大数据Hadoop-HA-Federation-3.3.1集群高可用联邦安装部署文档(建议收藏哦)
Posted 笑起来贼好看
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Hadoop-HA-Federation-3.3.1集群高可用联邦安装部署文档(建议收藏哦)相关的知识,希望对你有一定的参考价值。
背景概述
单 NameNode 的架构使得 HDFS 在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NameNode 进程使用的内存可能会达到上百 G,NameNode 成为了性能的瓶颈。因而提出了 namenode 水平扩展方案-- Federation。
Federation 中文意思为联邦,联盟,是 NameNode 的 Federation,也就是会有多个NameNode。多个 NameNode 的情况意味着有多个 namespace(命名空间),区别于 HA 模式下的多 NameNode,它们是拥有着同一个 namespace。
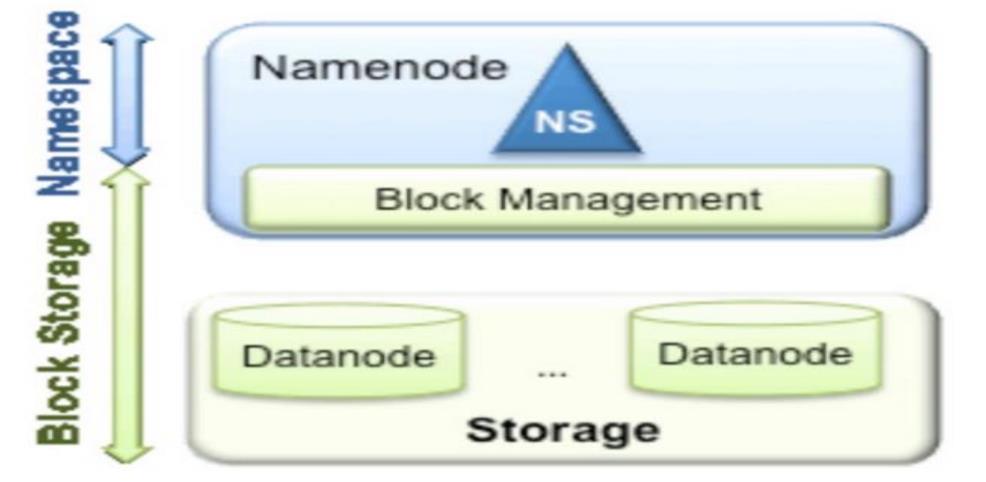
从上图中,我们可以很明显地看出现有的 HDFS 数据管理,数据存储 2 层分层的结构.也就是说,所有关于存储数据的信息和管理是放在 NameNode 这边,而真实数据的存储则是在各个 DataNode 下。而这些隶属于同一个 NameNode 所管理的数据都是在同一个命名空间下的。而一个 namespace 对应一个 block pool。Block Pool 是同一个 namespace 下的 block 的集合.当然这是我们最常见的单个 namespace 的情况,也就是一个 NameNode 管理集群中所有元数据信息的时候.如果我们遇到了之前提到的 NameNode 内存使用过高的问题,这时候怎么办?元数据空间依然还是在不断增大,一味调高 NameNode 的 jvm 大小绝对不是一个持久的办法.这时候就诞生了 HDFS Federation 的机制.
