常用的机器学习&数据挖掘知识(点)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常用的机器学习&数据挖掘知识(点)相关的知识,希望对你有一定的参考价值。
常用的机器学习&数据挖掘知识(点)Basis(基础):MSE(Mean Square Error 均方误差),LMS(LeastMean Square 最小均方),LSM(Least Squa
参考技术A 常用的机器学习&数据挖掘知识(点)Basis(基础):MSE(Mean Square Error 均方误差),
LMS(LeastMean Square 最小均方),
LSM(Least Square Methods 最小二乘法),
MLE(MaximumLikelihood Estimation最大似然估计),
QP(Quadratic Programming 二次规划),
CP(Conditional Probability条件概率),
JP(Joint Probability 联合概率),
MP(Marginal Probability边缘概率),
Bayesian Formula(贝叶斯公式),
L1 /L2Regularization(L1/L2正则,
以及更多的,现在比较火的L2.5正则等),
GD(GradientDescent 梯度下降),
SGD(Stochastic Gradient Descent 随机梯度下降),
Eigenvalue(特征值),
Eigenvector(特征向量),
QR-decomposition(QR分解),
Quantile (分位数),
Covariance(协方差矩阵)。
Common Distribution(常见分布):
Discrete Distribution(离散型分布):
BernoulliDistribution/Binomial(贝努利分布/二项分布),
Negative BinomialDistribution(负二项分布),
MultinomialDistribution(多项式分布),
Geometric Distribution(几何分布),
HypergeometricDistribution(超几何分布),
Poisson Distribution (泊松分布)。
Continuous Distribution (连续型分布):
UniformDistribution(均匀分布),
Normal Distribution /Guassian Distribution(正态分布/高斯分布),
ExponentialDistribution(指数分布),
Lognormal Distribution(对数正态分布),
GammaDistribution(Gamma分布),
Beta Distribution(Beta分布),
Dirichlet Distribution(狄利克雷分布),
Rayleigh Distribution(瑞利分布),
Cauchy Distribution(柯西分布),
Weibull Distribution (韦伯分布)。
Three Sampling Distribution(三大抽样分布):
Chi-squareDistribution(卡方分布),
t-distribution(t-distribution),
F-distribution(F-分布)。
Data Pre-processing(数据预处理):
Missing Value Imputation(缺失值填充),
Discretization(离散化),Mapping(映射),
Normalization(归一化/标准化)。
Sampling(采样):
Simple Random Sampling(简单随机采样),
OfflineSampling(离线等可能K采样),
Online Sampling(在线等可能K采样),
Ratio-based Sampling(等比例随机采样),
Acceptance-RejectionSampling(接受-拒绝采样),
Importance Sampling(重要性采样),
MCMC(MarkovChain Monte Carlo 马尔科夫蒙特卡罗采样算法:Metropolis-Hasting& Gibbs)。
Clustering(聚类):
K-Means,
K-Mediods,
二分K-Means,
FK-Means,
Canopy,
Spectral-KMeans(谱聚类),
GMM-EM(混合高斯模型-期望最大化算法解决),
K-Pototypes,CLARANS(基于划分),
BIRCH(基于层次),
CURE(基于层次),
DBSCAN(基于密度),
CLIQUE(基于密度和基于网格)。
