HBase原理总结
Posted 北邮郭大宝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase原理总结相关的知识,希望对你有一定的参考价值。
在总结Spark读写HBase的同时,也顺便回顾了一下HBase的原理,同样做个简单的记录。事实上,相关的总结网上超级多,写的已经很到位了。本文一些内容会直接摘取相关参考资料,对原文作者表示感谢。
互联网的面试一般问的都比较细,尤其是简历里提到过的一些大数据组件,都会问问底层原理,体系结构,有什么好的设计思想,甚至是源码等。所以在能调用API实现开发功能之后,也需要花一点时间对组件的原理至少是了解。
我自己觉得学习大数据原理时最麻烦的就是逻辑概念和物理概念的交叉混叠。每一套组件里都涉及到很多新的专有名词,很容易就搞混弄乱。学习过程最重要的还是集中注意力,参考多份资料,仔细反复阅读,效果会好些。
1.HBase简介
HBase是Hadoop生态圈中的非关系型数据库,其最大的特点是面向列存储、可以实现在超大规模数据集上的实时读写和随机访问,可以说是对HDFS的有益补充。
传统的行存储是将完整的数据行存储在磁盘中,查询时会读取该行的所有数据列。但有些应用场景,只需要一小部分数据列,这种方式就很浪费IO。
列存储就是将同一个数据列的各个值存放在一起,也就是说插入某行数据时,该行的各个数据列的值会存放到不同的地方。好处就是需要某几列数据时,可以很方便读取。
2.HBase数据模型
HBase同数据库一样,也是以表的形式存储数据。表由行和列构成,若干列可以组成一个列族(Column family)。
2.1 HBase逻辑数据模型
基本概念:
RowKey:每条记录的“主键”
Column Family:列族,包含一个或者多个相关列,列族是表的Schema的一部分
Column:属于某一个columnfamily,即familyName:columnName,每条记录在同一个列族中可以由不同的列组成
Version Number:版本,类型为Long,默认值是系统时间戳timestamp,也可由用户自定义
Value:值
2.2 HBase物理数据模型
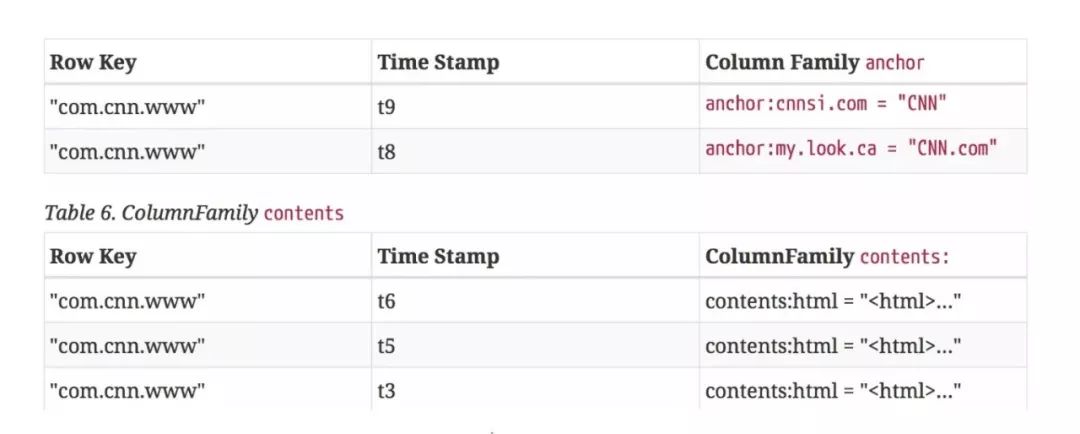
对于任意值,都是按照<key, columnfamily, columnname, timestamp, value>这种多级索引结构存储的
每个column family存储在HDFS上的一个单独文件中,空值不会被保存
HBase中通过RowKey和Column确定的一个存储单元称为Cell。每个Cell都保存着同一份数据的多个版本,默认情况下通过时间戳区分。
3.HBase体系架构
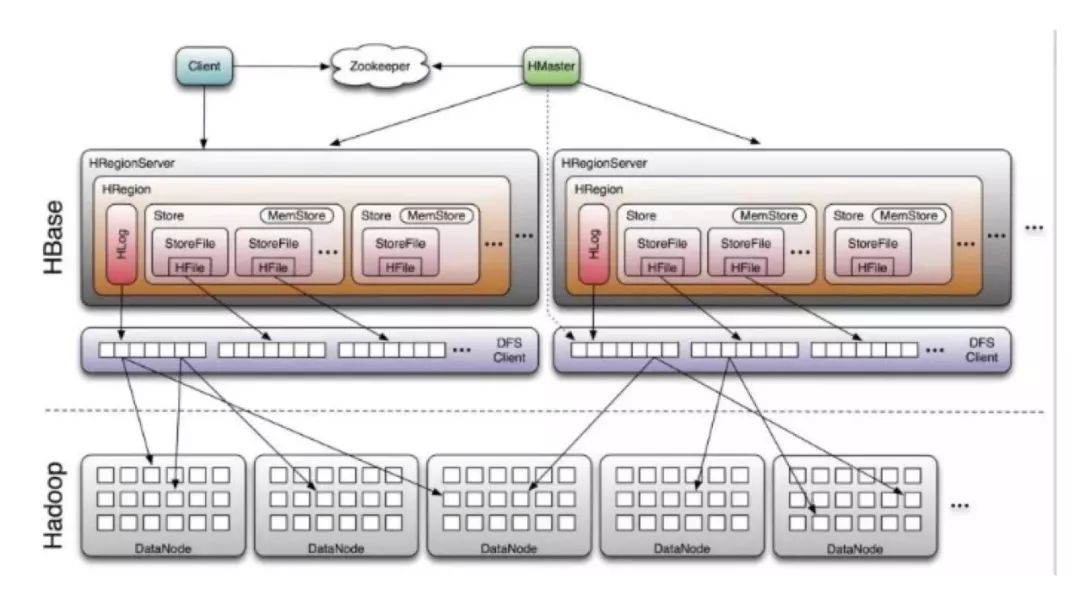
从架构上看,HBase由Client、Zookeeper、HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog等构成。
Client:访问HBase的接口,可以是HBase Shell、HBase-Client API等
Master:协调多个Region Server,侦测各个RegionServer之间的状态,并平衡RegionServer之间的负载,分配Region给RegionServer。
