大数据(5b)HBase架构读写流程
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据(5b)HBase架构读写流程相关的知识,希望对你有一定的参考价值。
架构
简单架构图

每个Region Server有多个Region
每个Region有多个Store
每个Store有多个StoreFile
详细架构图
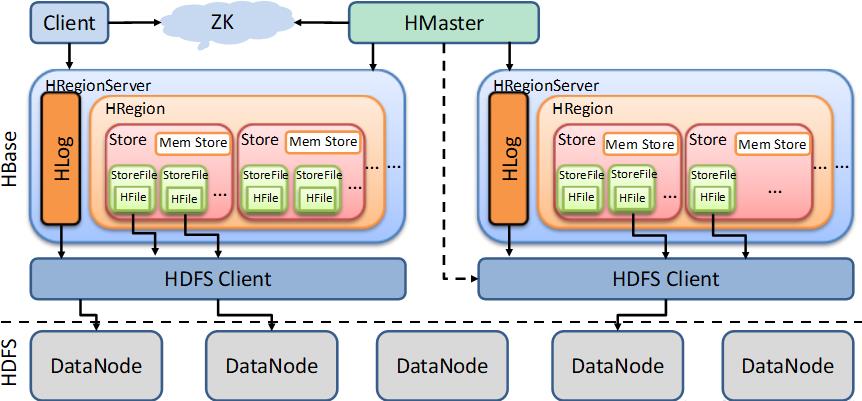
StoreFile保存实际数据的物理文件
StoreFile以HFile的形式存储在HDFS上
StoreFile中的数据是有序的
MemStore写缓存
HFile中的数据 要求有序
数据会先存MemStore并排序,然后等待时机刷写到HFile
每次刷写都会形成一个新的HFile
写数据流程
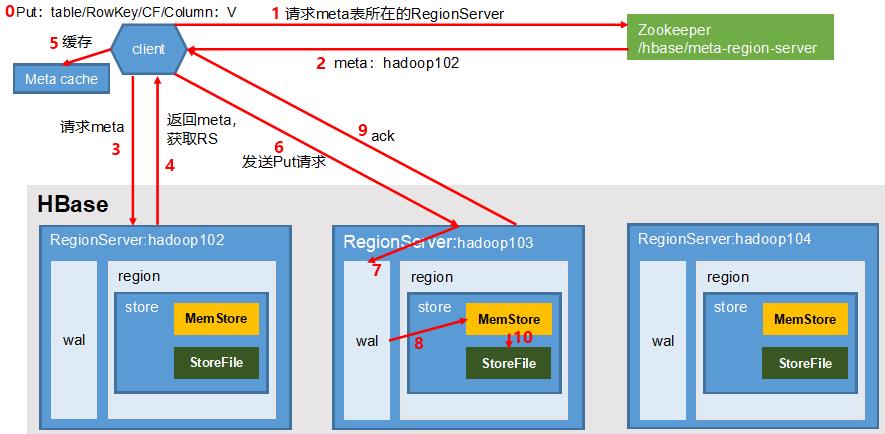
- PUT
- 客户端访问Zookeeper
- Zookeeper返回信息:hbase:meta表位于哪个RegionServer
- 访问对应的RegionServer,获取hbase:meta表
- 根据读请求的namespace:table/rowkey,查询出目标数据位于哪个RegionServer中的哪个Region中
- 将该table的region信息以及meta表的位置信息缓存在客户端的MetaCache,方便下次访问
- 与目标RegionServer进行通讯
- 将数据顺序写入(追加)到WAL
- 将数据写入对应的MemStore,数据会在MemStore进行排序
- 向客户端发送ack
- 等到MemStore的刷写时机后,将数据刷写到HFile
WAL
数据要经MemStore排序后才能刷写到HFile,内存中的数据容易丢失
对此,数据会先写到Write-Ahead LogFile,然后再写入MemStore
在系统故障的时,可通过该日志文件重建数据
MemStore Flush
| MemStore刷写时机 | 说明 |
|---|---|
| MemStore级别 | 某个MemStore的大小达到(默认128M) |
| HRegion级别 | Region中所有MemStore总大小达到(默认512M) |
