线上酒店用户流失分析预警
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线上酒店用户流失分析预警相关的知识,希望对你有一定的参考价值。
参考技术A 本文是对某线上酒店用户流失预测分析项目的一个总结。目录/分析思路:
01: 项目介绍
02:问题分析
03:数据探索
04:数据预处理
05:建模分析
06:用户画像分析
一、项目介绍
该项目是对某酒店预订网在一段时间内的客户预定信息数据进行分析,通过算法预测客户访问的转化结果,挖掘出影响用户流失的关键因素,并深入了解用户画像及行为偏好,从而更好地完善产品设计,进行个性化营销服务,以减少用户流失,提升用户体验。
二、问题分析
这个项目是问题诊断型,要解决的问题是关于用户流失的。在官方提供的字段和解释中,有一个label字段,这个是目标变量,也就是我们需要进行预测的值。label=1代表客户流失,label=0代表客户未流失,很显然这是个分类的预测问题。
我们的目标就是在预测准确率高的同时最大化召回率,从业务角度出发,也就是将更多原本可能会流失的客户最大概率地预测出来,以针对性进行挽留。因为通常来讲,获取新用户的成本比挽留老用户流失的成本要多得多。
三、数据探索
1、数据总体情况
本数据集合userlostprob_data.txt,为某酒店预订网2016年5月16至21日期间一周的访问数据。
本数据集总的数据共有689945行,51列,包含样本id,label以及49个变量特征。
考虑到保护用户隐私,该数据经过了数据脱敏处理,和实际的订单、浏览量、转化率有一些差距,但是并不影响问题的可解性。
2、数据指标梳理
观察数据集,里面的变量比较多。所以首先将数据字典中中文解释替换对应变量名,增强可读性,然后最好将指标进行梳理分类,然后逐个字段进行解析。
经过研究发现,指标大概可以分为三类:一类是订单相关的指标,如入住日期、订单数、取消率等;一类是与客户行为相关的指标,如星级偏好、用户偏好价格等;还有一类是与酒店相关的指标,如酒店评分均值、酒店评分人数、平均价格等。
3、相关特征描述性分析
3.1 访问日期和入住时间
入住人数和访问人数都在5月20日达到峰值,大概是“520”情人节的原因;5月21日之后入住人数大幅减少,后面的两个小波峰,表明周末会比平日人多一些。
3.2 访问时间段
可以观察到,凌晨3-5点是访问人数最少的时间段,因为大多数人这个时间都在睡觉;在晚上9-10点左右访问人数是最多的。
3.3 客户价值
“客户近1年价值”和“客户价值”两个特征非常相关,都可以用来表示客户的价值;可以看到,大部分客户的价值在0-100范围;有些客户价值高达600,后期需重点关注分析这类高价值客户。
3.4 消费能力指数
基本呈现正态分布,大部分人的消费能力在30附近。消费能力达到近100的人数也很多,说明在我们酒店的访问和入住客户中,存在不少高消费水平群体。
3.5 价格敏感指数
去掉极值,数据呈右偏分布,大部分客户对价格不是很敏感,不用太费心定价;针对价格敏感指数100的客户群体,可以采用打折的方式进行吸引。
3.6 入住酒店平均价格
大部分人选择酒店价格在1000以下,价格2000以上的酒店选择的人非常少;排除“土豪”,可以看到,消费者对酒店价格的选择,基本是一个正偏态的分布,大部分人会选择的平均价格在300元左右(大概是快捷酒店一类)。
3.7 用户年订单数
大部分用户的年订单数在40以下,同时,也存在部分频繁入住酒店的用户,需要重点维护;
3.8 订单取消率
用户一年内取消订单率最多的是100%和0,对于百分百取消订单的客户可以结合订单数了解一下原因。
3.9 一年内距离上次下单时长
可以观察出,预定间隔时间越长的人数是递减的,说明相当多的人订酒店还是比较频繁的;侧面反映出“熟客”会经常性地选择预定酒店,回头客较多。
3.10 会话ID
服务器分配给访问者的一个id,1为新的访客。
访问客户中老客户占大多数;老客的预定概率比新客的预定概率稍微高一点。
四、数据预处理
4.1 重复值处理
数据维度没有发生 变化,说明该数据集没有重复值。
4.2 生成衍生字段
基于对业务的理解,考虑到用户提前预定酒店时间这一特征可能会比较重要,将两个日期型特征转化生成一个新的特征,提高模型准确度和可解释性。
4.3 缺失值处理
查看缺失值情况
共51个字段,缺失字段:44个
缺失值处理思路及过程
查看特征分布情况:
查看所有数值型特征的分布情况,根据数据分布合理选用处理方法,包括异常值、缺失值处理,同时有助于深入了解用户行为。
共51个字段,缺失字段:44个,选择合适的方法进行缺失值处理:
缺失比例80%以上:1个,“近7天用户历史订单数”缺失88%,直接删除该字段。
趋于正态分布的字段,使用均值填充;右偏分布的字段,使用中位数填充。
检查缺失值填充情况
查看可知,缺失值数据已填充完毕。
4.4 异常值处理
极值处理:
(后面基于实际业务思考,盖帽法存在部分不合理,可能会过滤高价值用户,需要调整)
负值处理:
4.5 标准化处理
距离类模型需要提前进行数据标准化。
五、建模分析
首先拆分训练集和测试集
5.1 逻辑回归
[0.7366529216096935, 0.7016048745527705]
5.2 决策树
[0.8728884186420657, 0.8448881691422343]
5.3 随机森林
[0.8936581901455913, 0.9399374165108152]
5.4 朴素贝叶斯
[0.6224554131126394, 0.6610756921767458]
5.5 XGBOOST
[0.8886143098362913, 0.9383456626294802]
5.6 模型比较
画出ROC曲线
可以看到,朴素贝叶斯表现最差,逻辑回归的表现也不是很好,说明该数据不是线性可分的;随机森林和xgboost模型的表现差不多,二者的AUC得分都在0.9以上,分类效果很好,随机森林AUC值为0.94更高一点,固采用随机森林进行用户流失预测。
5.7 随机森林模型优化
交叉验证
学习曲线——取分类器为80
[0.9333570067179268, 0.97816699979759]
即根据这个随机森林模型召回率可以达到97.8%,流失客户预测准确率可以达到93.3%。
该模型可以直接上线用于用户流失预测。
5.8 影响客户流失的关键因素
用随机森林分析影响客户流失的因素:使用feature_importance方法,可以得到特征的重要性排序。
最重要的前10个特征:
年访问次数、一年内距上次访问时长、昨日访问当前城市同入住日期的app uv数、一年内距离上次下单时长、昨日提交当前城市同入住日期的app订单数、24小时内已访问酒店可订最低价均值、24小时内已访问酒店商务属性指数均值、24小时内已访问次数最多酒店可订最低价、24小时历史浏览次数最多酒店评分人数、客户价值 。
六、用户画像分析
接下来用K-Means聚类的方法将用户分为3类,观察不同类别客户的特征。
K-means聚类
可以看到,聚出来的3类用户有各自非常明显的特征,针对不对类用户的个性化营销建议:
0类为中等群体: 消费水平和客户价值都偏低,访问和预定频率较高,提前预定的时间是三类中最长的;花费非常多的时间进行浏览才能做出选择,比较谨慎,推测可能为出门旅行的用户。
建议:尽可能多地进行推送,因为此类客户通常比较喜欢浏览;多推荐价格相对实惠的酒店;推送当地旅游资讯,因为这类客户旅游出行的概率较大。
1类为低价值客户: 消费水平和客户价值极低,偏好价格较低,访问和预定频率很低; sid值很低,说明新客户居多。
建议:按照流失客户处理,不建议花费过多营销成本,不做特定渠道运营;推荐促销活动,价格折扣大的的低价酒店;新用户占比较大,潜在客户居多,可以维持服务推送。
2类为高价值客户: 消费水平高,客户价值大,追求高品质,价格敏感度高;登陆时间长,访问次数多,提前预定时间短,但退单次数较多。
建议:为客户提供更多差旅地酒店信息; 推荐口碑好、性价比高的商务连锁酒店房源吸引用户; 在非工作日的11点、17点等日间流量小高峰时段进行消息推送。
一些备注:
1、数据特征筛选时可以做相关性分析,因为可能某些特征之间存在高度相关,可以用相关性分析去掉和目标变量相关性小于0.01的变量,其他变量之间相关性高于0.9的可以删除,再利用主成份分析对指标进行降维整合,可能会使模型效果达到最好。
2、如果想对用户分类更加精细,可以使用RFM模型进行用户价值分析。但本项目特征包含信息较多,用RFM可能损失信息量比较大。
数据挖掘实战:2万字深度分析《电信用户流失预测模型》