Zookeeper:维护HBase集群,Master与RegionServers启动时会向Zookeeper注册。集群内可以有多个Master,但是ZK保证只有一个对外提供服务,其他做Stand by,出现宕机有相应的选举机制选出新Master
Region Server:对于一个RegionServer而言,其包括了多个Region。RegionServer的作用是维护Master分配给他的region,以及实现读写IO操作。Client通过ZK寻址,最终也是直接连接RegionServer实现读取数据。
Region:table在行的方向上分隔为多个region,不同的region可以分别在不同的Region Server上。随着数据不断插入表,region不断增大,当region的某个列族达到一个阈值时就会分成两个新的region。
以上是宏观上HBase的体系架构,下面就是更细节的信息,主要是对Region的剖析。
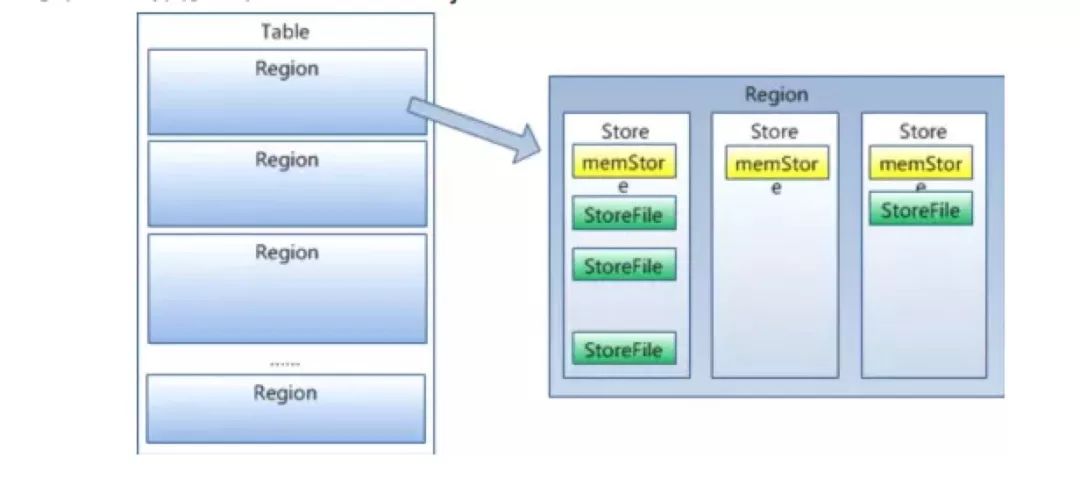
Store:每一个region由一个或多个store组成,一个store存放一个列族,如果有几个ColumnFamily,也就有几个Store。一个Store由一个memStore和0或者 多个StoreFile组成。HBase以store的大小来判断是否需要切分region。
MemStore:存放在内存中,保存修改的数据。当memStore的大小达到一个阀值(默认128MB)时,memStore会被flush到StoreFile。
StoreFile:MemStore快照后存储在StoreFile中,其底层是以HFile的格式保存。
HFile:HFile是Hadoop的二进制格式文件,就是按照一定的结构存储信息。HFile也是一个逻辑概念,最后落地是HDFS。HFile的存储格式有点像帧结构这种一大堆,就不展开了。
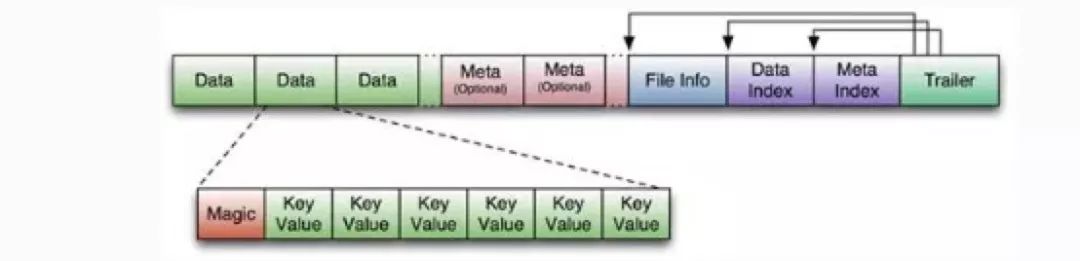
HLog(WAL log):WAL意为write ahead log,用来做灾难恢复使用。每个RegionServer中都会有一个HLog的实例,会将RegionServer的所有更新操作记录在HLog中,一旦regionServer宕机,就可以从log中进行恢复。HLog本身就是一个保障HA的机制,跟Hadoop的NameNode中的Edits的作用一样。
HBase基本体系架构就是这样,从宏观上理解:Client作为API接口,访问HBase;Master是整个集群的大脑,负责维护RegionServer;RegionServer管理若干个Region,并实现与Client的数据通信;Region是逻辑上分布式存储和负载均衡的最小单元;Zookeeper实现对集群的监护和HA。
从微观上理解Region,一个table会至少有一个Region,随着数据量的增大,Region实现分裂。Region内部由多个Store构成,每个Store存储一个列族。Store又由MemStore、StoreFile构成,MemStore内存写到一定程度后落磁盘到StoreFile。
4.Region寻址
