翻译图解自注意力机制
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了翻译图解自注意力机制相关的知识,希望对你有一定的参考价值。
这是我翻译这位大佬的第二篇文章了。这篇文章是受到大佬认证的了。他的原文中有翻译链接,直接指向我。

作者博客:@Jay Alammar
重大声明
-
这个文章是《图解GPT-2 | The Illustrated GPT-2 (Visualizing Transformer Language Models)》的一部分,因为篇幅太长我就单独拿出来了。
当然如果你只想了解自注意力机制也可以看看本文章的前半部分,这篇文章属算是入门科普读物了,不需要太多知识铺垫。 后半部分主要是讲masked self-attention在GPT-2中的应用,不了解GPT-2的可以忽略这部分内容。
-
我补充的内容格式如下:
正文
看一下下图,下图表示的是注意力处理输入序列的it单词的时候。

接下来我们详细介绍一下这一过程是如何实现的。
注意,接下来的图解过程会用到很多 “向量” 来图解算法机制,而实际实现中是使用 矩阵 进行计算的。这个分析过程是想让读者了解在处理过程中每个单词发生了什么,因此本文的重点是单词级(word-level)处理逻辑进行解析。
自注意力
我们从原始的自注意开始,它是在一个encoder组件中计算的。我们先来看看这个简单的Transformer组件,它一次只能处理四个tokens。
仅需三步即可实现自注意力:
- 为每个单词路径创建Query、Key、Value。
- 对于每个输入token,使用其Query向量对其他所有的token的Key向量进行评分。
- 将Value向量乘以上一步计算的分数后加起来。

1. 创建Query、Key、Value
现在我们只关注第一个路径,我们需要用它的Query和所有的Key比较,这一步骤会为每个路径都生成一个注意力分数。
先不管什么是多头注意力,先看一个head 的情况。自注意力计算的第一步就是要计算出每个路径的Query、Key、Value三个向量。

2. 计算注意力分数
现在我们已经有了那三个向量,在第二步我们只需要用到query和key向量。因为我们关注的是第一个token,所以我们将其第一个token的query乘以其他token的key向量,这样计算会得到每一个token的注意力分数。

3. 求和
我们现在可以将上一步得到的注意力分数乘以Value向量。将相乘之后的结果加起来,那些注意力分数大的占比会更大。

对于Value向量,注意力分数越低,颜色越透明。这是为了说明乘以一个小数如何稀释不同token的Value向量。
如果我们对每个路径进行相同的操作,最终会得到每个token新的表示向量,其中包含该token的上下文信息。之后会将这些数据传给encoder组件的下一个子层(前馈神经网络):

图解带Mask的自注意力
现在我们已经了解了Transformer中普通的自注意机制,让我们继续看看带mask的自注意。
带mask的自注意和普通的自注意是一样的,除了第二步计算注意力分数的时候。
假设模型只有两个token作为输入,我们当前正在处理第二个token。在下图的例子中,最后两个token会被mask掉。这样模型就能干扰计算注意力分数这一步骤,它会让未输入的token的注意力得分为0,这样未输入的token就不会影响当前的计算,当前词汇的注意力只会关注到在它之前输入的序列。

这种屏蔽通常以矩阵的形式实现,称为注意力屏蔽(attention mask)。
还是假设输入序列由四个单词组成,例如robot must obey orders。在语言建模场景中,这个序列包含四个处理步骤,每个单词一个步骤(假设现在每个单词都是一个token)。由于模型是按照批量(batch)进行处理的,我们可以假设这个模型的批量大小为4(batch_size = 4),然后模型将把整个序列作为一个batch处理进行四步处理。

在矩阵形式中,我们通过将Query矩阵乘以Key矩阵来计算注意力分数。让我们像下面这样进行可视化,注意,单词无法直接进行矩阵运算,所以要把他们的Query和Key丢到矩阵中。

完成乘法运算后,我们要加上上三角形式的mask矩阵。它会将我们想要屏蔽的单元格设置为$-∞$或一个非常大的负数(GPT-2中的为负一亿):

然后,对每一行进行softmax就会转化成我们需要的注意力分数:

这个分数表的含义如下:
-
当模型处理数据集中的第一个单词时,也就是第一行,其中只包含一个单词
robot,它的注意力将100%集中在这个单词上。 -
当模型处理数据集中的第二个单词时(第二行),其中包含单词
robot must,当它处理单词“must”时,48%的注意力会放在robot上,52%的注意力会放在must上。 -
以此类推……
GPT-2的 Masked Self-attention
让我们更详细地了解一下GPT-2的masked注意力。
现在假设模型做预测任务,每次处理一个 token。
我们用模型进行预测的时候,模型在每次迭代后都会增加一个新词,对于已经处理过的token来说,沿着之前的路径重新计算效率很低。
假设我们处理输入序列的第一个tokena时(暂时忽略<s>)。

GPT-2会保留atoken的Key和Value向量。每个自注意力层都有各自的Key和Value向量,不同的decoder组件中Key和Value向量不共享:

在下一次迭代中,当模型处理单词robot时,它不需要为a重新生成Query、Key、Value,而是直接用第一次迭代中保存的那些:

1. 创建queries, keys和values
让我们假设这个模型正在处理单词it。如果我们讨论的是最底层的decoder组件,那么它接收的token的输入是token的嵌入+ 第九个位置的位置编码:

Transformer中的每个组件之权重不共享,都有自己的权重。我们首先要和权重矩阵进行计算,我们使用权重矩阵创建Query、Key、Value。

自注意力子层会将输入乘以权值矩阵(还会加上bias,图中没表示出来),乘法会产生一个向量,这个向量是单词it的Query、Key、Value的拼接向量。

将输入向量乘以注意力权重向量(然后添加一个偏差向量),就会得到这个token的Query、Key、Value向量。
1.5 划分注意力头
在前面的例子中,我们只专注于自注意力,忽略了“多头”(muti-head)的部分。现在说一下什么是“多头”。 就是将原来一个长的Query、Key、Value向量按照不同位置截取并拆分成短的向量。

前边的例子中我们已经了解了一个注意力头怎么计算,现在我们考虑一下多头注意力,如下图考虑有三个head。

2. 注意力分数
现在我们可以开始打分了,你们应该知道,我们这只画出来一个注意力头(head #1),其他的头也是这么计算的:

现在,该token可以针对其他token的所有Value进行评分:

3. 加和
和前边讲的一样,我们现在将每个Value与它的注意力分数相乘,然后将它们相加,产生head #1的自我注意结果$Z$:

3.5 合并注意力头
不同的注意力头会得到不同的$Z$,我们处理不同注意力头的方法是把这个$Z$连接成一个向量:
 但是这个拼接结果向量还不能传给下一个子层。
但是这个拼接结果向量还不能传给下一个子层。
我们首先需要把这个拼接向量转换成对齐表示。
映射/投影
我们将让模型学习如何将自注意力的拼接结果 更好地映射成前馈神经网络可以处理的向量。下面是我们的第二个大权重矩阵,它将注意力的结果投射到自注意力子层的输出向量中:

之后我们就产生了可以发送到下一层的向量:

GPT-2 全连接神经网络第一层
全连接神经网络的输入是自注意力层的输出,用于处理自注意力子层得到的token的新的表示,这个表示包含了原始token及其上下文的信息。
它由两层组成。第一层是模型大小的4倍(因为GPT-2 small是768,所以GPT-2中的全连接神经网络第一层会将其投影到768*4 = 3072个单位的向量中)。为什么是四倍?因为原始Transformer的也是四倍,这里就没改。
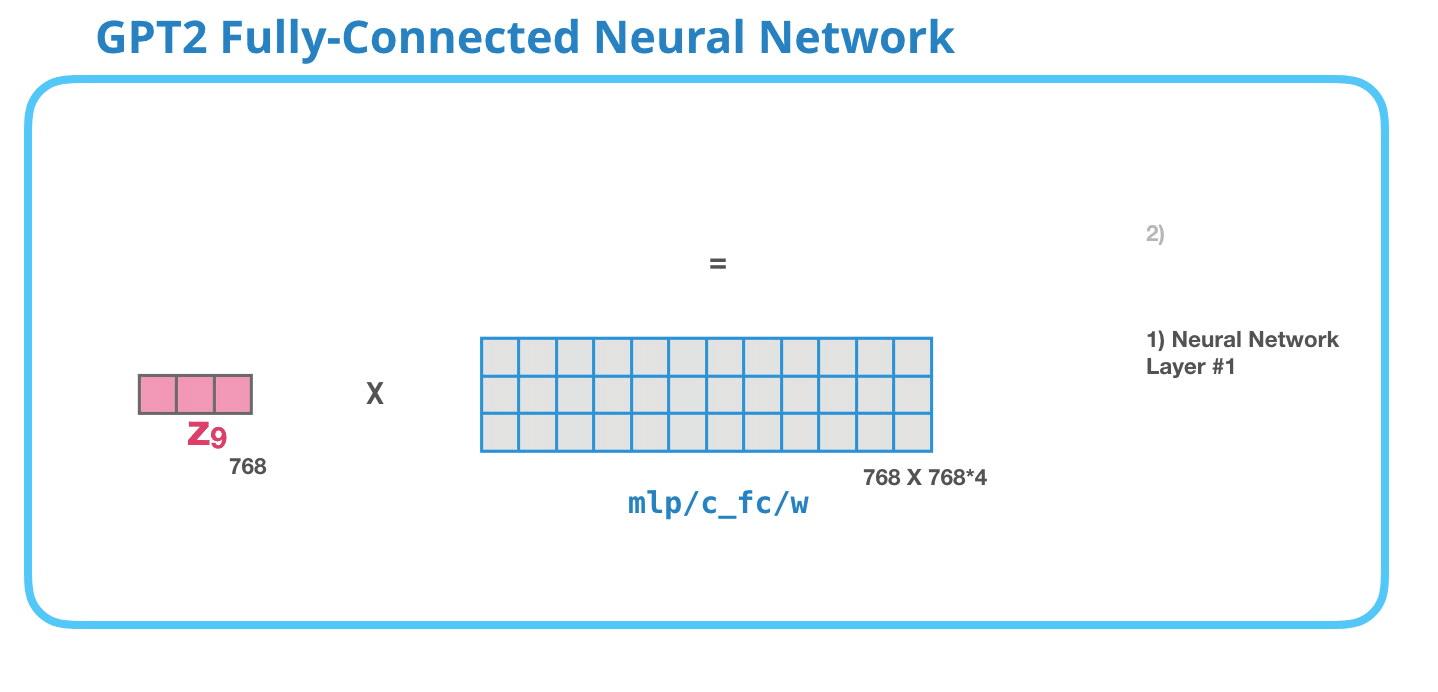
上图没画出bias。
GPT-2 全连接神经网络第二层:投影到模型维度
第二层将第一层的结果再投射回模型的维度(GPT-2 small为768)。这个计算结果就是整个decoder组件对token的处理结果。
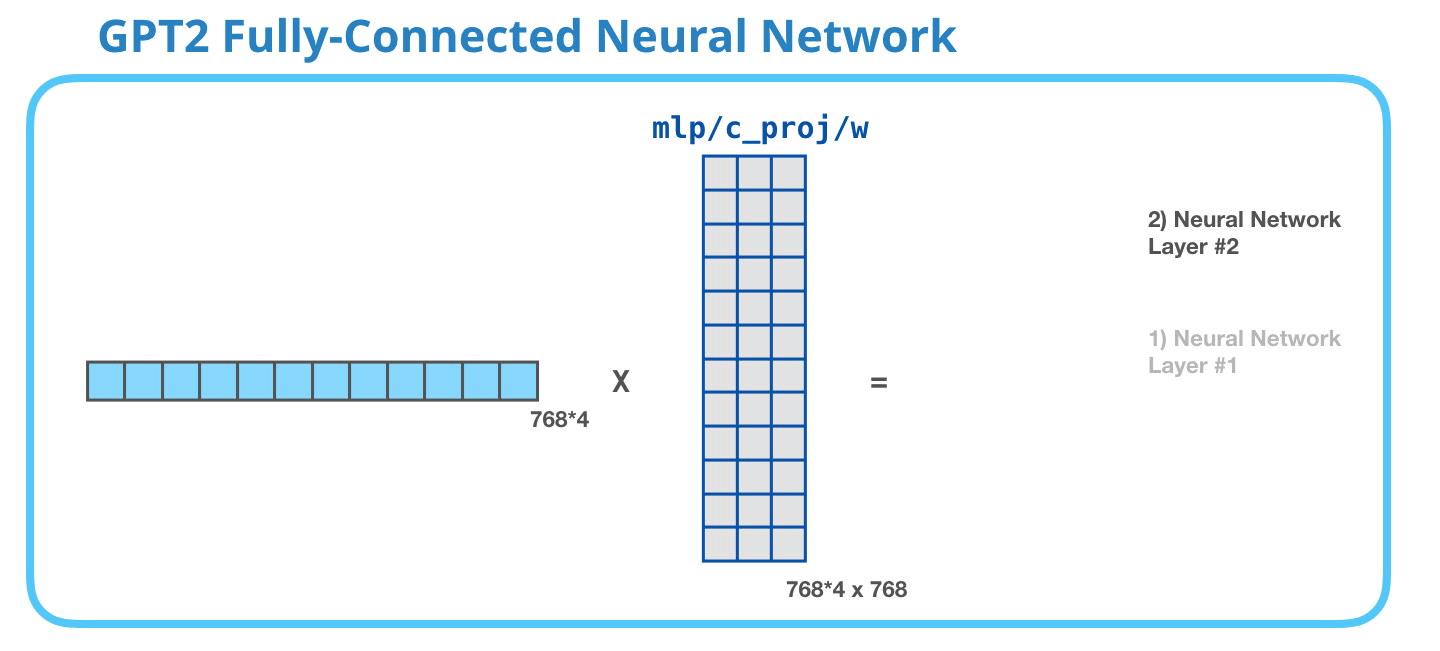
上图没画出bias。
You’ve Made It!
总结一下输入向量都会遇到哪些权重矩阵:

每个Transformer组件都有自己的权重。另外,该模型只有一个token的嵌入矩阵和一个位置编码矩阵:

如果你想看到模型的所有参数,我在这里对它们进行了统计:

由于某种原因,它们加起来有124M的参数,而不是117M。我不知道为什么,但这就是在发布的代码中它们的数量(如果我错了欢迎指正)。
以上是关于翻译图解自注意力机制的主要内容,如果未能解决你的问题,请参考以下文章