Hbase面试
Posted lucky_xian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbase面试相关的知识,希望对你有一定的参考价值。
Hbase知识点总结
- 1.Hbase是什么,Hbase的特点是什么?
- 2.Hbase是如何导入数据的?
- 3.Hbase的存储结构?
- 4.解释下Hbase实时查询的原理?
- 5.描述下Hbase rowkey的设计原则,rowkey的长度原则?
- 6.描述Hbase中scan和get功能以及实现的异同?
- 7.详细描述Hbase中一个cell的结构?
- 8.简述Hbase中compact的用途是什么,什么时候触发,分为那两种,有什么区别,有哪些相关配置参数?
- 9.Hbase实现了哪两种compaction方式,minor和major这两种compaction方式有什么区别?
- 10.简述Hbase filter的实现原理是什么,结合实际项目经验,写几个使用filter的场景?
- 11.Hbase内部机制?
- 12.Hbase宕机如何处理?
- 13.HRegionServer宕机如何处理?
- 14.Hbase写数据和读数据过程?
- 15.Hbase优化方法?
1.Hbase是什么,Hbase的特点是什么?
- 本质:Hbase是一个分布式键值存储,列簇式数据库;
- 数据模型 :
- 逻辑视图:它是以表形式组织的
- **table:**表,一张表包含多行数据;
- row:行,一行包含唯一的rowkey,多个column,以及value,表中的row按照rowkey以字典序进行排序;
- column:列,Hbase中的列表示为列簇名:列名,一张表包含固定数量的列簇,且列簇在表创建时需要指定,一个列簇包含不定数量的列,Hbase不会存储值为null的列(稀疏性)
- timeStamp:时间戳,Hbase可以存储一个数据多个版本,版本以时间戳来区分,timestamp越大,版本越新;
- cell:单元格,由五元祖组成(rowkey, column, timestamp, type, value),这个结构在数据库里实际上是用KV形式存储的,[rowkey, column, timestamp, type]组合为key,value为value;
- 物理视图:它是以KV键值对存储的
- 数据按照列簇分开存储在不同的目录中;
- 特点:
- 1.多维:可以存入多个版本;
- 2.稀疏:HBASE不存储值为null的列;
- 3.排序:Hbase中的数据是以rowkey按照字典序进行排序的;
- 4.容量巨大:Hbase本质上存储的是(K,V)键值对,且按照列簇存储数据,所以同一行的数据不必存储在同一个节点上,所以容易扩展,故可以通过增加节点的方式不断扩大容量;
- 5.Hbase支持ttl,即支持数据过去;
- 6.Hbase是把数据写到HDFS上的,故和Hadoop兼容性非常好,且数据写入为追加式写入,故效率特别高;
- 7.不支持二维索引;
- 8.不支持复杂的聚合运算;
- 9.不支持跨行事务;
- 使用场景:适合存储半结构化或非结构化数据,这种数据结构不确定的字段很难按照一个概念去抽取形成关系型数据库,而Hbase列的定义十分松散,用来存储大数据量的半结构或者非结构化数据十分适合。
2.Hbase是如何导入数据的?
- 1.通过API方式将数据存储到Hbase中:
-
客户端处理阶段:客户端对数据进行预处理,根据元数据定位数据写入的RegionServer,并发送请求写入数据数据。
- 1.处理批次大小:选择是否缓存put请求(设置缓存吞吐量大,但客户端崩溃会丢失部分已提交数据);
- 2.定位RegionServer:定位对应的RegionServer(mate元数据缓存在客户端中,如果在元数据里可以定位到RegionServer,则发送数据,否则,从Zookeeper节点(/hbase-root/meta-region-server)读到元数据所在的RegionServer地址,然后从该地址读到元数据并将其缓存到本地,供后续使用);
- 3.发送请求:Client为每一个Regionserver构造一个RPC请求,将数据通过protobu序列化厚发送给Regionserver。
-
MemStore写入阶段:RegionServer接到数据后,把数据存储于WAL文件中,然后对应Region列簇的MemStore中,数据在写入MemStore后就会向客户端返回写入成功;
- Hbase将请求反序列化,首先进行一系列检查操作,包括待写入Region是否是只读,MemStore大小是否已经超过阈值需要flush等。
- 数据写入步骤:
· 1.Hbase为该行数据加上行锁(避免多个线程一起更新此行数据);
· 2.Hbase为该行数据加上时间戳,默认使用当前系统时间;
· 3.在内存中构建WALEdit对象,将数据存入到WALEdit对象中;
· 4.将WALEdit对象按照顺序写到HLog中,此时WALEdit并未sync到磁盘上(级别:只存内存,异步持久化,同步持久化,默认));
· 5.Hbase将数据写入到对应列簇的MemStore中;
· 6.释放行锁(尽量减少行锁持有时间,提高并发度);
· 7.将WALEditsync到磁盘上,若此步骤失败,则执行回滚操作将memstore中的数据删除;
· 8.结束写事务,此时该线程的更新操作才会被读请求看到。 - MemStore写入流程:
· 1.判断当前MemStore大小是否超过阈值,超过的话重新申请一个chunk;
· 2.在内存中对KeyValue重新进行构建,在可用Chunk的指定offset处申请内存构建
· 3.将该对象写入到ConcurrentSkipListMap中;
-
MemStore Flush阶段:当MemStore中的数据超过一定阈值时,就会进行flush。
- 触发时机 :
· 1.MemStore大小超过阈值,需要flush;
· 2.执行Major Compaction以及minor Compaction动作,或者region迁移操作;
· 3.Region级别,Region总MemStore的大小超过阈值,触发flush;
· 4.RegionServer级别:若MemStore超过低水位,强制执行flush操作,从大到小依次执行,若超过高水位,则强制停止数据接入,强制执行flush,直到总的MemStore下降到低水位阈值。
· 5.HLog数量达到上限,则将最早的Hlog对应的MemStore进行Flush
· 6.用户手动执行flush
· 7.Hbase定期flush,避免所有MemStore在同一时间执行flush。 - flush流程 :两阶段提交
· 1.prepare阶段:遍历当前Region所有的MemStore,将MemStore中的当前ConCurrentSkipListMap做成快照,然后新建一个ConCurrentSkipListMap用于数据写入,此阶段对写入阻塞,但耗时极短;
· 2.flush阶段:将prepare阶段的快照文件持久化,所有持久化文件都放在临时文件夹.tmp下;
· 3.commit阶段:将.tmp中所有的临时文件移动到指定的ColumnFamily目录下,根据Hfile生成storeFile和Reader,然后将快照文件清空。- HFile文件生成 :将MemStore数据转换成Hfile格式存储。
1.组成:
· 1.Scanned Block:存储真实的数据,包括Data Block,Bloom Block以及LeafIndex Block;
· 2.Non-Scanned Block:存储MateBlock,一般不需要关心;
· 3.Load-On-Open:存储Hfile元数据信息,包括索引根节点等,在RegionServer打开Hfile是就会被加载到内存中;
· 4.Trailer:存储Scanned-Block和Load-On-Open的偏移地址,文件大小,版本号等基础信息,也会在打开时被加载到内存中;
2.构建Scanned Block:
