预训练模型:XLNet 和他的先辈们
Posted vpegasus
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了预训练模型:XLNet 和他的先辈们相关的知识,希望对你有一定的参考价值。
预训练模型
在CV中,预训练模型如ImagNet取得很大的成功,而在NLP中之前一直没有一个可以承担此角色的模型,目前,预训练模型如雨后春笋,是当今NLP领域最热的研究领域之一。
预训练模型属于迁移学习,即在某一任务上训练的模型,经过微调(finetune)可以应用到其它任务上。 在NLP领域,最早的预训练模型可以说是word2vec, Mikolov应用语言模型进行训练,产生的词向量(word embeddings)可以用于其他任务上,这样的词向量在目标任务上,可以固定不变,也可以随着模型训练进行微调。但word2vec自身有很多问题,比如其抓住的只是局部信息,一词多义无法区别等等。而且,词向量只是在自然语言模型中的张一层,而具体网络还需要根据任务重新设计,这样的预训练模型不是人们期待的样子。
目前,预训练模型研究上面如火如荼,研究文献也多得让人目不暇接不久前XLNet再次刷新各项NLP记录。本文来聊下XLNet与其先辈模型的发展历程。本文不能全部涵盖,只取其中影响较深的重要文献作介绍,简述训练模型的发展与现状。
word2vec 可以算最早的预训练模型了,也是当前预训练模型如此火热的火种,Mikolov功不可没。word2vec是为每个词预训练出词向量,企图刻画每个词其中蕴含的语义信息。
进一步地就有研究者想要刻画句子级别的句子向量,代表句子所涵盖的语义信息。非深度学习的方法有concatenated p-mean[5] 方法,而深度学习中中比较有代表性的有,skip-thought[1], inferSent[2]及quick thought[3].
要获取的句子级别的向量表示,最简单的方法就是句子中所有词向量的平均,但这种方法效果并不好,concatenated p-mean word embeddings 提出用power means的方法:
\\[
\\left(\\fracx_1^p+x_2^p+....+x_n^pn\\right)^\\frac1p; \\qquad p \\in R\\cup \\\\pm \\infty\\
\\]
并且发现p取1,正负无穷分别对应词向量的平均值,最大值与最小值,将三者拼接作为句子的向量。 这样得到的sentence embedding用于其它任务效果确实好于之前的结果。
