神经网络对多变量的性别结果预测
Posted 咋_T细胞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络对多变量的性别结果预测相关的知识,希望对你有一定的参考价值。
神经网络这几年可谓是火得一塌糊涂,它是目前最为火热的研究方向——深度学习的基础。在神经网络刚被发明之初,人们欢呼雀跃,认为是创造出来了比人更强的思维怪兽。它类比于人的神经元的工作方式,通过信号传递,不断调整权重,最终输出结果!本文将根据一个多参数预测男女性别的实际案例向大家!
目录
一、什么是神经网络?
简而言之,神经网络就是函数:输入数据,输出结果!
神经网络类似人类大脑,由一个个神经元组成,每个神经元和多个其他神元连接,形成网状。单个神经元只会解决最简单的问题,但是组合成一个分层的整体,就可以解决复杂问题。
顾名思义,神经网络是类似于人脑神经元的一种东西。学过生物的我们都知道,神经元彼此之间相互联系,传入一个信号后,可以在神经元之间不断传递,最终促使肌体做出反应,比如被针扎了之后会马上缩手。你也可以笼统的认为神经网络就是一个函数,传入一个或多个参数后,经过一系列变换,输出一个或多个参数。最简单的以y=x+1为例,传入一个值就能输出一个值,当传入x=2的时候输出3,x=3的时候输出4。不过,真正的神经网络要复杂的多。想要继续深入学习可以参考:什么是神经网络?
二、神经网络的工作原理
首先让我们来看一个经典的神经网络。这是一个包含三个层次的神经网络:输入层、中间层(也叫隐藏层)、输出层。
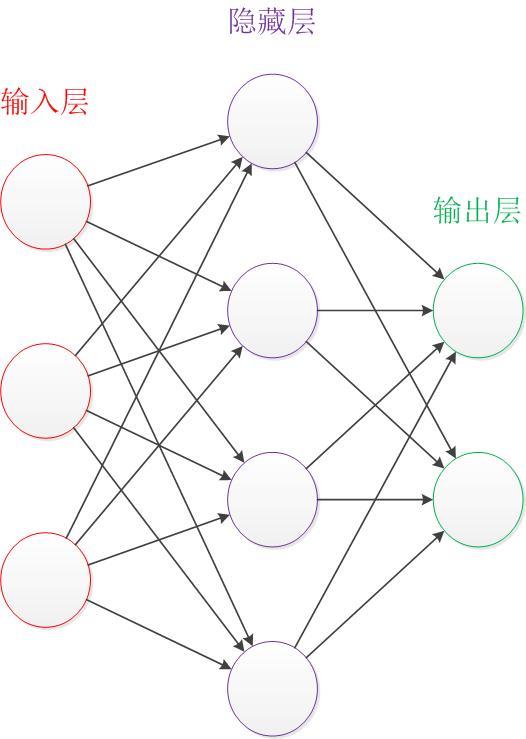
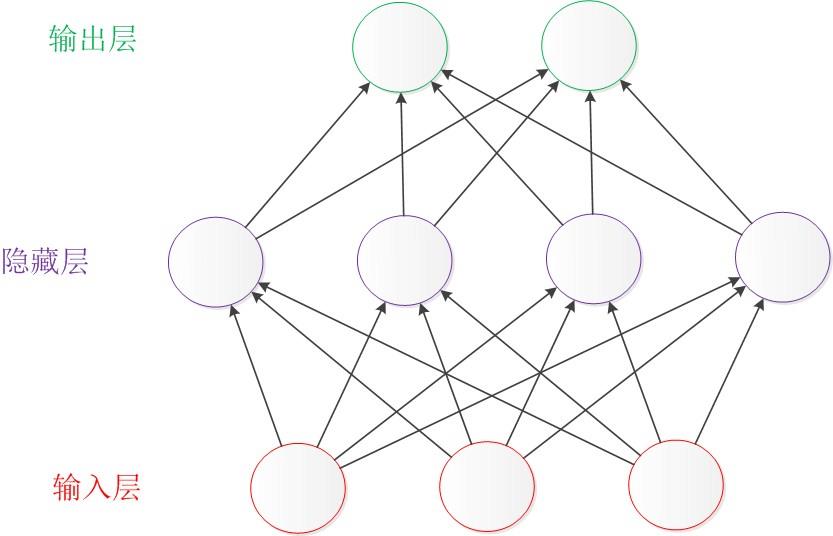
输入层和输出层比较好理解,一个输入一个输出。最难的是中间层,它相当于一个黑匣子,你也可以把他看成一个函数拟合器,它可以拟合任何函数。它的工作原理可以分为以下几个方面:
- 接受输入的变量,并以此作为信息来源;
- 拥有权重变量,并以此作为知识;
- 融合信息和知识,输出预测结果
目前为止所有的神经网络都是这样工作的,他使用权重中的知识解释输入数据的信息。
另一种理解神经网络权重的方法是将权重作为网络的输入和预测之间敏感度的度量:如果权重非常高,即使是最小的输入也可以对预测结果产生非常大的影响;如果权重很小,那就算是很大的输入也只能对预测结果产生很小的扰动。
在这里引入一篇博客:神经网络工作原理,感兴趣的小伙伴可以去看看!