· 1.创建Scanner从ConCurrentSkipList中顺序读取每个cell;
· 2.在内存中根据算法构建Bloom Block以及针对Delete数据的Bloom Block;
· 3.将cell写入Data Block中;
3.构建Bloom Block: Bloom过滤器内存中维护了很多chunk,每个chunk的结构如下:
· 1.一块连续的数组区域,初始状态数组所有位都为0,cell进来后根据rowkey的Hash映射对某些位置值为1;
· 2.firstkey:存入写入该chunk的第一个rowkey,用来构建Bloom Block Index;
4.构建Data Block:
· 1.使用特定编码对cell进行编码处理;
· 2.将编码过后的cell写入DataOutPutStream;
· 3.DataOutPutStream大小超过阈值会将数据flush形成Data Block;
5.构建Leaf Index Block:
· 1.DataBlock完成落盘后,会立刻生成一个leafIndexEntry,然后将该LeafIndexEntry添加到该Leaf Index Block;
· 2.LeafIndexBlock大小超过阈值后会落盘,LeafIndexBlock和DataBlock可以在Scanned-Block中穿插存储
· 3. LeaFIndexEntry包含三个元素:对应DataBlock的第一个key,DataBlock的偏移量和DataBlock的大小,用以索引到该DataBlock时第一时间将其加载到内存中;
· 4.LeafIndexBlock落盘后还要向上构建Root IndexBlock,Root Index Block存放在Load-On-Open模块;
6.构建Bloom Index Block:
· 1.DataBlock完成落盘后,会检查当前是否有写满的Bloom Block,若有则落盘;
· 2.落盘流程可参考LeafIndexBlock落盘; - 总结 : 1.flush数据来源: MemStore和Compaction的flush流程没有任何区别,知识数据来源不同,一个是读内存中MemStore的数据,一个是读多个HFile数据生成一个大Hfile文件;2.flush过程:flush首先构建Scanned-Block,在内存中创建Data Block用于存储数据,Bloom Block用于构建布隆过滤器,Leaf Index Block用于存储索引,将cell按顺序读取后编码写入DataBlock,并在Bloom Block中根据Hash映射将该Block数组对应位置值为1,若DataBlock超出阈值则落盘,落盘时生成一个LeafIndexEntry存入LeafIndexBlock中,同时检查Bloom Block与LeafIndexBlock是否超过阈值,若超过则落盘,故Scanned-Block是DataBlock,LeafIndexBlock和BloomBlock三者交错存储,内存中构建了RootIndexBlock和BloomIndexBlock,每当Bloom Block与LeafIndexBlock落盘时,则生成一个Entry存放到对应的位置中,RootIndexBlock和BloomIndexBlock在最终都会存储在Load-On-Open中;3.数据块生成步骤:先构建Scanned-Block,事实上,每写入一个cell都在动态的构建Scanned-Block,等Scanned-Block生成完毕后,就开始依次构建静态部分:Non-Scanned-Block,Load-On-Open,Trailer.
- HFile文件生成 :将MemStore数据转换成Hfile格式存储。
- 触发时机 :
-
MemStore Flush对业务的影响:
- 1.Region级别的Flush对业务基本无影响,因为只有在prepare阶段(为ConCurrentSkipMap设置快照时不允许有数据接入,但这个过程很快) ,此级别的flush有:MemStore超过阈值,整个Region的MemStore大小超过阈值,大小紧缩与region前移,用户手动进行flush,Hlog数量超过上限导致的flush,Hbase定期执行的flush。
- 2.RegionServer级别的Flush分两种,一种是整个RegionServer的MemStore大小到达低水位未超过高水位,此时只会触发强制flush,对写入业务影响不大,若MemStore大小到达高水位,RegionServer就会强制停止数据接入,此时就会对业务造成较大影响。
-
- 2.使用bulkLoad方式导入:
- 本质:把存储在HDFS的数据按照HFile的格式组织起来,然后在Hbase的data:mate表中补充元数据,就完成了数据导入。
- 背景:数据在HDFS上,用户需要将海量数据通过API写入到Hbase中,因为数据量过大,会给RegionServer带来极大压力,出现以下几种情况:
- flush影响:导致RegionServer不断进行flush,进而不停地compaction,split,影响集群稳定性;
- MemStore影响:导致RegionServer不断进行JVM垃圾回收(主要回收MemStore),导致系统GC;
- 资源消耗:这种写入方式需要耗费大量内存,CPU,网络,IO资源,可能会影响该Hbase集群的其他业务,以及与该Hbase集群部署在一起的其他集群的业务;
- 线程消耗:若平均KV较大的情况下,RegionServer处理KV会耗费较长时间,导致RegionServer的线程长时间不能被释放而耗尽,导致集群阻塞;
- 解决方案:BulkLoad,使用MapReduce将HDFS数据转换成Hfile文件,然后将这些Hfile文件加载到Hbase集群中直接管理,可以避免上述问题。
- BulkLoad核心流程:
- Hfile生成:使用MapReduce对HDFS文件进行处理得到Hfile文件,其中map过程需要用户自己编写,将HDFS文件读出来组装成KV对象,其中K为rowkey,V可以为一个KeyValue,或者Put对象或者Delete对象,reduce过程由Hbase的一个方法负责,这个方法主要负责以下事项:
- 1.需要根据表信息设置一个全局的partitioner(用于将数据按照region分配);
- 2.将partitioner上传到集群的distributedcache中;
- 3.根据目标表的Region个数设置Task;
- 4.设置输出的Key/Value满足HFileOutPutFormat格式要求;
- 根据类型设置reducer执行相应的排序;
此步骤可以根据Hbase文件目录生成Hfile文件。
- Hfile导入: 使用completebulkload工具将Hfile文件导入:
- 遍历第一步生成的HFile文件,将其与Region建立映射关系;
- 将HFile文件移动到相应Region所在的目录;
- 通知RegionServer加载相应的Hfile文件(通过修改元数据以及Zookeeper上的元数据进行加载);
- 如果在导入过程中,Region发生了分裂,completeBulkLoad工具会自动对其进行处理,但是这个过程并不搞笑,需要读取Hfile文件,所以建议生成Hfile文件后,立刻进行导入工作。
- Hfile生成:使用MapReduce对HDFS文件进行处理得到Hfile文件,其中map过程需要用户自己编写,将HDFS文件读出来组装成KV对象,其中K为rowkey,V可以为一个KeyValue,或者Put对象或者Delete对象,reduce过程由Hbase的一个方法负责,这个方法主要负责以下事项:
- 注意事项:
- Hbase1.3之后才开始支持BulkLoad的数据迁移,若有peer集群的需要请注意Hbase版本。
实例参考博客:https://www.cnblogs.com/smartloli/p/9501887.html
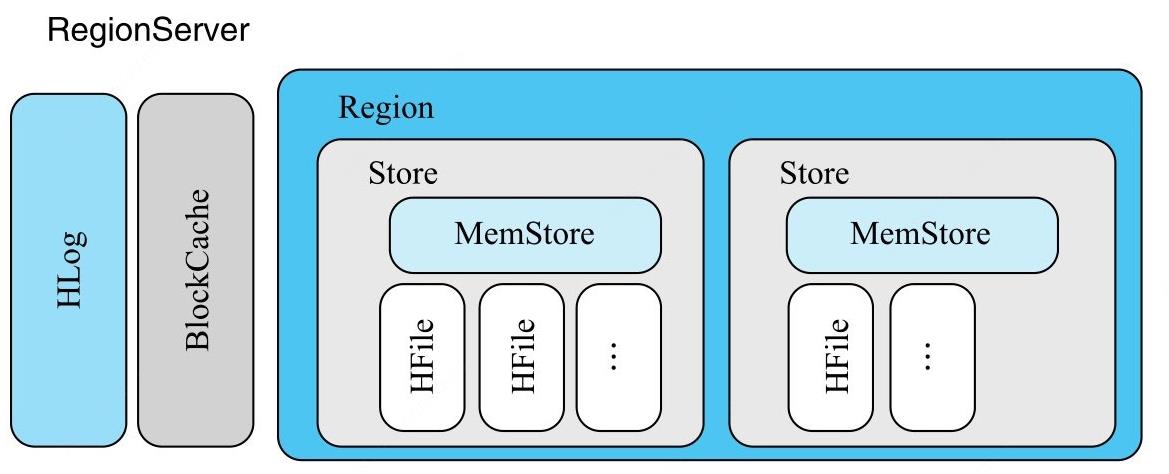
3.Hbase的存储结构?
