图文详解 HBase 的读写流程
Posted Shockang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图文详解 HBase 的读写流程相关的知识,希望对你有一定的参考价值。
前言
本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见1000个问题搞定大数据技术体系
正文
请结合我的这篇博客来理解本文:
一篇文章搞懂 HBase 的内部原理
读操作
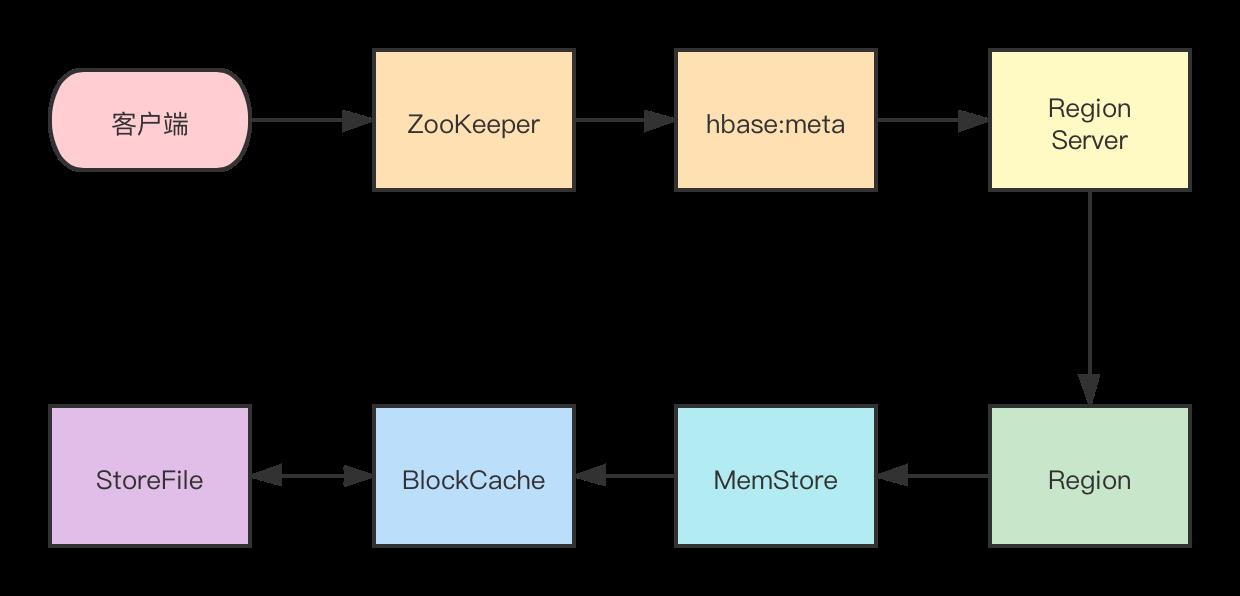
- 首先从 ZooKeeper 找到 meta 表的 region 位置,然后读取 hbase:meta 表中的数据, hbase:meta 表中存储了用户表的 region 信息
- 根据要查询的 namespace 、表名和 rowkey 信息,找到写入数据对应的 Region 信息
- 找到这个 Region 对应的 RegionServer ,然后发送请求
- 查找对应的 Region
- 先从 MemStore 查找数据,如果没有,再从 BlockCache 上读取
HBase 上 RegionServer 的内存分为两个部分一部分作为 MemStore ,主要用来写;。
