT是针对循环层设计的训练算法,他的基本原理与反向 传播算法BP是一样的,同样包含三个步骤,其正确顺序为(A) (1)前向计算每个神经元的输出值; (2)反向计算每个神经元的误差项值,它是误差函数E对神经元j的加权输人的偏导数; (3)计算每个权重的梯度。 A(1)(2)(3) B.(2)(1)(3) C.(3)(1)(2) D.(1)(3)(2)
[单选题]关于循环神经网络以下说法错误的是?(B)
- 循环神经网络可以根据时间轴展开
B、LSTM无法解决梯度消失的问题
C、LSTM也是—种循环神经网络
D、循环神经网络可以简写为RNN
[单选题]针对深度学习的梯度消失问题,哪种因素可能是无效的?(C)
- 添加shortcut(skip) connection
- 减少网络深度
- 减少输入层词嵌入向量维度
- 增大学习率
当时序数据比较长时,循环神经网络(RNN)容易产生长距离依赖问题,这是由网络训练时反向传播时的梯度消失引起的
RNN的损失函数度量所有时刻的输入与理想输出(导师值)的差异,需要使用梯度下降法调整参数不断降低损失函数
下列哪个应用领域不属于人工智能应用? ( B )
人工神经网络 B. 自动控制 C. 自然语言学习 D. 专家系统
人工智能研究的一项基本内容是机器感知, 以下列举中的 ( C ) 不属于机器感知
的领域。
A. 使机器具有视觉、 听觉、 触觉、 味觉、 嗅觉等感知能力。
B. 让机器具有理解文字的能力。
C. 使机器具有能够获取新知识、 学习 新技巧的能力
D. 使机器具有听懂人类语言的能力
人工神经网络具有的基本属性: 非线性 、 非局域性 、 非定常性 和 非凸性 。
双向循环神经网络由两层循环神经网络组成,它们的输入相同,信息传递的方向不同。
1、深度强化学习的经典算法有__(写出一种即可)
答案:深度Q网络算法,深度确定性策略梯度算法,A3C算法等
2、深度强化学习___( 填有或无 )标签信息。
答案:无
3、()是一种利用标签数据的分类技术,它通常使用这些正确的且已标记过的数据(即教师或目标)来训练神经网络。
A.有监督学习 B.无监督学习
C.强化学习 D.以上都是
答案:A
4、整个强化学习系统由智能体(agent)、环境( environment)、奖赏( reward)、状态(state )、动作( action) 5部分组成。()是整个强化学习系统的核心。
A.智能体(agent) B.环境( environment)
C.奖赏( reward) D.状态(state )
答案:A
1、生成对抗网络的核心思想源于(纳什均衡)。
2.生成对抗网络是(非监督学习)的一种深度学习模型,让两个“(生成模型 )”和“(判别模型)”神经网络以互相博弈的方式进行学习。
3、下列哪个是生成对抗网络(GenerativeAdversarialNetwork)可能的应用(D)
A.输入一个人的侧脸照片,生成一个人的正脸照片
B.以大量的真实的明星的照片训练模型,生成新的明星照片
C.输入一个的照片,生成不同年龄的照片
D.以上都是
4、生成对抗网络包括哪两个网络(C)
A.“生成网络”和“鉴别网络”
B.“对抗网络”和“判别网络”
C.“判别网络”和“生成网络”
D.“对抗网络”和“生成网络”
1.许多领域中,能取得最好表现的系统都是基于深度神经网络的。深度神经网络这种方法也被称为(黑盒系统),是一种(端到端)的方法论。
2.下面属于深度学习不足的是(D)
- 它不会判断数据的正确性
- 它缺少理论的支持和引导。
- 训练成本比较高
- 以上都是
3、下列选项中哪一个不是关于深度学习可解释性的研究方向(C)
【A】 卷积神经网络的可视化
【B】 新的神经网络操作工具
【C】 利用经验学习来解释神经网络
【D】 信息瓶颈理论的研究
1.CapsNet由胶囊而不是神经元组成。“胶囊”就是在神经网络中构建和抽象出的子网络,它输出一个向量,该向量的长度表示被检测对象存在的(估计概率),而方向对被检测对象的(姿态参数)进行编码。
2.神经胶囊网络由编码器和解码器两部分组成,下列结构不属于编码器的是(D)
- 卷积层
- 主胶囊层
- 数字胶囊层
- 全连接层
3.下列特点不是神经胶囊网络相对于CNN的优势的是(C)
- 需要的训练数据少得多
- 能较好地处理图像多义性表达
- 识别速度快,识别效率高
物体之间的空间辨识度很强
1.欧式距离相似度算法需要保证各个维度指标在(相同)的刻度级别
2.(时间)和(状态)都离散的马尔科夫过程称为马尔科夫链
3.不属于三层神经网络的是a
a池化层
