网页爬虫之二手车价格爬虫
Posted CodeSavior
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网页爬虫之二手车价格爬虫相关的知识,希望对你有一定的参考价值。
今天学习了爬虫技术
简单来说就是利用pyhon连续的访问网页,自动的将网页中我们用到的信息存储起来的过程。
需要我们的看懂简单的网页代码,能够写一些简单的python语句
下面我们举一个一个需要两步爬虫的例子:
第一步:获取车辆链接
我们想获取二手车辆的价格年份等信息
车辆信息的展示是分页的

为了将所有分页的车辆信息都获取到,我们总结了不同分页网络链接的不同
第一页为www.某某某/24-1282-1-1
第二页为www.某某某/24-1282-1-2
我们可以看到唯一的不同是有1282-1-1变为-2了。
依照这样的规律我们可以写一个循环来实现对网页的切换
for i in range (1,2,1):
print("开始爬取第 %s 页" % page)
url = 'https://www.某车帝.com/usedcar/x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-24-1282-1--x-x-x-x-x'.format(i)但是通过如上的操作我们并不能看到车辆的当前价格,可能是由于这个网站就是怕我们进行爬虫故意设置的。
但是聪明的我们可以点进去这个链接进入车辆的具体信息中
看到“新车指导价”和“比新车省”的价格做差可以得到当前价格,而这两个数据是可以在网页中获得的。

从此,我们心中就有底啦!开干!
第二步:在车辆详细信息中爬取数据
res = requests.get(url).text
content = BeautifulSoup(res, "html.parser")
data = content.find_all('li', attrs='class': 'tw-col-span-13')
car_list = []
for d in data:
carurl = d.find('a')['href']
car_list.append("https://www.dongchedi.com"+carurl)创建一个文件,将获取到的信息存储到txt文件中。
file = open("carprice.txt","w")
for percarlink in data:
result = getprice(percarlink)
realprice= float(result[1][0][6:-1])-float(result[2][0][5:-1])
file.write(result[0][0] +','+result[1][0][6:-1]+','+result[2][0][5:-1]+','+str(realprice)+'\\n')
time.sleep(1)
file.close()其中,获取具体的信息写在getprice函数中。
def getprice(url):
print(url)
html = requests.get(url,headers='').text
etree_html = etree.HTML(html)
content = etree_html.xpath('//*[@id="__next"]/div/div[2]/div/div[2]/div[2]/div[1]/h1/text()')#获取的是产品类型
stand_price = etree_html.xpath('//*[@id="__next"]/div/div[2]/div/div[2]/div[2]/div[3]/div/div/p[1]/text()')#获取的是指导价
takeoff_price = etree_html.xpath('//*[@id="__next"]/div/div[2]/div/div[2]/div[2]/div[3]/div/div/p[2]/text()')#获取的是比新车优惠的价格
distance= etree_html.xpath('//*[@id="__next"]/div/div[2]/div/div[2]/div[2]/div[5]/div/div[2]/p[1]/text()')
result = [content,stand_price,takeoff_price]
return result这里我们用到了xpath,
xpath的获取方式如下所示
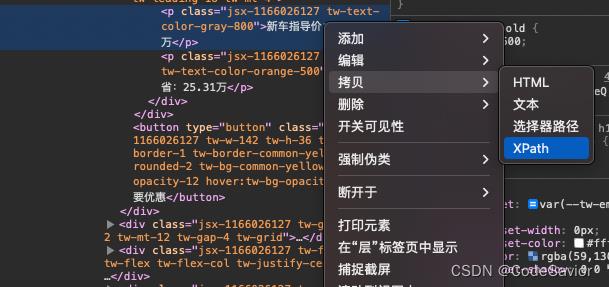
需要注意的是在后面需要加上/text()。
详细的代码大家可以看如下项目
网络爬虫案例+python+汽车价格爬虫-数据集文档类资源-CSDN下载
以上是关于网页爬虫之二手车价格爬虫的主要内容,如果未能解决你的问题,请参考以下文章
Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据