在深度学习这边,skip-thought, 基本上是word2vec skip-gram在句子层面的应用,而最终的预测也借鉴语言模型给出一个decoder模块,通用性不足,inferSent则是借鉴CV中的想法,找到一个可能媲美ImagNet的数据集然后训练一个通用的句子encoder, 它认为SNLI[4]具备这样的潜质,并在此基础上训练句子encoder。inferSent在多个数据集上取得了较好效果。quick thought在二者的基础上做出改进,一是拿掉了skip-thought中的decoder, 换成了一个分类器,通用性大在提高了。 而且quick thought不使用 如inferSent中的SNLI这样的监督语料,而是使用无监督语料,进行下一句的预测。
ULMFiT[6]: 在ULMFiT之前的模型主要探讨句子的编码,并没有想要提供一个可以迁移的整个模型。ULMFiT算是真正将预训练模型这个研究方向点燃的研究,它是第一个体现出预训练模型优越性的模型。他在在多个文本分类数据集上取得当时最好效果的模型,并且只需要对模型进行很小的改动就可将模型再次应用到其他任务上。该研究立即引起了 人们的注意。 ULMFiT结构并不复杂,只是三层LSTM。它将语言模型的思想成功的应用在预训练中,将其作为预训练任务不但非常容易的获得非监督语料,而且模型效果大大提升。ULMFiT将建模工作分成了三人上阶段:1)通用领域的语言模型预训练;2)在目标任务数据集上进行语言模型微调;3)目标任务微调。
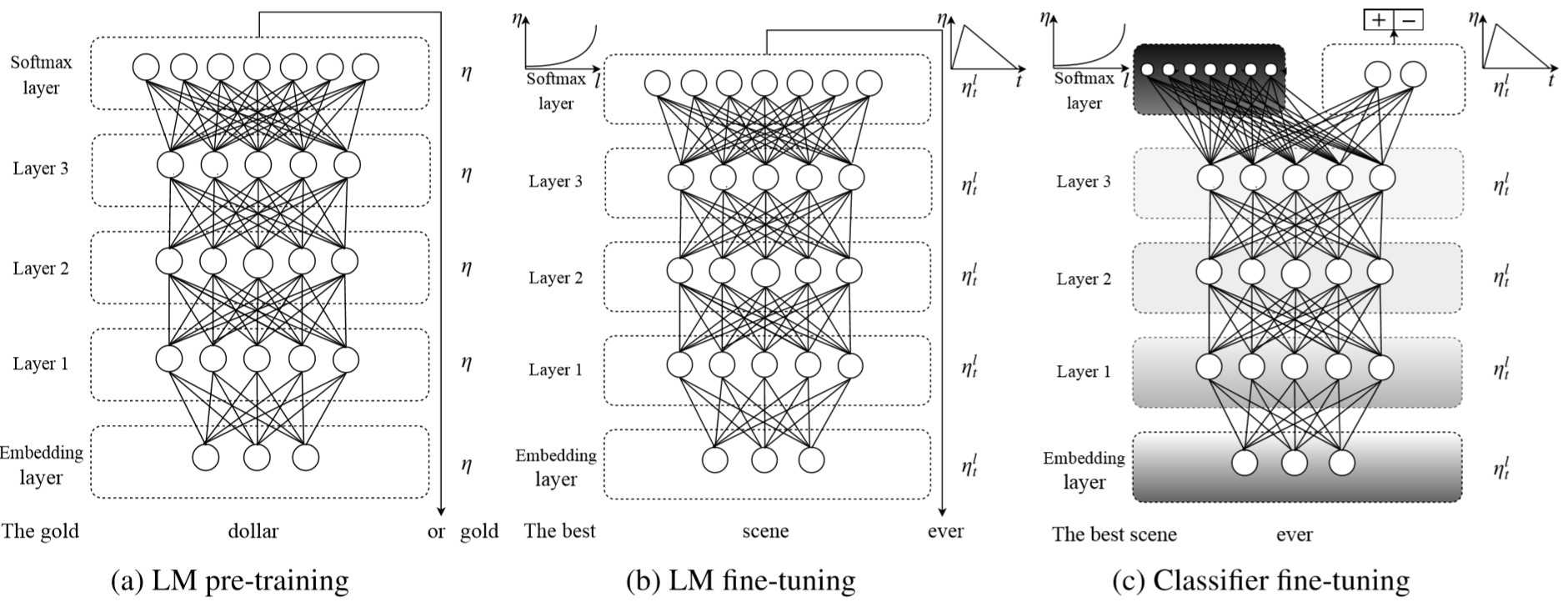
ELMo[7]: Embedding from Language Models, 是不得不提的一个研究,因为它将当时多个任务的最好模型的表现都提高了10%-20%, 是一个非常大的进步。不过ELMo做为预训练模型,还是为模型提供word embeddings,不是如ULMFit那样的完整预训练模型, 但也不似word2vec等模型的静态式的,而是将句子输入到EMLo模型中,为每个句子的每个词生成相应的词向量,这么说来,EMLo是动态的词向量,为每个词在其语义环境(context)下提供表征。
GPT[8] 与GPT2.0[9] 是OpenAI提出的模型,GPT是继ULMFiT之后强大的预训练模型,相比于其前辈,GPT终于使用上了目前已经非常流行的transformer。 transformer的特征提取能力已被多个模型证明强于RNN与CNN,已成为NLP中特征提取的首选模块。GPT仍就以语言模型为目标任务进行非监督式的训练,但却只使用上文信息,即单向的的transformer.
