Hadoop2.0高可用集群搭建保姆级教程
Posted Charon_yyy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop2.0高可用集群搭建保姆级教程相关的知识,希望对你有一定的参考价值。
搭载Hadoop2.0高可用集群
说明
主要是记录自己学习Hadoop的过程,梳理自己的思路,可能也会帮助正在配置Hadoop环境同学。
准备
下载好所需要的文件
首先安装好三台虚拟机比如我的命名为node-01、node-02、node-03,并且已经完成了jdk、Hadoop、zookeeper文件的下载(我自己使用的是*vmworkstation、centos6.7、 jdk-8u161、hadoop-2.7.4、Zookeeper-3.4.10)
附上文件链接
链接:https://pan.baidu.com/s/18eEnbsU5Eyl7UcqI-VXlRA
提取码:fzlt
目录准备
为了规范Hadoop集群的配置文件,防止我们产生混淆,我们在根目录下创建几个文件用于存储文件(命名可以自己选择,自己分清就行)
/export/data/ 用与存储数据类
/export/servers/ 用于存储服务类软件
/export/software/ 用于存放安装包文件
虚拟机网络配置(可能会在其他文章中讲到)
1、主机名与ip映射配置
2、网络参数配置
文件的安装
这里我使用的是SecureCRT远程连接工具,连接到node-01、node-02、node-03虚拟机(进行ssh服务配置之后可以避免主节点对其他节点访问时频繁输入代码)
在secureCRT中有好几种上传文件到虚拟机的方法,比如sftp上传以及rz命令(rz命令使用yum install rz -y安装,但由于Centos6停止维护因此无法使用yum源,我们需要重新安装yum源,可以参考其他博主的文章进行安装)
1、安装包的上传(我们只在node-01上操作就可以)
①cd /export/software先进到这个目录下上传安装包
②如果使用rz命令的话可以直接输入rz会弹出如下窗口,然后选择刚才下载的jdk、Hadoop、zookeeper所在的目录进行上传就可以。
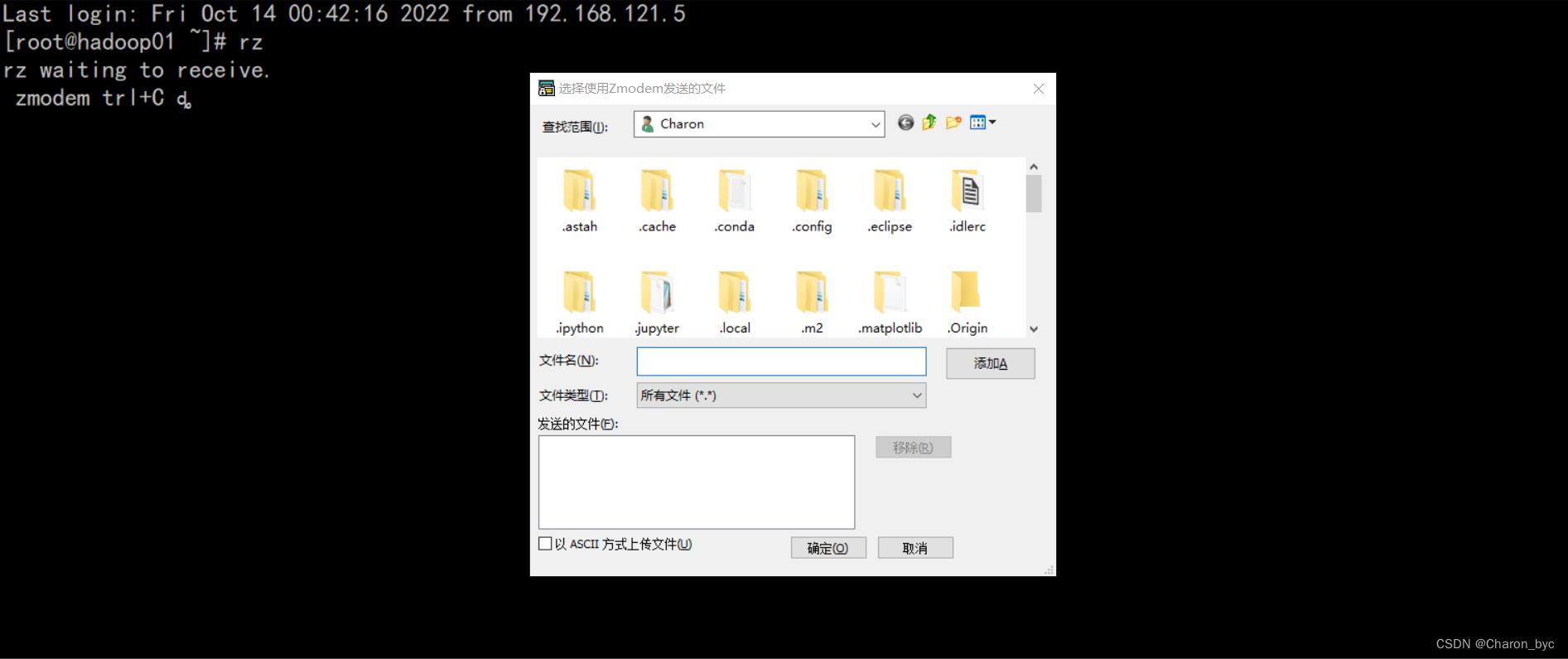 ③使用sftp上传时,点击CRT菜单栏中的选项,点击会话选项,选择X/Y/Zomdem,可以切换到Windows中下载三个安装包的目录中。按住alt+p,会在CRT中弹出一个新的会话,然后使用cd /export/software去切换到我们要上传到Linux的文件目录中,使用pwd可以查看所在Linux目录位置,使用lpwd可以查看Windows所在目录位置,之后使用put jdk-8u161-linux-x64.tar.gz命令将Windows中下载的安装包上传到Linux中 /export/software/ ,其他两个安装包类似方法上传。
③使用sftp上传时,点击CRT菜单栏中的选项,点击会话选项,选择X/Y/Zomdem,可以切换到Windows中下载三个安装包的目录中。按住alt+p,会在CRT中弹出一个新的会话,然后使用cd /export/software去切换到我们要上传到Linux的文件目录中,使用pwd可以查看所在Linux目录位置,使用lpwd可以查看Windows所在目录位置,之后使用put jdk-8u161-linux-x64.tar.gz命令将Windows中下载的安装包上传到Linux中 /export/software/ ,其他两个安装包类似方法上传。
注意:
在安装jdk之前应该先使用rpm -qa|grep java检查系统中是否有其他jdk如果有,就全部删除之后在进行jdk的安装
使用rpm -e --nodeps [jdk的名称]
切记切记把显示的所有jdk全部卸载!!!否则安装不了自己需要的jdk!!!