-
Hbase内部存储结构:
- Hbase每张表都根据行键按照一定范围被分割为多个子表;
- 默认一个Region超过256M就要被分割为2个;
- RegionServer用于管理Hbase中所有的Region;
- Regionserver中包括HLog(一至多个),BlockCache(1个),Region(1至多个);
- Region用来存储表数据,它包括HStore(1至多个,存储列簇)
- Store:存储列簇,包含MemStore(1个),HFile(1至多个,存放在HDFS上,存储实际的数据文件);
- HFile:存储数据,包括四部分:Scanned-Block(DataBlock,BloomBlock,IndexLeafBlock),Non-Scanned-Block,Load-On-Open,Trailer;
-
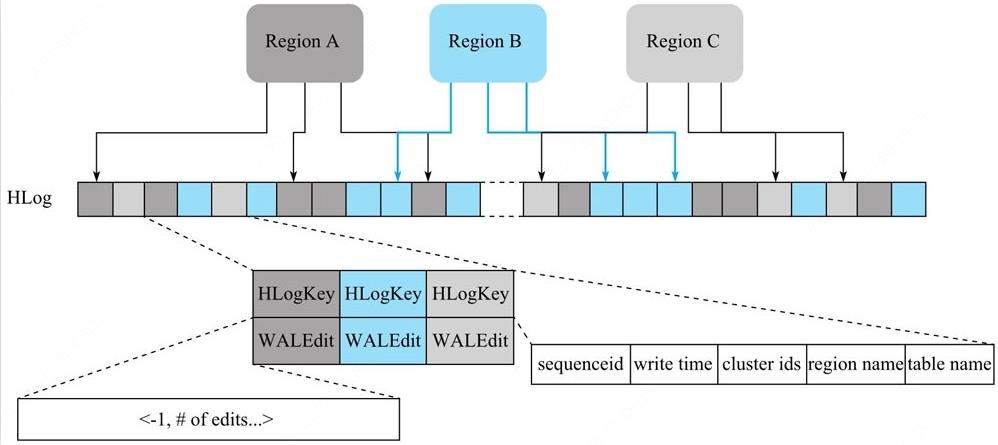
HLog:在Hbase中用于主从复制和故障恢复,所有的写入工作都先写入到HLog中,再写入MemStore,大多数情况下Hlog都不会被读取,但是RegionServer异常宕机,这时候保存在内存中的MemStore的数据就会丢失,这时候就需要回放HLog恢复数据。
- 结构图如下:
- 每个RegionServer可以有一至多个HLog;
- HLog由多个Region共享;
- Hlog中,最小追加但愿是WALEntry,每个WALEdit由HLogKey和WALEdit组成,其中HLogKey有TableName,region name和sequenceid组成;
- 一个行级的事务写入操作在HLog里被表示为一个记录;
- HLog目录如下:
- /hase/WALs:存储未过期日志;
- /hbase/oldWALs:存储过期日志;
- ./hbase wal -j /hbase/WALs/node1,16020,1589885827336/node1%2C16020%2C1589885827336.1590566316907:以Json的方式输出wal日志;
- HLog生命周期:
- HLog构建:Hbase的任何写入操作,会在内存中将KeyValue构建出一个WALEntry对象,然后将该WALEntry落盘到HLog中(一共有四种落盘级别);
- HLog滚动:Hbase后台会启动一个线程,每隔一段时间都新建一个HLog日志,来接收新的WALEntry,这样做的目的是为了以文件的形式清理日志,间隔时间由参数hbase.regionserver.logroll.period决定;
- HLog失效:对应的MemStore中的数据落盘,HLog中的日志就可以认为已经失效,失效后的日志会从WALs目录移动到OldWALs中,此时该HLog日志并未删除;
- HLog删除:Hbase后台会启动一个线程,每隔一段时间检查一下oldWALs目录的失效日志,确认是否可删除,确认可删除即执行删除操作,删除条件有两条:
- 该HLog是否还参与主从复制;
- 该HLog是否在oldWAls目录下存储了10分钟;
- 结构图如下:
-
MemStore:因为HBase的数据是顺序追加存储在HDFS上的,所以MemStore在写数据时承担了排序工作,读数据时,先从MemStore中读取,读取不到才会去读取HFile;
- MemStore概述:
- 和Hfile在一个层级,每个Store由一个MemStore和一系列HFile组成;
- LSM树组成部分,数据写入顺序:HLog——MemStore——MemStore经过flush形成HFile;
- LSM树优点:
- 将一次随即写入转换为顺序IO写入和一次内存写入;
- HFile中的数据按照rowkey进行排列;
- MemStore总是缓存着最近写入的数据;
- 在数据形成HFile文件时,可以在MemStore中进行优化(例如,设置了仅保留新版本数据,就可以在内存中(MemStore)丢弃旧版本数据);
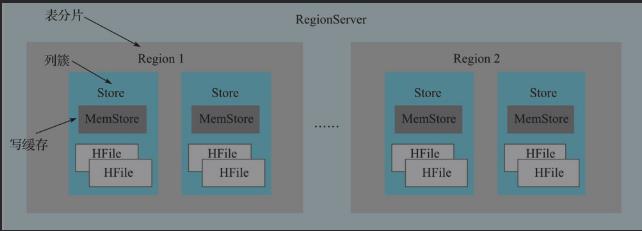
- MemStore内部结构:
- MemStore职责:1.承担数据高效写入;2.承担多线程并发读;
- 采用了ConCurrenntSkipListMap结构,此结构线程安全,底层采用CAS原子性操作,满足了多线程,跳跃表可以保证写入,查找,删除都能在O(LogN)的复杂读完成,满足了数据高效写入;
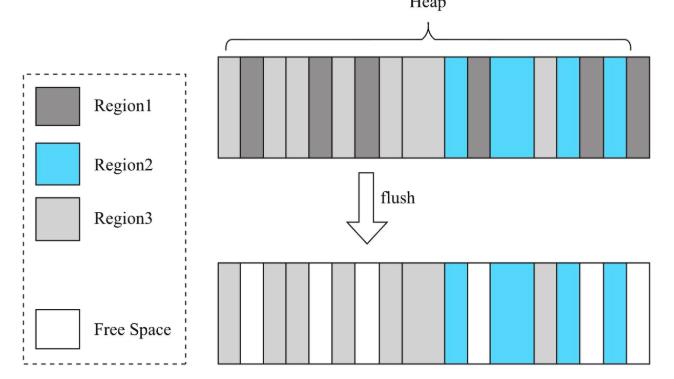
- MemStore内存管理
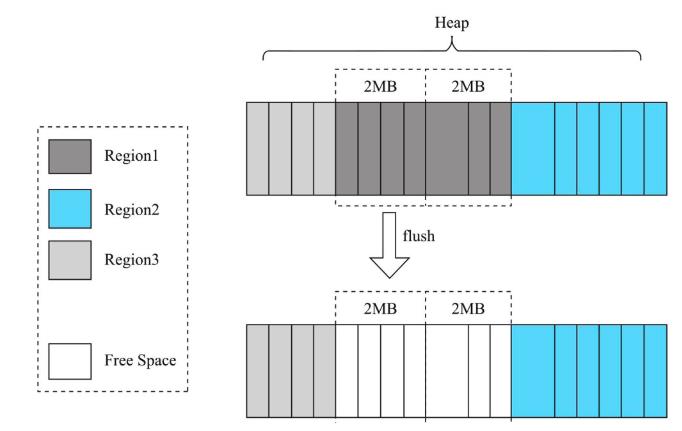
- 原因:MemStore本质上来说就是写缓存,RegionServer由多个Region组成,每个Region又根据列簇的不同包含多个MemStore,这些MemStore是共享内存的,这样不同Region的数据写入对应的MemStore,在JVM看来这些MemStore的数据是混合卸载Heap中的,所以MemStore数据落盘时会产生大量的内存碎片,如下图:
- 解决方案一:使用MSLAB管理方式:其实是借鉴了ThreadLocal内存管理方式,通过顺序话分配内存,内存数据分块等特性使得内存碎片更加粗粒度,改善Full GC;
- 每个MemStore实例化会得到一个MemStoreLAB对象;
- MemSToreLAB会申请一个2M大小的chunk数据,同时记录offset,出事offset为0;
- 当KeyValue插入MemStore后,将该KeyValue写入扫Chunk数组中,并移动offset;
- 当前chunk写满,申请一个新的chunk继续写入;
- 解决方案二:MemStore Chunk Pool主要是为了降低内存中新生代的内存回收,将Chunk数组放在Chunk Pool中管理,循环使用Chunk数组,步骤如下:
- 系统创建一个Chunk Pool管理所有未被引用的Chunk,这些Chunk不会被垃圾回收;
- 如果一个Chunk没有再被引用,则将其放进Chunk pool中;
- 如果Chunk Pool数量达到最大值,则不再接收新的Chunk Pool;