1.研究背景
1、做好用户流失预测可以降低营销成本。老生常谈,新客户开发成本是老客户维护成本的5倍。
2、获得更好的用户体验。并不是所有的增值服务都可以有效留住客户。
3、获得更高的销售回报。价格敏感型客户和非价格敏感性客户。
2.提出问题
1、流失客户有哪些显著性特征?
2、当客户在哪些特征下什么条件下比较容易发生流失?
3.数据集描述
该数据是datafountain上的《电信客户流失数据》,这里提供一个下载地址。
数据下载地址:
https://www.datafountain.cn/datasets/35guide
该数据集有21个变量,7043个数据点。变量可分为以下三个部分:用户属性、用户行为、研究对象。
用户属性
customerID :用户IDgender:性别(Female & Male)SeniorCitizen :老年人(1表示是,0表示不是)Partner :是否有配偶(Yes or No)Dependents :是否经济独立(Yes or No)tenure :客户的职位(0-72,共73个职位)
用户行为
PhoneService :是否开通电话服务业务(Yes or No)MultipleLines :是否开通了多线业务(Yes 、No or No phoneservice 三种)InternetService :是否开通互联网服务(No, DSL数字网络,fiber optic光纤网络 三种)OnlineSecurity :是否开通网络安全服务(Yes,No,No internetserive 三种)OnlineBackup :是否开通在线备份业务(Yes,No,No internetserive 三种)DeviceProtection :是否开通了设备保护业务(Yes,No,No internetserive 三种)TechSupport :是否开通了技术支持服务(Yes,No,No internetserive 三种)StreamingTV :是否开通网络电视(Yes,No,No internetserive 三种)StreamingMovies :是否开通网络电影(Yes,No,No internetserive 三种)Contract :签订合同方式 (按月,一年,两年)PaperlessBilling :是否开通电子账单(Yes or No)PaymentMethod :付款方式(bank transfer,credit card,electronic check,mailed check)MonthlyCharges :月费用TotalCharges :总费用
研究对象
Churn:该用户是否流失(Yes or No)
4.分析思路
分析视角是分析方法的灵魂。
分析方法有上百种,但分析视角只有四种:
对比视角
分类视角
相关视角
描述视角
一旦将业务需求拆解成指标,接下来只需要针对每个指标进行分析视角四选一即可。
数据集描述,已经将变量分为三个维度了:用户属性、用户行为、研究对象(是否流失客户),三个维度组合一下就得出了以下解题思路了:
哪些属性的用户比较容易流失?
哪些行为的用户比较容易流失?
以上两个分析思路运用的是【对比视角】,该视角下具体的分析方法有:
数值型数据:均值比较
分类型数据:频数分布比较(交叉分析)
以上的分析方法是统计分析,只能一个维度一个维度地去比较。但实际情况中,并不是每个维度的权重都一样的,那如何去研究各个维度的权重?
权重问题属于分类视角,故我们可以采用分类模型,要用哪个分类模型呢?不知道。可以全部采用,看模型精度得分,然后选得分最高的模型进行进一步预测。
Random Forest 随机森林
SVC 支持向量机
LogisticRegression 逻辑回归
KNN 近邻算法
Naive Bayes 朴素贝叶斯
Decision Tree 决策树
AdaBoost
GradientBoosting
XGB
CatBoost
5.分析结论及运营建议
5.1 分析结论
综合统计分析和XGB算法输出特征重要性得出流失客户有以下特征(依特征重要性从大到小排列):
tenure :1-5号职位的用户比较容易流失
PaymentMethod :使用
电子支票支付的人MonthlyCharges 、TotalCharges : 总费用在2281.92元以下,月费用在64.76元以上的客户比较容易流失
PaperlessBilling : 开通电子账单
Partner : 单身
OnlineBackup : 没开通
在线备份业务InternetService :开通了
Fiber optic 光纤网络TechSupport :没开通“技术支持服务”
DeviceProtection :没开通
设备保护业务OnlineSecurity :没开通
网络安全服务Contract :
按月签订合同方式Dependents :无经济独立
SeniorCitizen :青年人
TotalCharges :总费用在2281.92元以下,月费用在64.76元以上的客户比较容易流失
当条件覆盖得越多,人群越精确,但与此同时,覆盖的人群也会越少。业务方可直接在数据库中,通过SQL检索符合要求的客户,然后做针对性的运营工作。
5.2 运营建议
如何留住客户,可以从两方面去思考:
增加用户的沉没成本(损失厌恶)
会员等级
积分制
充值赠送
满减券
其他增值服务
培养用户的条件反射(习惯)
会员日
定期用户召回
签到
每日定时抽奖
小游戏
电子账单解锁新权益
现象:“开通电子账单”的人反而容易流失。基本假设:价格敏感型客户。电子账单,让客户理性消费。建议:让“电子账单”变成一项“福利。跟连锁便利店,联名发"商品满减券",每月的账单时间,就将"商品满减券“和账单一起推送过去。文案:您上月消费了XX元,解锁了xx会员权益。底层规律:增加沉没成本。
“单身用户”尊享亲情网
现象:“单身用户”容易流失。基本假设:社交欲望低。建议:一个单身用户拥有建立3个人以内的“亲情网”的权益。底层规律:增加沉没成本。
推广“在线备份、设备保护、技术支持、网络保护”等增值服务。
6.数据清洗
6.1 导入模块
6.1.1 数据处理
import pandas as pd
import numpy as np
6.1.2 可视化
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style='darkgrid',font_scale=1.3)
plt.rcParams['font.family']='SimHei'
plt.rcParams['axes.unicode_minus']=False
6.1.3 特征工程
import sklearn
from sklearn import preprocessing #数据预处理模块
from sklearn.preprocessing import LabelEncoder #编码转换
from sklearn.preprocessing import StandardScaler #归一化
from sklearn.model_selection import StratifiedShuffleSplit #分层抽样
from sklearn.model_selection import train_test_split #数据分区
from sklearn.decomposition import PCA #主成分分析 (降维)
6.1.4 分类算法
from sklearn.ensemble import RandomForestClassifier #随机森林
from sklearn.svm import SVC,LinearSVC #支持向量机
from sklearn.linear_model import LogisticRegression #逻辑回归
from sklearn.neighbors import KNeighborsClassifier #KNN算法
from sklearn.cluster import KMeans #K-Means 聚类算法
from sklearn.naive_bayes import GaussianNB #朴素贝叶斯
from sklearn.tree import DecisionTreeClassifier #决策树
6.1.5 分类算法--集成学习
import xgboost as xgb
from xgboost import XGBClassifier
from catboost import CatBoostClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
6.1.6 模型评估
from sklearn.metrics import classification_report,precision_score,recall_score,f1_score #分类报告
from sklearn.metrics import confusion_matrix #混淆矩阵
from sklearn.metrics import silhouette_score #轮廓系数(评价k-mean聚类效果)
from sklearn.model_selection import GridSearchCV #交叉验证
from sklearn.metrics import make_scorer
from sklearn.ensemble import VotingClassifier #投票
6.1.7 忽略警告
import warnings
warnings.filterwarnings('ignore')
6.2 读取数据
df=pd.read_csv(r'C:\\Users\\Think\\Desktop\\刻意练习数据\\电信数据集\\Customer-Churn.csv',header=0)
#预览数据
df.head()
#查看数据大小
df.shape
#查看数据数据及分布
df.describe()
这里安利一下spyder编辑器,下图是这个编辑器的界面。编程过程中,有赋值变量的操作,该编辑器都会在右上角呈现,双击一下,就可以像在Execel上查看数据,非常方便。
查看该数据集的详情。

