大数据Hadoop的HA高可用架构集群部署
Posted linjunwei2017
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Hadoop的HA高可用架构集群部署相关的知识,希望对你有一定的参考价值。
1 概述
在Hadoop 2.0.0之前,一个Hadoop集群只有一个NameNode,那么NameNode就会存在单点故障的问题,幸运的是Hadoop 2.0.0之后解决了这个问题,即支持NameNode的HA高可用,NameNode的高可用是通过集群中冗余两个NameNode,并且这两个NameNode分别部署到不同的服务器中,其中一个NameNode处于Active状态,另外一个处于Standby状态,如果主NameNode出现故障,那么集群会立即切换到另外一个NameNode来保证整个集群的正常运行,那么接下来本文将重要介绍该如何搭建Hadoop的HA集群。
该环境是在上篇:https://my.oschina.net/feinik/blog/1621000 大数据平台Hadoop的分布式集群环境搭建 的基础上完成的
2 集群HA部署节点列表
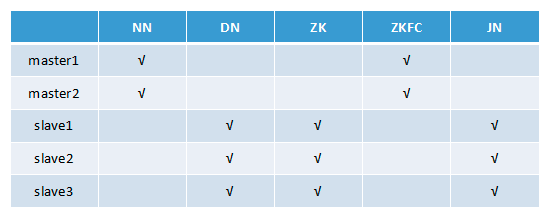
注:Hadoop版本: Hadoop 2.7.5
NN(NameNode 名称节点)、DN(DataNode 数据节点)、ZK(Zookeeper)、ZKFC(ZKFailoverController)、JN(JournalNode 元数据共享节点)、RM(ResourceManager 资源管理器)、DM(DataManager 数据节点管理器)
3 安装Zookeeper集群
(1) 首先在slave1中安装
a)下载zookeeper-3.4.9.tar.gz包
b)解压:tar -zxvf zookeeper-3.4.9.tar.gz
c)cd zookeeper-3.4.9/conf
d)cp zoo_sample.cfg zoo.cfg
e)修改zoo.cfg配置文件
tickTime=2000 dataDir=/home/hadoop/app/zookeeper/data clientPort=2181 initLimit=10 syncLimit=5 server.1=slave1:2888:3888 server.2=slave2:2888:3888 server.3=slave3:2888:3888
(2)拷贝相同的一份zookeeper-3.4.9到slave2、slave3服务
(3)配置Zookeeper的环境变量并分别启动即可完成Zookeeper集群的部署
4 开始配置
(1)修改hdfs-site.xml,内容如下:
<configuration>
<!--HDFS HA的逻辑服务名称配置-->
<property>
<name>dfs.nameservices</name>
<value>masters</value>
</property>
<!--NameNode的唯一标识服务名,注意这里namenodes.masters中的masters必须是上面的dfs.nameservices中的逻辑服务名,下面同理-->
<property>
<name>dfs.ha.namenodes.masters</name>
<value>master1,master2</value>
</property>
<!--NameNode的rpc监听地址-->
<property>
<name>dfs.namenode.rpc-address.masters.master1</name>
<value>master1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.masters.master2</name>
<value>master2:8020</value>
</property>
<!--NameNode的http地址配置-->
<property>
<name>dfs.namenode.http-address.masters.master1</name>
<value>master1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.masters.master2</name>
<value>master2:50070</value>
</property>
<!--NameNode的edits文件的共享地址配置,及JournalNodes的节点配置-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slave1:8485;slave2:8485;slave3:8485/masters</value>
</property>
<!--指定JournalNode在本地磁盘存放数据的位置-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/app/hadoop-HA/data/journal</value>
</property>
<!--配置将由DFS客户端使用的Java类的名称,以确定哪个NameNode当前正在服务于客户端请求-->
<property>