b输入层
c输出层
d隐藏层
4.人工智能的含义最早由一位科学家于
1950年提出,并且同时提出一个机器智能的测试模型,请问这个科学家是(C)。
A.明斯基
B.扎德
C.图灵
D.冯.诺依曼
云端人工智能,是将云计算的运作模式与_____深度融合,在云端集中使用和共享机器学习工具的技术。答案:人工智能
元学习的最终目的是使得模型获取一种学会学习调整()的能力。
答案:参数
下列有关神经形态计算的相关说法,错误的是:
A.目前普遍采用哈佛体系结构。
B.神经形态计算的类生物本质使之拥有非常低的能耗。
C.该概念最早在1980年由美国计算机科学家卡福·米德提出。
D.神经形态计算是指在芯片上模拟生物神经元、突触,赋予机器感知和学习能力的技术。
答案:A
下列有关元学习的相关说法,错误的是
A.元学习是“学会学习”,是利用以往的知识经验来指导新任务的学习,具有学会学习的能力。
B.元学习是指利用训练好的开源网络模型,将自己的任务数据集在这些迁移过来的网络上进行训练或微调。
C.元学习是从旧任务中学习如何高效的学会新任务。
D.元学习大体分为两个阶段,训练阶段和测试阶段。
选B。
选择题:
搜索分为盲目搜索和(A)
A 启发式搜索 B模糊搜索
C 精确搜索 D大数据搜索
在深度优先搜索策略中:open表是(B)的数据结构
A 先进先出 B后进后出
C根据估价函数值重排 D随机出
填空题
广度优先搜索算法中,OPEN表的数据结构实际是一个二叉树,深度优先搜索算法中,OPEN表的数据结构实际是一个单链表。
选择题:
下列哪个算法不属于启发式搜索算法:(C)
A.A*算法 B.Dijkstra算法
C.广度优先算法 D.有序搜索算法
α-β剪枝技术是对下面哪个算法的优化(A)
A.极大极小分析法 B.蒙特卡洛树搜索法
C.以上说法都对 D.以上说法都不对
填空题:
Dijkstra算法主要特点是从起始点开始,采用(贪心算法/贪婪算法)的策略,每次遍历到始点距离最近且未访问过的顶点的邻接节点,直到扩展到终点为止。
蒙特卡洛树搜索大概可以被分为(4)步。
在与或图中,没有后裔的非终叶节点为不可解节点,那么含有或后继节点且后裔中至少由一个为可解的非终叶节点是(可解节点),含有与后继节点且后裔中至少由一个为不可解的非终叶节点是(不可解节点)
在语义网络中,用(B)来标明类与子类之间的关系。
A.实例联系 B.泛化联系 C.聚集联系 D.属性联系
在图搜索中,选择最有希望的节点作为下一个要扩展的节点,这种搜索方法叫做( C)
A.宽度搜索 B.深度搜索 C.有序搜索 D.广义搜索
1.97年5月,著名的“人机大战”,最终计算机以3.5:2.5的总比分将世界国际象棋棋王卡斯帕罗夫击败,这台计算机被称为(A)
A.深蓝
B.IBM
C.深思
D蓝天
2.符合贝叶斯理论(连续特征)的选项(D)(单选)
a允许除分类以外的行动主要允许拒绝的可能性
b拒绝在接近或糟糕的情况下做出决定
c损失函数表示采取的每项行动的成本
d全部
- 在启发式搜索中,(启发函数)通常用来表示启发性信息。
4.人工智能研究途径主要包括(符号主义)和(连接主义)两种观点。
- 图灵测试的目的是(验证机器是否有智能)
- 人工智能术语的提出是在(达特茅斯会议)
- 神经网络是(B)学派的成果 A符号学派 B联接学派 C行为学派 D统计学派
AI的诞生是在(A)A1956年 B 1950年 C1946年 D1940年
人工智能诞生于哪一年?(C )
A. 1955
B. 1957
C. 1956
D. 1965
以下不属于人工智能技术的是(D)
- 指纹识别 B.语音识别 C人脸识别 D.自动感应门
人工智能按照其智能程度可以分为弱人工智能、强人工智能和()三个层次
答案:超人工智能
为了增加模型训练的效率,我们应用了 GPU、 _____和分布式运算等新的运算加速技术
答案:FPGA
下列几个表达式 (A)是L2范数的表达式,(B)是L1范数的表达式
A.
B.
C.
D.
相关的文档资源已上传,可自行下载,也可留言邮箱,会一一发送。
 https://download.csdn.net/download/m0_52316372/85913998
https://download.csdn.net/download/m0_52316372/85913998以上是关于2022春山东大学人工智能导论期末题库附答案的主要内容,如果未能解决你的问题,请参考以下文章
百度联手清华大学出版社 打造国内首套产教融合人工智能系列教材
百度联手清华大学出版社 打造国内首套产教融合人工智能系列教材