6.3 数据清洗
6.3.1 缺失值处理
#查看缺失值
df.isnull().sum()
注:缺失值的数据类型是 float 类型。一旦有变量的数据类型转换成float 类型,需再次查看缺失值。

6.3.2 重复值处理
#查看重复值
df.duplicated().sum()
【输出】
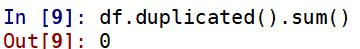
6.3.3 数值类型转换
#查看数据类型
df.info()
【输出】
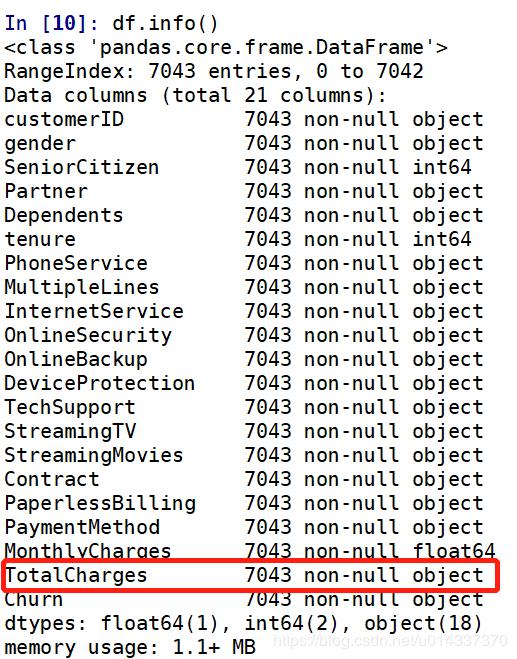
TotalCharages总费用应该跟MonthlvCharges是同一个数据类型(float64)。故需将TotalCharages由object转换成float64,且需要再次查看缺失值。
#总费用 TotalCharges 该列的数据类型应是float64,不是object
# df['TotalCharges'].astype('float64')
# 此处用“astype”转化数据类型报错 “could not convert string to float”
#改用强制转化 convert_numeric=True
df['TotalCharges']=df['TotalCharges'].convert_objects(convert_numeric=True)
df['TotalCharges'].dtype
输出如下:

再次查看缺失值:
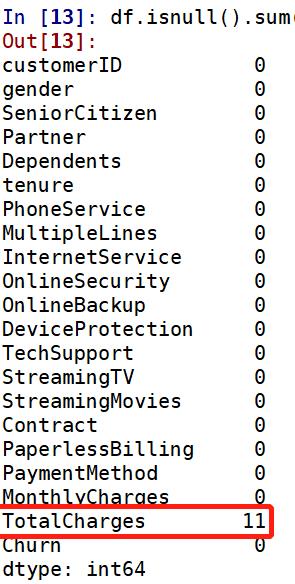
TotalCharges列有11个缺失值,处理缺失值的原则是尽量填充,最后才是删除。缺失值填充的原则:
分类型数据:众数填充
数值型数据:正态分布,均值/中位数填充;偏态分布,中位数填充。
TotalCharges列是数值型数据,先画直方图查看数据分布形态。
#分别作直方图:全部客户类型、流失客户类型、留存客户类型
plt.figure(figsize=(14,5))
plt.subplot(1,3,1)
plt.title('全部客户的总付费直方图')
sns.distplot(df['TotalCharges'].dropna())
plt.subplot(1,3,2)
plt.title('流失客户的总付费直方图')
sns.distplot(df[df['Churn']=='Yes']['TotalCharges'].dropna())
plt.subplot(1,3,3)
plt.title('留存客户的总付费直方图')
sns.distplot(df[df['Churn']=='No']['TotalCharges'].dropna())
结果如下:
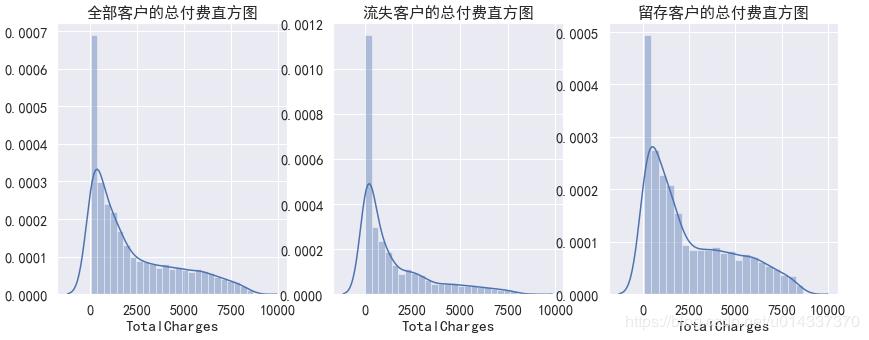
从三个直方图看,该列数据是偏态分布,故选择中位数填充。
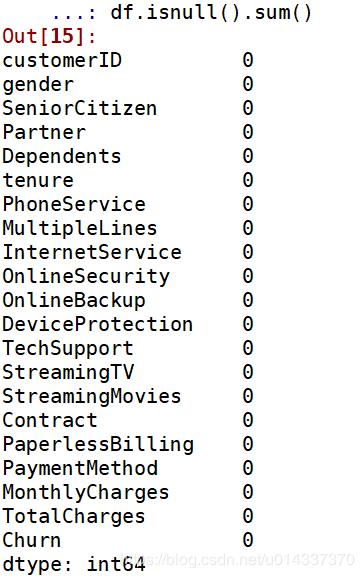
df.fillna({'TotalCharges':df['TotalCharges'].median()},inplace=True)
#再次确认是否还有空值
df.isnull().sum()
结果如下:
6.4 查看样本分布
研究对象'Churn'列重新编码“Yes”=1,“No”=0。重新编码有下面两种方法。
方法一:replace
df['Churn'].replace(to_replace = 'Yes', value = 1,inplace = True)
df['Churn'].replace(to_replace = 'No', value = 0,inplace = True)
方法二:map函数
df['Churn']=df['Churn'].map({'Yes':1,'No':0})
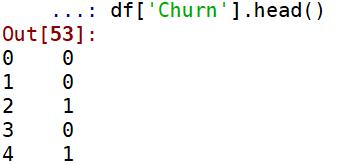
预览数据:
df['Churn'].head()
结果如下:
绘制饼图,查看流失客户占比。
churn_value=df["Churn"].value_counts()
labels=df["Churn"].value_counts().index
plt.figure(figsize=(7,7))
plt.pie(churn_value,labels=labels,colors=["b","w"], explode=(0.1,0),autopct='%1.1f%%', shadow=True)
plt.title("流失客户占比高达26.5%")
plt.show()
结果如下:
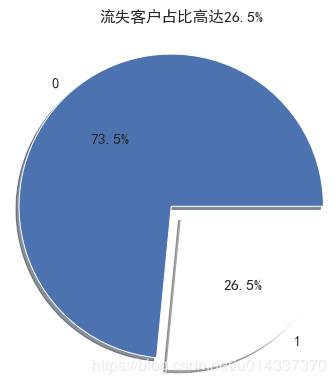
【分析】:流失客户样本占比26.5%,留存客户样本占比73.5%,明显的“样本不均衡”。
解决样本不均衡有以下方法可以选择:
分层抽样
过抽样
欠抽样
7.特征选择
提取特征
feature=df.iloc[:,1:20]
7.1 整数编码
查看变量间的两两相关性
#重新编码
corr_df = feature.apply(lambda x: pd.factorize(x)[0])
corr_df.head()
#相关性矩阵
corr=corr_df.corr()
corr
结果如下:
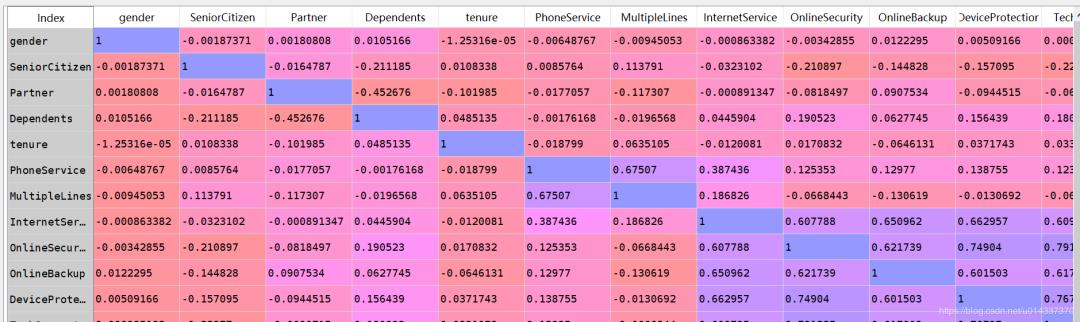
相关性矩阵可视化
#绘制热力图观察变量之间的相关性强弱
plt.figure(figsize=(15,12))
ax = sns.heatmap(corr, xticklabels=corr.columns, yticklabels=corr.columns,
linewidths=0.2, cmap="RdYlGn",annot=True)
plt.title("Correlation between variables")
结果如下:
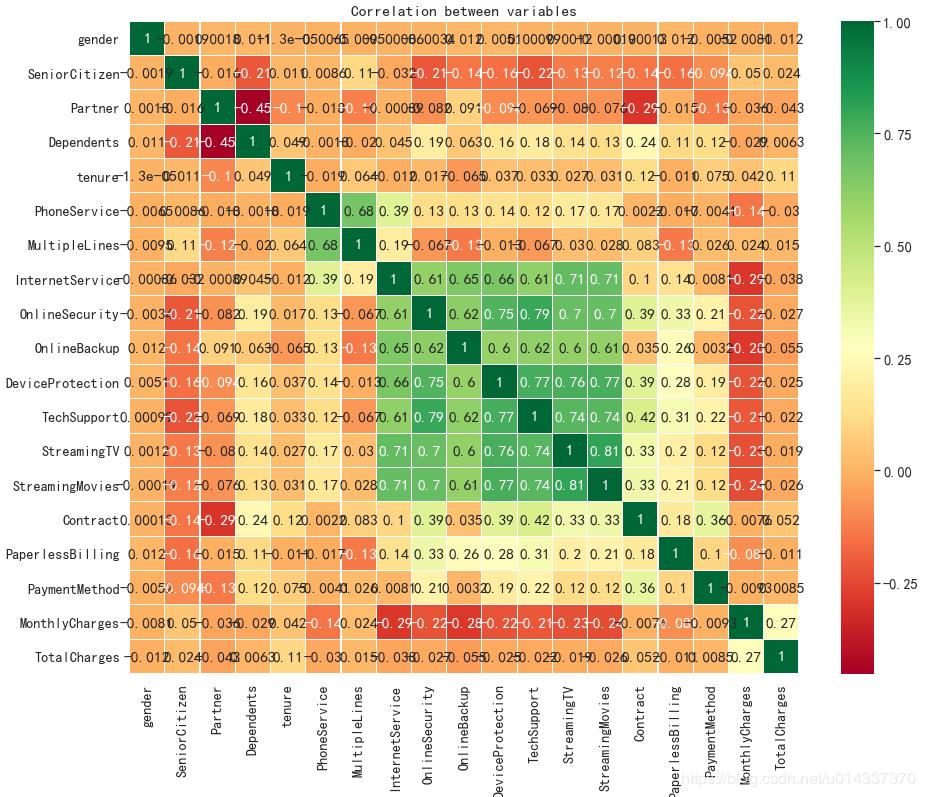
【分析】:从热力图来看,互联网服务、网络安全、在线备份、设备维护服务、技术支持服务、开通网络电视服务、开通网络电影之间相关性很强,且是正相关。电话服务和多线业务之间也存在很强的正相关关系。
7.2 独热编码
查看研究对象"Churn"与其他变量下的标签相关性。独热编码,可以将分类变量下的标签转化成列
df_onehot = pd.get_dummies(df.iloc[:,1:21])
df_onehot.head()
结果如下:

绘图查看用户流失('Churn')与各个维度之间的关系
plt.figure(figsize=(15,6))
df_onehot.corr()['Churn'].sort_values(ascending=False).plot(kind='bar')
plt.title('Correlation between Churn and variables ')
结果如下:
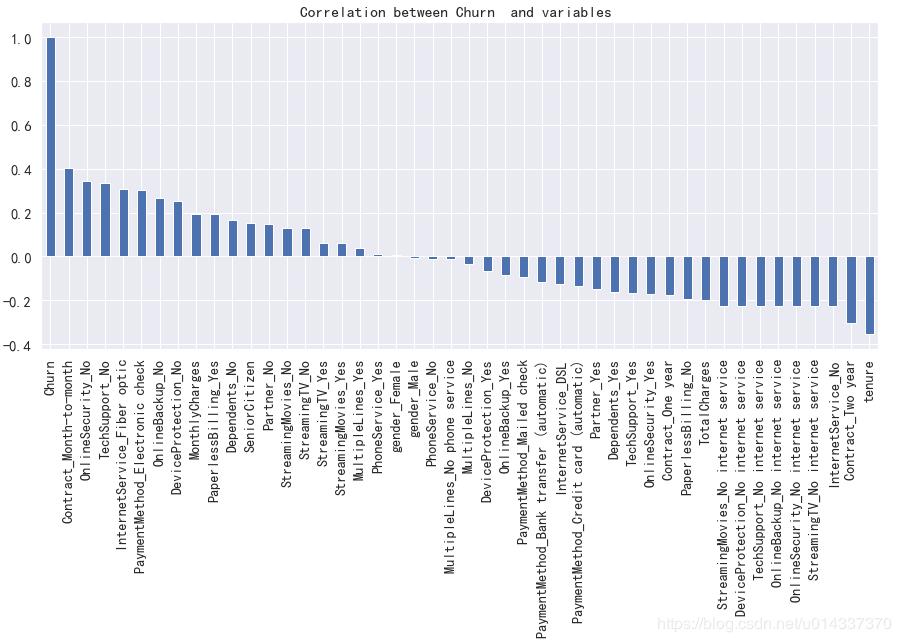
【分析】:从图看gender(性别)、PhoneService(电话服务)相关性几乎为0,故两个维度可以忽略。
['SeniorCitizen','Partner','Dependents', 'Contract',MultipleLines,'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection','TechSupport', 'StreamingTV', 'StreamingMovies','PaperlessBilling','PaymentMethod'] 等都有较高的相关性,将以上维度合并成一个列表kf_var,然后进行频数比较。
kf_var=list(df.columns[2:5])
for var in list(df.columns[7:18]):
kf_var.append(var)
print('kf_var=',kf_var)
结果如下:

8.统计分析
8.1 频数分布比较
8.1.1 卡方检验
组间有显著性差异,频数分布比较才有意义,否则可能会做无用功。"卡方检验",就是提高频数比较结论可信度的统计方法。
#分组间确实是有显著性差异,频数比较的结论才有可信度,故需进行”卡方检验“
from scipy.stats import chi2_contingency #统计分析 卡方检验
#自定义卡方检验函数
def KF(x):
df1=pd.crosstab(df['Churn'],df[x])
li1=list(df1.iloc[0,:])
li2=list(df1.iloc[1,:])
kf_data=np.array([li1,li2])
kf=chi2_contingency(kf_data)
if kf[1]<0.05:
print('Churn by {} 的卡方临界值是{:.2f},小于0.05,表明{}组间有显著性差异,可进行【交叉分析】'.format(x,kf[1],x),'\\n')
else:
print('Churn by {} 的卡方临界值是{:.2f},大于0.05,表明{}组间无显著性差异,不可进行交叉分析'.format(x,kf[1],x),'\\n')
#对 kf_var进行卡方检验
print('kf_var的卡方检验结果如下:','\\n')
print(list(map(KF, kf_var)))
kf_var的卡方检验结果如下:
Churn by SeniorCitizen 的卡方临界值是0.00,小于0.05,表明SeniorCitizen组间有显著性差异,可进行【交叉分析】
Churn by Partner 的卡方临界值是0.00,小于0.05,表明Partner组间有显著性差异,可进行【交叉分析】
Churn by Dependents 的卡方临界值是0.00,小于0.05,表明Dependents组间有显著性差异,可进行【交叉分析】
Churn by MultipleLines 的卡方临界值是0.99,大于0.05,表明MultipleLines组间无显著性差异,不可进行交叉分析
Churn by InternetService 的卡方临界值是0.00,小于0.05,表明InternetService组间有显著性差异,可进行【交叉分析】
Churn by OnlineSecurity 的卡方临界值是0.00,小于0.05,表明OnlineSecurity组间有显著性差异,可进行【交叉分析】
Churn by OnlineBackup 的卡方临界值是0.00,小于0.05,表明OnlineBackup组间有显著性差异,可进行【交叉分析】
Churn by DeviceProtection 的卡方临界值是0.00,小于0.05,表明DeviceProtection组间有显著性差异,可进行【交叉分析】
Churn by TechSupport 的卡方临界值是0.00,小于0.05,表明TechSupport组间有显著性差异,可进行【交叉分析】
Churn by StreamingTV 的卡方临界值是0.00,小于0.05,表明StreamingTV组间有显著性差异,可进行【交叉分析】
Churn by StreamingMovies 的卡方临界值是0.00,小于0.05,表明StreamingMovies组间有显著性差异,可进行【交叉分析】
Churn by Contract 的卡方临界值是0.00,小于0.05,表明Contract组间有显著性差异,可进行【交叉分析】
Churn by PaperlessBilling 的卡方临界值是0.00,小于0.05,表明PaperlessBilling组间有显著性差异,可进行【交叉分析】
Churn by PaymentMethod 的卡方临界值是0.00,小于0.05,表明PaymentMethod组间有显著性差异,可进行【交叉分析】
从卡方检验的结果,kf_var包含的特征,组间都有显著性差异,可进行频数比较。
8.1.2 柱形图
频数比较--柱形图
plt.figure(figsize=(20,25))
a=0
for k in kf_var:
a=a+1
plt.subplot(4,4,a)
plt.title('Churn BY '+ k)
sns.countplot(x=k,hue='Churn',data=df)
结果如下:
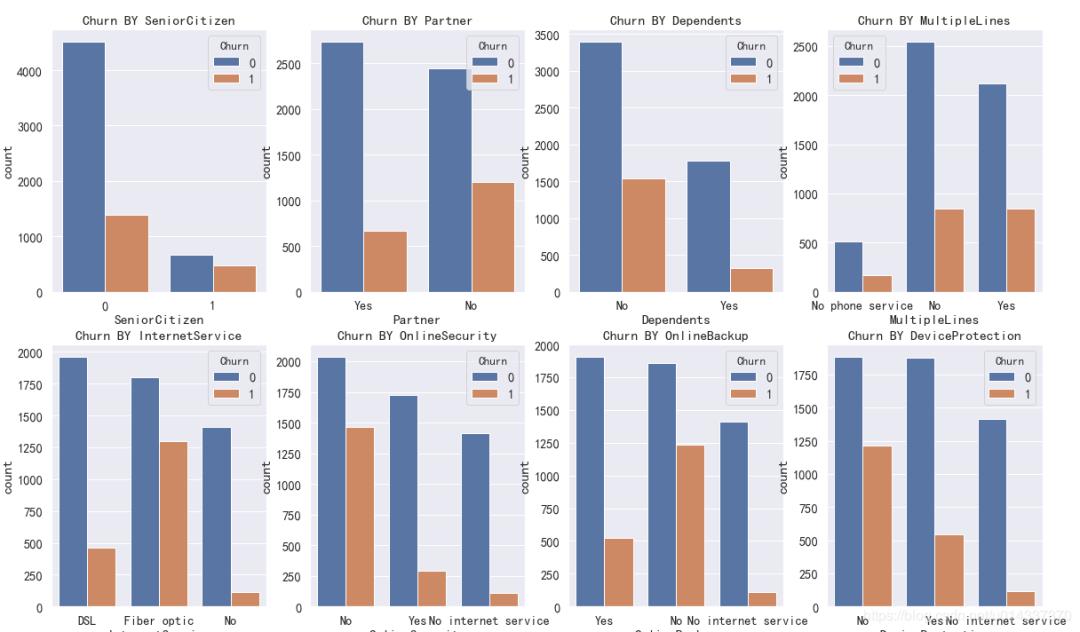
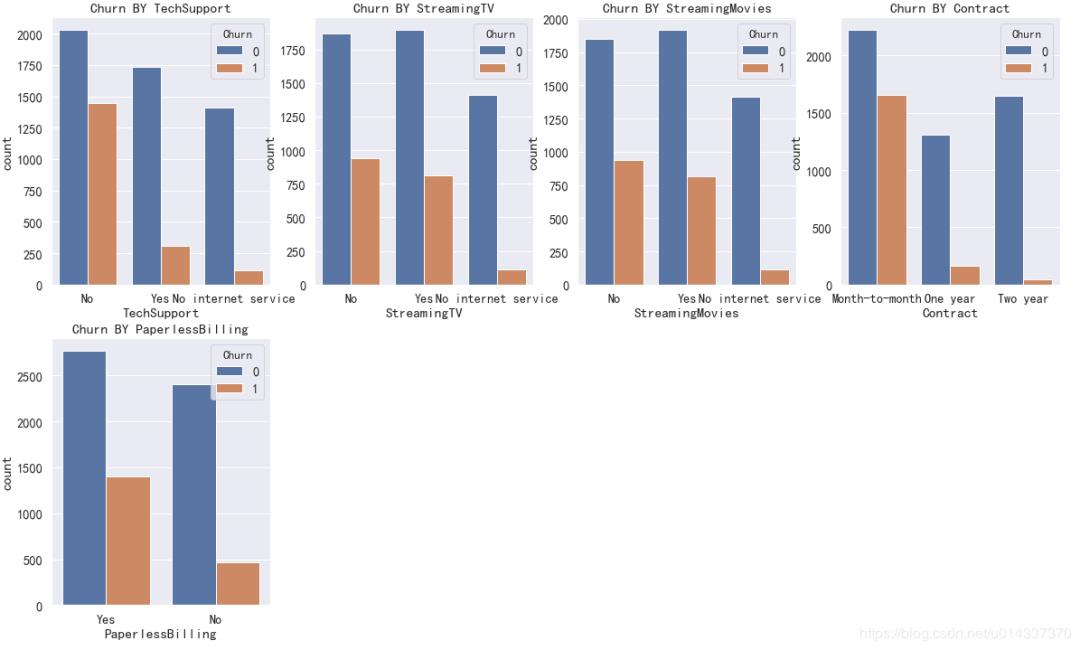
因为PaymentMethod的标签比较长,影响看图,所以单独画。
plt.xticks(rotation=45)
sns.countplot(x='PaymentMethod',hue='Churn',data=df)

可以直接从柱形图去判断对哪个维度对流失客户的影响大吗?不能,因为“样本不均衡”(流失客户样本占比26.5%,留存客户样本占比73.5%),基数不一样,故不能直接通过“频数”的柱形图去分析。解决办法:交叉分析,且作同行百分比('Churn'作为“行”)
8.1.3 交叉分析
print('ka_var列表中的维度与Churn交叉分析结果如下:','\\n')
for i in kf_var:
print('................Churn BY {}...............'.format(i))
print(pd.crosstab(df['Churn'],df[i],normalize=0),'\\n') #交叉分析,同行百分比
ka_var列表中的维度与Churn交叉分析结果如下:

【SeniorCitizen 分析】:年轻用户 在流失、留存,两个标签的人数占比都高。

【Parter 分析】:单身用户更容易流失。

【Denpendents 分析】:经济不独立的用户更容易流失。
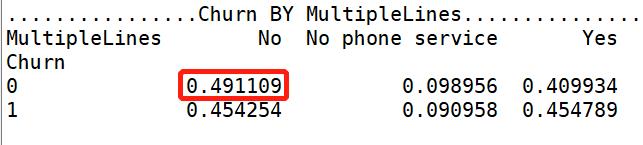
【MultipleLines 分析】:是否开通MultipleLines,对留存和流失都没有明显的促进作用。