Classification&Regression(分类&回归):
LR(Linear Regression 线性回归),
LR(LogisticRegression逻辑回归),
SR(Softmax Regression 多分类逻辑回归),
GLM(GeneralizedLinear Model 广义线性模型),
RR(Ridge Regression 岭回归/L2正则最小二乘回归),
LASSO(Least Absolute Shrinkage andSelectionator Operator L1正则最小二乘回归),
RF(随机森林),
DT(DecisionTree决策树),
GBDT(Gradient BoostingDecision Tree 梯度下降决策树),
CART(ClassificationAnd Regression Tree 分类回归树),
KNN(K-Nearest Neighbor K近邻),
SVM(Support VectorMachine),
KF(KernelFunction 核函数PolynomialKernel Function 多项式核函、
Guassian KernelFunction 高斯核函数/Radial BasisFunction RBF径向基函数、
String KernelFunction 字符串核函数)、
NB(Naive Bayes 朴素贝叶斯),BN(Bayesian Network/Bayesian Belief Network/ Belief Network 贝叶斯网络/贝叶斯信度网络/信念网络),
LDA(Linear Discriminant Analysis/FisherLinear Discriminant 线性判别分析/Fisher线性判别),
EL(Ensemble Learning集成学习Boosting,Bagging,Stacking),
AdaBoost(Adaptive Boosting 自适应增强),
MEM(MaximumEntropy Model最大熵模型)。
Effectiveness Evaluation(分类效果评估):
Confusion Matrix(混淆矩阵),
Precision(精确度),Recall(召回率),
Accuracy(准确率),F-score(F得分),
ROC Curve(ROC曲线),AUC(AUC面积),
LiftCurve(Lift曲线) ,KS Curve(KS曲线)。
PGM(Probabilistic Graphical Models概率图模型):
BN(Bayesian Network/Bayesian Belief Network/ BeliefNetwork 贝叶斯网络/贝叶斯信度网络/信念网络),
MC(Markov Chain 马尔科夫链),
HMM(HiddenMarkov Model 马尔科夫模型),
MEMM(Maximum Entropy Markov Model 最大熵马尔科夫模型),
CRF(ConditionalRandom Field 条件随机场),
MRF(MarkovRandom Field 马尔科夫随机场)。
NN(Neural Network神经网络):
ANN(Artificial Neural Network 人工神经网络),
BP(Error BackPropagation 误差反向传播)。
Deep Learning(深度学习):
Auto-encoder(自动编码器),
SAE(Stacked Auto-encoders堆叠自动编码器,
Sparse Auto-encoders稀疏自动编码器、
Denoising Auto-encoders去噪自动编码器、
Contractive Auto-encoders 收缩自动编码器),
RBM(RestrictedBoltzmann Machine 受限玻尔兹曼机),
DBN(Deep Belief Network 深度信念网络),
CNN(ConvolutionalNeural Network 卷积神经网络),
Word2Vec(词向量学习模型)。
DimensionalityReduction(降维):
LDA LinearDiscriminant Analysis/Fisher Linear Discriminant 线性判别分析/Fisher线性判别,
PCA(Principal Component Analysis 主成分分析),
ICA(IndependentComponent Analysis 独立成分分析),
SVD(Singular Value Decomposition 奇异值分解),
FA(FactorAnalysis 因子分析法)。
Text Mining(文本挖掘):
VSM(Vector Space Model向量空间模型),
