np2016课程总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了np2016课程总结相关的知识,希望对你有一定的参考价值。
林牧 SA16222166
- 课程目标
- 课程安排
- A1a
- A2
- A3
- 其他方面的收获
- 本课心得
课程目标
通过实现一个医学辅助诊断的专家系统原型,具体为实现对血常规检测报告OCR识别结果,预测人物的年龄和性别,学习机器学习的常见算法,重点分析神经网路,理解和掌握常用算法的使用。
课程安排
- A1a 神经网络实现手写字符识别系统
- A2 血常规检验报告的图像OCR识别
- A3 根据血常规检验的各项数据预测年龄和性别
Pull Request
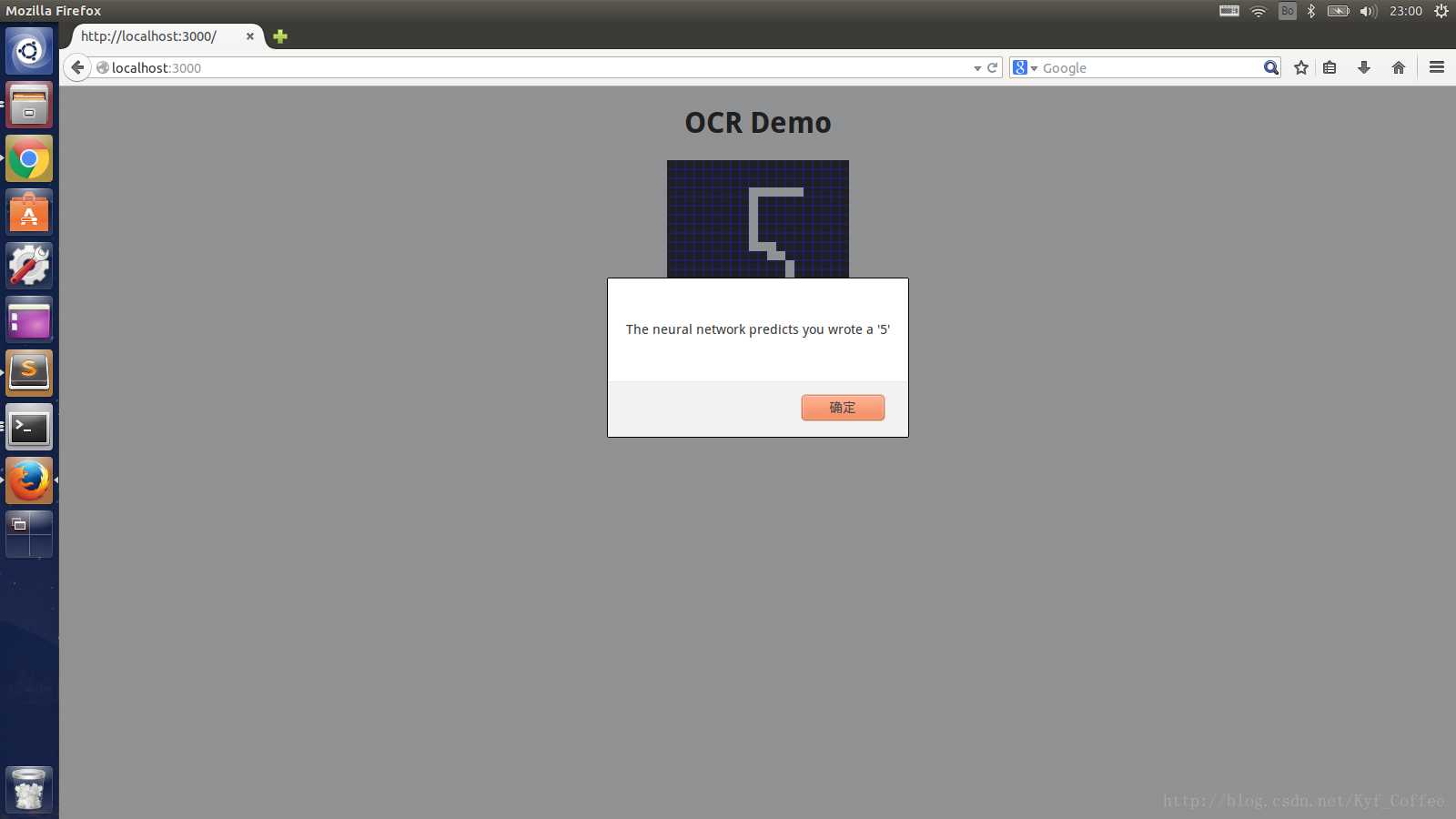
A1a
该项目属于神经网络中的"Hello World",本项目的目的是通过对一定量数字的训练,达到对手写数字的识别。输入的图像是一个20x20的图像,共有400个像素点。我们把这400个像素点都作为输入加入到神经网络的输入层。然后,我们为隐藏层设置为15个节点。输出层设置为10个节点,这10个节点也就是该神经网络对输入图像进行分类所输出的分类信息,我们从中可以确定输出的是哪个数字。然后在网页端显示出来。
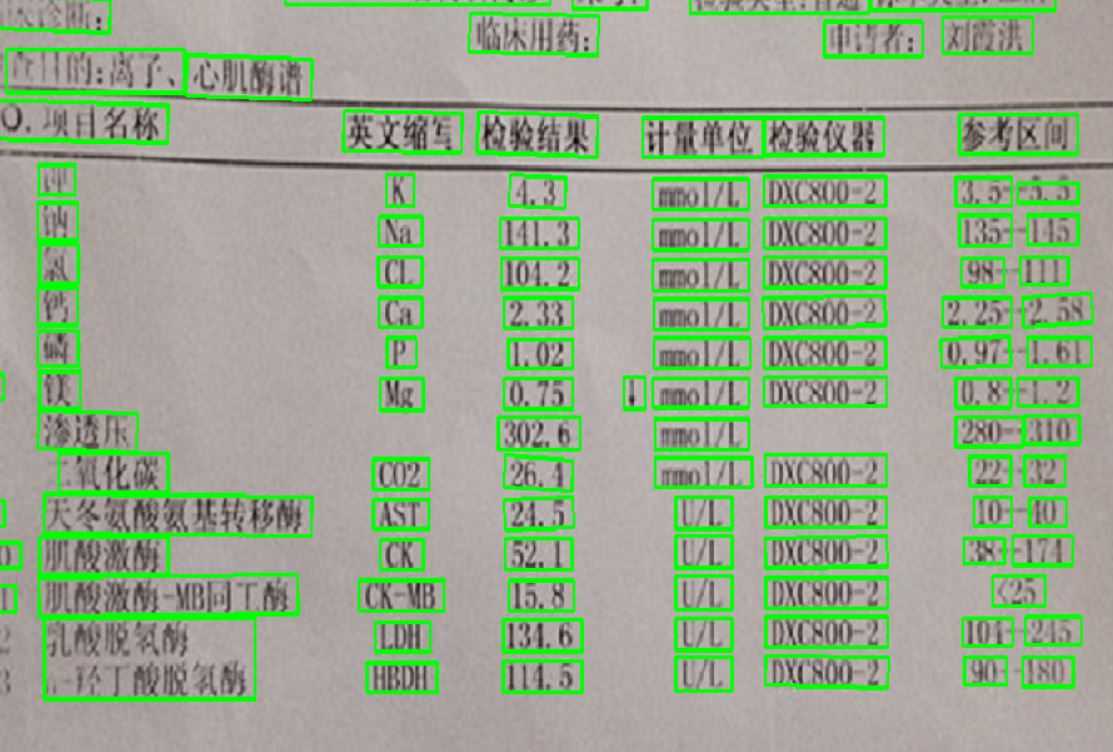
A2
A2部分主要是对得到的化验单进行图像预处理后,利用OCR提取出其中有用的信息。例如人名,时间以及各种化验指标等。在这一部分,我的思路主要是用一些形态学的方法(腐蚀膨胀)对图像进行预处理,代码如下:
def preprocess(gray): # 1. Sobel算子,x方向求梯度 sobel = cv2.Sobel(gray, cv2.CV_8U, 1, 0, ksize = 3) cv2.namedWindow("sobel") cv2.imshow("sobel", sobel) cv2.waitKey(0) # 2. 二值化 ret, binary = cv2.threshold(sobel, 0, 255, cv2.THRESH_OTSU+cv2.THRESH_BINARY) cv2.namedWindow("binary") cv2.imshow("binary", binary) cv2.waitKey(0) # 3. 膨胀和腐蚀操作的核函数 element1 = cv2.getStructuringElement(cv2.MORPH_RECT, (15, 3)) element2 = cv2.getStructuringElement (cv2.MORPH_RECT, (17,3)) # 4. 膨胀一次,让轮廓突出 dilation = cv2.dilate(binary, element2, iterations = 1) cv2.namedWindow("dilation1") cv2.imshow("dilation1", dilation) cv2.waitKey(0) # 5. 腐蚀一次,去掉细节,如表格线等。注意这里去掉的是竖直的线 erosion = cv2.erode(dilation, element1, iterations = 1) cv2.namedWindow("erosion") cv2.imshow("erosion", erosion) cv2.waitKey(0) #6. 再次膨胀,让轮廓明显一些 dilation2 = cv2.dilate(erosion, element2, iterations = 1) cv2.namedWindow("dilation2") cv2.imshow("dilation2", dilation2) cv2.waitKey(0) # 7. 存储中间图片 cv2.imwrite("binary.png", binary) cv2.imwrite("dilation1.png", dilation) cv2.imwrite("erosion.png", erosion) cv2.imwrite("dilation2.png", dilation2) return dilation2
这里大概解释一下,膨胀和腐蚀操作都是通过一个核对图像进行类似卷积的操作实现的,其中膨胀操作会使图像的区域变大,而腐蚀的操作会使图像的区域变小。在本例中,先使用一个水平方向的sobel算子求梯度。这样一来,长横线在水平方向上一直存在,也就是说梯度是趋近于0,在梯度操作后会消失。然后进行了膨胀——腐蚀——膨胀的操作。第一次膨胀使轮廓更加明显,接下来的腐蚀操作会去掉一些噪点,最后的膨胀操作有补偿腐蚀操作的作用,这样一来经过腐蚀操作还留下来的点会扩大一点使轮廓更清晰,而噪点会消失。如下两图所示:

然后,排除其中面积比较小的区域,把大的区域圈出来:
最后取出圈出的点,利用tesseract进行识别。
然而,最后还是放弃了这个办法,因为在数字和文字离得很近的时候无法分开数字和文字,导致文字和数字在一起识别的时候没有办法识别出数字和文字。
最后使用的是某个大神针对我们要处理的图像的进行的特别的处理,主要步骤如下:
- 原图像如下:
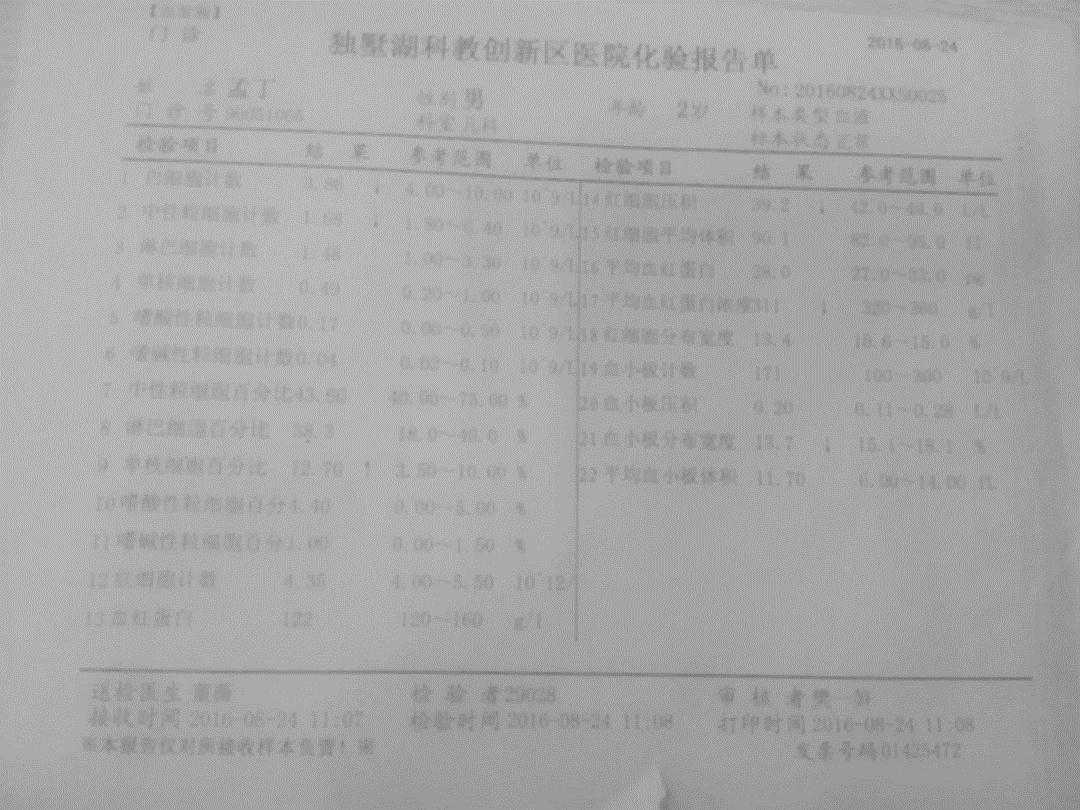