【InternetService 分析】:办理了 “Fiber optic 光纤网络”的客户容易流失。

【OnlineSecurity 分析】:没开通“网络安全服务”的客户容易流失。

【OnlineBackup 分析】:没开通“在线备份服务”的客户容易流失。

【DeviceProtection 分析】:没开通“设备保护业务”的用户比较容易流失
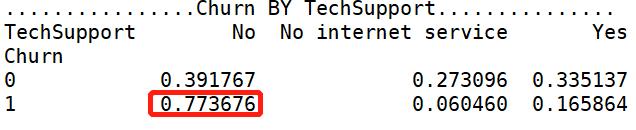
【TechSupport 分析】:没开通“技术支持服务”的用户容易流失。

【StreamingTV 分析】:是否开通“网络电视”服务,对用户留存、流失,没有明显的促进作用。

【StreamingMovies 分析】:是否开通“网络电影”服务,对用户留存、流失,没有明显的促进作用。
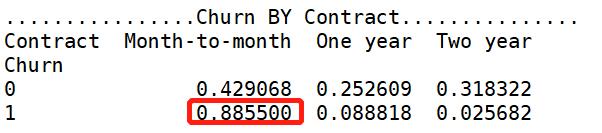
【Contract 分析】逐月签订合同的用户最容易流失。

因为"Churn BY PaymentMethod"打印出来显示不全,故我就从临时表将“交叉表”给截图出来了:

【分析】使用“电子支票”支付的人更容易流失。
8.2 均值比较
组间有显著性差异,均值比较才有意义。显著性检验,先通过了齐性检验,再通过方差分析,最后才能做均值比较。
8.2.0 齐性检验,方差分析
#自定义齐性检验 & 方差分析 函数
def ANOVA(x):
li_index=list(df['Churn'].value_counts().keys())
args=[]
for i in li_index:
args.append(df[df['Churn']==i][x])
w,p=stats.levene(*args) #齐性检验
if p<0.05:
print('警告:Churn BY {}的P值为{:.2f},小于0.05,表明齐性检验不通过,不可作方差分析'.format(x,p),'\\n')
else:
f,p_value=stats.f_oneway(*args) #方差分析
print('Churn BY {} 的f值是{},p_value值是{}'.format(x,f,p_value),'\\n')
if p_value<0.05:
print('Churn BY {}的均值有显著性差异,可进行均值比较'.format(x),'\\n')
else:
print('Churn BY {}的均值无显著性差异,不可进行均值比较'.format(x),'\\n')
对MonthlyCharges、TotalCharges维度分别进行齐性检验和方差分析
print('MonthlyCharges、TotalCharges的齐性检验 和方差分析结果如下:','\\n')
ANOVA('MonthlyCharges')
ANOVA('TotalCharges')
【输出】:MonthlyCharges、TotalCharges的齐性检验 和方差分析结果如下:
警告:Churn BY MonthlyCharges的P值为0.00,小于0.05,表明齐性检验不通过,不可作方差分析
警告:Churn BY TotalCharges的P值为0.00,小于0.05,表明齐性检验不通过,不可作方差分析
8.3 总结
用户出现以下特征比较容易流失:
SeniorCitizen:青年人
Partner :单身
Dependents :无经济独立
InternetService:开通了 “Fiber optic 光纤网络”
OnlineSecurity:没开通“网络安全服务”
OnlineBackup:没开通“在线备份业务”
DeviceProtection:没开通通了“设备保护业务
TechSupport:没开通“技术支持服务”
Contract:“按月”签订合同方式
PaperlessBilling:开通电子账单
PaymentMethod:使用“电子支票”支付的人
我们可以在SQL(数据库)上找有以上特征的客户,进行精准营销,即可以降低用户流失。虽然特征选得越多,越精确,但覆盖的人群也会越少。故,我们还需要计算“特征”的【重要性】,将最为重要的几个特征作为筛选条件。
计算特征的【重要性】,是“分类视角”,接下来我们会挑选常见的分类模型,进行批量训练,然后挑出得分最高的模型,进一步计算“特征重要性”。
9.特征工程
9.1 提取特征
有前面的流失率与各个维度的相关系数柱状图可知:流失率与gender(性别)、PhoneService(电话服务)相关性几乎为0,可以筛选掉,而customerID是随机数,不影响建模,故可以筛选掉。最终得到特征 churn_var
churn_var=df.iloc[:,2:20]
churn_var.drop("PhoneService",axis=1, inplace=True)
churn_var.head()
结果如下:

9.2 处理“量纲差异大”
“MonthlyCharges"、"TotalCharges"两个特征跟其他特征相比,量纲差异大。
处理量纲差异大,有两种方法:
标准化
离散化
以上两种方法,哪个能让模型精度提高,就选哪个。根据模型的最后得分,我选了“离散化”来处理量纲差异大。
9.2.1 标准化
scaler = StandardScaler(copy=False)
scaler.fit_transform(churn_var[['MonthlyCharges','TotalCharges']]) #fit_transform拟合数据
churn_var[['MonthlyCharges','TotalCharges']]=scaler.transform(churn_var[['MonthlyCharges','TotalCharges']]) #transform标准化
print(churn_var[['MonthlyCharges','TotalCharges']].head() )#查看拟合结果
【输出】

9.2.2 特征离散化
特征离散化后,模型易于快速迭代,且模型更稳定。
1、处理'MonthlyCharges':
#查看'MonthlyCharges'列的4分位
churn_var['MonthlyCharges'].describe()
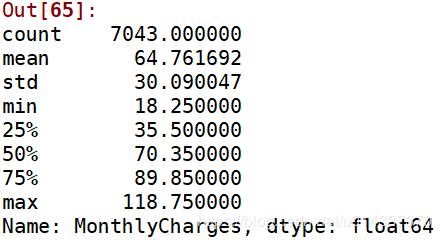
离散操作 18.25=<churn_var['MonthlyCharges']<=35.5,标记 “1” 35.5<churn_var['MonthlyCharges']<=70.35,标记 “2” 70.35<churn_var['MonthlyCharges']<=89.85,标记 “3” 89.85=<churn_varf['MonthlyCharges']<=118.75,标记“4”
#用四分位数进行离散
churn_var['MonthlyCharges']=pd.qcut(churn_var['MonthlyCharges'],4,labels=['1','2','3','4'])
churn_var['MonthlyCharges'].head()
结果如下:
2、处理'TotalCharges':
#查看'TotalCharges'列的4分位
churn_var['TotalCharges'].describe()
结果如下:
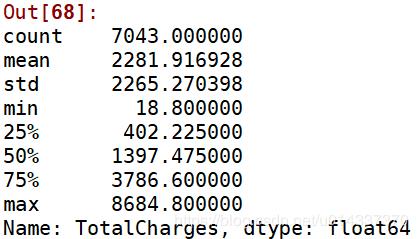
离散操作:18=<churn_var['TotalCharges']<=402,标记 “1” 402<churn_var['TotalCharges']<=1397,标记 “2” 1397<churn_var['TotalCharges']<=3786,标记 “3” 3786<churn_var['TotalCharges']<=8684,标记 “4”
#用四分位数进行离散
churn_var['TotalCharges']=pd.qcut(churn_var['TotalCharges'],4,labels=['1','2','3','4'])
churn_var['TotalCharges'].head()
【输出】

9.3 分类数据转换成“整数编码”
9.3.1 查看churn_var中分类变量的label(标签)
#自定义函数获取分类变量中的label
def Label(x):
print(x,"--" ,churn_var[x].unique())
#筛选出数据类型为“object”的数据点
df_object=churn_var.select_dtypes(['object'])
print(list(map(Label,df_object)))
结果如下:
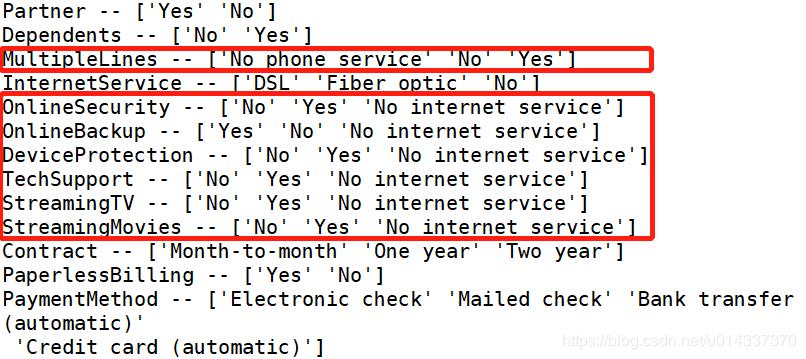