④上传成功后,在Linux中将安装包进行解压到node-01中,进入到/export/servers/目录下,使用如下命令
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /export/servers/
tar -zxvf hadoop-2.7.4.tar.gz -C /export/servers
tar -zxvf zookeeper-3.4.10.tar.gz -C /export/servers/
⑤如果感觉解压名过长可以进入到cd /export/servers/ 目录中使用mv命令进行重命名
比如
mv jdk1.8.0_161/ jdk
配置环境变量
进入到 /etc目录下使用vi编辑器编辑profile来编辑环境变量
vi /etc/prifile
export JAVA_HOME=/export/servers/jdk 配置jdk系统的环境变量
export HADOOP_HOME=/export/servers/hadoop-2.7.4 配置hadoop的环境变量
export ZK_HOME=/export/servers/zookeeper-3.4.10 配置zookeeper的环境变量
export CLASSPATH=.:$JAVA_HOME/lib/da.jar:$JAVA_HOME/lib/tools.jar
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin: $ ZK_HOME/bin:$PATH
环境变量的验证
使用source /etc/profile指令使配置文件生效
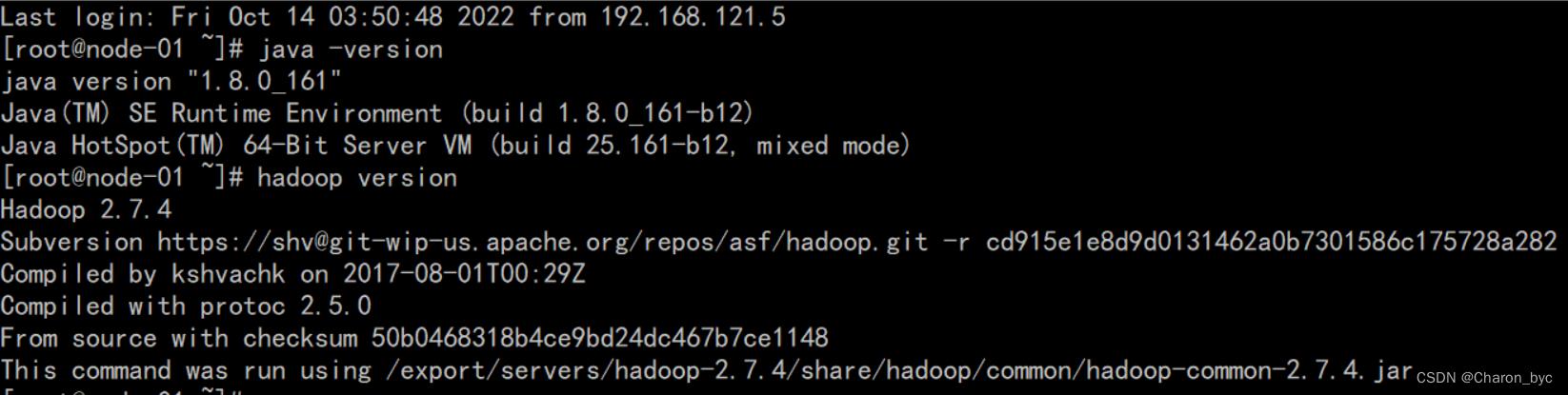
查看我们的版本号
java -version
hadoop version
显示结果如下图表示配置正确
关闭防火墙
因为我们使用的是vmware的虚拟机,是通过系统的内网创建的,关闭防火墙并没有什么安全隐患,而且会避免出现一些问题(具体原因可以自己查一下)
service iptables stop(三台虚拟机都需要关闭)
配置Hadoop高可用集群
修改hadoop-env.sh
由于Hadoop是Java进程所以需要添加jdk,配置hadoop-env.sh文件是设置Hadoop运行时需要的JDK环境变量,我们先进入到主节点node-01解压包下的==/etc/hadoop/==目录下
cd /export/servers/hadoop-2.7.4/etc/hadoop/
export JAVA_HOME=/export/servers/jdk
修改core-site.xm文件
该文件是Hadoop的核心配置文件,同样是在*/export/servers/hadoop-2.7.4/etc/hadoop/*目录下
vi core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.7.4/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>node-01:2181,node-02:2181,node-03:2181</value>
</property>
</configuration>
修改hdfs-site.xml文件
<configuration>
<!-- 设置副本个数 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 设置namenode.name目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/export/data/hadoop/name</value>
</property>
<!-- 设置namenode.data目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/export/data/hadoop/data</value>