Word2Vec(词向量学习模型),
TF(Term Frequency词频),
TF-IDF(Term Frequency-Inverse DocumentFrequency 词频-逆向文档频率),
MI(MutualInformation 互信息),
ECE(Expected Cross Entropy 期望交叉熵),
QEMI(二次信息熵),
IG(InformationGain 信息增益),
IGR(Information Gain Ratio 信息增益率),
Gini(基尼系数),
x2 Statistic(x2统计量),
TEW(TextEvidence Weight文本证据权),
OR(Odds Ratio 优势率),
N-Gram Model,
LSA(Latent Semantic Analysis 潜在语义分析),
PLSA(ProbabilisticLatent Semantic Analysis 基于概率的潜在语义分析),
LDA(Latent DirichletAllocation 潜在狄利克雷模型)。
Association Mining(关联挖掘):
Apriori,
FP-growth(Frequency Pattern Tree Growth 频繁模式树生长算法),
AprioriAll,
Spade。
Recommendation Engine(推荐引擎):
DBR(Demographic-based Recommendation 基于人口统计学的推荐),
CBR(Context-basedRecommendation 基于内容的推荐),
CF(Collaborative Filtering协同过滤),
UCF(User-basedCollaborative Filtering Recommendation 基于用户的协同过滤推荐),
ICF(Item-basedCollaborative Filtering Recommendation 基于项目的协同过滤推荐)。
Similarity Measure&Distance Measure(相似性与距离度量):
Euclidean Distance(欧式距离),
ManhattanDistance(曼哈顿距离),
Chebyshev Distance(切比雪夫距离),
MinkowskiDistance(闵可夫斯基距离),
Standardized Euclidean Distance(标准化欧氏距离),
MahalanobisDistance(马氏距离),
Cos(Cosine 余弦),
HammingDistance/Edit Distance(汉明距离/编辑距离),
JaccardDistance(杰卡德距离),
Correlation Coefficient Distance(相关系数距离),
InformationEntropy(信息熵),
KL(Kullback-Leibler Divergence KL散度/Relative Entropy 相对熵)。
Optimization(最优化):
Non-constrainedOptimization(无约束优化):
Cyclic VariableMethods(变量轮换法),
Pattern Search Methods(模式搜索法),
VariableSimplex Methods(可变单纯形法),
Gradient Descent Methods(梯度下降法),
Newton Methods(牛顿法),
Quasi-NewtonMethods(拟牛顿法),
Conjugate Gradient Methods(共轭梯度法)。
ConstrainedOptimization(有约束优化):
Approximation Programming Methods(近似规划法),
FeasibleDirection Methods(可行方向法),
Penalty Function Methods(罚函数法),
Multiplier Methods(乘子法)。
Heuristic Algorithm(启发式算法),
SA(SimulatedAnnealing,
模拟退火算法),
GA(genetic algorithm遗传算法)。
Feature Selection(特征选择算法):
Mutual Information(互信息),
DocumentFrequence(文档频率),
Information Gain(信息增益),
Chi-squared Test(卡方检验),
Gini(基尼系数)。
Outlier Detection(异常点检测算法):
Statistic-based(基于统计),
Distance-based(基于距离),
Density-based(基于密度),