通过同行百分比的“交叉分析”发现,label “No internetserive”的人数占比在以下特征[OnlineSecurity,OnlineBackup,DeviceProtection,TechSupport,StreamingTV,StreamingTV]都是惊人的一致,故我们可以判断label “No internetserive”不影响流失率。因为这6项增值服务,都是需要开通“互联网服务”的基础上才享受得到的。不开通“互联网服务”视为没开通这6项增值服务,故可以将 6个特正中的“No internetserive” 并到 “No”里面。
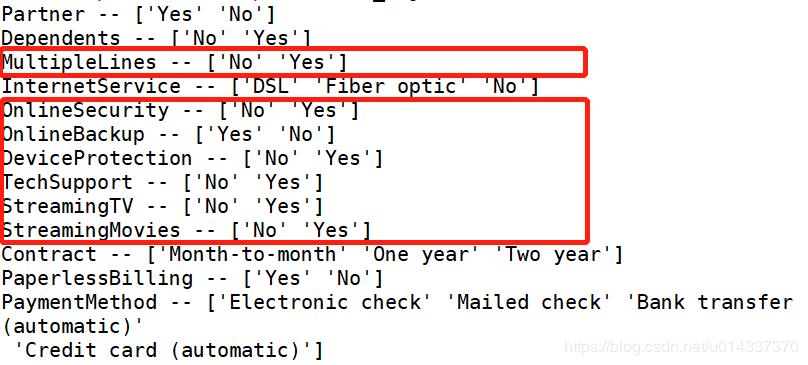
churn_var.replace(to_replace='No internet service',value='No',inplace=True)
而特征MultipleLines的“ No phoneservice”在流失客户、留存客户样本中的人数占比几乎接近,且比较少,故可以将“ No phoneservice”并到“No”。
churn_var.replace(to_replace='No phone service',value='No',inplace=True)
df_object=churn_var.select_dtypes(['object'])
print(list(map(Label,df_object.columns)))
结果如下:
9.3.2 整数编码
整数编码的方法有两种:
1、sklearn中的LabelEncoder()
2、pandas中的factorize 此处选用 LabelEncoder()
def labelencode(x):
churn_var[x] = LabelEncoder().fit_transform(churn_var[x])
for i in range(0,len(df_object.columns)):
labelencode(df_object.columns[i])
print(list(map(Label,df_object.columns)))
结果如下:

9.4 处理“样本不均衡”
分拆变量
x=churn_var
y=df['Churn'].values
print('抽样前的数据特征',x.shape)
print('抽样前的数据标签',y.shape)
【输出】 抽样前的数据特征 (7043, 17) 抽样前的数据标签 (7043,)
处理样本不均衡常用的方式有三种:
分层抽样
过抽样
欠抽样
笔者先后尝试了“分层抽样”和“欠抽样”,前者最终得到的模型中精度最高的是0.63,而后者最终得到的模型中精度最低是0.78,最高是0.84。所以说“抽样方式”的选择极为重要,大家要在这里多试错。
分层抽样
sss=StratifiedShuffleSplit(n_splits=5, test_size=0.2, random_state=0)
print(sss)
print("训练数据和测试数据被分成的组数:",sss.get_n_splits(x,y))
# 分拆训练集和测试集
for train_index, test_index in sss.split(x, y):
print("train:", train_index, "test:", test_index)
x_train,x_test=x.iloc[train_index], x.iloc[test_index]
y_train,y_test=y[train_index], y[test_index]
“过抽样”让模型精度更高,故我选“过抽样”。
from imblearn.over_sampling import SMOTE
model_smote=SMOTE()
x,y=model_smote.fit_sample(x,y)
x=pd.DataFrame(x,columns=churn_var.columns)
#分拆数据集:训练集 和 测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=0)
输出数据集大小
print('过抽样数据特征:', x.shape,
'训练数据特征:',x_train.shape,
'测试数据特征:',x_test.shape)
print('过抽样后数据标签:', y.shape,
' 训练数据标签:',y_train.shape,
' 测试数据标签:',y_test.shape)
【输出】
过抽样后数据特征:(10348, 17) 训练数据特征:(7243, 17) 测试数据特征:(3105, 17) 过抽样后数据标签:(10348,) 训练数据标签:(7243,) 测试数据标签:(3105,)
10.数据建模
使用分类算法
Classifiers=[["Random Forest",RandomForestClassifier()],
["Support Vector Machine",SVC()],
["LogisticRegression",LogisticRegression()],
["KNN",KNeighborsClassifier(n_neighbors=5)],
["Naive Bayes",GaussianNB()],
["Decision Tree",DecisionTreeClassifier()],
["AdaBoostClassifier", AdaBoostClassifier()],
["GradientBoostingClassifier", GradientBoostingClassifier()],
["XGB", XGBClassifier()],
["CatBoost", CatBoostClassifier(logging_level='Silent')]
]
训练模型
Classify_result=[]
names=[]
prediction=[]
for name,classifier in Classifiers:
classifier=classifier
classifier.fit(x_train,y_train)
y_pred=classifier.predict(x_test)
recall=recall_score(y_test,y_pred)
precision=precision_score(y_test,y_pred)
f1score = f1_score(y_test, y_pred)
class_eva=pd.DataFrame([recall,precision,f1score])
Classify_result.append(class_eva)
name=pd.Series(name)
names.append(name)
y_pred=pd.Series(y_pred)
prediction.append(y_pred)
11.模型评估
names=pd.DataFrame(names)
names=names[0].tolist()
result=pd.concat(Classify_result,axis=1)
result.columns=names
result.index=["recall","precision","f1score"]
result
【输出】 特征工程,采用“标准化”处理量纲差异,采用“分层抽样”处理样本不均衡。最终模型精度得分,最高分是0.63,是“朴素贝叶斯”模型

