爬取一些网页图片
Posted Kkh_8686
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取一些网页图片相关的知识,希望对你有一定的参考价值。
爬取一些网页图片
1、随机爬取一个网页:
import requests
# 1、获取图片网页源码
def Get_Source_Page():
url = 'https://pic.netbian.com/index.html'
# 当爬虫程序运行爬网站,若不设置header为任意一个名字,会被有些网站检查出是python爬虫,被禁止访问
headers =
# 'Host':'image.baidu.com'
# 'Cookie':
# 'Referer':
"User-Agent": "hdy"
# 后去网页get请求
response = requests.get(url=url, headers=headers)
# 获取数据内容,并打印(获取网页源码很重要,每个网页都不尽相同,可以根据具体返回的网页信息来截取图片信息)
text = response.text
print(text)
return text
if __name__=='__main__':
Get_Source_Page()
2、运行,出现部分乱码:
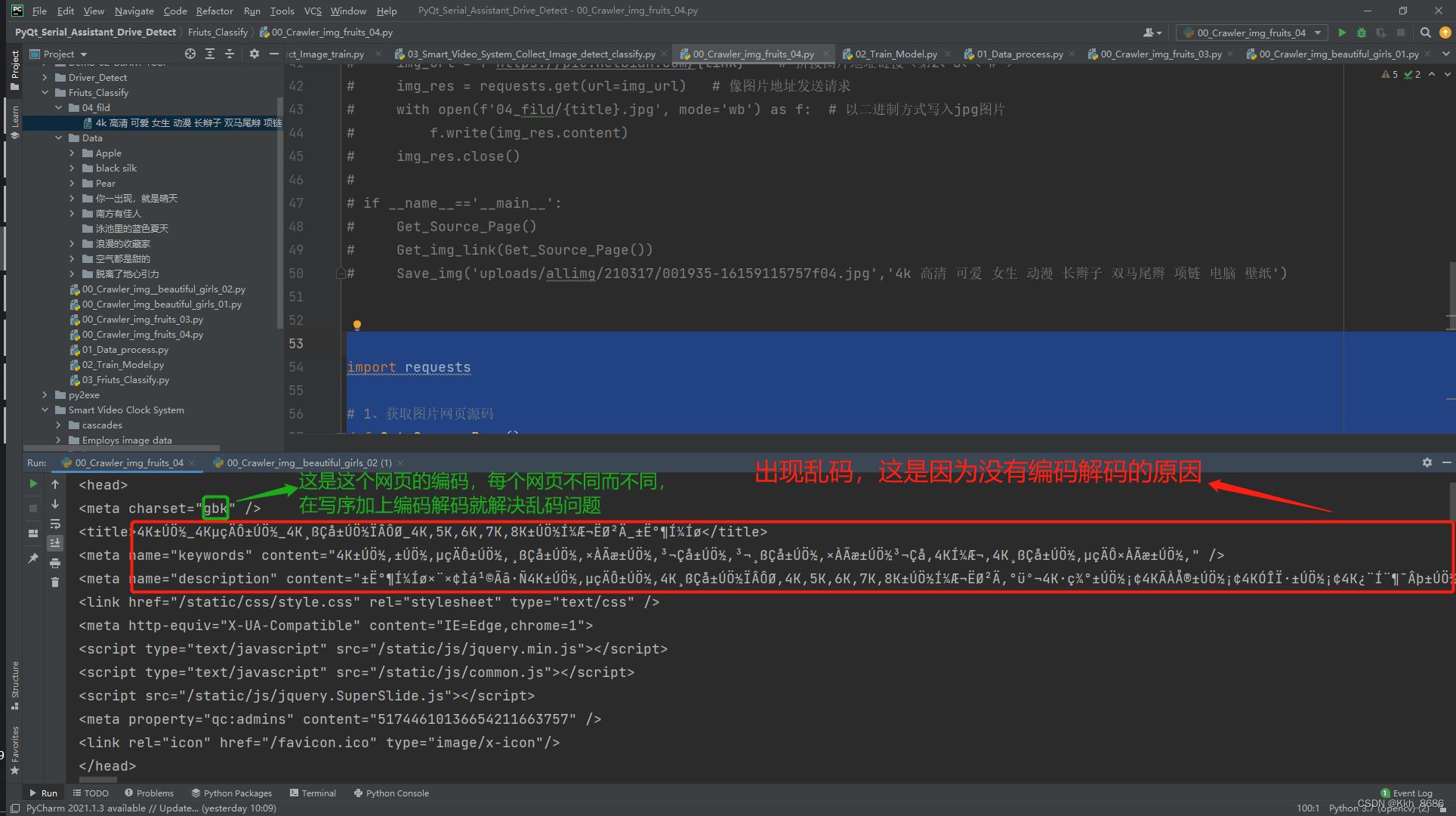
3、将返回的网页进行编码解码,具体什么编码看开头的“meta charset="gbk“,这里是gbk编码。
response.encoding = 'gbk'
4、完整代码:
import requests
# 1、获取图片网页源码
def Get_Source_Page():
url = 'https://pic.netbian.com/index.html'
# 当爬虫程序运行爬网站,若不设置header为任意一个名字,会被有些网站检查出是python爬虫,被禁止访问
headers =
# 'Host':'image.baidu.com'
# 'Cookie':
# 'Referer':
"User-Agent": "hdy"
# 后去网页get请求
response = requests.get(url=url, headers=headers)
# gbk编码解码
response.encoding = 'gbk'
# 获取数据内容,并打印(获取网页源码很重要,每个网页都不尽相同,可以根据具体返回的网页信息来截取图片信息)
text = response.text
print(text)
return text
if __name__=='__main__':
Get_Source_Page()
5、运行结果,网页获取成功,乱码解决:
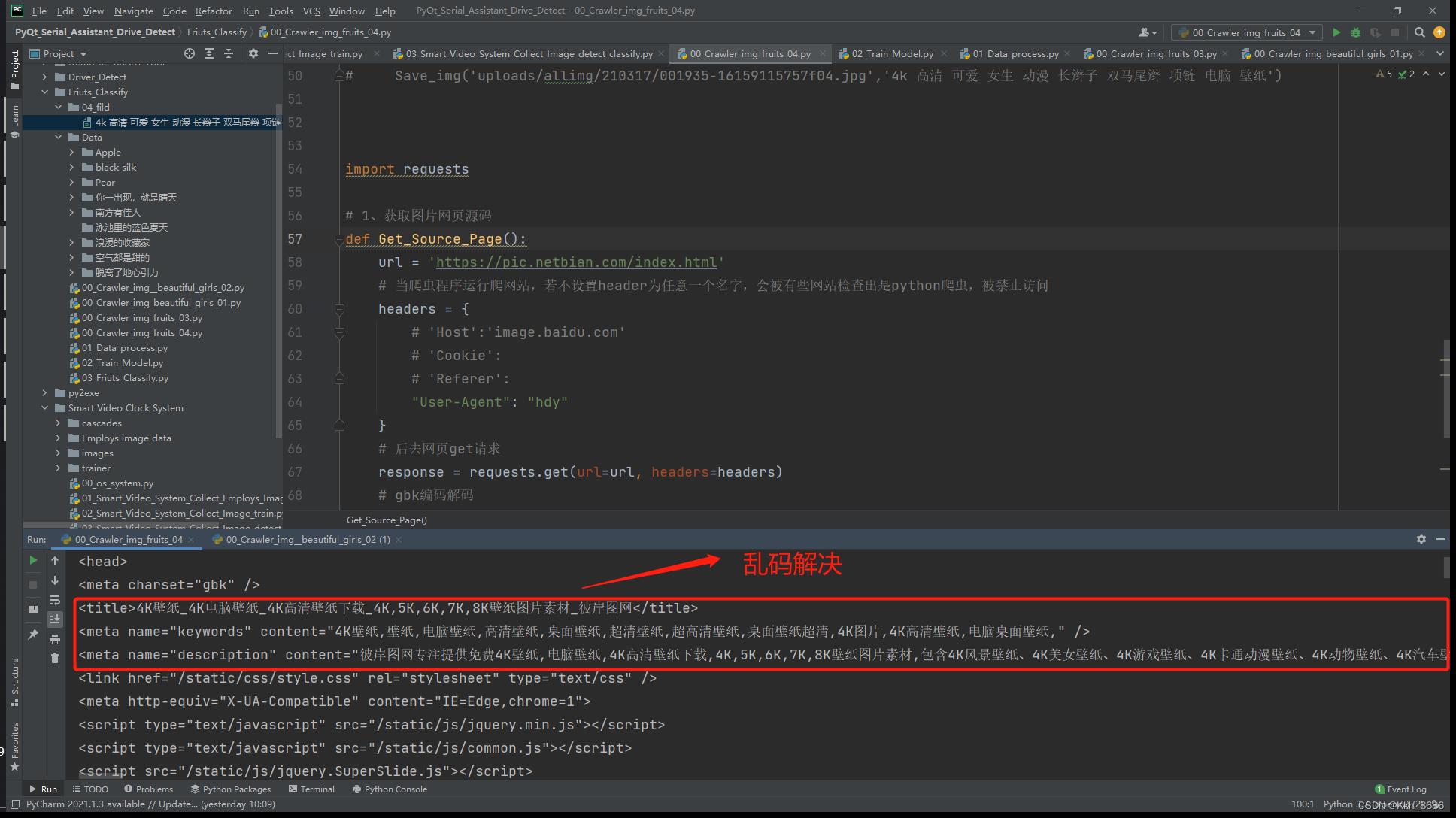
6、对于需要截取一些特定多行的网页源码,需要进行如下操作:
import re
a = '''aabbccdd123456:
121313413
xxyyzz'''
