python——爬取图片(shutter图片网)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python——爬取图片(shutter图片网)相关的知识,希望对你有一定的参考价值。
在本爬虫程序中共有三个模块:
1、爬虫调度端:启动爬虫,停止爬虫,监视爬虫的运行情况
2、爬虫模块:包含三个小模块,URL管理器、网页下载器、网页解析器。
(1)URL管理器:对需要爬取的URL和已经爬取过的URL进行管理,可以从URL管理器中取出一个待爬取的URL,传递给网页下载器。
(2)网页下载器:网页下载器将URL指定的网页下载下来,存储成一个字符串,传递给网页解析器。
(3)网页解析器:网页解析器解析传递的字符串,解析器不仅可以解析出需要爬取的数据,而且还可以解析出每一个网页指向其他网页的URL,这些URL被解析出来会补充进URL管理器
3、数据输出模块:存储爬取的图片
具体思路就是根据正则表达式,找到url,然后完成下载。
设计环境
IDE:Sublime Text3
Python版本:python3.7
目标分析
目标:从https://www.shutterstock.com/zh/search/开始,爬取多个类别的前十张图片
(1)初始URL:"https://www.shutterstock.com/zh/search/"
(2)词条页面URL格式:
https://www.shutterstock.com/zh/search?searchterm=Architecture&image_type=photo
(3)找到backgrounds,Architecture,business,kids,food,portrait,flowers,travel等类别标签名
代码如下:
import requests import re import urllib.request import time headers = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36\' } url_base = \'https://www.shutterstock.com/zh/search/\' imge_list = [] for i in [\'backgrounds\',\'Architecture\',\'business\',\'kids\',\'food\',\'portrait\',\'flowers\',\'travel\',\'skyline\']: url = url_base+i+\'?image_type=photo\' res = requests.get(url,headers= headers).text # 为图片生成缩略图 #"thumbnail":"(.*?)", cop = re.compile(\'"thumbnail":"(.*?)",\',re.S) result = re.findall(cop,res)[:10] for each in result: filename = each.split(\'/\')[-1] #imge_list.append(each) #[90] response = urllib.request.urlopen(each) img = response.read() with open(filename,\'wb\')as f: f.write(img) print("已下载:",each) time.sleep(5) # 休眠五秒 print("下载结束")
结果:
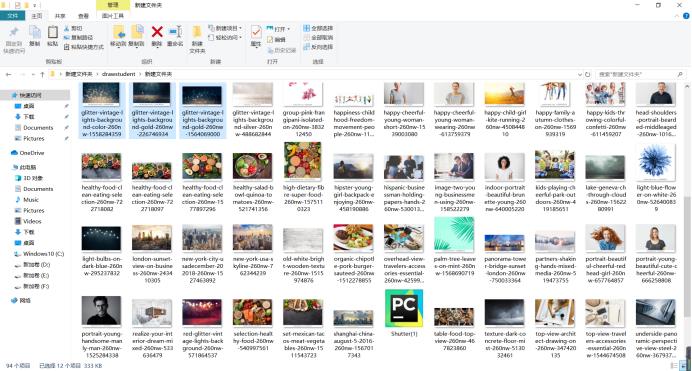
遇到的问题
(1)爬取几张图片后,没有产生新的图片。原因:因为是外国网站,访问次数过多,会被限制访问。
解决方法:设置sleep函数,休眠几秒继续访问。
(2)英文页面不要随便翻译,会使源码标签显示错误!
解决方法:确认浏览器是否自动翻译过,可以获取一下他的页面,然后找想要的标签,不存在,则有两种情况,动态或者被翻译过。
以上是关于python——爬取图片(shutter图片网)的主要内容,如果未能解决你的问题,请参考以下文章