特征工程,采用“离散化”处理量纲差异,采用“过抽样”处理样本不均衡。最终模型精度得分,最高分是0.84,是“XGB”模型

12.基于“XGB”模型输出特征重要性
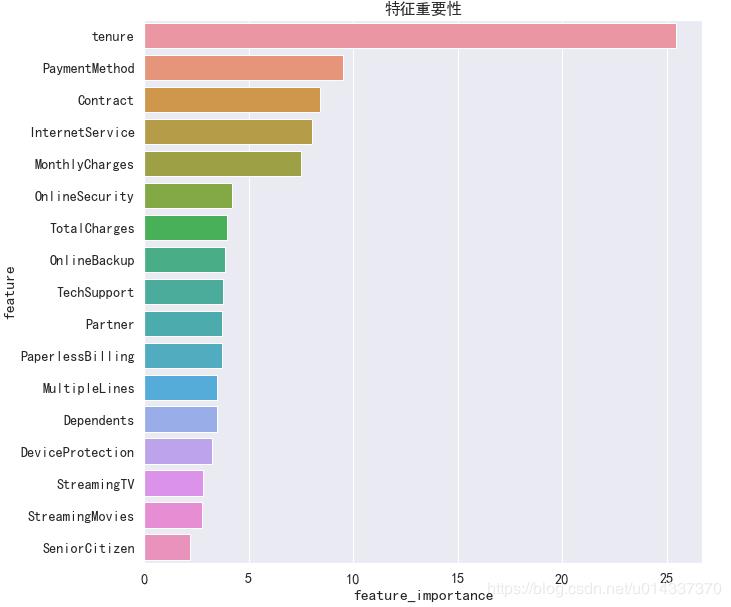
笔者尝试了两个算法分别输出“特征重要性”:CatBoost算法 和 XGB 算法
CatBoost算法
model = CatBoostClassifier()
model.fit(x_train,y_train,eval_set=(x_test, y_test),plot=True)
#特征重要性可视化
catboost=pd.DataFrame(columns=['feature','feature_importance'])
catboost['feature']=model.feature_names_
catboost['feature_importance']=model.feature_importances_
catboost=catboost.sort_values('feature_importance',ascending=False) #降序排列
plt.figure(figsize=(10,10))
plt.title('特征重要性')
sns.barplot(x='feature_importance',y='feature',data=catboost)
【输出】
-XGB 算法
model_xgb= XGBClassifier()
model_xgb.fit(x_train,y_train)
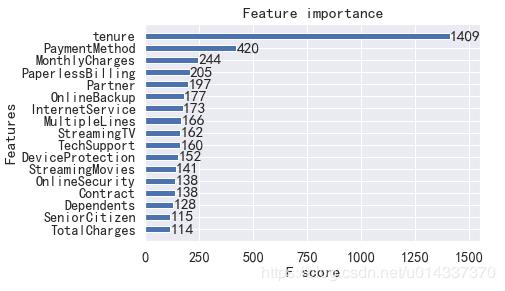
from xgboost import plot_importance
plot_importance(model_xgb,height=0.5)
plt.show()
【输出】
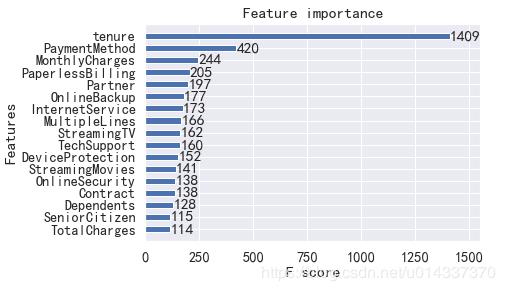
由于 XGB算法精度得分最高,故我们以XGB得到的“特征重要性”进行分析。【分析】
1、第一重要特征:tenure
plt.figure(figsize=(20,4))
sns.countplot(x='tenure',hue='Churn',data=df)
【输出】
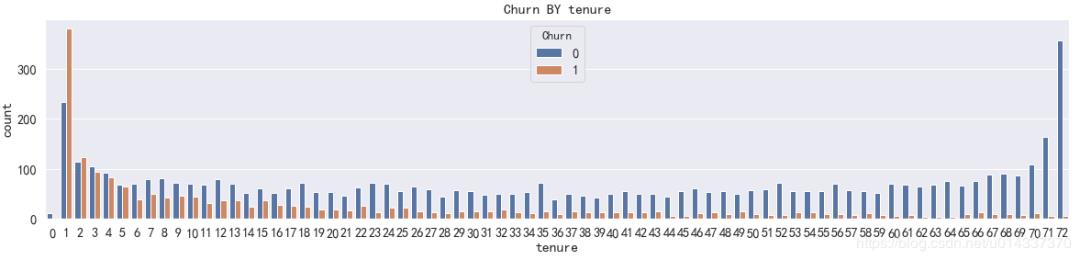
【分析】 由图可知,流失客户集中在1-5号职位,运营团队需要重点关注1-5号职位。
2、第二重要特征:PaymentMethod
【分析】 使用“电子支票”支付的人更容易流失。
3、第三重要特征:MonthlyCharges 查看流失用户、留存用户在付费方面的偏好:'MonthlyCharges'、'TotalCharges',离散化后,可进行卡方检验,然后交叉分析。
卡方检验:'MonthlyCharges'、'TotalCharges'
df['MonthlyCharges-']=churn_var['MonthlyCharges']
df['TotalCharges-']=churn_var['TotalCharges']
print('kf_var的卡方检验结果如下:','\\n')
KF('MonthlyCharges-')
KF('TotalCharges-')
【输出】 kf_var的卡方检验结果如下:
Churn by MonthlyCharges 的卡方临界值是0.00,小于0.05,表明MonthlyCharges组间有显著性差异,可进行【交叉分析】
Churn by TotalCharges 的卡方临界值是0.00,小于0.05,表明TotalCharges组间有显著性差异,可进行【交叉分析】
交叉分析
for i in ['MonthlyCharges','TotalCharges']:
print('................Churn BY {}...............'.format(i))
print(pd.crosstab(df['Churn'],df[i],normalize=0),'\\n')
【输出】

18.25=<churn_var['MonthlyCharges']<=35.5,标记 “1” 35.5<churn_var['MonthlyCharges']<=70.35,标记 “2” 70.35<churn_var['MonthlyCharges']<=89.85,标记 “3” 89.85=<churn_varf['MonthlyCharges']<=118.75,标记“4” 【分析】 月付费70.35--118.75元的用户更容易流失

18=<churn_var['TotalCharges']<=402,标记 “1” 402<churn_var['TotalCharges']<=1397,标记 “2” 1397<churn_var['TotalCharges']<=3786,标记 “3” 3786<churn_var['TotalCharges']<=8684,标记 “4” 【分析】 总付费18--1397元的用户更容易流失
基于"MonthlyCharges"和“TotalCharges”画四分图:求两个维度的均值
print('MonthlyCharges的均值是{:.2f},TotalCharges的均值是{:.2f}'.format(df['MonthlyCharges'].mean(),df['TotalCharges'].mean()))
流失客户四分图:
df_1=df[df['Churn']==1] #流失客户
df_0=df[df['Churn']==0] #留存客户
plt.figure(figsize=(10,10))
sns.scatterplot('MonthlyCharges','TotalCharges',hue='Churn', palette=plt.cm.RdYlBu,data=df_1)
plt.axhline(y=df['TotalCharges'].mean(),ls="-",c="k")
plt.axvline(x=df['MonthlyCharges'].mean(),ls="-",c="green")
【输出】

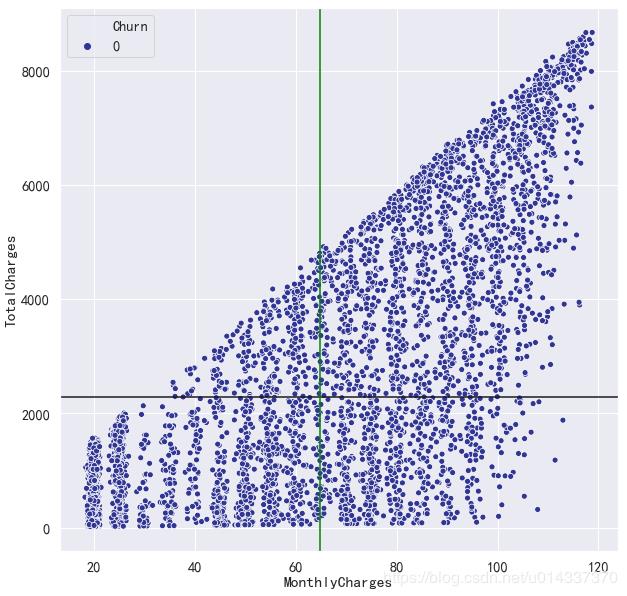
【分析】 四分图的右下区域,流失客户比较集中,即总费用在2281.92元以下,月费用在64.76元以上的客户比较容易流失。
留存客户四分图
plt.figure(figsize=(10,10))
sns.scatterplot('MonthlyCharges','TotalCharges',hue='Churn', palette=plt.cm.RdYlBu_r,data=df_0)
plt.axhline(y=df['TotalCharges'].mean(),ls="-",c="k")
plt.axvline(x=df['MonthlyCharges'].mean(),ls="-",c="green")
【输出】
【结论】 综合“ 统计分析” 和 “XGB算法输出特征重要性” 得出流失客户有以下特征(依特征重要性从大到小排列):
tenure:1-5号职位的用户比较容易流失
PaymentMethod:使用“电子支票”支付的人
MonthlyCharges 、TotalCharges:总费用在2281.92元以下,月费用在64.76元以上的客户比较容易流失
PaperlessBilling:开通电子账单
Partner:单身
OnlineBackup:没开通“在线备份业务”
InternetService:开通了 “Fiber optic 光纤网络”
TechSupport:没开通“技术支持服务”
DeviceProtection:没开通通了“设备保护业务
OnlineSecurity:没开通“网络安全服务”
Contract:“按月”签订合同方式
Dependents:无经济独立
SeniorCitizen :青年人
TotalCharges:总费用在2281.92元以下,月费用在64.76元以上的客户比较容易流失
觉得还不错就给我一个小小的鼓励吧!
以上是关于线上酒店用户流失分析预警的主要内容,如果未能解决你的问题,请参考以下文章