Clustering-based(基于聚类)。
Learning to Rank(基于学习的排序):
Pointwise:McRank;
Pairwise:RankingSVM,RankNet,Frank,RankBoost;
Listwise:AdaRank,SoftRank,LamdaMART。
Tool(工具):
MPI,Hadoop生态圈,Spark,BSP,Weka,Mahout,Scikit-learn,PyBrain…
以及一些具体的业务场景与case等。
机器学习的一些常用算法
下面是些泛泛的基础知识,但是真正搞机器学习的话,还是非常有用。像推荐系统、DSP等目前项目上机器学习的应用的关键,我认为数据处理非常非常重要,因为很多情况下,机器学习的算法是有前提条件的,对数据是有要求的。
机器学习强调三个关键词:算法、经验、性能,其处理过程如下图所示。
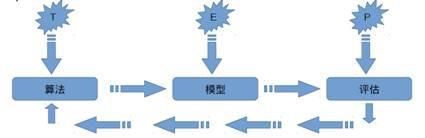
上图表明机器学习是数据通过算法构建出模型并对模型进行评估,评估的性能如果达到要求就拿这个模型来测试其他的数据,如果达不到要求就要调整算法来重新建立模型,再次进行评估,如此循环往复,最终获得满意的经验来处理其他的数据。
1.2 机器学习的分类
1.2.1 监督学习
监督是从给定的训练数据集中学习一个函数(模型),当新的数据到来时,可以根据这个函数(模型)预测结果。监督学习的训练集要求包括输入和输出,也可以说是特征和目标。训练集中的目标是由人标注(标量)的。在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”、“非垃圾邮件”,对手写数字识别中的“1”、“2”、“3”等。在建立预测模型时,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断调整预测模型,直到模型的预测结果达到一个预期的准确率。常见的监督学习算法包括回归分析和统计分类:
l 二元分类是机器学习要解决的基本问题,将测试数据分成两个类,如垃圾邮件的判别、房贷是否允许等问题的判断。
l 多元分类是二元分类的逻辑延伸。例如,在因特网的流分类的情况下,根据问题的分类,网页可以被归类为体育、新闻、技术等,依此类推。
监督学习常常用于分类,因为目标往往是让计算机去学习我们已经创建好的分类系统。数字识别再一次成为分类学习的常见样本。一般来说,对于那些有用的分类系统和容易判断的分类系统,分类学习都适用。
监督学习是训练神经网络和决策树的最常见技术。神经网络和决策树技术高度依赖于事先确定的分类系统给出的信息。对于神经网络来说,分类系统用于判断网络的错误,然后调整网络去适应它;对于决策树,分类系统用来判断哪些属性提供了最多的信息,如此一来可以用它解决分类系统的问题。
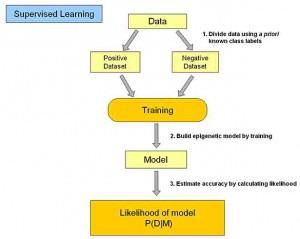
1.2.2 无监督学习
与监督学习相比,无监督学习的训练集没有人为标注的结果。在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。常见的应用场景包括关联规则的学习以及聚类等。常见算法包括Apriori算法和k-Means算法。这类学习类型的目标不是让效用函数最大化,而是找到训练数据中的近似点。聚类常常能发现那些与假设匹配的相当好的直观分类,例如基于人口统计的聚合个体可能会在一个群体中形成一个富有的聚合,以及其他的贫穷的聚合。
非监督学习看起来非常困难:目标是我们不告诉计算机怎么做,而是让它(计算机)自己去学习怎样做一些事情。非监督学习一般有两种思路:第一种思路是在指导Agent时不为其指定明确的分类,而是在成功时采用某种形式的激励制度。需要注意的是,这类训练通常会置于决策问题的框架里,因为它的目标不是产生一个分类系统,而是做出最大回报的决定。这种思路很好地概括了现实世界,Agent可以对那些正确的行为做出激励,并对其他的行为进行处罚。
因为无监督学习假定没有事先分类的样本,这在一些情况下会非常强大,例如,我们的分类方法可能并非最佳选择。在这方面一个突出的例子是Backgammon(西洋双陆棋)游戏,有一系列计算机程序(例如neuro-gammon和TD-gammon)通过非监督学习自己一遍又一遍地玩这个游戏,变得比最强的人类棋手还要出色。这些程序发现的一些原则甚至令双陆棋专家都感到惊讶,并且它们比那些使用预分类样本训练的双陆棋程序工作得更出色。
1.2.3 半监督学习