另外一部分作为 BlockCache ,主要用于读数据;
- 如果 BlockCache 中也没有找到,再到 StoreFile(HFile) 上进行读取
从 StoreFile 中读取到数据之后,不是直接把结果数据返回给客户端,而是把数据先写入到 BlockCache 中,目的是为了加快后续的查询;然后在返回结果给客户端。
写操作
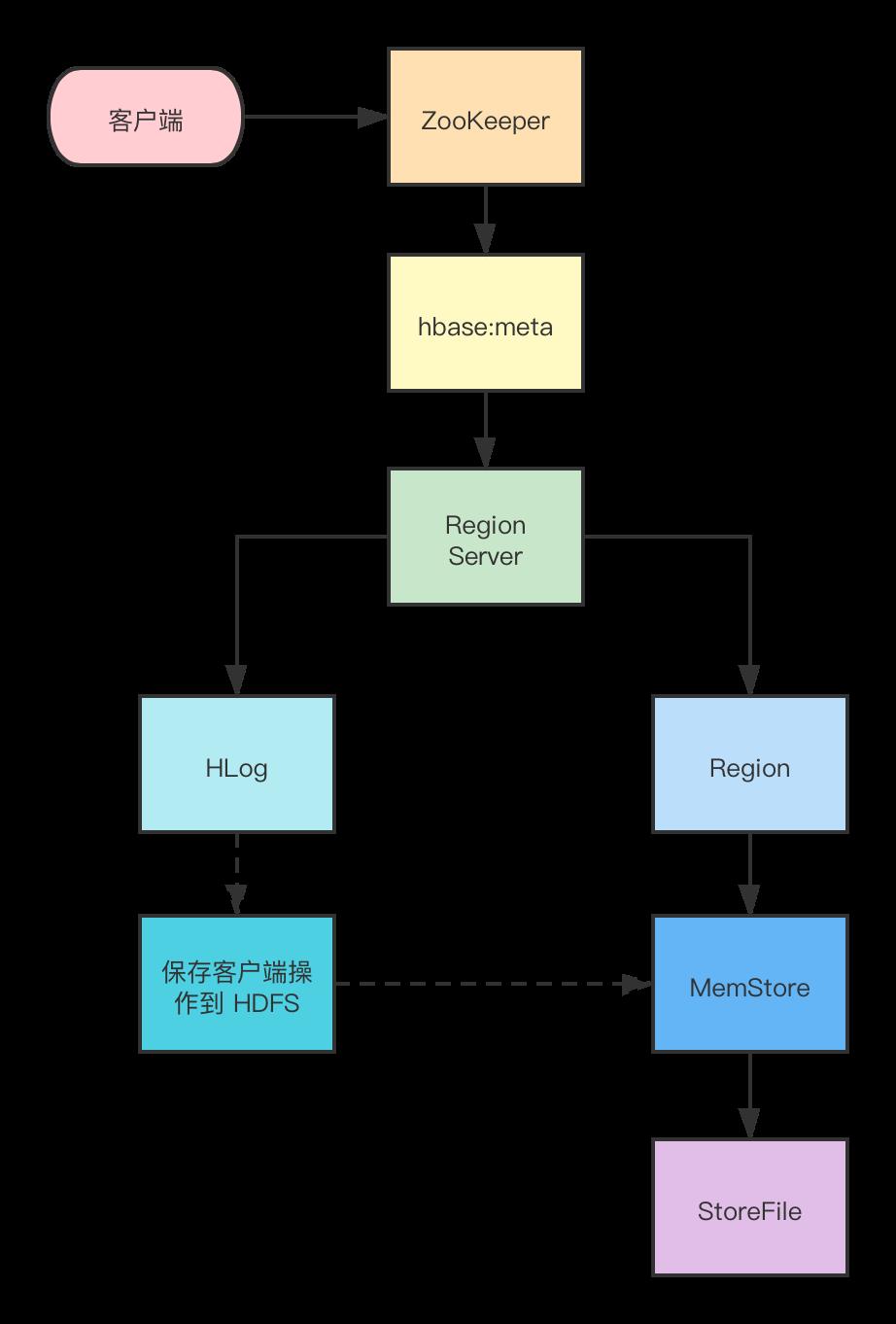
- 首先从 ZooKeeper 找到 hbase:meta 表的 Region 位置,然后读取 hbase:meta 表中的数据, hbase:meta 表中存储了用户表的 Region 信息
- 根据 namespace 、表名和 rowkey 信息找到写入数据对应的 Region 信息
- 找到这个 Region 对应的 RegionServer ,然后发送请求
- 把数据分别写到 HLog ( WriteAheadLog )和 MemStore 各一份
- MemStore 达到阈值后把数据刷到磁盘,生成 StoreFile 文件
- 删除 HLog 中的历史数据。
以上是关于图文详解 HBase 的读写流程的主要内容,如果未能解决你的问题,请参考以下文章