- MemStore需要一个新的Chunk,先从Chunk Pool申请,如果申请步到,则在内存Eden重建Chunk;
- 原因:MemStore本质上来说就是写缓存,RegionServer由多个Region组成,每个Region又根据列簇的不同包含多个MemStore,这些MemStore是共享内存的,这样不同Region的数据写入对应的MemStore,在JVM看来这些MemStore的数据是混合卸载Heap中的,所以MemStore数据落盘时会产生大量的内存碎片,如下图:
- MemStore参数:
- hbase.hregion.memstore.mslab.chunksize:配置Chunk大小;
- hbase.hregion.memstore.chunkpool.maxsize:分配给ChunkPool的内存空间占MemStore内存的百分比;
- MemStore概述:
-
HFile:在HDFS文件上,存储了Hbase实际的数据;
- HFile概述:
- MemStore中的数据落盘后,会形成一个文件落盘到HDFS上,这个文件就叫HFile;
- HFile逻辑结构:
- Scanned-Block:顺序扫描时Scanned所有文件都会被读取,包含Data-Block(存储数据);Leaf-Index-Block(存储叶子索引);Bloom-Block(存储布隆过滤器相关数据);
- Non-Scanned-Block:顺序扫描不会被读取,存储MetaBlock和Intermediate Level Data Index Blocks两部分;
- Load-on-open:在RegionServer打开Hfile时直接加载到内存,包括FileInfo、布隆过滤器MetaBlock、Root Data Index和Meta IndexBlock
- Trailer:RegionServer打开HFile时即加载,包含Hbase的版本信息,Load-on-open的偏移位置和大小,以便依次将Load-on-open加载到内存;
- HFile物理结构:
- 所有的Block都时一样的物理结构;
- 可以在创建列簇的时候指定大小(blocksize=> ‘65535’),默认64k,大的Block有利于顺序查询,小的Block有利于随机查询;
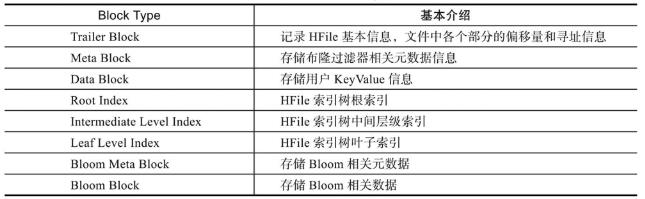
- HBlock主要分为两部分,BlockHeader和BlockData,其中BlockHeader主要存储Block元数据信息,BlockData存储具体数据,BlockHead含有BlockType字段,BlockType意义如下:
- HFile的基础Block:
- Trailer Block:记录HFile的版本信息,各部分的偏移值和寻址信息;
- Data Block:Hbase读取加载到内存的最小单位,主要存储用户的Key-Value信息;
- KeyValue由四部分组成:KeyLength,ValueLength,Key,Value;
- Key由五部分组成:rowkey,Column Family、Column Qualif ier,timeStimp,KeyType,KeyType有四种类型,分别是Put、Delete、DeleteColumn和DeleteFamily。
- HFile中Bloom过滤器相关的Block:
- Bloom本质:一个由0和1组成的数组,每一个KeValue会根据Hash算法将该数组部分位置为1,Bloom过滤器得到的结论是,该RowKey是不是可能在该HFile上;
- 整个Hfile仅有一个Bloom Index Block数据块,存储在load-on-open模块;
- 一次get请求通过Bloom过滤器查找需要以下三项操作:
- 根据查找key在Bloom Index Block中进行二分查找,直到找到对应的Bloom Index entry;
- 根据Bloom Index entry加载对应的Bloom位数组;
- 对key进行Hash映射,判断映射的位数在位数组里是否都为1,是的话则证明该key可能在在该HFile中,加载该位数组对应的DataBlock到内存中进行查询;
- HFile中Bloom过滤器相关的Block:
- 分类:single-level(单级索引)和multi-level(多级索引),每个索引字段由三个元素组成:BlockKey(用于二分查找),BlockSize+Block Offset(用于一次将索引Block加载到内存中);
- Root Index Block:索引树根节点索引,存储在load-on-open中;
- NonRoot Index Block:中间层节点和叶子节点;
- HFile文件查看工具:
- $HBASE_HOME/bin/hbase hfile:
- -m参数可以打印出该文件对应的基本元数据,可以通过avgKeyLen和avgValueLen两个参数调整DataBlock的大小;
- HFile的f irstKey和lastKey两个参数,可以在scan是帮助过滤HFile;
- HFile概述:
-
BlockCache:读缓存,Hbase会将Hfile中的dataBlock加载出来放到BlockCache中,提升读效率。
- BlockCache概述:
- 作用:提升数据库性能,将热点数据存储在内存中,避免昂贵的IO开销;
- 步骤:客户端读取某个Block时,会首先判断它是否在BlockCache中,如果存在则直接读取,否则从HFile加载出来放到BlockCache中,后续同一请求或者临近数据查询都可以省略了IO过程,直接从内存中读取;()
- BlockCache主要用来缓存Block,dataBlock是Hbase中数据读取的最小单位;
- BlockCache是RegionServer级别的,在RegionServer启动时完成Block Cache的初始化工作,目前由三种Block Cache方案:LRUBlockCache(常用),SlabCache(缺点太多不咋用),BucketCache(比较好用);