半监督学习(Semi-supervised Learning)是介于监督学习与无监督学习之间一种机器学习方式,是模式识别和机器学习领域研究的重点问题。它主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题。半监督学习对于减少标注代价,提高学习机器性能具有非常重大的实际意义。主要算法有五类:基于概率的算法;在现有监督算法基础上进行修改的方法;直接依赖于聚类假设的方法等,在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理地组织数据来进行预测。应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测,如图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM)等。
半监督学习分类算法提出的时间比较短,还有许多方面没有更深入的研究。半监督学习从诞生以来,主要用于处理人工合成数据,无噪声干扰的样本数据是当前大部分半监督学习方法使用的数据,而在实际生活中用到的数据却大部分不是无干扰的,通常都比较难以得到纯样本数据。

1.2.4 强化学习
强化学习通过观察来学习动作的完成,每个动作都会对环境有所影响,学习对象根据观察到的周围环境的反馈来做出判断。在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式,在强化学习下,输入数据直接反馈到模型,模型必须对此立刻做出调整。常见的应用场景包括动态系统以及机器人控制等。常见算法包括Q-Learning 以及时间差学习(Temporal difference learning)。
在企业数据应用的场景下,人们最常用的可能就是监督式学习和非监督式学习的模型。在图像识别等领域,由于存在大量的非标识的数据和少量的可标识数据,目前半监督式学习是一个很热的话题。而强化学习更多地应用在机器人控制及其他需要进行系统控制的领域。
1.3 机器学习的常见算法
常见的机器学习算法有:
l 构造条件概率:回归分析和统计分类;
l 人工神经网络;
l 决策树;
l 高斯过程回归;
l 线性判别分析;
l 最近邻居法;
l 感知器;
l 径向基函数核;
l 支持向量机;
l 通过再生模型构造概率密度函数;
l 最大期望算法;
l graphical model:包括贝叶斯网和Markov随机场;
l Generative Topographic Mapping;
l 近似推断技术;
l 马尔可夫链蒙特卡罗方法;
l 变分法;
l 最优化:大多数以上方法,直接或者间接使用最优化算法。
根据算法的功能和形式的类似性,我们可以把算法分类,比如说基于树的算法,基于神经网络的算法等等。当然,机器学习的范围非常庞大,有些算法很难明确归类到某一类。而对于有些分类来说,同一分类的算法可以针对不同类型的问题,下面用一些相对比较容易理解的方式来解析一些主要的机器学习算法:
1.3.1 回归算法
回归算法是试图采用对误差的衡量来探索变量之间的关系的一类算法。回归算法是统计机器学习的利器。在机器学习领域,人们说起回归,有时候是指一类问题,有时候是指一类算法,这一点常常会使初学者有所困惑。常见的回归算法包括:最小二乘法(Ordinary Least Square),逻辑回归(Logistic Regression),逐步式回归(Stepwise Regression),多元自适应回归样条(Multivariate Adaptive Regression Splines)以及本地散点平滑估计(Locally Estimated Scatterplot Smoothing)。
1.3.2 基于实例的算法
基于实例的算法常常用来对决策问题建立模型,这样的模型常常先选取一批样本数据,然后根据某些近似性把新数据与样本数据进行比较。通过这种方式来寻找最佳的匹配。因此,基于实例的算法常常也被称为“赢家通吃”学习或者“基于记忆的学习”。常见的算法包括 k-Nearest Neighbor (KNN),、学习矢量量化(Learning Vector Quantization, LVQ)以及自组织映射算法(Self-Organizing Map,SOM)
1.3.3 正则化方法
正则化方法是其他算法(通常是回归算法)的延伸,根据算法的复杂度对算法进行调整。正则化方法通常对简单模型予以奖励而对复杂算法予以惩罚。常见的算法包括:Ridge Regression、Least Absolute Shrinkage and Selection Operator(LASSO)以及弹性网络(Elastic Net)。
1.3.4 决策树学习
决策树算法根据数据的属性采用树状结构建立决策模型,决策树模型常常用来解决分类和回归问题。常见的算法包括:分类及回归树(Classification And Regression Tree, CART)、 ID3 (Iterative Dichotomiser 3)、C4.5、Chi-squared Automatic Interaction Detection (CHAID)、Decision Stump、机森林(Random Forest)、多元自适应回归样条(MARS)以及梯度推进机(Gradient Boosting Machine,GBM)。