| HRegionServer级别 | RegionServer中所有MemStore总大小达到(默认 j a v a _ h e a p × 0.4 × 0.95 java\\_heap \\times 0.4 \\times 0.95 java_heap×0.4×0.95) |
| HLog级别 | 当WAL文件的数量超过(默认32;新版已经废弃?) |
| 定期刷写 | (默认1小时) |
| 手动刷写 | flush 表名或flush 区域名分别对一个或多个Region进行刷写 |
读数据流程
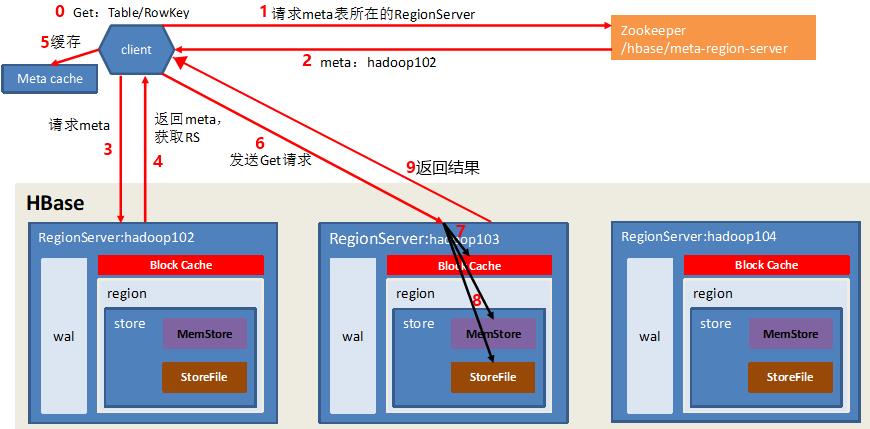
- GET:Table/RowKey
- 客户端访问Zookeeper
- Zookeeper返回信息:hbase:meta表位于哪个RegionServer
- 访问对应的RegionServer的hbase:meta表
- 根据读Table/RowKey查询出目标数据位于哪个RegionServer中的哪个Region中
- 将该table的region信息和meta表的位置信息缓存在客户端的MetaCache,以便下次访问
- 与目标RegionServer进行通讯
- 在BlockCache(读缓存)查询目标数据
- MemStore中查询目标数据,如果BlockCache中未查到相应数据则扫描对应的HFile文件,HFile中扫描到的数据块(默认64K)写入BlockCache,并将查到的 所有数据 进行合并
- 将合并后的最终结果返回给客户端
StoreFile Compaction(HBase文件合并精简)

| en | 🔉 | cn |
|---|---|---|
| compaction | kəmˈpækʃən | n. 压紧;精简;密封;凝结 |
| minor | ˈmaɪnər | adj. 未成年的;次要的;较小的;n. 未成年人;vi. 辅修 |
| major | ˈmeɪdʒər | adj. 主要的;重要的;主修的;n. [人类] 成年人;主修科目;vi. 主修 |
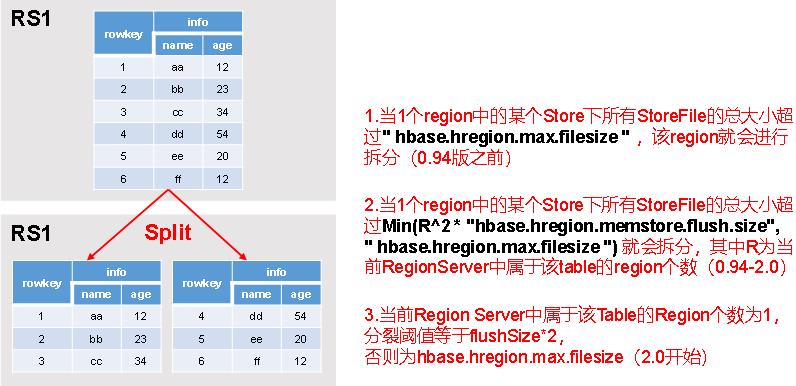
Region Split(Region切分机制)
以上是关于大数据(5b)HBase架构读写流程的主要内容,如果未能解决你的问题,请参考以下文章