- LRUBlockCache概述:
- 完全交给JVM管理内存,内部结构时ConCurrentHashMap,当BlockCache中的Block超过阈值启动淘汰机制,淘汰算法时严格的LRU算法;
- 缓存分层策略:
- BlockCahce分为三层:single-access,mulit-access,in-memory,比例为25%,50%,25%;
- Block刚加载出来放在single-access,时间段内被多次被访问则移动到multi-access,in-memory表示数据可以常驻内存,一般存储访问频繁、量小的数据,比如元数据,客户在创建列簇时也可以为列簇设置in-memory=true;
- in-memory=true并不代表该数据就在内存总,它需要经过一次从磁盘加载到内存中的过程,并且在RegionServer运行时一直没有因为LRU算法被移除;
- 系统会对着三层设置三个queue,每个层级根据最少使用算法对Block在队列中进行排序,然后根据LRU算法进行淘汰;
- 缺点:使用了CMS垃圾淘汰算法,此算法使用标记-清除算法,会累计大量的内存碎片,当内存碎片达到一定数量,就会引起full Gc,严重影响性能;
- SlabCache概述:
- 主要解决CMS带来的FUll GC问题;
- 思想:
- SlabCache使用NIO实现堆外内存,不再使用JVM管理内存;
- 系统在初始化时会分配两个缓冲区,各占BlockCache的80%和20%,前者把内存分成64KB的缓存区,后者分为128KB的小缓存区,用来缓存对应大小的BlockCahce;
- 使用LRU清除 小缓存区;
- 缺点:
- 线上环境,可以根据不同Store设置不同的DataBlock大小,若某个DataBlock设置太大就不能使用SlabBlock模式的BlockCache了;
- 固定大小内存设置使得内存使用率太低了;
- 线上环境将LRUBlockCache和SlabCache一起使用,查询时先从LRUBlockCache中读取,读不到从SlabCache中读,读到了就将其移动到LRUBlockCache中,这样也会因为CMS引起FUllGC,还引入了SlabCache的效率不好的问题,线上测试效果不理想,该方案被废弃;
- BucketCache概述:
- 三种模式:
- heap:从JVM中申请内存给BlockCache用;
- offheap:从堆外内存中申请内存用;
- f ile:从存储介质中申请内存用(SSD);
- 思想:
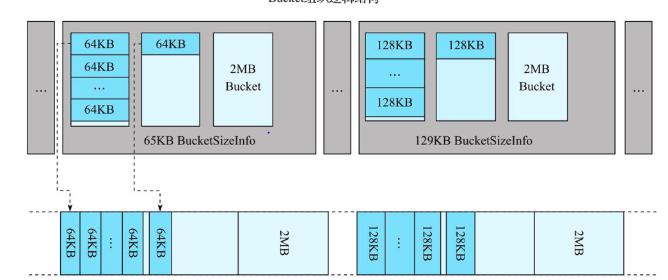
- 实际使用者搭配LRUBlockCache一起,BlockCache存储IndexBlock和BloomBlock,BucketCache存储DataBlock;
- 借鉴了Slab模式,Hbase启动时会向内存申请大量Bucket,每个Bucket2M,每个Bucket有一个baseoffset变量和一个size标签,size标签表示这个Bucket可以存放的Block大小;
- 根据size标签对Bucket进行分类,默认标签有5k,9k……513K,为每种标签分配一个Bucket,最后剩余内存分给最大的Bucket;
- Bucket可以动态调整,如果64K的Bucket用完了,可以从其他size中完全空闲的bucket转成65的Bucket,但是每种类型的bucket必须留下一个;
- 三种模式:
- BlockCache概述:
- BucketCache中Block缓存写入、读取流程:
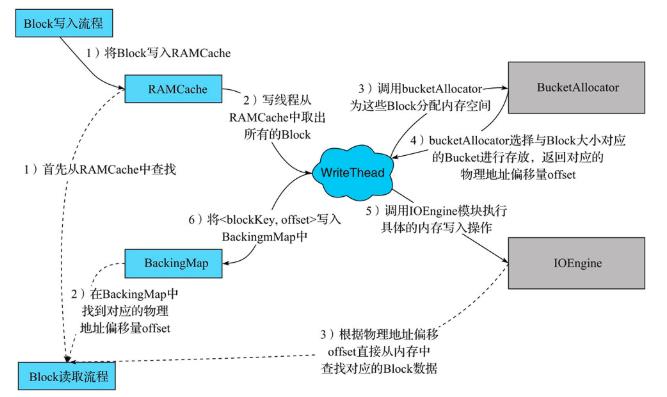
- RAMCache是一个存储blockKey和Block对应关系的HashMap
- WriteThead是整个Block写入的中心枢纽,主要负责异步地将Block写入到内存空间
- BucketAllocator主要实现对Bucket的组织管理,为Block分配内存空间
- IOEngine是具体的内存管理模块,将Block数据写入对应地址的内存空间
- BackingMap也是一个HashMap,用来存储blockKey与对应物理内存偏移量的映射关系,并且根据blockKey定位具体的Block
- Block缓存写入流程如下:
- 将Block写入RAMCache;
- WriteThead从RAMCache中取出所有的Block执行异步写入 ;
- 调用bucketAllocator为这些Block分配内存空间;
- BucketAllocator会选择Bucke,返回对应的物理地址偏移量offset;
- WriteThead将Block以及分配好的物理地址偏移量传给IOEngine模块,执行具体的内存写入操作
- 写入成功后,将blockKey与对应物理内存偏移量的映射关系写入BackingMap中;
- Block缓存读取流程如下:
- 首先从RAMCache中查;
- 如果在RAMCache中没有找到,再根据blockKey在bucket中查询;
- 根据物理偏移地址offset直接从内存中查找对应的Block数据;
- RAMCache的作用:
- 将Block数据写入到Bucket中需要一定的时间,如果没有RAMCache,那么在这一段时间内,该数据的Block Cache不能用,而且BlockCache还可能是使用堆外内存/SSD存储实现的,可能会更加耗时,根据热点数据的特点,新加载进来的数据更容易称为热点数据,所以要保证数据加载到内存就能以Block Cache的方式使用;
- 将Block数据写入到Bucket中需要一定的时间,如果没有RAMCache,那么在这一段时间内,该数据的Block Cache不能用,而且BlockCache还可能是使用堆外内存/SSD存储实现的,可能会更加耗时,根据热点数据的特点,新加载进来的数据更容易称为热点数据,所以要保证数据加载到内存就能以Block Cache的方式使用;
- BucketCache配置:
- heap模式:

- offheap模式的配置

- f ile模式:

- heap模式:
4.解释下Hbase实时查询的原理?