Federation 架构设计
HDFS Federation 是解决 namenode 内存瓶颈问题的水平横向扩展方案。
Federation 意味着在集群中将会有多个 namenode/namespace。这些 namenode 之间是联合的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的 datanode 被用作通用的数据块存储存储设备。每个 datanode 要向集群中所有的namenode 注册,且周期性地向所有 namenode 发送心跳和块报告,并执行来自所有 namenode的命令。
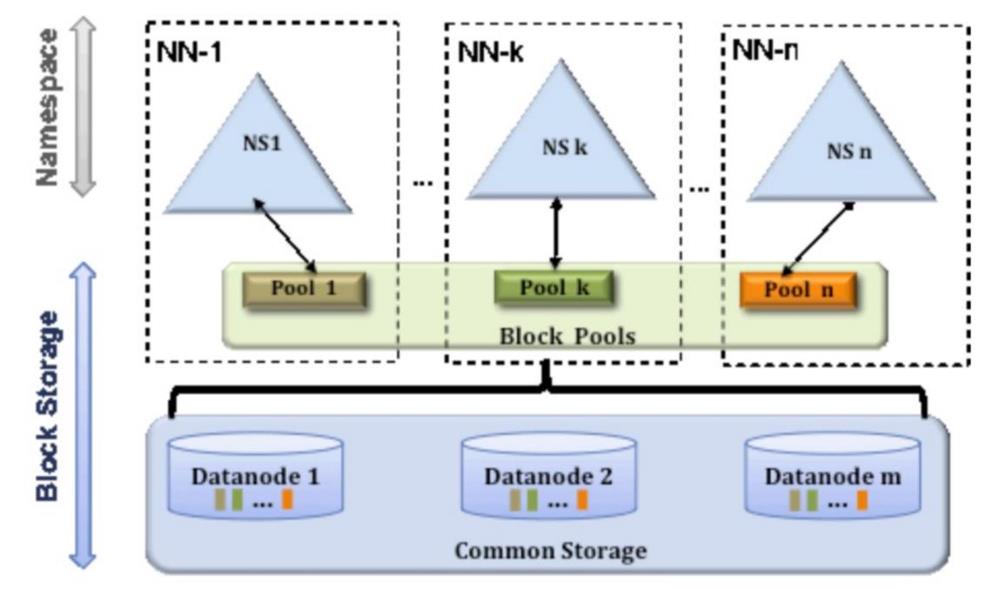
Federation 一个典型的例子就是上面提到的 NameNode 内存过高问题,我们完全可以将上面部分大的文件目录移到另外一个NameNode上做管理. 更重要的一点在于, 这些 NameNode是共享集群中所有的 e DataNode 的 , 它们还是在同一个集群内的 。
这时候在DataNode上就不仅仅存储一个Block Pool下的数据了,而是多个(在DataNode的 datadir 所在目录里面查看 BP-xx.xx.xx.xx 打头的目录)。
多个 NN 共用一个集群里的存储资源,每个 NN 都可以单独对外提供服务。
每个 NN 都会定义一个存储池,有单独的 id,每个 DN 都为所有存储池提供存储。
DN 会按照存储池 id 向其对应的 NN 汇报块信息,同时,DN 会向所有 NN 汇报本地存储可用资源情况。
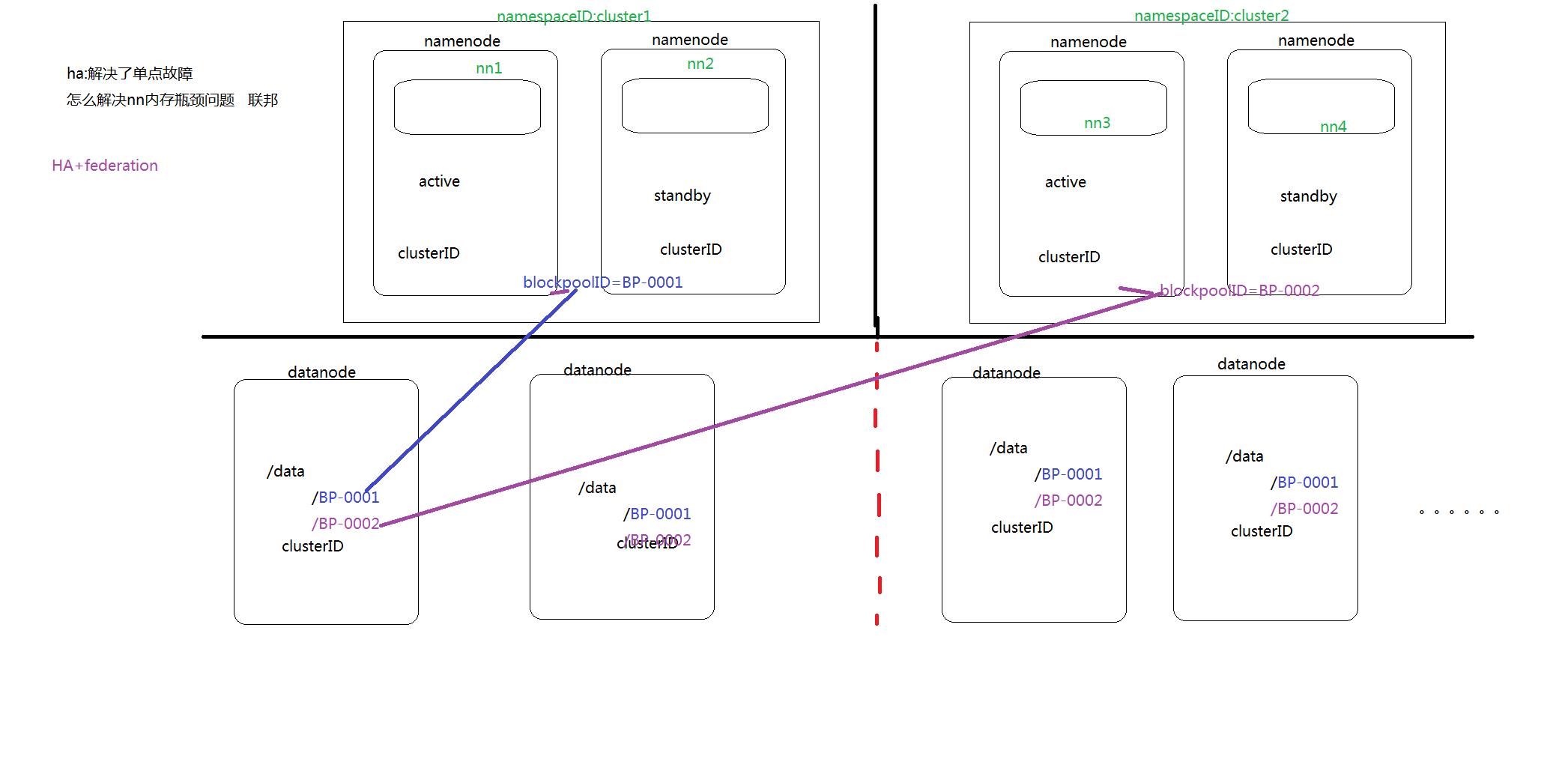
集群部署搭建
主机规划
公共组件
zk: 192.168.1.31:2181,192.168.1.32:2181,192.168.1.33:2181
mysql: 192.168.1.32
HDFS-federation 规划
| cluster | hostname | ip | 机型 | 组件 |
|---|---|---|---|---|
| cluster-a | hadoop-31 | 192.168.1.31 | arm | NameNode/DataNode/JournalNode/DFSZKFailoverController/DFSRouter |
| hadoop-32 | 192.168.1.32 | NameNode/DataNode/JournalNode/DFSZKFailoverController/DFSRouter | ||
| hadoop-33 | 192.168.1.33 | DataNode/JournalNode | ||
| cluster-b | spark-34 | 192.168.1.34 | NameNode/DataNode/JournalNode/DFSZKFailoverController/DFSRouter | |
| spark-35 | 192.168.1.35 | NameNode/DataNode/JournalNode/DFSZKFailoverController/DFSRouter | ||
| spark-36 | 192.168.1.36 | DataNode/JournalNode |
YARN-federation 规划
| cluster | hostname | ip | 机型 | 组件 |
|---|---|---|---|---|
| cluster-a | hadoop-31 | 192.168.1.31 | arm | ResourceManager/NodeManager/Router/ApplicationHistoryServer/JobHistoryServer/WebAppProxyServer |
| hadoop-32 | 192.168.1.32 | ResourceManager/NodeManager | ||
| hadoop-33 | 192.168.1.33 | NodeManager | ||
| spark-34 | 192.168.1.34 | NodeManager | ||
| cluster-b | spark-35 | 192.168.1.35 | ResourceManager/NodeManager/Router/ApplicationHistoryServer/JobHistoryServer/WebAppProxyServer | |
| spark-36 | 192.168.1.36 | ResourceManager/NodeManager |
环境变量配置
hadoop-env.sh 配置
export HADOOP_GC_DIR="/data/apps/hadoop-3.3.1/logs/gc"
if [ ! -d "$HADOOP_GC_DIR" ];then
mkdir -p $HADOOP_GC_DIR
fi
export HADOOP_NAMENODE_JMX_OPTS="-Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.port=1234 -javaagent:/data/apps/hadoop-3.3.1/share/hadoop/jmx_prometheus_javaagent-0.17.2.jar=9211:/data/apps/hadoop-3.3.1/etc/hadoop/namenode.yaml"
export HADOOP_DATANODE_JMX_OPTS="-Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.port=1244 -javaagent:/data/apps/hadoop-3.3.1/share/hadoop/jmx_prometheus_javaagent-0.17.2.jar=9212:/data/apps/hadoop-3.3.1/etc/hadoop/namenode.yaml"
