深度学习模型评价指标
Posted 超级无敌陈大佬的跟班
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习模型评价指标相关的知识,希望对你有一定的参考价值。
一、分类任务
分类任务一般有二分类、多分类和多标签分类。
多分类: 表示分类任务中有多个类别,但是对于每个样本有且仅有一个标签,例如一张动物图片,它只可能是猫,狗,虎等中的一种标签(二分类特指分类任务中只有两个类别)
多标签: 一个样本可以有多个标签。例如文本分类中,一个文本可以是宗教相关,也可以是新闻相关,所以它就可以有两个标签。
常见的评价指标有:准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 score、ROC曲线(Receiver Operating Characteristic Curve)等,本文将对上述指标进行讲解。
1.1 混淆矩阵
混淆矩阵是数据科学和机器学习中经常使用的用来总结分类模型预测结果的表,用n行n列的矩阵来表示,将数据集中的记录按照“真实的类别”和“预测的类别”两个标准进行汇总。以二分类任务为例,混淆矩阵的结构如下: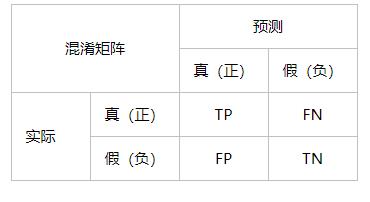
TP = True Postive = 真阳性; FP = False Positive = 假阳性
FN = False Negative = 假阴性; TN = True Negative = 真阴性
- 第一位表示模型预测的是否正确,T(True)表示预测正确,F(False)表示预测错误;
- 第二位表示模型的预测结果,P(Positive)表示预测为正样本,N(negative)表示预测为负样本;
TP:表示实际为正被预测为正的样本数量,
FP:表示实际为负但被预测为正的样本数量,
FN:表示实际为正但被预测为负的样本的数量,
TN:表示实际为负被预测为负的样本的数量。
另外,TP+FP表示所有被预测为正的样本数量,同理FN+TN为所有被预测为负的样本数量,TP+FN为实际为正的样本数量,FP+TN为实际为负的样本数量。
1.2 准确率
准确率是分类正确的样本占总样本个数的比例,即:
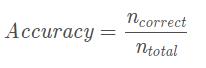
其中,n_correct为被正确分类的样本个数,n_total为总样本个数。
结合上面的混淆矩阵,公式还可以这样写:
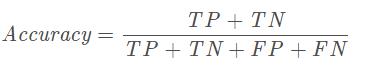
准确率指标的缺陷:
准确率是分类问题中最简单直观的评价指标,但存在明显的缺陷。比如如果样本中有99%的样本为正样本,那么分类器只需要一直预测为正,就可以得到99%的准确率,但其实际性能是非常低下的。也就是说,当不同类别样本的比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
1.3 精确率(精确度)
精确率指模型预测为正的样本中实际也为正的样本占被预测为正的样本的比例。计算公式为:
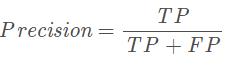
1.3.1 多分类任务精确率的两种方式:
- Macro Average 宏平均:是指在计算均值时使每个类别具有相同的权重,最后结果是每个类别的指标的算术平均值。
- Micro Average 微平均:是指计算多分类指标时赋予所有类别的每个样本相同的权重,将所有样本合在一起计算各个指标。
1.3.2 宏平均和微平均的比较:
- 如果每个类别的样本数量差不多,那么宏平均和微平均没有太大差异
- 如果每个类别的样本数量差异很大,那么注重样本量多的类时使用微平均,注重样本量少的类时使用宏平均
- 如果微平均大大低于宏平均,那么检查样本量多的类来确定指标表现差的原因
- 如果宏平均大大低于微平均,那么检查样本量少的类来确定指标表现差的原因
1.4 召回率
召回率指实际为正的样本中被预测为正的样本所占实际为正的样本的比例。
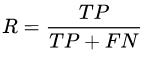
召回率直观地说是分类器找到所有正样本的能力. 召回率最好的值是1,最差的值是0.
1.5
F1 score
F1 score也被叫做F-score或F-measure。F1 score可以解释为精确率和召回率的加权平均值.