- Hbase实时查询的原理:MemStore,BlockCache;
- MemStore:Hbase在数据写入时,会先将数据写入到内存中的MemStore中,查询时也是先从MemStore中查询,然后才查询HFile,由于实时场景中要查询的实时数据都是新写入的数据,所以很多查询都命中在了MemStore上(即内存查询),故实现了实时查询;
- BlockCache:Hbase从HFile中加载的数据会存储在内存中的BlockCache中作为一个读缓存使用,可以节省很多IO消耗,提高读效率;
- Hbase读取流程概述:
- Hbase一次查询可能涉及多个缓存,多个Region,多个数据存储文件;
- Hbase读取数据时,需要过滤版本,以及已删除的数据;
- 步骤:
- Client-Server交互逻辑;
- Server端的Scan框架;
- 过滤不符合查询条件的HFile;
- 从HFile中读取待查找Key。
- Client-Server端交互:
- 步骤:
- 客户端根据本地缓存获得目标RegionServer地址;
- 如本地缓存缓存地址有误或者无相关缓存,则去zookeeper中获得元数据表所在的RegionServer;
- 向RegionServer发送请求得到Mate:data;
- 将Mate:data缓存到本地,然后根据ate:data获得目标RegionServer;
- 向目标RegionServer发送读请求,得到数据;
- 注意事项
-
RPC请求设置:
不可以为Scan操作设计一个RPC请求,否则会引发:- 1.短时间内大量数据传输会导致网络内存等系统资源被大量占用,影响集群其他业务;
- 2.传递给客户端的数据量过大,超过客户端内存会导致OOM;
正确设置
- 将一个大的Scan拆分为多个RPC请求,每个RPC请求是一次next请求;
- 单次请求数量由cacheing决定;
- 可通过setBatch设置每次返回多少列;
- setMaxResultSize可设置每次返回的数据大小(不是数量条数),默认为2G;
-
- 步骤:
- Server端的Scan体系:
- Region选择:
- 根据rowkey的range和Region的起始区间[startKey, stopKey]进行切分,得到要扫描的Region列表;
- 并发的向Region发送读取请求;
- Region收到请求后,1.构建scanner 迭代体系,2.然后执行next函数获取KeyValue,并对其进行条件过滤;
- Scanner迭代体系:
- Scanned分为RegionScanner,StoreScanner,MemStoreScanner,StoreFileScanner;
- RegionScanner以及StoreScanner并不负责实际查找操作,它们更多地承担组织调度任务,负责KeyValue最终查找操作的是StoreFileScanner和MemStoreScanner
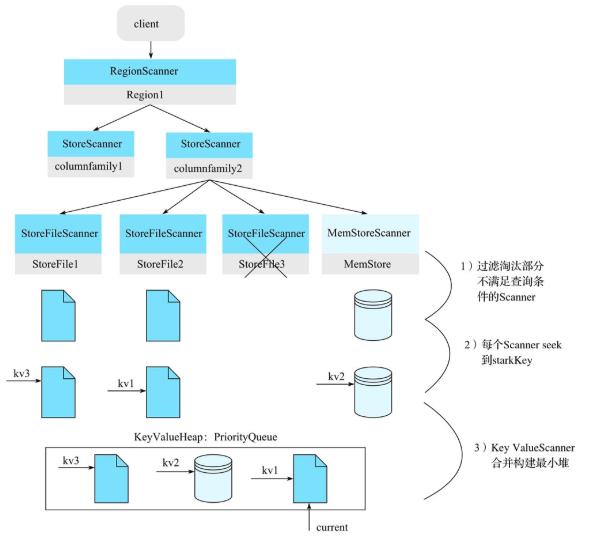
- 过滤不符合查询条件的Scanner:过滤策略有Rowkey Range,Time Region,布隆过滤器过滤;
- 每个Scanner seek到startKey:扫描起始点startKey。
- KeyValueScanner合并构建最小堆 :将该Store中的所有StoreFileScanner和MemStoreScanner合并形成一个heap(最小堆),然后顺序输出。
- 执行next函数获取KeyValue并对其进行条件过滤:
检查第一步获得的KeyValue是否满足用户设定的TimeRange请求,版本号条件以及Filter条件等等;- 检查该KeyValue的Type是否属于Deleted/DeletedColumn/DeletedFamily,若是,则跳过;
- 检查该Key Value的时间戳范围;
- 检查该KeyValue是否满足设置好的filter过滤;
- 检查得到的KeyValue是否满足用户查询设置的版本数;
- Region选择:
- 过滤不符合条件的HFile:
- 根据KeyRange过滤:HFile的数据按照顺序排列,所以从元数据中得到文件起始key范围[ f irstkey,lastkey ],与查询范围做交集,若无相交区域可过滤;
- 根据TimeRange过滤:HFile的元数据有TimeRange属性[miniTimestamp, maxTimestamp ],与TimeRange做交集,若无相交区域可过滤;
- 根据布隆过滤器进行过滤:可以根据bloom过滤器判断该HFile中是否有需要的DataBlock;
- 从HFile中查找Key:
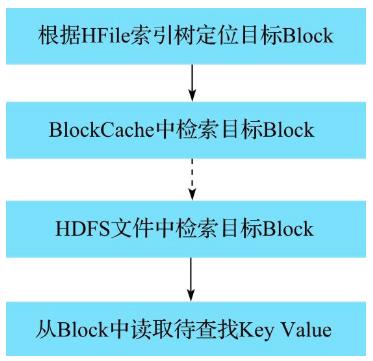
- 根据Hfile中的Index Block定位到目标Block:
- 根据load-on-open得到Root Index Block(BlockKey、Block Offset、BlockDataSize);
- 根据二分查找定位到IndexEntry,然后根据Block Offset、BlockDataSize加载到对应的DataBlock到内存中(不一定会加载,如果BlockCache有的话);
- 遍历BlockCache得到KeyValue;
- BlockCache中检索KeyValue:
- DataBlock在内存中以ConCurrentHashMap形式存在;
- Key为BlockKey,HFile名称+Block在Hfile中的偏移位置;
- Value为Block内容;
- 在从HDFS文件系统加载文件前,会先在BlockCache中寻找其是否已经被加载到读缓存中。
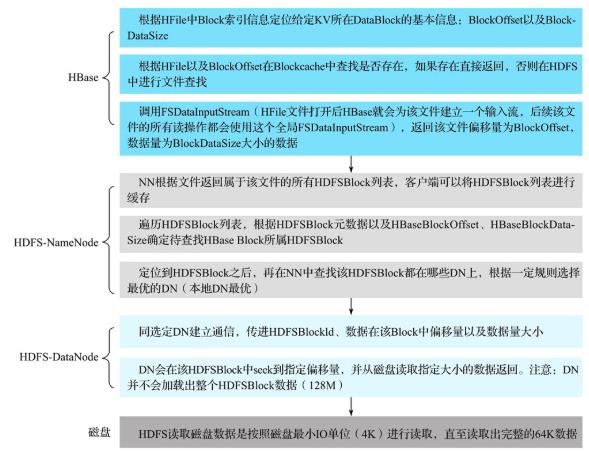
- HDFS中检索KeyValue:
- NameNode工作:
1.找到属于这个HFile的所有HDFSBlock列表,确认待查找数据在哪个HDFSBlock上;
2.确认定位到的HDFSBlock在哪些DataNode上,选择一个最优DataNode返回给客户端;
- NameNode工作:
- 根据Hfile中的Index Block定位到目标Block:
5.描述下Hbase rowkey的设计原则,rowkey的长度原则?
- Hbase的存储形式:
- 内部使用KeyValue形式存储,key为rowkey,family,column,timestamp;
- 在region中顺序排列;
- rowkey设计原则:
- 长度原则:越短越好,最长不要超过64k,太长一个是影响HFile存储效率,一个影响MemStore的存储效率;
- 唯一原则:要保证rowkey的唯一性;
- 散列原则:把经常一起用的rowkey金量放在一个region上,提升检索效率,但要主意热点问题;
- 其他原则:对于常用的rowkey,列数尽量不要设置过多;
- rowkey引发的热点问题的解决方案:
- 加盐:在rowkey最前面加上无关信息,根据冗余信息把数据分散到不同的region中,缺点是无形中增加了rowkey的长度;
- 字段交换,提升权重:例如将rowkey反转,调整信息字段的顺序,缺点是:对于单个字段不能使用,弱者无论怎么调整都无法避免热点问题的rowkey不能使用;
- 随机键:把rowkey进行hash化,分配到不同的RegionServer上。
- 性能排行:
- 顺序键 -> 使用加盐键 -> 提升字段键 -> 随机键
6.描述Hbase中scan和get功能以及实现的异同?
- get:按照指定RowKey获取唯一一条记录;
- Scan:按照指定条件获取一批记录,可以通过setCaching和setBatch方法提高速度,通过setStartRow和seyEndRow限定范围,使用setFilter方法添加过滤器;
- get是scan的特殊形式;
7.详细描述Hbase中一个cell的结构?