b = re.findall("aa(.*?)zz", a)
c = re.findall("aa(.*?)zz", a, re.S) # re.S的功能
print("b is :", b)
print("c is :", c)
# re.S的作用是将多行的字符串a连接成一行,多行中的aa和zz不在同一行,则"aa(.*?)zz"的条件没有
# 需要将多行中aa和zz通过re.S链接在一起
7、运行效果:

8、查看网页源码信息,定位到图片的URL链接和标题,以备用在程序中获取的网页源码中提取URL链接和图片标题:
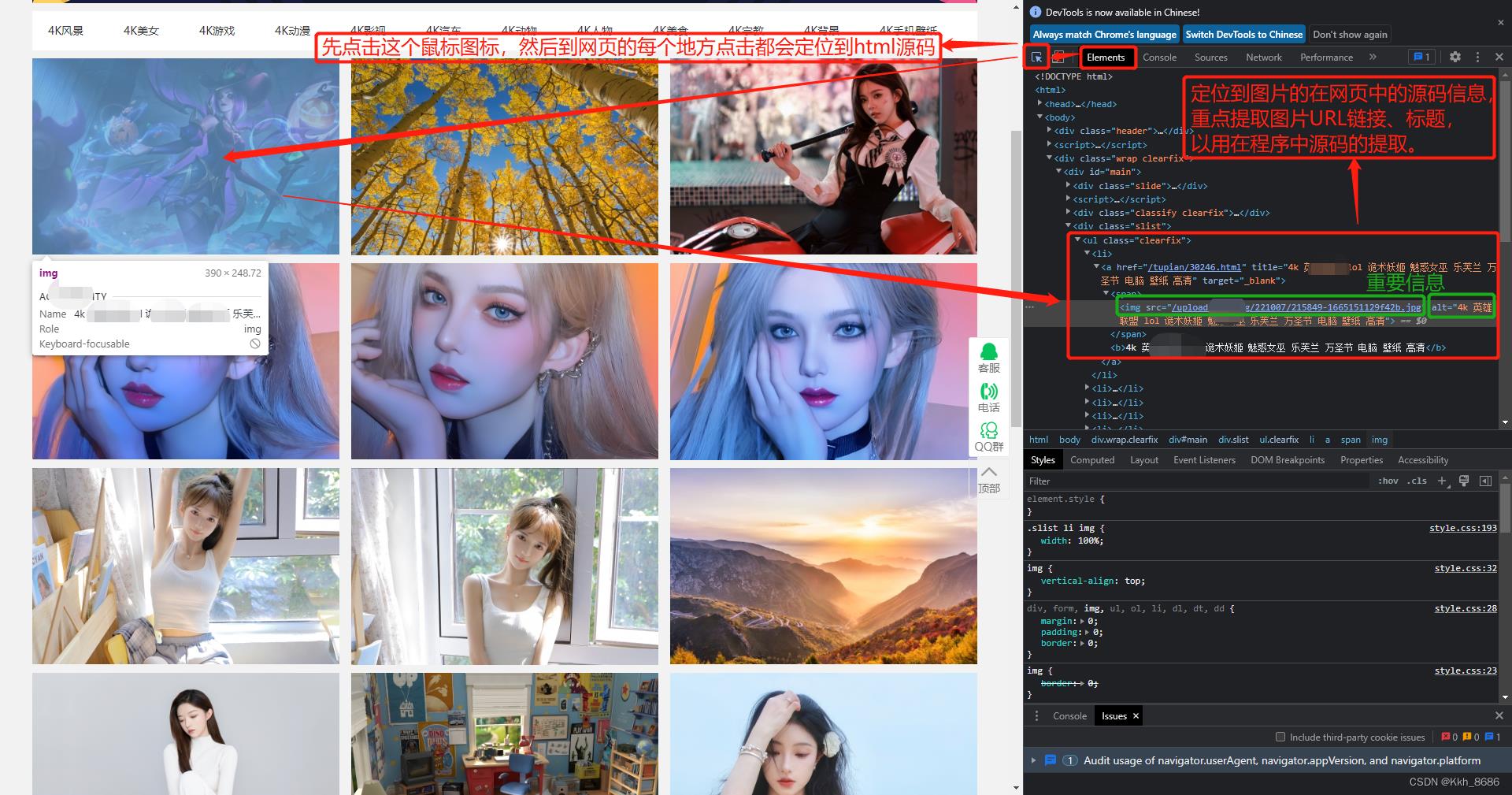
9、在第5步中程序运行获取的网页信息,根据在浏览器上网页源码的图片信息定位到程序请求得到的网页信息。


10、设计程序获取图片信息(URL、标题):
import requests
import re
# 1、获取图片网页源码
def Get_Source_Page():
url = 'https://pic.netbian.com/index.html'
# 当爬虫程序运行爬网站,若不设置header为任意一个名字,会被有些网站检查出是python爬虫,被禁止访问
headers =
# 'Host':'image.baidu.com'
# 'Cookie':
# 'Referer':
"User-Agent": "hdy"
# 后去网页get请求
response = requests.get(url=url, headers=headers)
# utf-8编码解码
response.encoding = 'gbk'
# 获取数据内容,并打印(获取网页源码很重要,每个网页都不尽相同,可以根据具体返回的网页信息来截取图片信息)
text = response.text
print(text)
return text
# 2、从源码中解析出图片地址
def Get_img_link(text):
# 对整个网页截取有图片的地址、标题等信息的网页内容
# find要求的的内容信息”<ul class="clearfix">(.*?)</ul>“,<ul></ul>中间内容
find = re.compile('<ul class="clearfix">(.*?)</ul>', re.S)
# 对text网页信息截取符合find要求的的内容信息
li_list = re.findall(find, text)
print(li_list[0])
if __name__=='__main__':
Get_Source_Page()
Get_img_link(Get_Source_Page())
11、在网页信息中提取得到需要图片信息:
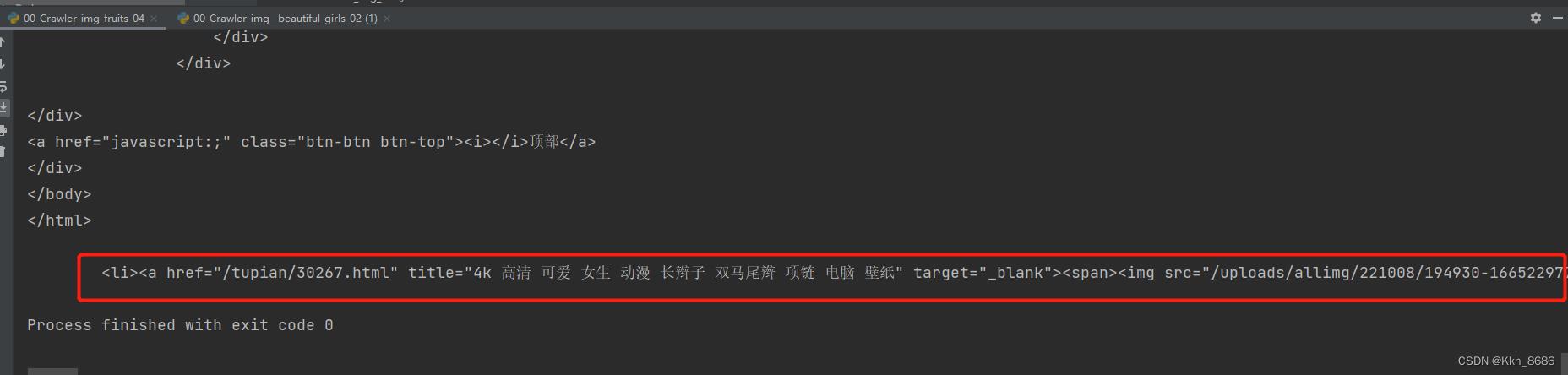
12、进一步提取图片信息:
import requests
import re
# 1、获取图片网页源码
def Get_Source_Page():