</property>
<!-- 开启webHDFS -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
<!-- 在NN和DN上开启WebHDFS (REST API)功能,不是必须 -->
</property>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>node-01:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>node-01:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>node-02:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>node-02:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>
qjournal://node-01:8485;node-02:8485;node-03:8485/ns1
</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/export/data/hadoop/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
修改mapred-site.xml文件
在目录默认没有mapred-site.xml文件但是有mapred-site.xml.template文件,因此我们需要使用cp命令复制文件并重命名为mapred-site.xml。
cp mapred-site.xml.template mapred-site.xml
<configuration>
<!-- 指定MapReduce运行时框架,这里指定在Yarn上,默认是local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml文件
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node-01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node-02</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node-01:2181,node-02:2181,node-03:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改slaves文件
注意在Hadoop3.0以后slaves更名为workers了(我们配置的是Hadoop2.0),该文件是用来记录Hadoop集群所有slaves的节点名称或者是ip,每行存放一个,在配置完SSH免密登陆后,还可以用来一键启动集群所有从节点。
使用vi slaves后删除里面的默认localhost,添加
node-01
node-02
node-03
注意:我们在三台机器上搭载了Hadoop集群,同时在hdfs-site.xml指定了副本数量为3
Zookeeper分布式集群部署
修改myid文件
这是我们的zookeeper集群的参数文件,参数越大,在FastLeaderElection选举leader时所占权重越大,这里我设置node-01、node-02、node-03的参数分别为1、2、3。
首先进入到该目录cd /export/data/zookeeper/zkdata,使用echo添加信息到myid,注意在>后面有一个空格,不要出错,echo会覆盖文件中原信息。
echo 1 > myid
使用cat命令可以查看文件内容cat myid
修改zoo.cfg文件
