预训练语言模型XLNet: Generalized Autoregressive Pretraining for Language Understanding
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了预训练语言模型XLNet: Generalized Autoregressive Pretraining for Language Understanding相关的知识,希望对你有一定的参考价值。
·阅读摘要:
本文对标BERT模型,基于自回归(autoregressive, AR)和自编码(autoencoding, AE)两大阵营进行改进,提出了XLNet模型,并证明了XLNet比BERT的效果更好一些。
·参考文献:
[1] XLNet: Generalized Autoregressive Pretraining for Language Understanding
[2] BERT模型讲解,参考博客:【文本分类】BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[3] RoBERTa模型讲解,参考博客:【预训练语言模型】RoBERTa: A Robustly Optimized BERT Pretraining Approach
目前预训练语言模型按时间排:ELMo - GPT - BERT - XML - XLNet - RoBERTa - ALBERT。基本上越往后的模型效果越好。
XLNet是我目前看的最糟心的一篇论文,比Transformer和BERT还糟心。XLNet总给我一种“强行改进,打败BERT”的感觉。
[0] Abstract
BERT这样基于去噪自编码(autoencoding, AE)的预训练模型有很好地建模双向上下文的能力,性能优于基于自回归(autoregressive, AR)语言模型的预训练方法。然而,由于BERT需要mask一部分输入,BERT忽略了被mask的词的位置之间的依赖关系,因此出现预训练和微调效果的差异。
【注一】:AR模型与AE模型的区别将在Introduction中介绍。
基于上述问题,该研究提出了一种泛化的自回归预训练模型 XLNet。XLNet可以:
1)通过最大化所有可能的因式分解顺序的对数似然,学习双向语义信息;
2)用自回归本身的特点克服BERT的缺点。
3)此外,XLNet还融合了当前最优自回归模型Transformer-XL 的思路。
[1] Introduction
如下图,AR模型与AE模型的区别。

什么是AR模型?
在BERT出世之前,大家使用的语言模型其实是根据上文内容预测下一个可能跟随的单词,就是常说的自左向右的语言模型任务,或者反过来也行(就是根据下文预测前面的单词)。这种类型被称为自回归语言模型(autoregressive)。
例如RNN、LSTM、GPT 都是自回归语言模型。
Bi-LSTM、ELMO尽管看上去利用了上文,也利用了下文,但是本质上仍然是自回归 LM,它们只是分别做了两个方向的自回归(从左到右以及从右到左两个方向的语言模型),然后把两个方向的隐状态拼接到一起,所以其本质上仍然是自回归语言模型。
【注二】:参考上图的左边部分,预测第t个词,需要基于前t-1个词,所以说AR是一种单向的、不能使用全局信息的模型。再看它的损失函数,它使用的就是对数乘积似然。
AR模型的优缺点?
自回归语言模型的缺点是无法同时利用上下文的信息。它的优缺点跟下游 NLP 任务有关,比如生成类NLP任务,比如文本摘要,机器翻译等,在实际生成内容的时候,就是从左向右的,自回归语言模型天然匹配这个过程。而在生成类 NLP 任务中,比如阅读理解等,就存在明显训练与实际过程不匹配的情况。
什么是AE模型?
相比之下,基于AE的预训练旨在从有噪声的输入中还原原始数据。一个显著的例子是BERT。给定输入序列,15%部分的序列被特殊符号[MASK]替换,并训练模型从有噪声的版本中恢复原始序列。
AR模型在t时刻只能看到之前的时刻;而AE模型可以同时看到整个句子的所有的Token,即看到全局序列。
【注三】:参考上图的右边部分,预测第t个词,它是被mask的,可以基于全体序列x。
AE模型的优缺点?
