生信代码:机器学习-模型评价
Posted 科研菌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了生信代码:机器学习-模型评价相关的知识,希望对你有一定的参考价值。
↑↑↑ 关注选刊说 ↑↑↑
您的SCI选刊助手!
错误类型
二元预测:
决策类型:真阳性、假阳性、真阴性、假阴性。
关键指标:
・灵敏度:真阳性/(真阳性+假阴性)
・特异性:真阴性/(假阳性+真阴性)
・阳性预测值:真阳性/(真阳性+假阳性)
・阴性预测值:真阴性/(假阴性+真阴性)
・准确性:(真阳性+真阴性)/(真阳性+假阳性+真阴性+假阴性)
连续数据:
均方误差(Mean squared error,MSE):
均方根误差(Root mean squared error,RMSE):
常见错误指标:
-
MSE/RMSE 用于连续型数据,对离群点敏感 -
中值绝对偏差 取观测值和预测值之间的距离的绝对值的中位数,用于连续型数据 -
灵敏度 减少假阴性 -
特异性 减少假阳性 -
准确性 对假阳性、假阴性平均加权 -
一致性
ROC曲线
应用:利用ROC曲线可以找出合适的阈值,通过比较不同算法的ROC曲线可以选择最有效的算法。
ROC 曲线是以灵敏度(真阳性)为y轴、以1-特异性(假阴性)为x 轴,曲线上的点对应特定的阈值。
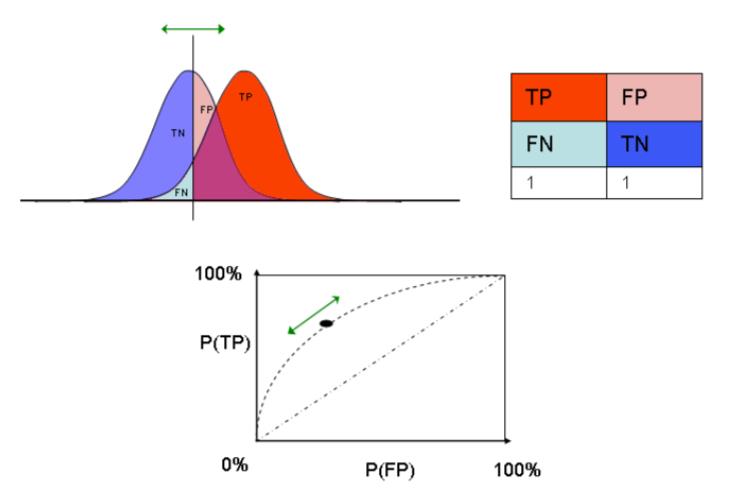
图1.ROC曲线
ROC曲线下的面积AUC:
ROC曲线下的面积AUC(Area under the curve)可以用来比较不同算法的优劣。
・AUC=0.5,预测算法表示为图中45º斜线,相当于随机对样本进行分类。
・AUC=1,预测算法表示为图中左上角顶点,在这个阈值下,可以得到100%的灵敏度和特异性,是个完美的分类器。
・通常AUC>0.8时可以认为是良好的预测算法。
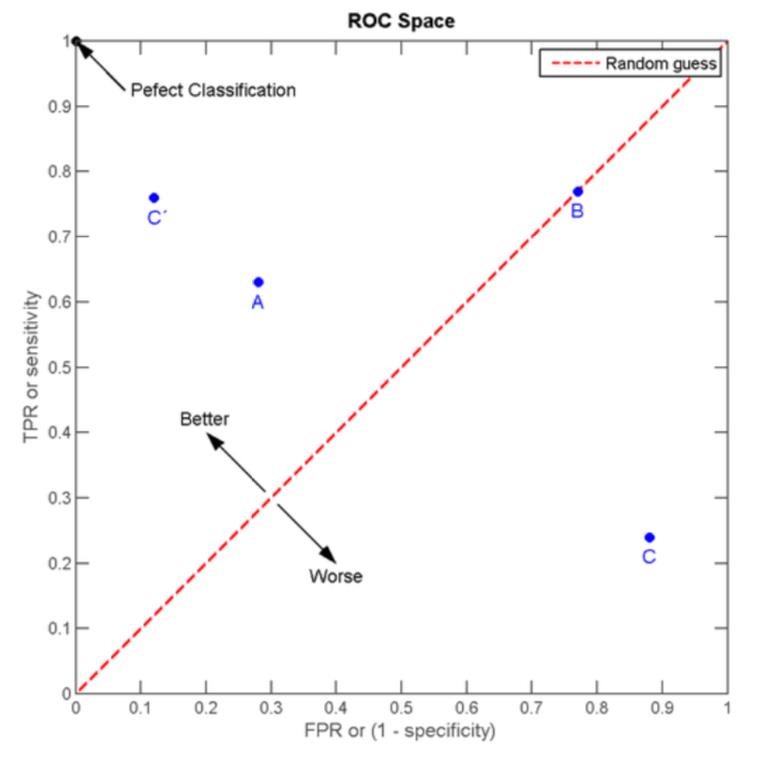
图2.AUC评价算法优劣
交叉验证(cross validation)
交叉验证法可以评价模型的泛化能力,而且可以用于某些参数的确定、变量的筛选等。
交叉验证将已有的样本训练集再分为训练集和测试集两部分,根据新的训练集建立模型,使用另一部分测试集进行验证,重复过程可以计算平均估计误差。常见的误差衡量标准是均方误差和均方根误差, 分别为交叉验证的方差和标准差。
1. 随机再抽样验证(random subsampling cross-validation):
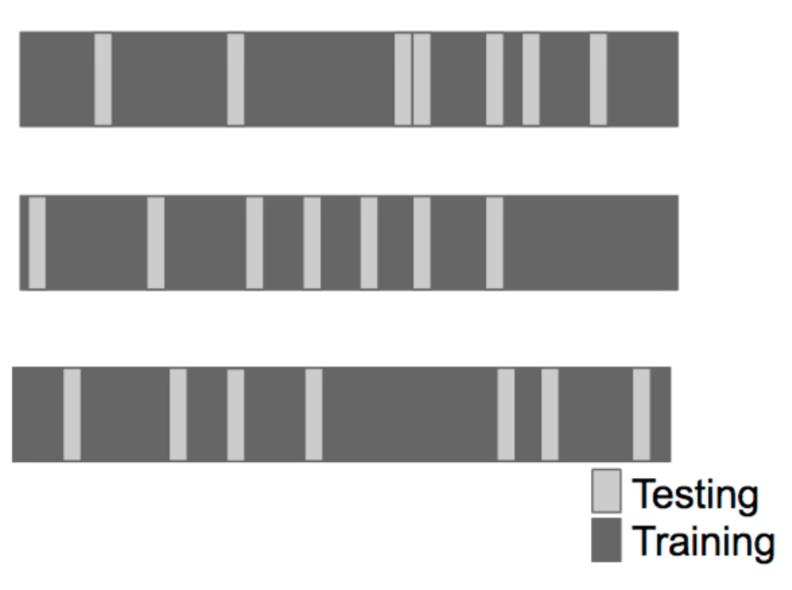
图3.随机再抽样验证
重复随机抽取测试集样本,计算平均估计误差。
2. K重交叉验证(K-fold cross-validation):
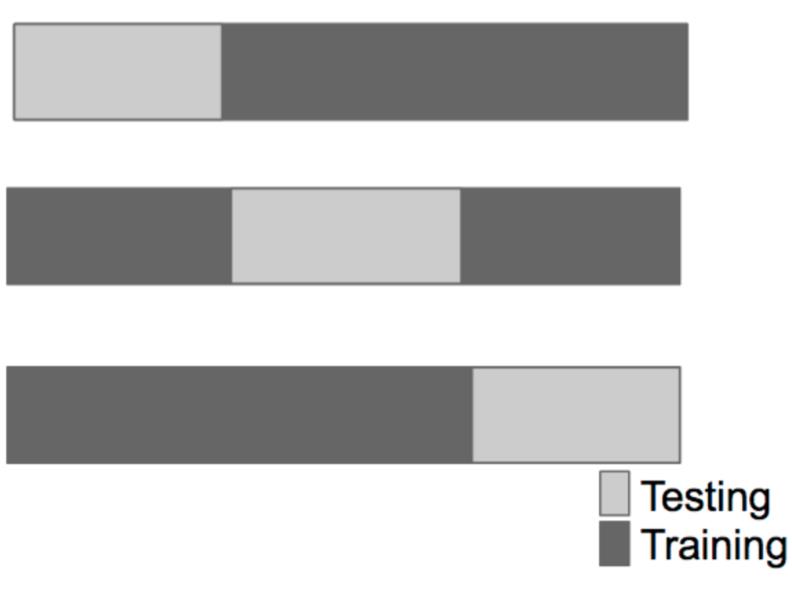
图4.K重交叉验证
将样本分为k个子样本,轮流将k–1个子样本组合作为训练集建立模型,另外1个子样本作为测试集,计算平均估计误差。
3. 留一交叉验证(leave-one-out cross-validation, LOOCV)

图5.留一交叉验证