我们的zookeeper同样解压到了/export/servers目录下,我们进入到Zookeeper解压目录下,找到conf目录
cd /export/servers/zookeeper-3.4.10/conf
在该目录同样默认没有zoo.cfg,我们需要复制zoo_sample.cfg文件并重命名为zoo.cfg
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
修改的内容
#该属性对应的目录是用来存放myid信息跟一些版本,日志,跟服务器唯一的ID信息
dataDir=/export/data/zookeeper/zkdata
#server.后面的是myid赋予每台机器的选举权重
#node-01...是机器的名(ip和机器名映射)
#2888,3888分别是内部默认的通信端口和选举端口
#将下面三行添加到zoo.cfg最下面
server.1=node-01:2888:3888
server.2=node-02:2888:3888
server.3=node-03:2888:3888
分发配置文件
1、使用scp-r命令递归复制整个export目录到node-02、node-03的根目录下,并将环境变量都分别分发到node-02、node-03
scp -r /export/ node-02:/
scp -r /export/ node-03:/
scp /etc/profile node-02:/etc/profile
scp /etc/profile node-03:/etc/profile
分发完成之后分别在node-02、node-03输入source /etc/profile重新加载环境变量
注意:在使用scp命令分发时,不会覆盖原文件,所以当我们得配置出现错误使,但是已经分发完成了,我们需要进入到虚拟机得目录中,将文件删除掉,然后将配置成功的文件重新进行分发。
2、起初我们在配置myid文件中,给node-01设置的参数为1,然后使用了scp命令将目录分发到了node-02、node-03,因此我们需要修改一下node-02、node-03的myid中的参数值。
在两台机器中执行下面命令:
cd /export/data/zookeeper/zkdata/
在node-02中
echo 2 >myid
cat myid
node-03中
echo 3 >myid
cat myid
启动Hadoop高可用集群
1、首先启动集群各个节点的Zookeeper服务
zkServer.sh start
2、启动集群各个节点监控NameNode的管理日志JournalNode
hadoop-daemon.sh start journalnode
3、在node-01节点格式化NameNode,并将格式化后的目录复制到node-02中,格式化只能在最开始配置时格式化,如果二次格式化,因为在目录dfs.name.dir已经存在了上次产生的文件,因此会使得集群不同步,如果必须进行格式化,应先把日志文件全部删除,包括zookeeper。
hadoop namenode -format
scp -r /export/data/hadoop node-02:/export/data
4、在node-01节点上格式化zkfc(注意事项与上面类似)
hdfs zkfc -formatZK
5、启动dfs、yarn集群
start-dfs.sh
start-yarn.sh
查看集群是否启动
使用jps命令可以查看进程,出现如图所示,集群配置完成。
| 特别说明:我们可以通过分别启动然后使用jps命令查看进程是否已经开启,如果某个进程并没有开启成功,我们就需要对没有配置好的文件进行修改,建议不要一看出错了就重装虚拟机,因为可能还会出错 ! |
以上是关于Hadoop2.0高可用集群搭建保姆级教程的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop 3.1.3 分布式集群搭建,超详细,保姆级教程