export HADOOP_ROOT_LOGGER=INFO,console,RFA
export SERVER_GC_OPTS="-XX:+UnlockExperimentalVMOptions -XX:+UseG1GC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=512M -XX:ErrorFile=/data/apps/hadoop-3.3.1/logs/hs_err_pid%p.log -XX:+PrintAdaptiveSizePolicy -XX:+PrintFlagsFinal -XX:MaxGCPauseMillis=100 -XX:+UnlockExperimentalVMOptions -XX:+ParallelRefProcEnabled -XX:ConcGCThreads=6 -XX:ParallelGCThreads=16 -XX:G1NewSizePercent=5 -XX:G1MaxNewSizePercent=60 -XX:MaxTenuringThreshold=1 -XX:G1HeapRegionSize=32m -XX:G1MixedGCCountTarget=8 -XX:InitiatingHeapOccupancyPercent=65 -XX:G1OldCSetRegionThresholdPercent=5"
export HDFS_NAMENODE_OPTS="-Xms4g -Xmx4g $SERVER_GC_OPTS -Xloggc:$HADOOP_GC_DIR/namenode-gc-`date +'%Y%m%d%H%M'` $HADOOP_NAMENODE_JMX_OPTS"
export HDFS_DATANODE_OPTS="-Xms4g -Xmx4g $SERVER_GC_OPTS -Xloggc:$HADOOP_GC_DIR/datanode-gc-`date +'%Y%m%d%H%M'` $HADOOP_DATANODE_JMX_OPTS"
export HDFS_ZKFC_OPTS="-Xms1g -Xmx1g $SERVER_GC_OPTS -Xloggc:$HADOOP_GC_DIR/zkfc-gc-`date +'%Y%m%d%H%M'`"
export HDFS_DFSROUTER_OPTS="-Xms1g -Xmx1g $SERVER_GC_OPTS -Xloggc:$HADOOP_GC_DIR/router-gc-`date +'%Y%m%d%H%M'`"
export HDFS_JOURNALNODE_OPTS="-Xms1g -Xmx1g $SERVER_GC_OPTS -Xloggc:$HADOOP_GC_DIR/journalnode-gc-`date +'%Y%m%d%H%M'`"
export HADOOP_CONF_DIR=/data/apps/hadoop-3.3.1/etc/hadoop
yarn-env.sh 配置
export YARN_RESOURCEMANAGER_OPTS="$YARN_RESOURCEMANAGER_OPTS -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.port=2111 -javaagent:/data/apps/hadoop-3.3.1/share/hadoop/jmx_prometheus_javaagent-0.17.2.jar=9323:/data/apps/hadoop-3.3.1/etc/hadoop/yarn-rm.yaml"
export YARN_NODEMANAGER_OPTS="$YARN_NODEMANAGER_OPTS -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.port=2112 -javaagent:/data/apps/hadoop-3.3.1/share/hadoop/jmx_prometheus_javaagent-0.17.2.jar=9324:/data/apps/hadoop-3.3.1/etc/hadoop/yarn-nm.yaml"
export YARN_ROUTER_OPTS="$YARN_ROUTER_OPTS"
配置文件配置
HDFS的配置
cluster-a
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster-a</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.1.31:2181,192.168.1.32:2181,192.168.1.33:2181</value>
</property>
<property>
<name>hadoop.zk.address</name>
<value>192.168.1.31:2181,192.168.1.32:2181,192.168.1.33:2181</value>
</property>
<property>
<name>ha.zookeeper.parent-znode</name>
<value>/hadoop-ha-cluster-a</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>360</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>0</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/apps/hadoop-3.3.1/data</value>
</property>
<!--安全认证初始化的类-->
<property>
<name>hadoop.http.filter.initializers</name>