三、实际场景描述
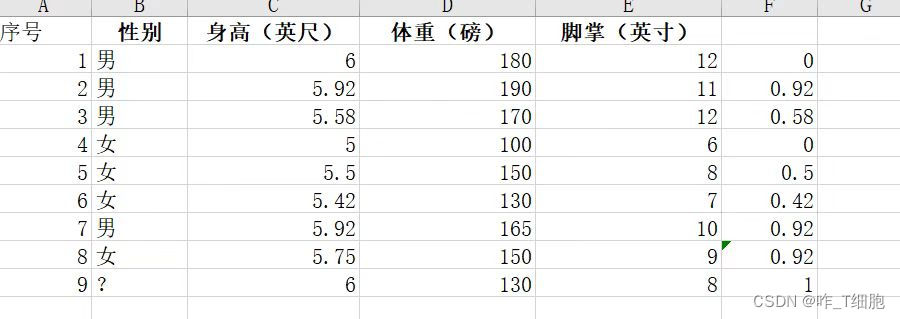
用KNN方法,将1-8数据做为训练集,判断第9条数据是男人还是女人?
思路:根据1-8给出的身高,体重,脚掌长度作为输入,性别作为输出训练一个神经网络,并将第9条数据传入,判断ta的性别。
四、代码
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
@Project :python
@File :knn.py
@IDE :PyCharm
@Author :咋
@Date :2022/10/25 10:41
"""
#预测男女性别
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
a=([(6,180,12),
(5.92,190,11),
(5.58,170,12),
(5,100,6),
(5.5,150,8),
(5.42,130,7),
(5.92,165,10),
(5.75,150,9)])
# mx=np.max(a)
# mn=np.min(a)
# b=(a-mn)/(mx-mn)
# print(b)
y=['male','male','male','female','female','female','male','female']
# 训练模型
neigh=KNeighborsClassifier(n_neighbors=6)
neigh.fit(a,y)
Z=neigh.predict(np.array([[6,130,8]]))
print(Z)结果为:female
归一化也是神经网络经常要进行的操作,代码如下:
mx=np.max(a)
mn=np.min(a)
b=(a-mn)/(mx-mn)
print(b)五、KNeighborsClassifier算法
KNeighborsClassifier(n_neighbors=5,weights=’uniform’,algorithm=’auto’,leaf_size=30,p=2,metric=’minkowski’,metric_params=None,n_jobs=1,**kwargs)
- n_neighbors: int, 可选参数(默认为 5)用于kneighbors查询的默认邻居的数量
-
weights(权重): str or callable(自定义类型), 可选参数(默认为 ‘uniform’)
用于预测的权重函数。可选参数如下:
‘uniform’ : 统一的权重. 在每一个邻居区域里的点的权重都是一样的。
‘distance’ : 权重点等于他们距离的倒数。使用此函数,更近的邻居对于所预测的点的影响更大。
[callable] : 一个用户自定义的方法,此方法接收一个距离的数组,然后返回一个相同形状并且包含权重的数组。 -
algorithm(算法): ‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’, 可选参数(默认为 ‘auto’)
计算最近邻居用的算法:
‘ball_tree’ 是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。
‘kd_tree’ 构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。
‘brute’ 使用暴力搜索.也就是线性扫描,当训练集很大时,计算非常耗时
‘auto’ 会基于传入fit方法的内容,选择最合适的算法。 -
leaf_size(叶子数量): int, 可选参数(默认为 30)
传入BallTree或者KDTree算法的叶子数量。此参数会影响构建、查询BallTree或者KDTree的速度,以及存储BallTree或者KDTree所需要的内存大小。 此可选参数根据是否是问题所需选择性使用。
-
p: integer, 可选参数(默认为 2)
用于Minkowski metric(闵可夫斯基空间)的超参数。p = 1, 相当于使用曼哈顿距离 (l1),p = 2, 相当于使用欧几里得距离(l2) 对于任何 p ,使用的是闵可夫斯基空间(l_p)
- metric(矩阵): string or callable, 默认为 ‘minkowski’
用于树的距离矩阵。默认为闵可夫斯基空间,如果和p=2一块使用相当于使用标准欧几里得矩阵. 所有可用的矩阵列表请查询 DistanceMetric 的文档。
- metric_params(矩阵参数): dict, 可选参数(默认为 None)
给矩阵方法使用的其他的关键词参数。
- n_jobs: int, 可选参数(默认为 1)
用于搜索邻居的,可并行运行的任务数量。如果为-1, 任务数量设置为CPU核的数量。不会影响fit方法。
| 方法名 | 含义 |
| fit(X, y) | 使用X作为训练数据,y作为目标值(类似于标签)来拟合模型。 |
| get_params([deep]) | 获取估值器的参数。 |
| kneighbors([X, n_neighbors, return_distance]) | 查找一个或几个点的K个邻居。 |
| kneighbors_graph([X, n_neighbors, mode]) | 计算在X数组中每个点的k邻居的(权重)图。 |
| predict(X) | 给提供的数据预测对应的标签。 |
| predict_proba(X) | 返回测试数据X的概率估值。 |
| score(X, y[, sample_weight]) | 返回给定测试数据和标签的平均准确值。 |
| set_params(**params) | 设置估值器的参数。 |
六、总结
卷积神经网络、BP神经网络,机器学习,深度学习,神经网络功能越来越强大。让人看到未来强人工智能的希望——即机器有自己的思维。当然,这还比较遥远。“人工智能”,先有人工才有智能,正因为人工收集采集成千上万的数据,才能训练好一个比较可靠的模型。真正机器完全有自己的思维可能还遥遥无期。好啦,今天的分享就到这里啦!欢迎感兴趣的小伙伴评论区留言哦!
以上是关于神经网络对多变量的性别结果预测的主要内容,如果未能解决你的问题,请参考以下文章