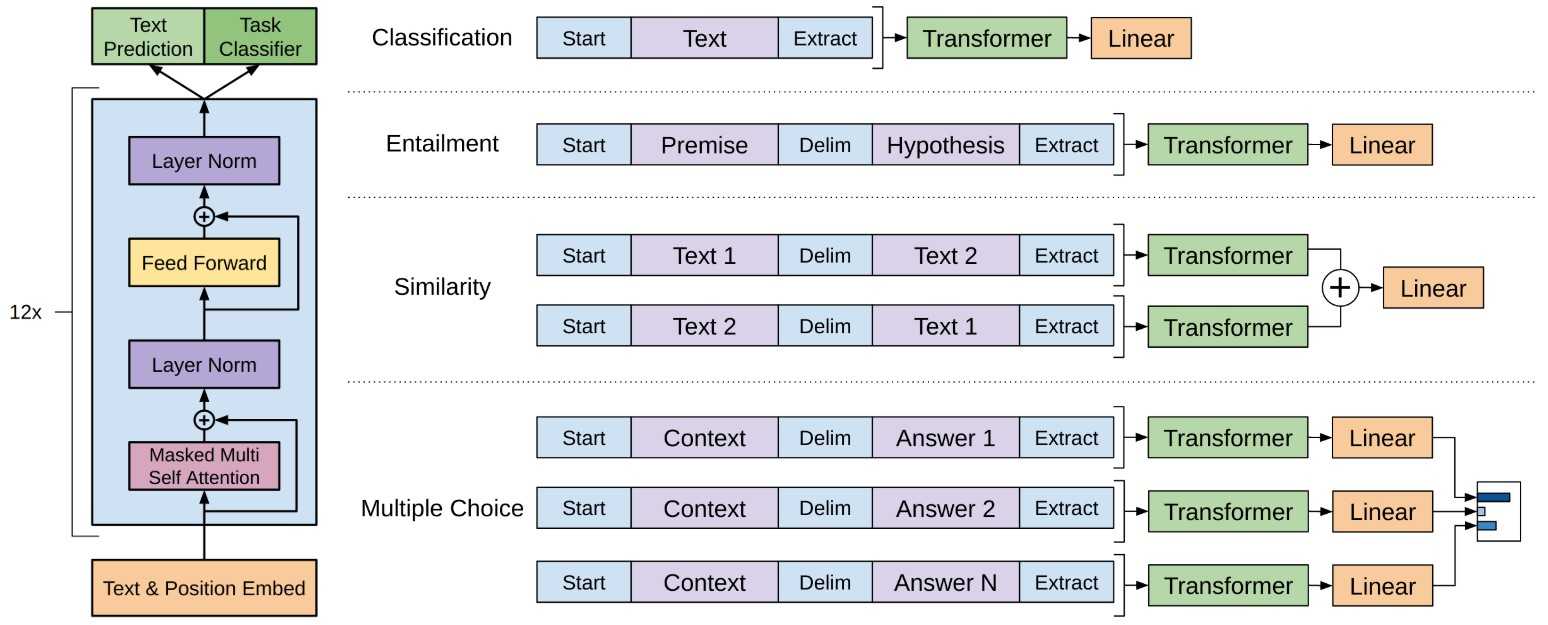
GPT是一个预训练模型,即在不同任务上使用同一个模型,只是不同任务input与output的方式不同,如上图举的分类,选择等任务的输入与输出的方式。GPT2.0是Bert(下文会提到)之后,OpenAI对GPT的改进版本,主要体现在数据量更大,模型更大上。
Bert[10]是目前名气最响的也是非常重要的预训练模型,是它将预训练模型推向了高潮,它在11个NLP任务上一举拿下当时最好结果。Bert相比于GPT使用了双向transformer,预训练时两个预训练任务同时进行,一个是经典的语言模型任务,不过稍稍修改了一下,即随机地将一定比例的词用"MASK"替换掉,然后预测这些被MASK掉的词原本是什么;另一个是二分类式的上下句判断任务。
XLNet[11]是最近最火的预训练模型,因为其在各个NLP任务上的表现基本都超过了Bert,甚至有些还是大幅超越。XLNet相比于Bert采用了TransformerXL, 并抛弃了MASKED 语言模型,而是提出了排序语言模型;不但如此,XLNet还提出了双流自己注意力模型。
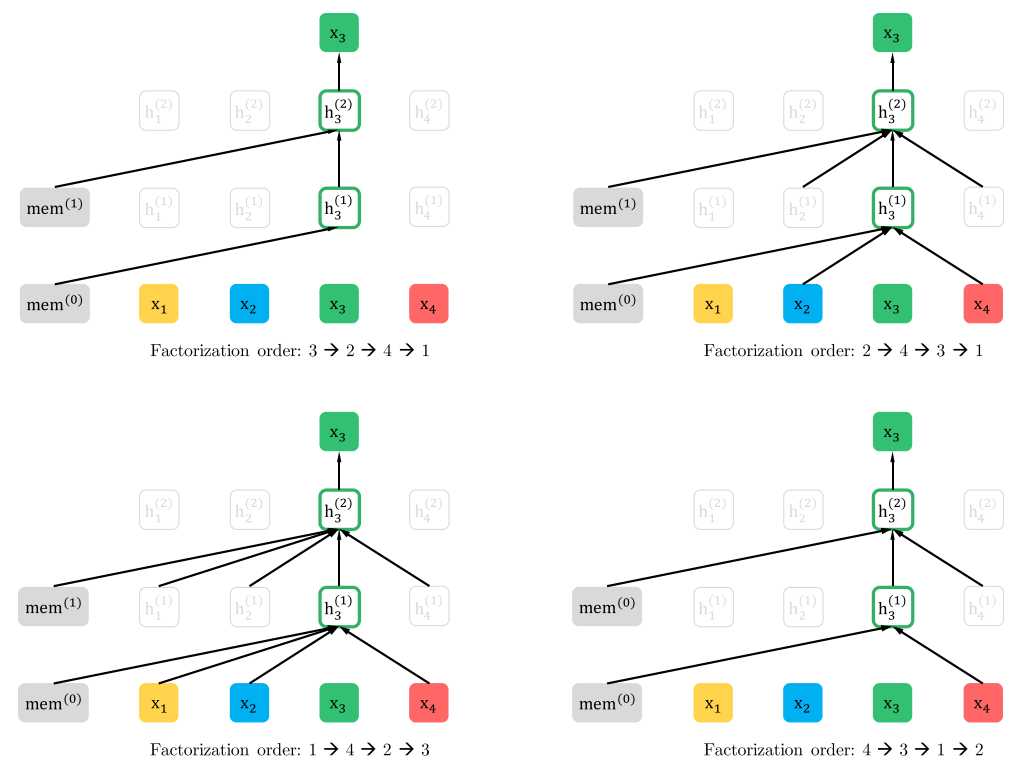
在XLNet论文中,作者将之前的语言模型分为两类,一种是自回归式的,一种是自编码式的。 自回归式的语言模型,即是用前文来预测当前词汇,不借助下文信息,例如,一句话由[x1,x2,x3,x,4,x5,x6,x7]组成(比如就是"黄河远上白云间"), 当我们预测x4时,只使用前文的x1,x2,x3,而不使用x5,x6,x7;而对于自编码式的语言模型,比如Bert,假设将x4 mask掉后,它会用x4周围的词来预测x4。自回归模型考虑文本中的各个词之间的联系性,但却只能使用单向信息,而自编码模型可使用双向信息,但却假设被mask掉的信息与语境之间相互独立,与实际有差距。为了同时获得二者的优势并规避掉缺点,XLNnet提出了排列式的语言模型: 即它将一段文本随机排序,如上文的x1到x7,重新排序之后,会出现这样的序列: [x3,x5,x1,x7,x4,x2,x6],那么使用自回归模型再预测x4时,就可利用来自下文(x5,x7)的信息。这里要注意,重新排序是保留位置信息的,比如上面的一段的下脚标(3,5,1,7,4,2,6),否则就是词袋模型了。另外,为使用输入方便,输入还是原始文本,对于排序的实现的方式是使用的注意力矩阵的方式:
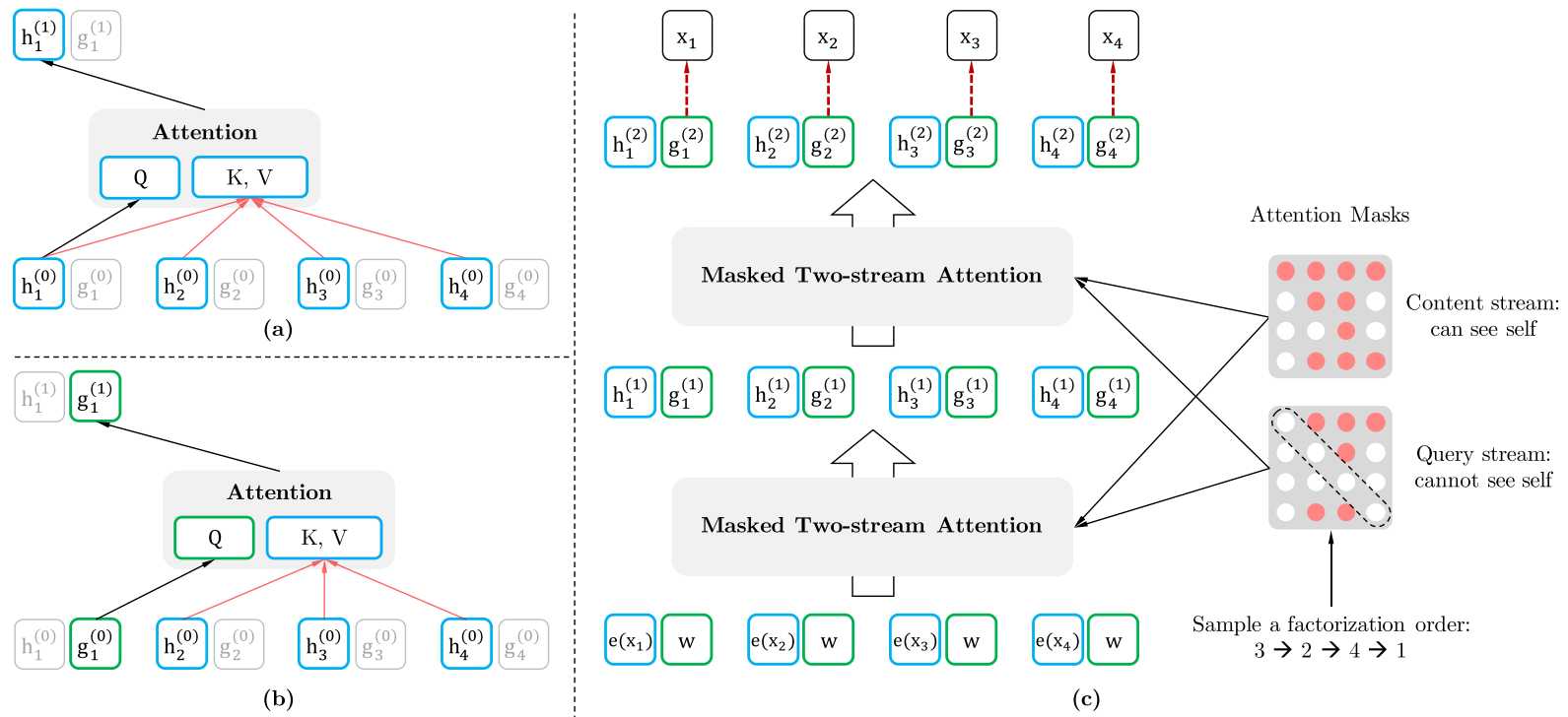