<name>dfs.client.failover.proxy.provider.masters</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--HA切换时的免密登录的秘钥访问路径配置-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!--开启NameNode失败自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--配置HDFS的DataNode的备份数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/app/hadoop-HA/data/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/app/hadoop-HA/data/hdfs/data</value>
</property>
<!--HDFS访问是否开启权限控制-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
(2)修改core-site.xml文件,内容如下:
<configuration>
<!--这里的masters值需与hdfs-site.xml中的dfs.nameservices配置项的值相同-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://masters</value>
</property>
<!-- 配置hadoop的临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-HA/data/tmp</value>
</property>
<!--Zookeeper服务配置-->
<property>
<name>ha.zookeeper.quorum</name>
<value>slave1:2181,slave2:2181,slave3:2181</value>
</property>
<!--表示客户端连接服务器失败尝试的次数-->
<property>
<name>ipc.client.connect.max.retries</name>
<value>10</value>
</property>
<!--表示客户端每次连接服务器需要等待的毫秒数,默认1s,如不配置则使用start-dfs.sh启动可能会导致NameNode连接JournalNode超时,如果单独一个个节点启动则无需此配置项-->
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
</property>
</configuration>
(3)修改slaves文件,内容如下:
slave1
slave2
slave3
5 初始化集群和启动
(1)分别启动三个JournalNode
$hadoop-daemon.sh start journalnode
(2)在其中一个NameNode节点中初始化NameNode,这里选择master1上的NameNode
$hdfs namenode -format
(3)启动第2步初始化好的NameNode服务
$hadoop-daemon.sh start namenode
(4)在master2服务器中运行下面命令来同步master1上的NameNode的元数据
$hdfs namenode -bootstrapStandby
(5)在其中一个NameNode节点中初始化ZKFC的状态,这里选择master1上的NameNode
$hdfs zkfc -formatZK
(6)启动Hadoop的HA集群
$start-dfs.sh
6 测试是否切换成功
(1)通过浏览器中查看 http:master1:50070 和 http:master2:50070 可以确定哪个NameNode处理激活状态
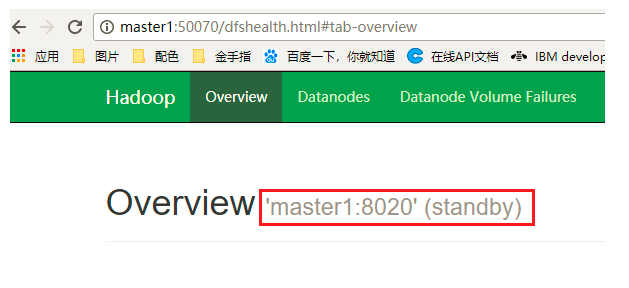
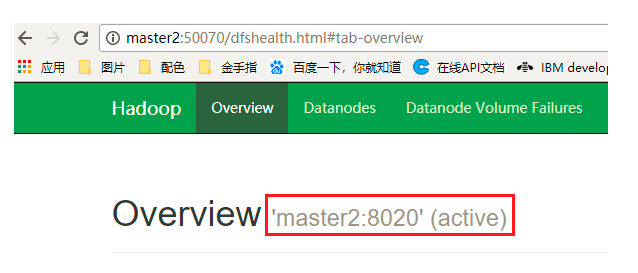
(2)如上图master2的状态为active,则通过kill杀死master2中的NameNode进程,然后查看master1中的NameNode是否由standby状态转换为了active状态,是的话说明切换成功!
注:在测试Hadoop的HA切换中,发现切换失败,在kill掉NameNode的节点中查看日志:
vi hadoop-2.7.5/logs/hadoop-hadoop-zkfc-master2.log
发现报错:PATH=$PATH:/sbin:/usr/sbin fuser -v -k -n tcp 8020 via ssh: bash: fuser: 未找到命令
解决办法:缺少psmisc依赖包,每个NameNode节点服务器上安装即可:
yum install psmisc
参考文献:http://hadoop.apache.org/docs/r2.7.5/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
文章来源:https://my.oschina.net/feinik/blog/1785026
点击链接加入群聊【大数据开发交流3群】:https://jq.qq.com/?_wv=1027&k=5sfIvvJ
以上是关于大数据Hadoop的HA高可用架构集群部署的主要内容,如果未能解决你的问题,请参考以下文章
大数据Hadoop-HA-Federation-3.3.1集群高可用联邦安装部署文档(建议收藏哦)