只使用原本样本中的一项来当做测试集,而其余的作为训练集,重复步骤直到每个样本都被当作一次测试集,相当于k为原本样本个数的K重交叉验证。
所有这些模型的建立和评估都在训练集中进行,我们将其分为子训练集和子测试集以评估模型。
注意:
-
对于时间序列数据,一个时间点可能取决于先前的时间点,如果仅对数据进行随机再抽样,可能会忽略许多重要信息,因此必须使用连续的时间段数据。 -
对于K重交叉验证,一般而言,随着k的增加,偏差会变小(模型回代效果好),但方差会增大(验证效果差)。 -
随机抽样必须是无放回抽样,有放回抽样(bootstrap,自举法)会低估误差。 -
交叉验证得到的模型必须应用到新的独立的训练数据集以得到实际的训练集误差。
数据要求
预测有关X的某些信息,请尽可能使用与X密切相关的数据,数据相关性越低,预测越难。了解数据实际上如何与实际尝试预测的事物相关联非常重要,这是机器学习中最常犯的错误,机器学习通常被认为是一种黑箱预测程序,在一端输入数据,在另一端得到预测结果。
caret 包
内置函数:
・预处理:preProcess()函数
・数据分割:createDataPartition()函数、createTimeSlices()函数、createResample()函数
・训练和测试:train()函数、predict()函数
・模型比较:confusionMatrix()函数
R中内置的机器学习算法:
・线性判别分析(Linear discriminant analysis)
・回归分析(Regression)
・朴素(Naive Bayes)
・支持向量机(Support vector machines)
・分类回归树(Classification and regression trees)
・随机森林(Random forests)
・提升(boosting),等等
R中有来自不同的开发者开发的不同的机器学习算法,每种算法都略有不同。
表1 不同R包中的机器学习算法的预测函数
| 算法类型 | R包 | predict()函数语法 |
|---|---|---|
| lda | MASS | predict(obj)(不需设置选项) |
| glm | stats | predict(obj, type = "response") |
| gbm | gbm | predict(obj, type = "response", n.trees) |
| mda | mda | predict(obj, type = "posterior") |
| rpart | rpart | predict(obj, type = "prob") |
| Weka | RWeka | predict(obj, type = "probability") |
| LogitBoost | caTools | predict(obj, type = "raw", nIter) |
使用以上算法应用predict()函数预测时必须传递不同的type选项参数。caret包提供了一个统一的框架,允许只使用一种函数且不需指定选项来进行预测。
例:spam数据集
将数据分为训练集和测试集:
library(caret)library(kernlab)data(spam)inTrain <- createDataPartition(y=spam$type,p=0.75, list = FALSE) #75%的数据作为训练集training <- spam[inTrain, ]testing <- spam[-inTrain, ]dim(training)[1] 3451 58
拟合模型:
set.seed(32343)modelFit <- train(type ~., data = training, method="glm")modelFitGeneralized Linear Model3451 samples57 predictor2 classes: 'nonspam', 'spam'No pre-processingResampling: Bootstrapped (25 reps)Summary of sample sizes: 3451, 3451, 3451, 3451, 3451, 3451, ...Resampling results:Accuracy Kappa0.9207464 0.8333755
采用重抽样的方式测试模型,选择最佳模型。进行25次有放回重抽样,并校正了自举抽样可能带来的潜在偏差。
查看拟合的最佳模型:
modelFit <- train(type ~., data = training, method="glm")modelFit$finalModelCall: NULLCoefficients:(Intercept) make address all-1.541e+00 -3.248e-01 -1.448e-01 -4.829e-02num3d our over remove1.968e+00 4.750e-01 5.455e-01 2.218e+00internet order mail receive6.016e-01 5.926e-01 1.638e-01 -8.654e-01will people report addresses-1.416e-01 8.584e-02 1.268e-01 2.017e+00free business email you9.468e-01 1.084e+00 1.746e-01 9.129e-02credit your font num0002.903e+00 3.356e-01 1.740e-01 1.933e+00money hp hpl george2.605e-01 -2.556e+00 -7.866e-01 -9.418e+00num650 lab labs telnet6.231e-01 -2.372e+00 -3.618e-01 -7.320e-02num857 data num415 num851.305e-01 -4.910e-01 -1.918e+01 -5.939e+00technology num1999 parts pm1.180e+00 1.585e-01 -5.811e-01 -9.438e-01direct cs meeting original-2.426e-01 -4.281e+01 -3.005e+00 -1.240e+00project re edu table-1.790e+00 -8.871e-01 -1.212e+00 -1.981e+00conference charSemicolon charRoundbracket charSquarebracket-4.245e+00 -1.269e+00 -1.424e-01 -4.982e-01charExclamation charDollar charHash capitalAve3.084e-01 5.776e+00 3.337e+00 -1.680e-02capitalLong capitalTotal1.199e-02 6.359e-04Degrees of Freedom: 3450 Total (i.e. Null); 3393 ResidualNull Deviance: 4628Residual Deviance: 1367 AIC: 1483
进行预测:
predictions <- predict(modelFit, newdata = testing)predictions[1] spam spam spam nonspam spam spam spam spam spam spam[11] spam spam spam spam spam spam spam spam spam nonspam[21] spam spam spam nonspam spam spam spam nonspam spam nonspam[31] spam spam spam spam spam spam spam spam spam spam[41] spam spam spam spam spam nonspam spam spam spam spam[51] nonspam spam spam nonspam spam spam spam spam spam nonspam……Levels: nonspam spam
比较预测结果与实际结果,得到汇总统计信息:
confusionMatrix(predictions, testing$type)Confusion Matrix and StatisticsReferencePrediction nonspam spam #预测效果nonspam 660 59spam 37 394Accuracy : 0.916595% CI : (0.899, 0.9319) #准确性的置信区间No Information Rate : 0.6061P-Value [Acc > NIR] : < 2e-16Kappa : 0.8237Mcnemar's Test P-Value : 0.03209Sensitivity : 0.9469 #灵敏度Specificity : 0.8698 #特异性Pos Pred Value : 0.9179Neg Pred Value : 0.9142Prevalence : 0.6061Detection Rate : 0.5739Detection Prevalence : 0.6252Balanced Accuracy : 0.9083'Positive' Class : nonspam
加小编,请备注: 单位+研究方向


以上是关于生信代码:机器学习-模型评价的主要内容,如果未能解决你的问题,请参考以下文章