机器学习领域知识概念问题点积累
Posted kidsitcn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习领域知识概念问题点积累相关的知识,希望对你有一定的参考价值。
nd-array/scipy sparse matrices/pandas dataframe
sparse matrice是scipy包定义的一种紧凑数据组织矩阵,pandas dataframe基于numpy的nd-array
https://docs.scipy.org/doc/scipy/reference/sparse.html
feature extraction:特征提取
所有的机器学习算法的输入就是一堆行列构成的数字集合,那么问题来了一般性问题的输入可能并非数字,比如nlp自然语言处理,得到的语料都是文本,使用之前必须做特征提取的工作,将自然语言编码变换为对计算机有意义的数据。还有一种情况是降维时的特征提取
structured learning/unstructured learning
https://pystruct.github.io/intro.html
结构化学习预测是经典监督式学习:分类和回归范例的一个泛化。分类算法也好,回归算法也好都可以更加抽象为以下本质的过程:
寻找到一个针对训练数据集能够最小化损失函数L值的函数F,所不同的是算法函数$F$以及损失函数样式$L$.比如,针对分类问题,目标为离散的标签类别,而loss通常就是0-1 loss,即:计数分类错误总数。而在回归问题中,目标是实数值,loss通常用MSE均方差.
机器学习的本质实际上可以简化为寻找一个函数F,使得输入data到F能够映射为对应的输出:
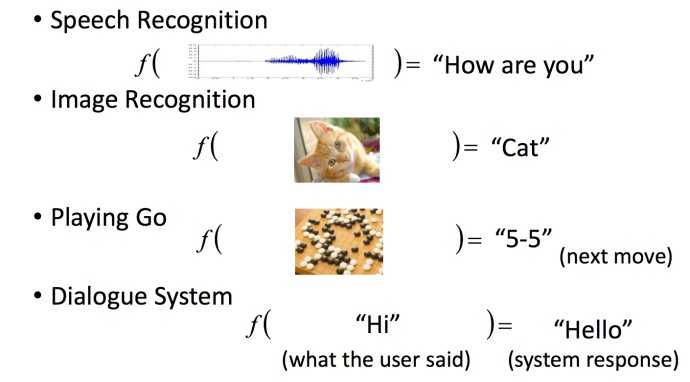
而在结构化学习范畴中,target和loss都或多或少可能是任意的。这意味着我们的目标不再是预测一个分类标签或者一个数值,而可能是更加复杂的对象:比如一个序列或者一副图片。


https://blog.csdn.net/qq_32690999/article/details/78840312
http://yoferzhang.com/post/20170326ML01Introduction/
结构化学习统一框架:
找到一个函数F->评估F(x,y)对象x和y有多么匹配。
以上是关于机器学习领域知识概念问题点积累的主要内容,如果未能解决你的问题,请参考以下文章