F1 score的最好值为1,最差值为0. 精确率和召回率对F1 score的相对贡献是相等的。
F1 score是精确率和召回率的调和平均值,计算公式为:
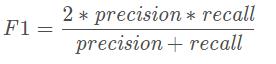
- Precision体现了模型对负样本的区分能力,Precision越高,模型对负样本的区分能力越强;
- Recall体现了模型对正样本的识别能力,Recall越高,模型对正样本的识别能力越强。
- F1 score是两者的综合,F1 score越高,说明模型越稳健。
1.6 ☆P-R曲线
评价一个模型的好坏,不能仅靠精确率或者召回率,最好构建多组精确率和召回率,绘制出模型的P-R曲线。
下面说一下P-R曲线的绘制方法。P-R曲线的横轴是召回率,纵轴是精确率。P-R曲线上的一个点代表着,在某一阈值下,模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本,此时返回结果对应的召回率和精确率。整条P-R曲线是通过将阈值从高到低移动而生成的。原点附近代表当阈值最大时模型的精确率和召回率。
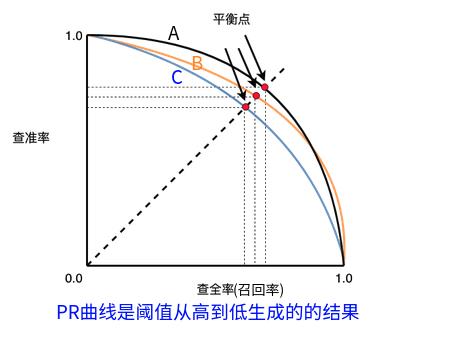
- 如果一个模型的P-R曲线被另一个模型的P-R曲线完全包住,则可断言后者的性能优于前者,例如上面的A和B优于学习器C。
- 如果两个模型的PR曲线相交,如A和B的性能无法直接判断,我们可以根据曲线下方的面积大小来进行比较,但更常用的是平衡点或者是F1值。
- 平衡点(BEP)是P=R时的取值,如果这个值较大,则说明学习器的性能较好。
- 而F1 = 2 * P * R /( P + R ),同样,F1值越大,我们可以认为该学习器的性能较好。
1.7 ☆ROC曲线
在ROC曲线中,横轴是假正例率(FPR),纵轴是真正例率(TPR)。
- 真正类率(True Postive Rate)TPR: TP / (TP+FN),代表分类器预测的正类中实际正实例占所有正实例的比例。
- 负正类率(False Postive Rate)FPR: FP / (FP+TN),代表分类器预测的正类中实际负实例占所有负实例的比例。
ROC曲线也需要相应的阈值才可以进行绘制,原理同上的PR曲线。
下图为ROC曲线示意图,因现实任务中通常利用有限个测试样例来绘制ROC图,因此应为无法产生光滑曲线,如右图所示。
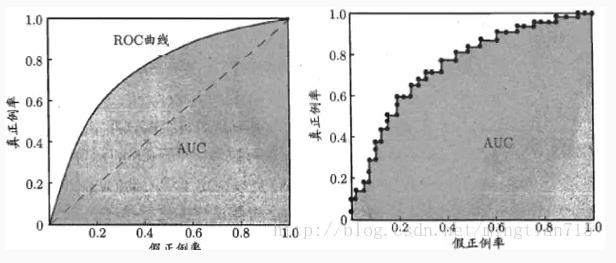
绘图过程:
- step1.给定m个正例子,n个反例子,根据学习器预测得分进行排序;
- step2.先把分类阈值设为最大,使得所有例子均预测为反例,此时TPR和FPR均为0,在(0,0)处标记一个点;
- step3.再将分类阈值依次设为每个样例的预测值,即依次将每个例子划分为正例。设前一个坐标为(x,y),若当前为真正例,对应标记点为(x,y+1/m),若当前为假正例,则标记点为(x+1/n,y),然后依次连接各点。