<value>org.apache.hadoop.security.HttpCrossOriginFilterInitializer</value>
</property>
<!--是否启用跨域支持-->
<property>
<name>hadoop.http.cross-origin.enabled</name>
<value>true</value>
</property>
<property>
<name>hadoop.http.cross-origin.allowed-origins</name>
<value>*</value>
</property>
<property>
<name>hadoop.http.cross-origin.allowed-methods</name>
<value>GET, PUT, POST, OPTIONS, HEAD, DELETE</value>
</property>
<property>
<name>hadoop.http.cross-origin.allowed-headers</name>
<value>X-Requested-With, Content-Type, Accept, Origin, WWW-Authenticate, Accept-Encoding, Transfer-Encoding</value>
</property>
<property>
<name>hadoop.http.cross-origin.max-age</name>
<value>1800</value>
</property>
<property>
<name>hadoop.http.authentication.simple.anonymous.allowed</name>
<value>true</value>
</property>
<property>
<name>hadoop.http.authentication.type</name>
<value>simple</value>
</property>
<property>
<name>hadoop.security.authorization</name>
<value>false</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<property>
<name>io.serializations</name>
<value>org.apache.hadoop.io.serializer.WritableSerialization</value>
</property>
<property>
<name>ipc.client.connect.max.retries</name>
<value>50</value>
</property>
<property>
<name>ipc.client.connection.maxidletime</name>
<value>30000</value>
</property>
<property>
<name>ipc.client.idlethreshold</name>
<value>8000</value>
</property>
<property>
<name>ipc.server.tcpnodelay</name>
<value>true</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>cluster-a,cluster-b</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster-a</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster-b</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster-a.nn1</name>
<value>192.168.1.31:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster-a.nn2</name>
<value>192.168.1.32:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster-a.nn1</name>
<value>192.168.1.31:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster-a.nn2</name>
<value>192.168.1.32:9870</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster-b.nn1</name>
<value>192.168.1.34:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster-b.nn2</name>
<value>192.168.1.35:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster-b.nn1</name>
<value>192.168.1.34:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster-b.nn2</name>