如上图(c)中, x1,x,2,x3,x4重新排列成x3,x2,x4,x1后,要预测x1,可以用到x3,x2,x4及x1的信息所以attention mask 矩阵第一行(代表x1)四个位置的文本信息就都是有用的(红色),而第二行(代表x2)可利用的文本信息只有x3与自身x2,而x3因为被排在了第一位,故前文无可用信息,所以attention mask矩阵的第三行只有一个红点(表示x3只能利用自己的文本信息). 但这里有个问题是,在预测当前位置(比如x4在第三个位置)时,只能用到前文信息,对于自身的信息,只能利用位置(这也是为什么下面的query attention矩阵的对角线为空),而对于内容是不可以的(不能使用x4来预测x4, 这是无意义的), 这就产生一了一个分歧,attention 有时要用内容信息(比如x3,x2预测x4时,x3,x2的所有信息都是可用的),有时却只能使用位置信息(比如在预测x4时,x3,x2的所有信息是可用的,但对于x4本身,我们却只能使用x4的位置信)。为解决这个问题,XLNet使用了双流attention机制,即一个刻画所有信息,另一个只刻画位置信息。
预训练模型还有其他一些模型,比如百度的ERINE,Microsoft的MASS, 还如roBerta等等,就不一一列举了。
预训练模型当前如日中天,也确实表现出其强大的能力,但,也因此将NLP的研究“贵族”化了,一般人要训练一个这样的模型,非常困难,只能看着大企业神仙打架了。另外,由于预训模型的良好表现,也劝退了很多在其他方向探索的研究者。
[1]: Kiros, R., Zhu, Y., Salakhutdinov, R., Zemel, R. S., Torralba, A., Urtasun, R., & Fidler, S. (2015). Skip-Thought Vectors, (786), 1–11. Retrieved from http://arxiv.org/abs/1506.06726
[2]: Conneau, A., Kiela, D., Schwenk, H., Barrault, L., & Bordes, A. (2017). Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, 670–680. https://doi.org/10.18653/v1/D17-1070
[3]: Logeswaran, L., Lee, H., & Arbor, A. (2016). An Efficient Framework for Learning Sentence. Iclr2018, 1–16.
[4]: Bowman, S. R., Angeli, G., Potts, C., & Manning, C. D. (2015). A large annotated corpus for learning natural language inference. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, 632–642. https://doi.org/10.18653/v1/D15-1075
[5]: Rücklé, A., Eger, S., Peyrard, M., & Gurevych, I. (2018). Concatenated Power Mean Word Embeddings as Universal Cross-Lingual Sentence Representations. Retrieved from http://arxiv.org/abs/1803.01400
[6]: Howard, J., & Ruder, S. (2019). Universal Language Model Fine-tuning for Text Classification, 328–339. https://doi.org/10.18653/v1/p18-1031
[7]: Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contextualized word representations. https://doi.org/10.18653/v1/N18-1202
[8]: Radford, A., & Salimans, T. (2018). Improving Language Understanding by Generative Pre-Training. OpenAI, 1–12. Retrieved from https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
[9]: Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2018). Language Models are Unsupervised Multitask Learners.
[10]: Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, (Mlm). Retrieved from http://arxiv.org/abs/1810.04805
以上是关于预训练模型:XLNet 和他的先辈们的主要内容,如果未能解决你的问题,请参考以下文章