这种 AE LM 的优缺点正好和 AR LM 反过来,它能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文。缺点主要在输入侧引入 [Mask] 标记,导致预训练阶段和 Fine-tuning 阶段不一致的问题,因为 Fine-tuning 阶段是看不到 [Mask] 标记的。
此外,由于预测的Token在输入中被mask,BERT不能像AR语言建模那样使用乘积规则来建模损失函数。
【注四】:到这里,再去看Abstract的第一段话,就很好懂了。“BERT需要mask一部分输入,BERT忽略了被mask的词的位置之间的依赖关系,因此出现预训练和微调效果的差异。”
【注五】:XLNet的目的是:融合自回归 LM 和 DAE LM 两者的优点。具体来说就是,站在 AR 的角度,如何引入和双向语言模型等价的效果。做法在Proposed Method部分。
[2] Proposed Method
[2.1] 排列语言建模
文章提出使用 排列语言建模(Permutation Language Modeling) 来融合AR LM 和 AE LM 两者的优点。
什么是排列语言建模?
设有一个输入序列L,通过随机取L排列的一种,然后将末尾一定量的词给 “遮掩”(并不是像BERT用 “[MASK]” 替换)掉,最后用 AR LM 的方式来按照这种排列方式依次预测被 “遮掩” 掉的词。
例如,假设一个序列L=[a, b, c, d, e],我们随便取它的一种排列 L 1 L_1 L1=[b, e, d, c, a],再随机遮掩掉末尾一个词变成 L 2 L_2 L2=[b, e, d, c, _]。这样当我们预测第5个词的时候(而实际它是原序列中第1个词),既是从左到右依次编码的,也是看到了全局信息才去预测的。
如何实现排列语言建模?
具体的实现方式不是打乱输入句子的顺序,而是保持原始序列顺序,使用与原始序列相对应的位置编码,而是通过对 Transformer 的 Attention Mask 来实现因子分解顺序的排列。
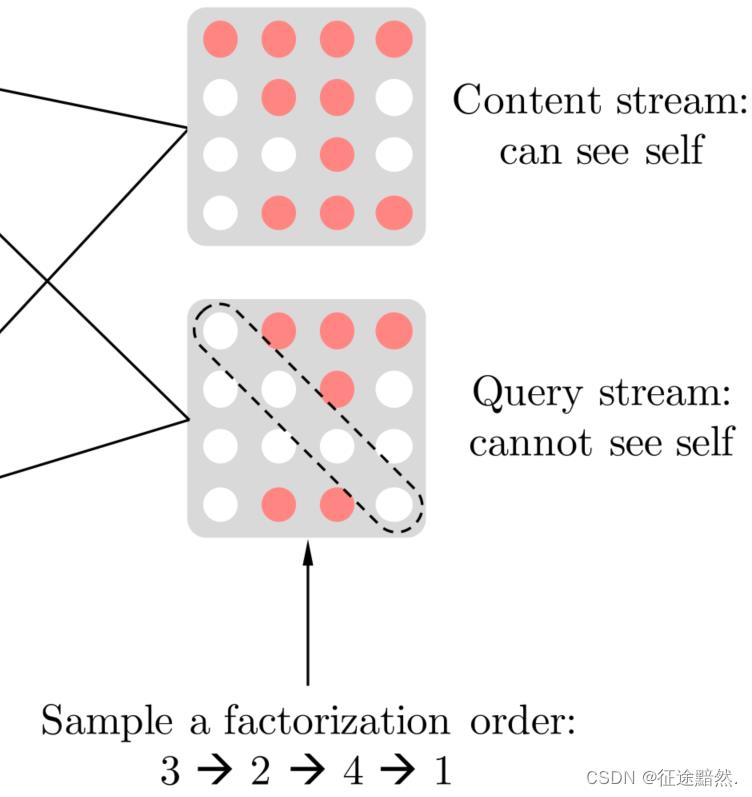
如上图,假设序列[1, 2, 3, 4]被打乱成了[3, 2, 4, 1]。
在“can see self”模式下,第1行代表序列[3, 2, 4, 1]中“1”的状态,由于它在最后,它什么信息都能看到,所以第一行都是红色;第2行代表序列[3, 2, 4, 1]中“2”的状态,由于“2”前面只有“3”,所以它能看到“2”、“3”的信息,所以第2、3个是红色;其他同理。
在“cannot see self”模式下,也同理,只是当前状态下不能看到自身的信息了。
[2.2] 目标感知表示的双流自注意
通过对 Transformer 的 Attention Mask 来实现因子分解顺序的排列之后,模型并不知道要预测的那个词在原始序列中的位置(目标预测中的模糊性)。
这个和Transformer中的位置编码没有关系。因为:1)假设模型知道一个词的向量,模型就能准确分辨出来这是序列中第几个词?2)况且在预测掩码时,我们肯定完全不知道这个词的任何信息,因此就不可能知道它要预测的词到底是哪个位置的词,所以我们必须 “显式” 的告诉模型我要预测哪个位置的词。
综上,我们不但要预测这个词的语义信息 X Z t X_Z_t XZt,还要预测它的位置信息 Z t Z_t Zt。