<value>192.168.1.35:9870</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/apps/hadoop-3.3.1/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/apps/hadoop-3.3.1/data/datanode</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/apps/hadoop-3.3.1/data/journal</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://192.168.1.31:8485;192.168.1.32:8485;192.168.1.33:8485/cluster-a</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster-a</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster-b</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.client.failover.random.order</name>
<value>true</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置隔离机制方法-->
<property>
<name>dfs.ha.zkfc.port</name>
<value>8019</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<property>
<name>dfs.ha.nn.not-become-active-in-safemode</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>/data/apps/hadoop-3.3.1/data/checkpoint</value>
</property>
<property>
<name>dfs.datanode.hostname</name>
<value>192.168.1.31</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>20</value>
</property>
<property>
<name>dfs.datanode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>100</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/data/apps/hadoop-3.3.1/etc/hadoop/exclude-hosts</value>
</property>
</configuration>
cluster-b
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster-b</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.1.31:2181,192.168.1.32:2181,192.168.1.33:2181</value>
</property>
<property>
<name>hadoop.zk.address</name>
<value>192.168.1.31:2181,192.168.1.32:2181,192.168.1.33:2181</value>
</property>
<property>
<name>ha.zookeeper.parent-znode</name>
<value>/hadoop-ha-cluster-b</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>360</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>0</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/apps/hadoop-3.3.1/data</value>
</property>
<!--安全认证初始化的类-->
<property>
<name>hadoop.http.filter.initializers</name>
<value>org.apache.hadoop.security.HttpCrossOriginFilterInitializer</value>
</property>
<!--是否启用跨域支持-->
<property>
<name>hadoop.http.cross-origin.enabled</name>
<value>true</value>
</property>
<property>
<name>hadoop.http.cross-origin.allowed-origins</name>
<value>*</value>
</property>
<property>
<name>hadoop.http.cross-origin.allowed-methods</name>
<value>GET, PUT, POST, OPTIONS, HEAD, DELETE</value>
</property>
<property>
<name>hadoop.http.cross-origin.allowed-headers</name>
<value>X-Requested-With, Content-Type, Accept, Origin, WWW-Authenticate, Accept-Encoding, Transfer-Encoding</value>
</property>
<property>
<name>hadoop.http.cross-origin.max-age</name>
<value>1800</value>
以上是关于大数据Hadoop-HA-Federation-3.3.1集群高可用联邦安装部署文档(建议收藏哦)的主要内容,如果未能解决你的问题,请参考以下文章