- cell:Hbase的存储单元,Key:由(rowkey,family,column,timestamp,type),Value及存储的数据。
8.简述Hbase中compact的用途是什么,什么时候触发,分为那两种,有什么区别,有哪些相关配置参数?
- Compact概述:
- 用途:LSM体系架构中,每次flush得到的HFile文件都特别小,如果小文件过多的话就会影响查询效率,compaction会把小的HFile合并成大的HFile,提升读效率(一个Region中每个HFile的文件是存储在一起的,每次检索HFile时需要从NameNode中得到对应的DataNode的位置,若HFile文件太小的话,大量小文件会消耗NameNode资源,也会浪费查询时间);
- 简述:从一个Region的Store中选择部分HFile文件进行合并,先从这些待合并文件中读出keyValue,然后用最小堆的方式合并,从小到大排序后写入一个新的文件中;
- 分类:Major Compaction,Minor Compaction;
- Minor Compaction:从Store中选择小的,相邻的HFile,将他们合并成一个大的HFile;
- Major Compaction:将整个Store中的HFile进行合并,得到一个大的HFile,一般来说持续时间长,容易消耗大量系统资源,对上层业务由较大影响,所以一般关闭自动触发,由用户设置在低峰时段手动触发;
- 核心作用:
- 合并小文件,减少文件数:降低随机读延迟;
- 提高数据的本地率:Compaction合并小文件的同时会将落在远程DataNode上的数据读取出来重新写入大文件,合并后的大文件在当前DataNode节点上有一个副本,因此可以提高数据的本地化率;
- 删除无用数据:将超过版本限制的,或者标记为deleted的数据清除;
- 副作用:Compaction操作重写文件会带来很大的带宽压力以及短时间IO压力;
- 总结:
- Compaction操作是所有LSM树结构数据库所特有的一种操作,它的核心操作是批量将大量小文件合并成大文件用以提高读取性能;
- Compaction是有副作用的,它在一定程度上消耗系统资源,进而影响上层业务的读取响应;
- 知识点:基本工作原理,分类,在LSM体系中的核心作用以及副作用,Compaction触发机制;
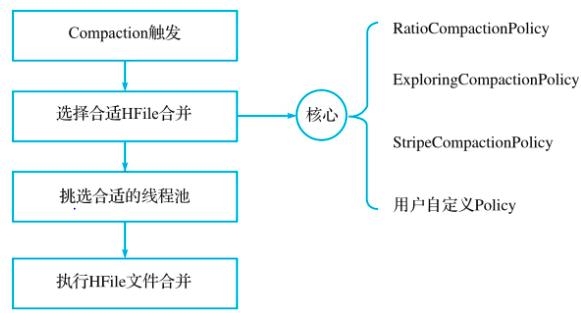
- Compact基本流程:
- Compaction触发:只有在特定条件下才能触发,例如MemStore大小超过阈值;
- 选择合适的HFile合并:根据算法选择待合并HFile文件,最佳选择时IO负载重,但是文件大小又小的文件;
- 挑选合适的线程池:根据挑选的HFile文件,HBase会分配不同的线程池进行处理;
- 执行HFile文件合并:从小文件中独处KeyValue写到一个大的HFile文件中;
- 触发时机:
- 常见三种:MemStore的flush操作,后台线程周期性检查,手动compaction;
- MemStore 的flush:每次flush完就会对当前store的Hfile文件个数进行判断,若超过阈值(hbase.hstore.compactionThreshold),则进行compaction操作;
- 后台线程周期性检查:RegionServer会在后台启动一个线程,定期检查对应的Store是否需要执行Compaction,它会检查store的文件个数(触发Monir Compaction),也检查留存期,如果当前Store中HFile的最早更新时间早于某个值mcTime,就会触发Major Compaction;
- 手动触发:手动触发Compaction一般都是为了执行Major Compaction,原因1:客户关闭了Major compaction,为了避免影响上层业务,要在低峰时段手动进行Compaction;原因2:用户执行了alter操作后夕阳立刻生效;原因2:Hbase管理员发现硬盘空间不足,向删除deleted数据释放空间;
- 待合并的HFile文件选择策略:
- 选择标准:选择的待合并HFile文件集合承载了大量IO请求但是文件本身很小;
- 前置处理:1.排除正在进行compaction的文件,以及比这些文件更新的HFile文件;2.排除过大的文件;
- 判断文件是否符合Major Compaction标准:
- 用户是否强制执行Major Compaction;
- 长时间没有执行Major Compaction;
- Store中是否含有reference文件(Region Spilt后标记的);
- 留存期清理,如果当前Store中HFile的最早更新时间早于某个值mcTime。
- 判断文件是否符合monir Compaction标准:
- RatioBasedCompactionPolicy:
从老到新扫描store中的文件,满足以下任一条件停止:- 当前文件大小小于阈值(store中所有文件大小*Retio);
- 当前所剩候选文件数<=hbase.store.compaction.min;
扫描停止后,候选文件即为当前扫描停止文件,以及所有比它更新的文件;
- ExploringCompactionPolicy:
- 类似于Ratio策略,但是Retio是找到一个文件集即停止,Exploring会找到多个,然后选一个最优解进行minor compaction;
- RatioBasedCompactionPolicy:
- 挑选合适的执行线程池:
- 分类:largeCompactions、smallCompactions以及splits等。
- splits线程池:负责处理所有的split请求;
- largeCompactions和smallCompaction:根据要compaction的总文件大小来分配;
- HFile文件合并:
- 从待合并的HFile文件中独处KeyValue,进行归并排序处理,然后将得到的HFile文件写入到./tmp目录中;
- 将./tmp目录中的compaction文件移动到对应的Store目录中;
- 将Compaction的输入文件路径和输出文件路径封装成KeyValue,写道HLog中,然后强制Sync;
- 将对应Store的输入HFile文件删除;
- 容错:
- 2步骤之前出错,本次compaction失败,仅多了一份冗余文件;
- 3步骤出错,本次compaction失败,仅多了一份冗余文件;
- 4步骤出错,本次compaction成功,重新打开region是进行输入HFile的删除;
- Compaction相关注意事项:
- Limit Compaction Speed:通过感知Compaction的压力情况自动调节系统的Compaction吞吐量.
- 设置上下限参数,Hbase实际compaction吞吐量为lower+(higher - lower) * ratio,ratio会根据当前需要compaction的数量进行浮动,数量越多,retio越小;
- 如果当前Store中HFile的数量太多超过阈值,那么设置参数完全失效,所有写请求被阻塞,Hbase优先全力进行Compaction;
- Compaction BandWidth Limit:类似Limit Compaction Speed,如果消耗带宽超过阈值,则强制sleepcompaction线程一段时间:
- compactBwLimit :一次Compaction的最大带宽使用量;
- numOfFilesDisableCompactLimit:Store中HFile数量超过该设定值,带宽限制就会失效。
- Limit Compaction Speed:通过感知Compaction的压力情况自动调节系统的Compaction吞吐量.
9.Hbase实现了哪两种compaction方式,minor和major这两种compaction方式有什么区别?
- ComPaction方式:MajorCompaction,Minor Compaction;
- 区别:Minor Compaction仅合并Store中部分的Hfile文件,Major合并一个Store中的文件,且reference文件只会在Major Compaction中删除;
10.简述Hbase filter的实现原理是什么,结合实际项目经验,写几个使用filter的场景?
- Hbase为筛选数据提供了一组过滤器,通过这个过滤器可以在HBase中的多个维度(行列版本)上进行数据筛选操作,即数据筛选器最终粒度可以细化到具体的一个存储单元格中;
- Hbase的filter是通过scan设置的,例如PredixFilter.
11.Hbase内部机制?