那么现在,对于我们的模型编码 g θ ( X Z < t , Z t ) g_\\theta(X_Z_<t,Z_t) gθ(XZ<t,Zt)有两个要求:
1) 为了预测当前词
X
Z
t
X_Z_t
XZt,模型编码
g
θ
(
X
Z
<
t
,
Z
t
)
g_\\theta(X_Z_<t,Z_t)
gθ(XZ<t,Zt)只能知道这个词的位置信息
Z
t
Z_t
Zt,而不可能知道这个词的语义信息
X
Z
t
X_Z_t
XZt。
2) 为了预测下一个词
X
Z
t
+
1
X_Z_t+1
XZt+1,模型编码
g
θ
(
X
Z
<
t
,
Z
t
)
g_\\theta(X_Z_<t,Z_t)
gθ(XZ<t,Zt)得知道前一个词的的语义信息
X
Z
t
X_Z_t
XZt。
综上,这个两个要求发生不可调和得矛盾,所以论文提出“目标感知表示的双流自注意”来解决。
为了解决这个问题,论文引入了两个 Stream,也就是两个隐状态(隐状态类似于RNN中的隐藏层):
内容隐状态
h
θ
(
X
Z
<
t
)
h_\\theta(X_Z_<t)
hθ(XZ<t),它就和标准的 Transformer 一样,既编码上下文(context)也编码
X
Z
t
X_Z_t
XZt的内容
查询隐状态
g
θ
(
X
Z
<
t
,
Z
t
)
g_\\theta(X_Z_<t,Z_t)
gθ(XZ<t,Zt) ,它只编码上下文和要预测的位置
Z
t
Z_t
Zt,但是不包含
X
Z
t
X_Z_t
XZt的内容。
这两个Stream的用法是,在预测第 Z t Z_t Zt词时使用查询隐状态 g θ ( X Z < t , Z t ) g_\\theta(X_Z_<t,Z_t) gθ(XZ<t,Zt);预测下一个词第 Z t + 1 Z_t+1 Zt+1词时,先操作一下内容隐状态 h θ ( X Z < t ) h_\\theta(X_Z_<t) hθ(XZ<t)与查询隐状态 g θ ( X Z < t , Z t ) g_\\theta(X_Z_<t,Z_t) gθ(XZ<t,Zt) ,更新一下查询隐状态 g θ ( X Z < t , Z t ) g_\\theta(X_Z_<t,Z_t) gθ(XZ<t,Zt)的内容,然后再预测。
[2.3] Transformer-XL
接下来 XLNet 借鉴了 Transformer-XL 的优点,它对于很长的上下文的处理是要优于传统的 Transformer 的。
Transformer-XL是对Transformer的改进或变种,主要是解决长序列的问题,其中XL表示extra long,在最近流行的XLNet中就是使用Transformer-XL作为基础模块。
[3] Conclusions
XLNet是一种通用的AR预训练方法,它使用排列语言建模目标来结合AR和AE方法的优点。XLNet的神经架构被开发为与AR目标无缝协作,包括集成Transformer XL和精心设计的双流注意机制。XLNet在各种任务上比之前的预培训目标有了实质性的改进。
以上是关于预训练语言模型XLNet: Generalized Autoregressive Pretraining for Language Understanding的主要内容,如果未能解决你的问题,请参考以下文章
预训练模型综述--Albert,xlnet,bert,word2vec