大数据Hadoop的HA高可用架构集群部署
Posted jingluodashu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Hadoop的HA高可用架构集群部署相关的知识,希望对你有一定的参考价值。
1 概述
在Hadoop 2.0.0之前,一个Hadoop集群只有一个NameNode,那么NameNode就会存在单点故障的问题,幸运的是Hadoop 2.0.0之后解决了这个问题,即支持NameNode的HA高可用,NameNode的高可用是通过集群中冗余两个NameNode,并且这两个NameNode分别部署到不同的服务器中,其中一个NameNode处于Active状态,另外一个处于Standby状态,如果主NameNode出现故障,那么集群会立即切换到另外一个NameNode来保证整个集群的正常运行,那么接下来本文将重要介绍该如何搭建Hadoop的HA集群。
该环境是在 大数据平台Hadoop的分布式集群环境搭建 的基础上完成的
2 集群HA部署节点列表
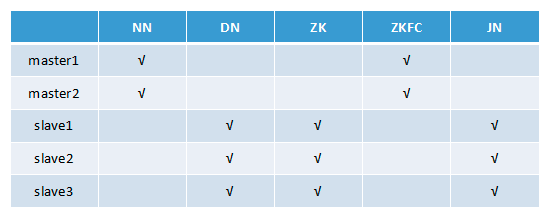
注:Hadoop版本: Hadoop 2.7.5
NN(NameNode 名称节点)、DN(DataNode 数据节点)、ZK(Zookeeper)、ZKFC(ZKFailoverController)、JN(JournalNode 元数据共享节点)、RM(ResourceManager 资源管理器)、DM(DataManager 数据节点管理器)

3 安装Zookeeper集群
(1) 首先在slave1中安装
a)下载zookeeper-3.4.9.tar.gz包
b)解压:tar -zxvf zookeeper-3.4.9.tar.gz
c)cd zookeeper-3.4.9/conf
d)cp zoo_sample.cfg zoo.cfg
e)修改zoo.cfg配置文件
tickTime=2000
dataDir=/home/hadoop/app/zookeeper/data
clientPort=2181
initLimit=10
syncLimit=5
server.1=slave1:2888:3888
server.2=slave2:2888:3888
server.3=slave3:2888:3888(2)拷贝相同的一份zookeeper-3.4.9到slave2、slave3服务
(3)配置Zookeeper的环境变量并分别启动即可完成Zookeeper集群的部署
4 开始配置
(1)修改hdfs-site.xml,内容如下:
<configuration>
<!--HDFS HA的逻辑服务名称配置-->
<property>
<name>dfs.nameservices</name>
<value>masters</value>
</property>
<!--NameNode的唯一标识服务名,注意这里namenodes.masters中的masters必须是上面的dfs.nameservices中的逻辑服务名,下面同理-->
<property>
<name>dfs.ha.namenodes.masters</name>
<value>master1,master2</value>
</property>
<!--NameNode的rpc监听地址-->
<property>
<name>dfs.namenode.rpc-address.masters.master1</name>
<value>master1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.masters.master2</name>
<value>master2:8020</value>
</property>
<!--NameNode的http地址配置-->
<property>
<name>dfs.namenode.http-address.masters.master1</name>
<value>master1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.masters.master2</name>
<value>master2:50070</value>
</property>
<!--NameNode的edits文件的共享地址配置,及JournalNodes的节点配置-->
<property>
<name>dfs.namenode.shared.edits.dir</