HBase通过三级索引结果实现region的寻址。我们逆序描述这个设计的思路,HBase的所有数据region元数据被存储在.META.表中,但是随着region增多,显然.META.会越大越大,最终也会分裂成多个region;-ROOT-表实现定位.META.表的region的位置,保存.META.表中所有region的元数据。而且-ROOT-不会分裂,只有一个region。Zookeeper会记录-ROOT-表的位置信息。
我们在正序描述寻址过程,Client通过ZK找到-ROOT-表的位置,通过-ROOT-表查找到.META.的位置,再从.META.查找用户Region的位置。可以实现最多三次跳转就可以定位任意一个region的效果。为了加快访问速度,.META.表的所有Region全部保存在内存中。客户端会将查询过的位置信息缓存起来,且缓存不会主动失效。
5.HBase读写过程
这部分直接拿来了参考文章的截图,写的已经很简单清晰了。
5.1 读过程
Client访问ZK,通过-ROOT-和.META.表,查找到表的Region元数据,并找到相应的RegionServer
Client直接与RegionServer通信获取数据
Regionserver的内存分为MemStore和BlockCache两部分,MemStore主要用于写数据,BlockCache主要用于读数据。读请求先到MemStore中查数据,查不到就到BlockCache中查,再查不到就会到StoreFile上读,并把读的结果放入BlockCache
5.2 写过程
Client访问ZK,通过-ROOT-和.META.表,查找到表的Region元数据,并找到相应的RegionServer
数据被写入HLog和Region的MemStore中,当MemStore达到预设阈值后,Flush成一个StoreFile
StoreFile文件的不断增多,当其数量增长到一定阈值后,触发Compact合并操作,将多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除
StoreFile的大小超过一定阈值后,会把当前的Region分割为两个(Split),并由Hmaster分配到相应的HRegionServer,实现负载均衡
6.HBase的HA
Master的HA机制:Master为一主多备。当Master主节点宕机后,剩下的备节点通过ZK选举,产生新的主节点
RegionServer容错:当RegionServer损坏时,Master将该RegionServer上的Region重新分配到其他RegionServer上,失效服务器上“预写”日志由主服务器进行分割并派送给新的RegionServer
7.参考
https://www.cnblogs.com/csyuan/p/6543018.html
https://www.jianshu.com/p/20aff7d85e95
https://blog.csdn.net/wypersist/article/details/80115123
以上是关于HBase原理总结的主要内容,如果未能解决你的问题,请参考以下文章
Hbase框架原理及相关的知识点理解Hbase访问MapReduceHbase访问Java APIHbase shell及Hbase性能优化总结