2. 开闭操作后采用canny算子提取边缘

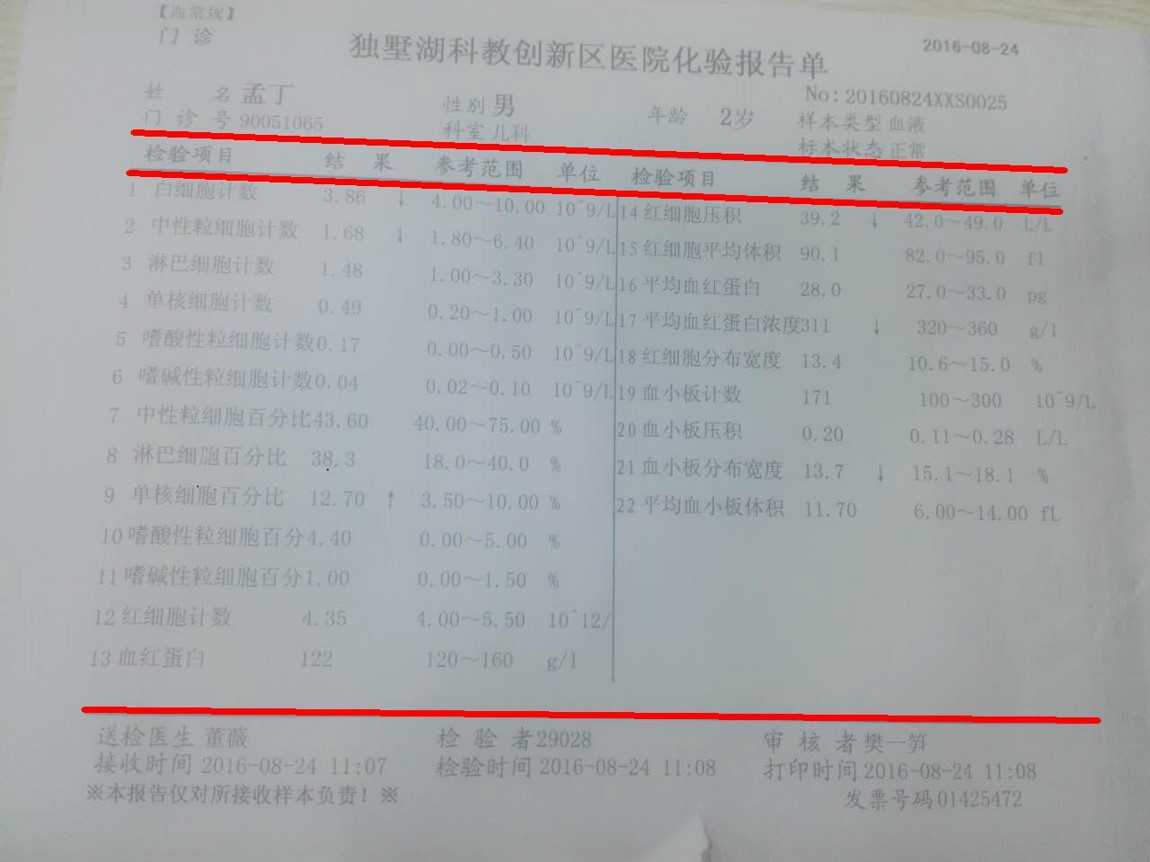
3. 用findCounters提取出三条线的轮廓:
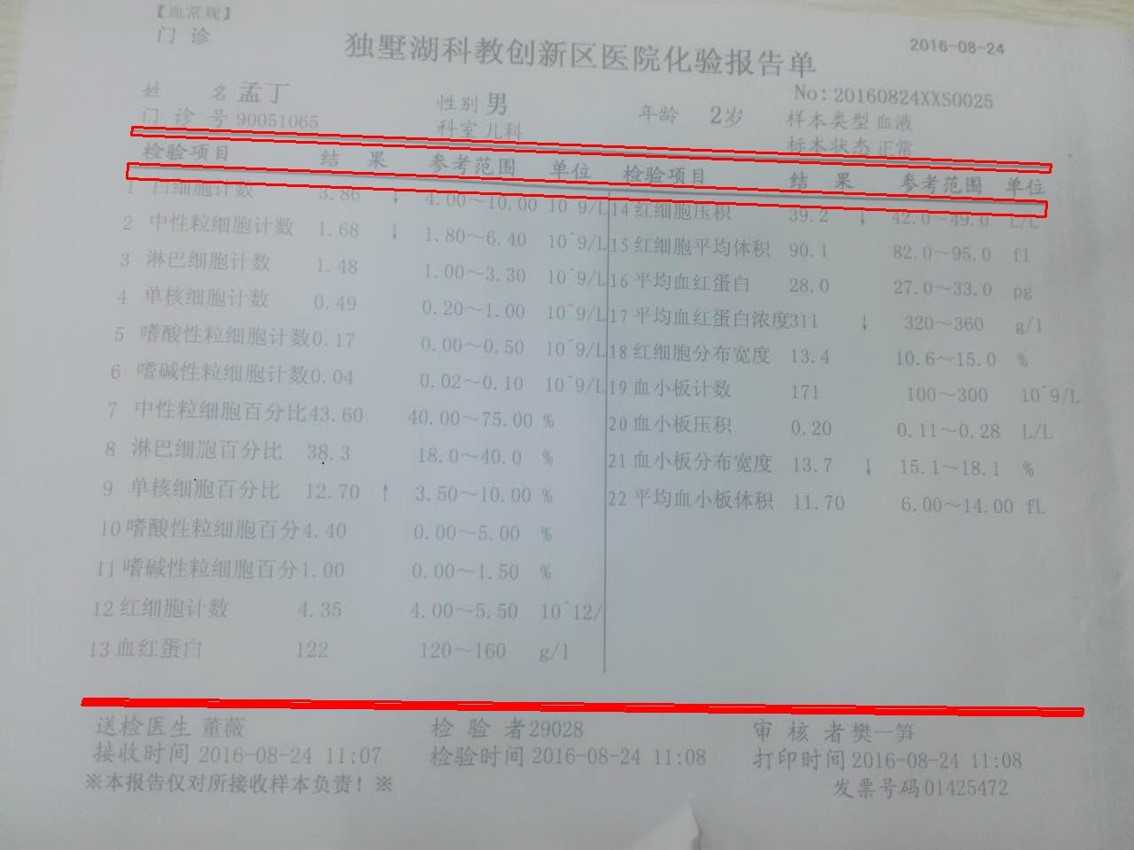
4. 将轮廓变成线,准备下一步的处理,在下一步处理之前,如果多于三条线,则选出其中最长的三条线。接着,根据三条线互相之间的距离确定表头和表尾的位置:
5. 然后,根据叉乘不可变性确定起始点,切下表格进行透视投影变换。
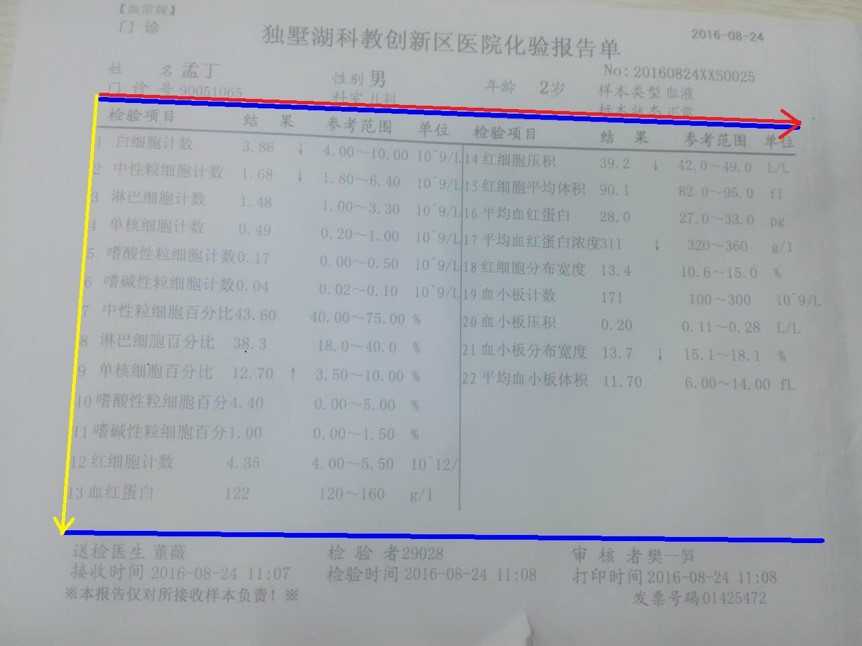
在提取有用部分的时候,我们直接使用上下两条线之间的距离作为一个基准距离,从而可以得到每一个栏目所在的位置的像素点的坐标,然后精准的提取出所要的项目名称和数字。该方法的好处是,可以把数字和文字精准的分开。但是在换其他格式的表格可能会出现一些问题。当然,在本项目中,如果只使用同种格式的表格,该方法是十分高效且便利的。
A3
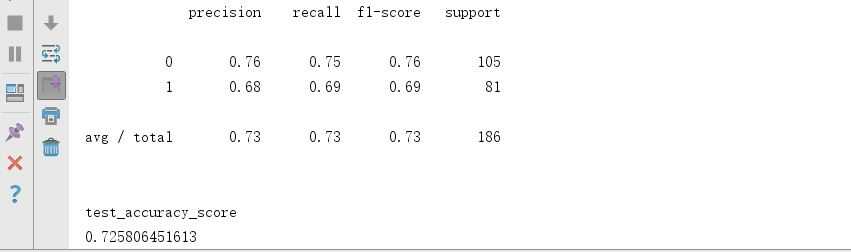
这一部分任务主要是对大量的数据进行处理,然后通过得到的模型对年龄和性别进行预测。在这一部分中,我使用了sklearn库中的svm模型,达到了70%的准确率,实现代码如下:
#coding = utf-8 import pickle import numpy as np from sklearn import svm from sklearn import metrics from sklearn.cross_validation import train_test_split def