山东大学人工智能导论实验一 numpy的基本操作
Posted timerring
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了山东大学人工智能导论实验一 numpy的基本操作相关的知识,希望对你有一定的参考价值。
目录
1. 代码运行结果截图(main函数里的内容不要修改)编辑
5. cross entropy loss function公式
【实验目标】
1.熟悉numpy的一些基本函数
2.理解sigmoid, softmax, cross entropy loss等函数
【实验内容】
使用numpy实现深度学习任务中的一些基本操作,包括以下函数:
1. sigmoid function
def sigmoid(x):
"""
Compute the sigmoid of x
Arguments:
x -- A scalar or numpy array of any size
Return:
s -- sigmoid(x)
"""
# write your code here
fx = []
for num in x:
fx.append(1 / (1 + math.exp(-num)))
return fx
2. sigmoid gradient function
def sigmoid_derivative(x):
"""
Compute the gradient (also called the slope or derivative) of the sigmoid function with respect to its input x.
You can store the output of the sigmoid function into variables and then use it to calculate the gradient.
Arguments:
x -- A scalar or numpy array
Return:
ds -- Your computed gradient.
"""
# write your code here
y = []
fx = []
for num in x:
y.append(1 / (1 + math.exp(-num)))
for n in y:
fx.append(n * (1 - n))
return fx
3. softmax function
def softmax(x):
"""Calculates the softmax for the input x.
Argument:
x -- A numpy matrix of shape (n,)
Returns:
s -- A numpy matrix equal to the softmax of x, of shape (n,)
"""
# write your code here
x_exp = np.exp(x)
x_sum = np.sum(x_exp, axis=0, keepdims=True)
fx = x_exp / x_sum
return fx
4. cross entropy loss function
def cross_entropy_loss(target, prediction):
"""
Compute the cross entropy loss between target and prediction
Arguments:
target -- the real label, a scalar or numpy array size = (n,)
prediction -- the output of model, a scalar or numpy array, size=(n, c)
Return:
mean loss -- cross_entropy_loss(target, prediction)
"""
# write your code here
batch_loss = 0.
for i in range(prediction.shape[0]):
numerator = np.exp(prediction[i, target[i]]) # 分子
denominator = np.sum(np.exp(prediction[i, :])) # 分母
# Calculating losses
loss = -np.log(numerator / denominator)
batch_loss += loss
return batch_loss
【代码要求】
1.按代码模板实现函数功能
【文档要求】
1. 代码运行结果截图(main函数里的内容不要修改)

2. sigmoid函数的公式及图像
sigmoid函数的公式如下:

用python绘制sigmoid函数的图像:

函数图像如下所示:

分析:从结果可知,符合sigmoid函数的定义,但是也可以看到sigmoid函数在x过大或者过小时梯度下降缓慢,因此除了Logistic Regression的输出层以外,很少用到sigmoid函数,且sigmoid函数会使得数据平均值在0.5附近。
3. sigmoid函数梯度求解公式及图像
sigmoid函数梯度求解推导如下:
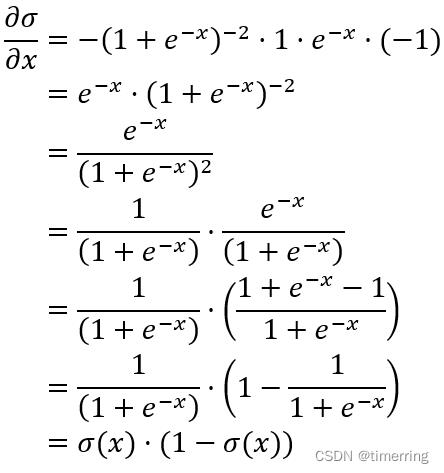
分析:函数的求导整体上是一个多重复合函数的求导,相对来说较为简单,但是后面的化简技巧我最初没有想到,根据结果的形式反推出了函数的化简方法。不得不感叹函数求导最终形式的简便。
用python绘制sigmoid函数梯度求解的图像:

sigmoid函数梯度求解的图像如下所示:

分析:从结果中可以看到sigmoid函数在x过大或者过小时梯度下降缓慢,会导致梯度更新得较缓,学习速度较慢。
4. softmax函数公式

目的:将实数范围内的分类结果--转化为0-1之间的概率。
1.利用指数的特性,将实数映射到0-正无穷(非负)
2.利用归一化方法,将1.的结果转化为0-1之间的概率。
5. cross entropy loss function公式
交叉熵损失函数公式如下:

具体在二分类问题中,交叉熵函数的公式如下:
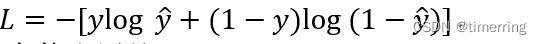
6. 它们在神经网络中有什么用处?
Sigmoid function:由上面的实验图可知,sigmoid是非线性的,因此可以用在神经网络隐藏层或者输出层中作为激活函数,常用在二分类问题中的输出层将结果映射到(0, 1)之间。可见sigmoid函数处处连续,便于求导,且可以将函数值的范围压缩到[0,1],可以压缩数据,且幅度不变。
Sigmoid gradient function:对于sigmoid函数的求导,可以在神经网络反向传播中求出。优化神经网络的方法是Back Propagation,即导数的后向传递:先计算输出层对应的loss,然后将loss以导数的形式不断向上一层网络传递,修正相应的参数,达到降低loss的目的。 Sigmoid函数在深度网络中常常会导致导数逐渐变为0,使得参数无法被更新,神经网络无法被优化。从导数图中容易看出,当中较大或较小时,导数接近0,而后向传递的数学依据是微积分求导的链式法则,当前层的导数需要之前各层导数的乘积,几个小数的相乘,结果会很接近0 ,此外Sigmoid导数的最大值是0.25,这意味着导数在每一层至少会被压缩为原来的1/4,通过两层后被变为1/16,…,通过10层后为1/1048576,且导数达到最大值这种情况很少见的。
Softmax function:softmax用于多分类问题,在多分类神经网络种,常常作为最后一层的激活函数,前一层的数值映射为(0,1)的概率分布,且各个类别的概率归一,与sigmoid不同的是,softmax没有函数图像,它不是通过固定的的映射将固定的值映射为固定的值,softmax是计算各个类别占全部的比例,可以理解为输入一个向量,然后出一个向量,输出的向量的个位置的元素表示原向量对应位置的元素所占整个向量全部元素的比例。因此原始向量经过softmax之后,原始向量中较大的元素,在输出的向量中,对应位置上还是较大,反之,原始向量中较小的元素还是会很小,保留了原始向量元素之间的大小关系。在做多分类问题时,输出向量的第几维最大,就表示属于第几个class的概率最大,由此分类。
Cross entropy loss function:交叉熵能够衡量同一个随机变量中的两个不同概率分布的差异程度,在机器学习中就表示为真实概率分布与预测概率分布之间的差异。交叉熵的值越小,模型预测效果就越好。交叉熵经常搭配softmax使用,将输出的结果进行处理,使其多个分类的预测值和为1,再通过交叉熵来计算损失。
初学人工智能导论,可能存在错误之处,还请各位不吝赐教。
受于文本原因,本文相关实验工程无法展示出来,现已将资源上传,可自行下载。
 https://download.csdn.net/download/m0_52316372/85912681
https://download.csdn.net/download/m0_52316372/85912681 高性能云服务器
高性能云服务器
 精品线路独享带宽,毫秒延迟,年中盛惠 1 折起
精品线路独享带宽,毫秒延迟,年中盛惠 1 折起
以上是关于山东大学人工智能导论实验一 numpy的基本操作的主要内容,如果未能解决你的问题,请参考以下文章