url = 'https://pic.netbian.com/index.html'
# 当爬虫程序运行爬网站,若不设置header为任意一个名字,会被有些网站检查出是python爬虫,被禁止访问
headers =
# 'Host':'image.baidu.com'
# 'Cookie':
# 'Referer':
"User-Agent": "hdy"
# 后去网页get请求
response = requests.get(url=url, headers=headers)
# utf-8编码解码
response.encoding = 'gbk'
# 获取数据内容,并打印(获取网页源码很重要,每个网页都不尽相同,可以根据具体返回的网页信息来截取图片信息)
text = response.text
print(text)
return text
# 2、从源码中解析出图片地址
def Get_img_link(text):
# 对整个网页截取有图片的地址、标题等信息的网页内容
# find要求的的内容信息”<ul class="clearfix">(.*?)</ul>“,<ul></ul>中间内容
find = re.compile('<ul class="clearfix">(.*?)</ul>', re.S)
# 对text网页信息截取符合find要求的的内容信息
li_list = re.findall(find, text)
print(li_list[0])
# 截取特定格式的网页信息
find_img_link = re.compile('<img src="(.*?)" alt="(.*?)" />', re.S)
# 对li_list[0]信息截取符合find_img_link要求的的内容信息
img_list = re.findall(find_img_link, li_list[0])
# print(img_list)
if __name__=='__main__':
Get_Source_Page()
Get_img_link(Get_Source_Page())
13、运行,从多张的图片的一整段信息,提取得到一张张图片的信息:

14、分别得到一张张图片信息(URL、标题):
import requests
import re
# 1、获取图片网页源码
def Get_Source_Page():
url = 'https://pic.netbian.com/index.html'
# 当爬虫程序运行爬网站,若不设置header为任意一个名字,会被有些网站检查出是python爬虫,被禁止访问
headers =
# 'Host':'image.baidu.com'
# 'Cookie':
# 'Referer':
"User-Agent": "hdy"
# 后去网页get请求
response = requests.get(url=url, headers=headers)
# utf-8编码解码
response.encoding = 'gbk'
# 获取数据内容,并打印(获取网页源码很重要,每个网页都不尽相同,可以根据具体返回的网页信息来截取图片信息)
text = response.text
print(text)
return text
# 2、从源码中解析出图片地址
def Get_img_link(text):
# 对整个网页截取有图片的地址、标题等信息的网页内容
# find要求的的内容信息”<ul class="clearfix">(.*?)</ul>“,<ul></ul>中间内容
find = re.compile('<ul class="clearfix">(.*?)</ul>', re.S)
# 对text网页信息截取符合find要求的的内容信息
li_list = re.findall(find, text)
print(li_list[0])
# 截取特定格式的网页信息
find_img_link = re.compile('<img src="(.*?)" alt="(.*?)" />', re.S)
# 对li_list[0]信息截取符合find_img_link要求的的内容信息
img_list = re.findall(find_img_link, li_list[0])
print(img_list)
for i in img_list:
print(i)
if __name__=='__main__':
Get_Source_Page()
Get_img_link(Get_Source_Page())
15、更清晰的显示图片信息:
16、向图片地址发送请求并保存:
import requests
import re
# 1、获取图片网页源码
def Get_Source_Page():
url = 'https://pic.netbian.com/index.html'
# 当爬虫程序运行爬网站,若不设置header为任意一个名字,会被有些网站检查出是python爬虫,被禁止访问
headers =
# 'Host':'image.baidu.com'
# 'Cookie':
# 'Referer':
"User-Agent": "hdy"
# 后去网页get请求
response = requests.get(url=url, headers=headers)
# gbk编码解码
response.encoding = 'gbk'
# 获取数据内容,并打印(获取网页源码很重要,每个网页都不尽相同,可以根据具体返回的网页信息来截取图片信息)
text = response.text
print(text)
return text
# 2、从源码中解析出图片地址
def Get_img_link(text):
# 对整个网页截取有图片的地址、标题等信息的网页内容
# find要求的的内容信息”<ul class="clearfix">(.*?)</ul>“,<ul></ul>中间内容
find = re.compile('<ul class="clearfix">(.*?)</ul>', re.S)
# 对text网页信息截取符合find要求的的内容信息
li_list = re.findall(find, text)
# print(li_list[0])
# 截取特定格式的网页信息
find_img_link = re.compile('<img src="(.*?)" alt="(.*?)" />', re.S)
# 对li_list[0]信息截取符合find_img_link要求的的内容信息
img_list = re.findall(find_img_link, li_list[0])
print(img_list)
for i in img_list:
print(i)
# 3、向图片发送请求,并保存图片
def Save_img(link, title):
# img_url = f'https://pic.netbian.com/index.html' # 第一页的图片地址
img_url = f'https://pic.netbian.com/link' # 拼接图片地址链接(第2、3、、# )
img_res = requests.get(url=img_url) # 像图片地址发送请求
with open(f'04_fild/title.jpg', mode='wb') as f: # 以二进制方式写入jpg图片
f.write(img_res.content)
img_res.close()
if __name__=='__main__':
Get_Source_Page()
Get_img_link(Get_Source_Page())
# 取需要保存的图片的部分URL链接
Save_img('uploads/allimg/210317/001935-16159115757f04.jpg','4k 高清 可爱 女生 动漫 长辫子 双马尾辫 项链 电脑 壁纸')
17、成功爬取一张图片:

18、改进程序,保存一个网页里面的多张图片:
import requests
import re
# 1、获取图片网页源码
def Get_Source_Page():
url = 'https://pic.netbian.com/index.html'
# 当爬虫程序运行爬网站,若不设置header为任意一个名字,会被有些网站检查出是python爬虫,被禁止访问
headers =
# 'Host':'image.baidu.com'
# 'Cookie':
# 'Referer':
"User-Agent": "hdy"
# 后去网页get请求
response = requests.get(url=url, headers=headers)
# gbk编码解码
response.encoding = 'gbk'
# 获取数据内容,并打印(获取网页源码很重要,每个网页都不尽相同,可以根据具体返回的网页信息来截取图片信息)
text = response.text
print(text)
return text
# 2、从源码中解析出图片地址
def Get_img_link(text):
# 对整个网页截取有图片的地址、标题等信息的网页内容
# find要求的的内容信息”<ul class="clearfix">(.*?)</ul>“,<ul></ul>中间内容
find = re.compile('<ul class="clearfix">(.*?)</ul>', re.S)
# 对text网页信息截取符合find要求的的内容信息
li_list = re.findall(find, text)
# print(li_list[0])
# 截取特定格式的网页信息
find_img_link = re.compile('<img src="(.*?)" alt="(.*?)" />', re.S)
# 对li_list[0]信息截取符合find_img_link要求的的内容信息
img_list = re.findall(find_img_link, li_list[0])
print(img_list)
for i in img_list:
print(i[0], i[1])
Save_img(i[0], i[1])
# 3、向图片发送请求,并保存图片
def Save_img(link, title):
# img_url = f'https://pic.netbian.com/index.html' # 第一页的图片地址
img_url = f'https://pic.netbian.com/link' # 拼接图片地址链接(第2、3、、# )
img_res = requests.get(url=img_url) # 像图片地址发送请求
with open(f'04_fild/title.jpg', mode='wb') as f: # 以二进制方式写入jpg图片
f.write(img_res.content)
img_res.close()
if __name__=='__main__':
Get_Source_Page()
Get_img_link(Get_Source_Page())
# Save_img('uploads/allimg/210317/001935-16159115757f04.jpg','4k 高清 可爱 女生 动漫 长辫子 双马尾辫 项链 电脑 壁纸')
19、代码解析:

20、进一步改进代码,获取认识页数的全部图片:
import requests
import re
# 1、获取图片网页源码
def Get_Source_Page():
# 当爬虫程序运行爬网站,若不设置header为任意一个名字,会被有些网站检查出是python爬虫,被禁止访问
headers =
# 'Host':'image.baidu.com'
# 'Cookie':
# 'Referer':
"User-Agent": "hdy"
for i in range(2, 5): # 若想要爬取多个页数的图片,就把这里的5改成想要爬的页数
# url = 'https://pic.netbian.com/index.html' # 首页的网页地址
if i == 1:
url = f'https://pic.netbian.com/index.html'
else:
url = f'https://pic.netbian.com/index_i.html' # 第i页的网页地址
# 后去网页get请求
response = requests.get(url=url, headers=headers)
# gbk编码解码
response.encoding = 'gbk'
# 获取数据内容,并打印(获取网页源码很重要,每个网页都不尽相同,可以根据具体返回的网页信息来截取图片信息)
text = response.text
print(text)
return text
# 2、从源码中解析出图片地址
def Get_img_link(text):
# 对整个网页截取有图片的地址、标题等信息的网页内容
# find要求的的内容信息”<ul class="clearfix">(.*?)</ul>“,<ul></ul>中间内容
find = re.compile('<ul class="clearfix">(.*?)</ul>', re.S)
# 对text网页信息截取符合find要求的的内容信息
li_list = re.findall(find, text)
# print(li_list[0])
# 截取特定格式的网页信息
find_img_link = re.compile('<img src="(.*?)" alt="(.*?)" />', re.S)
# 对li_list[0]信息截取符合find_img_link要求的的内容信息
img_list = re.findall(find_img_link, li_list[0])
print(img_list)
for i in img_list:
print(i[0], i[1])
Save_img(i[0], i[1])
# 3、向图片发送请求,并保存图片
def Save_img(link, title):
# img_url = f'https://pic.netbian.com/index.html' # 第一页的图片地址
img_url = f'https://pic.netbian.com/link' # 拼接图片地址链接(第2、3、、# )
img_res = requests.get(url=img_url) # 像图片地址发送请求
with open(f'04_fild/title.jpg', mode='wb') as f: # 以二进制方式写入jpg图片
f.write(img_res.content)
img_res.close()
if __name__=='__main__':
Get_Source_Page()
Get_img_link(Get_Source_Page())
# Save_img('uploads/allimg/210317/001935-16159115757f04.jpg','4k 高清 可爱 女生 动漫 长辫子 双马尾辫 项链 电脑 壁纸')
以上是关于爬取一些网页图片的主要内容,如果未能解决你的问题,请参考以下文章