extract(filename): X = np.loadtxt(filename, skiprows= 1,delimiter=‘,‘, usecols=(3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28)) y = np.loadtxt(filename, dtype=‘string‘, skiprows= 1,delimiter=‘,‘, usecols=(1,)) for i in range(len(y)): if y[i] == ‘\\xc4\\xd0‘: y[i] = 1 else: y[i] = 0 return X,y def split_test(X,y): X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1) return X_train, X_test, y_train, y_test def save_model(model,name): pickle.dump(model, open(str(name)+‘.pkl‘, ‘w‘)) def load_model(name): model = pickle.load(open(str(name)+‘.pkl‘)) return model if __name__ == "__main__": X, y = extract(‘train.csv‘) X_train, X_test, y_train, y_test = split_test(X, y) clf = svm.SVC(kernel=‘linear‘, gamma=0.7, C = 1.0).fit(X_train, y_train) y_predicted = clf.predict(X_test) print metrics.classification_report(y_test, y_predicted) print print "test_accuracy_score" print metrics.accuracy_score(y_test, y_predicted) save_model(clf,‘sex‘) X, y =extract(‘predict.csv‘) clf2 = load_model(‘sex‘) y2_predicted = clf2.predict(X) print "accuracy_score" print metrics.accuracy_score(y, y2_predicted)
支持向量机(support vector machine)是一种分类算法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
SVM从线性可分情况下的最优分类面发展而来。最优分类面就是要求分类线不但能够将两类正确分开(训练错误率位0),且使分类间隔最大。SVM考虑寻找一个满足分类要求的超平面,并且是训练集中的点距离分类面尽可能的远,也就是寻找一个分类面使它两侧的空白区域(margin)最大。过两类样本中离分类面最近的点且平行于最优分类面的超平面上H1,H2的训练样本就叫做支持向量。这也是支持向量机的名称的由来。
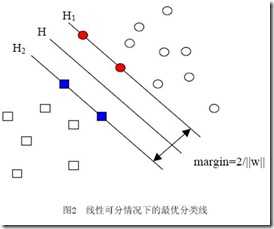
关于支持向量机的具体内容,可以参照手把手教你实现SVM算法这一系列文章。
以上是关于np2016课程总结的主要内容,如果未能解决你的问题,请参考以下文章