1.3.5 贝叶斯学习
贝叶斯方法算法是基于贝叶斯定理的一类算法,主要用来解决分类和回归问题。常见算法包括:朴素贝叶斯算法、平均单依赖估计(Averaged One-Dependence Estimators, AODE)以及 Bayesian Belief Network(BBN)。
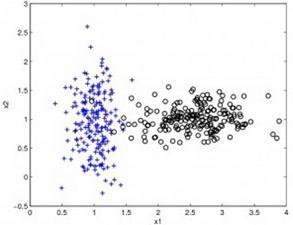
1.3.6 基于核的算法
基于核的算法中最著名的莫过于支持向量机(SVM)了。基于核的算法把输入数据映射到一个高阶的向量空间, 在这些高阶向量空间里, 有些分类或者回归问题能够更容易解决。常见的基于核的算法包括:支持向量机(Support Vector Machine,SVM)、径向基函数(Radial Basis Function,RBF)以及线性判别分析(Linear Discriminate Analysis,LDA)等。
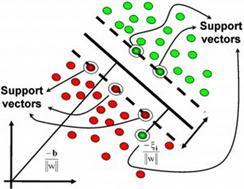
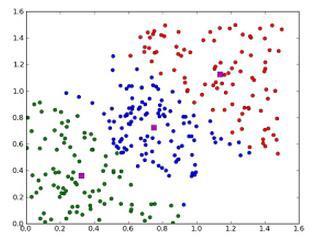
1.3.7 聚类算法
聚类就像回归一样,有时候人们描述的是一类问题,有时候描述的是一类算法。聚类算法通常按照中心点或者分层的方式对输入数据进行归并。所有的聚类算法都试图找到数据的内在结构,以便按照最大的共同点将数据进行归类。常见的聚类算法包括 k-Means 算法以及期望最大化算法(Expectation Maximization,EM)。
1.3.8 关联规则学习
关联规则学习通过寻找最能够解释数据变量之间关系的规则,来找出大量多元数据集中有用的关联规则。常见算法包括 Apriori 算法和 Eclat 算法等。
1.3.9 人工神经网络算法
人工神经网络算法模拟生物神经网络,是一类模式匹配算法。通常用于解决分类和回归问题。人工神经网络是机器学习的一个庞大的分支,有几百种不同的算法(其中深度学习就是其中的一类算法,我们会单独讨论)。重要的人工神经网络算法包括:感知器神经网络(Perceptron Neural Network)、反向传递(Back Propagation)、Hopfield 网络、自组织映射(Self-Organizing Map, SOM)、学习矢量量化(Learning Vector Quantization,LVQ)。
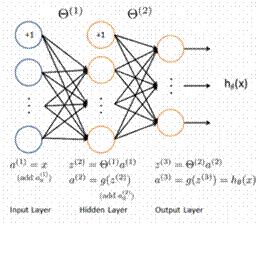
1.3.10 深度学习算法
深度学习算法是对人工神经网络的发展,在近期赢得了很多关注,特别是百度也开始发力深度学习后,更是在国内引起了很多关注。在计算能力变得日益廉价的今天,深度学习试图建立大得多也复杂得多的神经网络。很多深度学习的算法是半监督式学习算法,用来处理存在少量未标识数据的大数据集。常见的深度学习算法包括:受限波尔兹曼机(Restricted Boltzmann Machine, RBN)、 Deep Belief Networks(DBN)、卷积网络(Convolutional Network)、堆栈式自动编码器(Stacked Auto-encoders)。
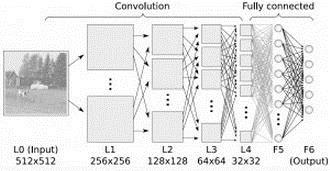
1.3.11 降低维度算法
像聚类算法一样,降低维度算法试图分析数据的内在结构,不过降低维度算法是以非监督学习的方式,试图利用较少的信息来归纳或者解释数据。这类算法可以用于高维数据的可视化或者用来简化数据以便监督式学习使用。常见的算法包括:主成份分析(Principle Component Analysis,PCA)、偏最小二乘回归(Partial Least Square Regression,PLS)、 Sammon 映射、多维尺度(Multi-Dimensional Scaling, MDS)、投影追踪(Projection Pursuit)等。
1.3.12 集成算法
集成算法用一些相对较弱的学习模型独立地对同样的样本进行训练,然后把结果整合起来进行整体预测。集成算法的主要难点在于究竟集成哪些独立的较弱的学习模型以及如何把学习结果整合起来。这是一类非常强大的算法,同时也非常流行。常见的算法包括:Boosting、Bootstrapped Aggregation(Bagging)、AdaBoost、堆叠泛化(Stacked Generalization, Blending)、梯度推进机(Gradient Boosting Machine, GBM)、随机森林(Random Forest)。
以上是关于常用的机器学习&数据挖掘知识(点)的主要内容,如果未能解决你的问题,请参考以下文章