ROC曲线图中的四个点
- 第一个点:(0,1),即FPR=0, TPR=1,这意味着FN=0,并且FP=0。这是完美的分类器,它将所有的样本都正确分类。
- 第二个点:(1,0),即FPR=1,TPR=0,类似地分析可以发现这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。
- 第三个点:(0,0),即FPR=TPR=0,即FP=TP=0,可以发现该分类器预测所有的样本都为负样本(negative)。
- 第四个点:(1,1),分类器实际上预测所有的样本都为正样本。经过以上的分析,ROC曲线越接近左上角,该分类器的性能越好。
ROC曲线和PR曲线对比:
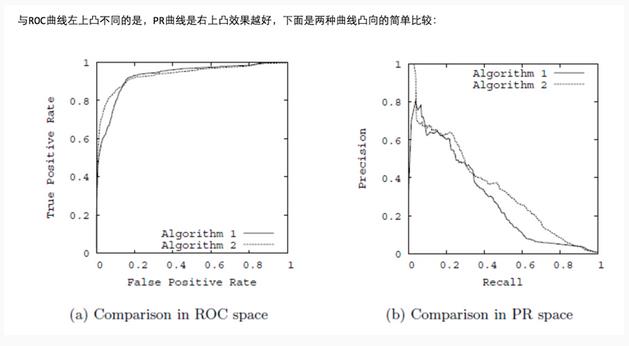
AUC:
AUC (Area under Curve):ROC曲线下的面积,介于0.1和1之间,作为数值可以直观的评价分类器的好坏,值越大越好。
- AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值
参考链接:https://www.jianshu.com/p/ac46cb7e6f87
二、目标检测MAP
参考链接:
目标检测中的precision,recall,AP,mAP计算详解 - 韩昊 - 博客园
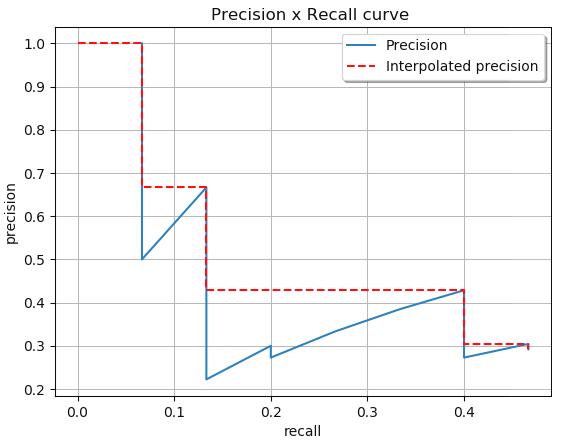
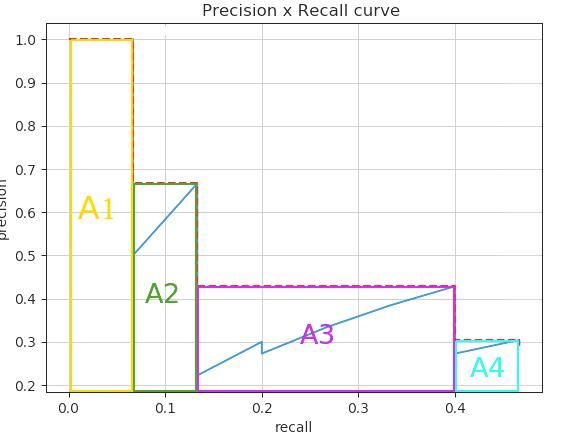
计算在所有点中执行的插值
通过内插所有点,平均精度(AP)可以解释为PR曲线的近似AUC。目的是减少曲线中摆动的影响。通过应用之前给出的方程,我们可以获得这里将要展示的区域。我们还可以通过查看从最高(0.4666)到0(从右到左看图)的Recall来直观地获得插值精度点,并且当我们减少Recall时,我们收集最高的精度值如下图所示:
注意:
1、为什么map的计算没有设置score_threshold?
- 计算PR曲线时,横坐标不同的召回率不是通过调整score阈值得到的,应该是累加计算所有的检测框得出来的,for循环遍历所有的检测框,然后更新AP和召回率的值,这样就得到了很多结果。
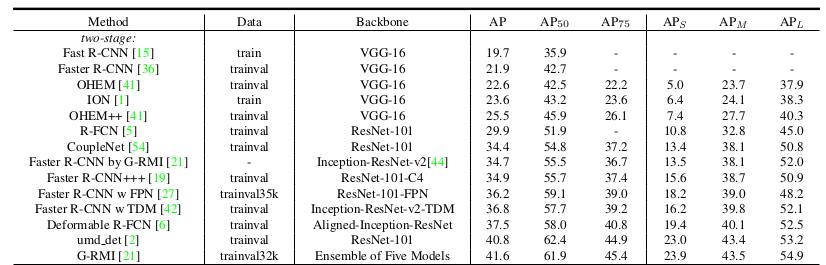
COCO mAP
最新的目标检测相关论文都使用coco数据集来展示自己模型的效果。对于coco数据集来说,使用的也是Interplolated AP的计算方式。与Voc 2008不同的是,为了提高精度,在PR曲线上采样了100个点进行计算。而且Iou的阈值从固定的0.5调整为在 0.5 - 0.95 的区间上每隔0.5计算一次AP的值,取所有结果的平均值作为最终的结果。

以上是关于深度学习模型评价指标的主要内容,如果未能解决你的问题,请参考以下文章