- 存储使用LSM架构;
- 数据统一以追加的方式写入,删除,修改和增加都是一样的写操作,只是会在对应数据的key上做个标记(例如deleted);
- 数据清理,更新等操作通过compaction操作进行;
- 写步骤为:HLog ->MemStore -> HFile;
- HLog:HDFS文件系统中,顺序写;
- MemStore:内存中,ConCurrentSkipList结构,读写删除复杂度都是logN,且线程安全,用于对Hbase中的数据进行排序,超过阈值触发flush操作,落盘得到HFile文件。
- HFile文件:存储在HFDS中,顺序写,文件内容根据Rowkey有序排列,内部有索引,布隆过滤器;
- Region根据Rowkey的范围划分,Hstore对应列簇
- 包含Master,RegionServer,Zookeeper;Master主要负责表创建删除,元数据的管理,zookeeper负责数据读写中索引到对应的RegionServer以及集群元数据信息的一致性,RegionServer负责数据读写以及region管理,region包含一个BlockCache,一个至多个HLog,一个至多个HStore,BlockCache是写缓存,用于提升数据读取效率(优化IO耗时),HLog做故障恢复和集群复制,HStore对应Hbase表中的列簇,HStore中含有MemStore和HFile,MemStore是写缓存,用于对数据进行排序,将随机写转换为顺序写,数据读取时也会优先读取MemStore,HFile文件存储的实际的KeyValue数据,数据存储在HDFS文件系统中,HFile文件时按照Rowkey顺序存储的。
12.Hbase宕机如何处理?
- Hbase常见故障分析:
- Master进程:主要负责集群的管理调度,在实际生产线上没有较大的压力,发生软件层面的故障的概率非常低;
- RegionServer进程:主要负责用户的读写服务,内部含有很多缓存组件以及与HDFS交互的组件,实际生产线上会有很大的压力,造成的软件层面上的故障非常多。
- RegionServer会出现的故障:
- Full GC:长时间的Full GC是导致RegionServer宕机的最主要原因,HBase对于Java堆内内存管理的不完善,HBase未合理使用堆外内存,JVM启动参数设置不合理,业务写入或读取吞吐量太大,写入读取字段太大等等;
- HDFS文件系统损坏:Hbase是基于HDFS文件系统进行读写的,HDFS文件系统损坏会导致Hbase服务出现异常;
- RegionServer机器宕机:主要发生在虚拟云上,网络不稳定也属于这种;
- HMaster故障恢复机制:
- Master主要负责集群负载均衡和读写调度,负载并不高;
- Master热备主要依靠Zookeeper实现;
- 步骤:
- 集群会启动至少两个Master进程,然后两个Master抢占在Zookeeper上注册Master节点,注册成功的进程为集群提供Master服务,失败的在Zookeeper上注册成Master备机;
- Master备机在Zookeeper的Master节点上注册Watcher时间,Master因故障导致宕机时,Zookeeper上的Master节点就会因为临时会话断掉而被删除,触发watch时间,备机Master收到Watch事件后,重新进行Master节点注册抢占,抢占成功的Master进程为集群中新的Master;
- 新的Master从Zookeeper上同步完元数据后,开始为集群提供服务;
- 职责:
- Master负责整个系统的元数据管理任务,包括Zookeeper和Mate表中的元数据,并根据元数据决定集群是否需要负载均衡;
- Master会响应用户的各种管理命令,包括创建删除修改表,move,merge Region等命令;
- RegionServer故障恢复原理:
- 概述:一旦RegionServer宕机,Hbase集群会立刻检测到这种状况,并将宕机的RegionServer上的Region分配到运行正常的RegionServer上,并通过HLog回放数据,进行丢失数据恢复,整个过程都是自动完成的,不需要人工介入。
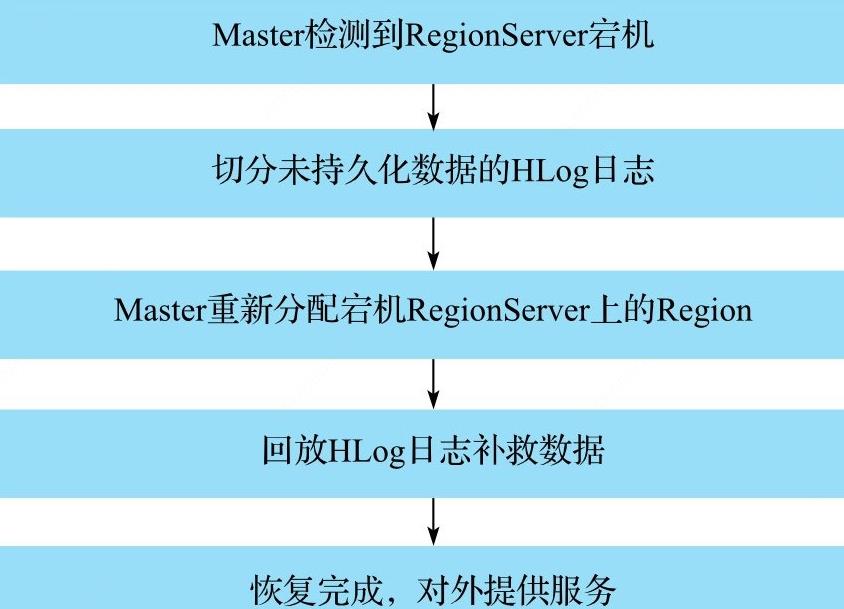
- 宕机RegionServer检测:通过Zookeeper实现,正常情况下,RegionServe会周期向Zookeeper发送心跳,一旦发生宕机,心跳就会停止,超过一段时间没有心跳给Zookeeper,Zookeeper就认为该RegionServer离线,并将该消息通知给Master。(其实就每台正常提供服务的RegionServer都会在Zookeeper上注册一个临时节点,然后每隔一段时间,RegionServer就会向Zookeeper发送心跳信息表示会话存在,若RegionServer宕机,Zookeeper长时间收不到心跳信息,就会移除临时节点,Master在该临时节点上注册了Watcher事件,一旦临时节点被移除,就触发Watcher事件,Master开始调度RegionServer宕机恢复机制);
- 切分未持久化的HLog日志:HLog中的日志是混合存储的,所以需要将其按照Region切分开,然后将同一个Region的日志聚合在一起,便于后续按照Region进行数据恢复;
- Master重新分配宕机的RegionServer上的Region:RegionServer宕机后,该RegionServer上所有的Region都是不可用状态,所有路由到该RegionServer上的请求都会返回错误,所以需要将这些Region交给正常工作的RegionServer管理,Master会将这些Region负载均衡的分配到其他RegionServer上;此时这些Region并没有进行HLog数据回放,并未上线,不能为外界提供查询服务;
- 回放HLog日志补救数据:第三步的Region被分配给其他的RegionServer进行管理,对这些分配好的Region,根据第二步切分好的Region进行回放,即可补回丢失的数据。
- 完成服务:数据补救完成,可以对外提供服务。
- 概述:一旦RegionServer宕机,Hbase集群会立刻检测到这种状况,并将宕机的RegionServer上的Region分配到运行正常的RegionServer上,并通过HLog回放数据,进行丢失数据恢复,整个过程都是自动完成的,不需要人工介入。
- HLog切分原则:
- LogSplitting策略:
- 对HLog文件进行Rename:为了防止Zookeeper认为RegionServer宕机,但RegionServer还持续向外界提供服务,导致数据不一致的情况;
- 读HLog数据到Buffle中:Master会启动一
以上是关于Hbase面试的主要内容,如果未能解决你的问题,请参考以下文章
- LogSplitting策略: