腾讯大数据总体架构图,首次对外公开
Posted 小虚竹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了腾讯大数据总体架构图,首次对外公开相关的知识,希望对你有一定的参考价值。
「数仓宝贝库」,带你学数据!
导读:腾讯作为国内体量最大的互联网公司之一,业务涵盖用户日常生活的方方面面,面对如此巨大业务数据量,如果不能对数据进行专业化处理并高效有序地存、管、用,如果不能使数据产生应有的价值,那么数据资产将会成为数据垃圾,成为社会和企业的负担。
大数据平台作为腾讯底层的基础设施之一,每天必须处理千万级规模的离线数据任务及十万亿级别的实时计算,否则无法满足业务每天数以亿计的数据分析计算的需求。
本文主要介绍腾讯大数据的构建理念和总体架构。
01腾讯大数据的构建理念
项目立项的时候我们曾有过激烈讨论,是自主研发还是使用开源,“To be, or not to be: that is the question”。当时业务需求比较迫切,2009年上半年,QQ空间引入了“开心农场”业务,开启了疯狂增长的模式,业务部门的同事看着几乎是垂直的增长曲线笑逐颜开,我们看着曲线却笑不出来。如何能快速构建全新的数据仓库,满足业务快速增长的计算需求,我们在努力寻找答案。
在2008~2009年,开源在国内还没大行其道,很多程序员都有一种偏见,觉得使用开源都是没什么技术含量的。几乎所有的程序员心里都有一个梦想和追求,希望能自己实现一套顶尖的系统,从而在中国乃至世界的软件行业扬名立万。但是盘点了业务的需求以及对比了那时候团队能力和所能调配的人力之后,我们发现实现这么一套系统,无异于登天。完全自主研发新一代的数据仓库是难以攀爬的珠峰。
此路不通,只能改走开源路线。其实开源有很多好处,它有着丰富的社区资源和社区生态,有着庞大的各路代码贡献者,使用开源的系统,相当于利用了全世界的资源,利用了全世界的程序员的智慧。使用开源项目,能快速搭建适应业务需求的平台。
但开源对于我们来说也并不容易。首先,技术栈不一样,我们原来是C/C++技术栈,是做计费系统的,而大数据开源基本以Java为主,需要从头去学,幸好语言的差异并不是很难克服,我们边学习边招聘有大数据经验的开发者,慢慢地做了起来;另外,大数据生态是很庞大的,每一个项目都不足以达到企业级的需求,每一个项目都要进行大量的优化,才能符合我们可用性方面的需求。
从最初的蹒跚学步到现在,腾讯大数据走过了十余年,历经三代技术演进。第一代是“拿来主义”,拿来就用,但部分系统比如HDFS(Hadoop Distributed File System, Hadoop分布式文件系统)、Hive等因为性能、功能不能满足需求,我们对核心模块进行了定制化的优化;第二代是有限自主研发的阶段,我们对部分核心平台进行参考性的自主研发,重构实时采集系统,同时对底层实时计算引擎Storm使用Java进行重写等;第三代是纯自主研发的阶段,第三代的核心平台—高性能分布式机器学习平台Angel,是腾讯和北大等高校联合研发,具有完全知识产权。
我们一直是开源的受益者,从Hadoop到Spark到Storm……我们的发展离不开社区,我们弱小的时候依赖开源社区,我们成长后又积极回馈社区。其实早在2014年,我们就把腾讯自己的Hive版本进行开源,它对Oracle语法兼容等特性广受欢迎。我们第三代最核心的高性能分布式机器学习平台Angel在2017年就开源了,2018年还进一步捐献给Linux基金会。2019年,我们一口气开源了四大平台:实时数据采集平台TubeMQ(捐献给Apache社区)、资源管理平台TKEStack、分布式数据库TBase以及腾讯版本的OpenJDK—Kona JDK。我们有几十个项目的PMC和提交者及更大量的贡献者,每天都为社区贡献代码。
通过开源进行技术上的协同,可聚拢人才,一个好的项目能吸引很多优秀的开发者,有利于形成一个优良的技术生态,有利于推动技术进步。这也是我们选择开源的原因。
来自开源、回馈开源、坚持开源,这可以说是腾讯大数据平台十年发展的技术理念。另外一个技术理念是:一切要为业务所用。
我们固执地认为,技术如果不能为业务所用,那它就是毫无价值的。我们自主研发的Angel项目,出发点也是因为当时开源社区里面没有符合我们业务需求的机器学习平台,自主研发是因为对业务有价值,而不是因为它在技术上很有挑战性以及我们要证明自己技术很牛。Angel自2017年开源后有超过一百多个公司和组织使用,包括华为、小米、OPPO、新浪微博、拼多多等,发挥了Angel在腾讯以外的价值。
02腾讯大数据的总体架构
如前所述,腾讯大数据十余年的发展,经历了三代的技术演变,如图1所示。

▲图1 腾讯大数据三代技术演变
第一代架构从2009~2011年,以承载离线计算任务为主,如图2所示。
TDW主要以Hadoop为基础构建,我们主要做了两方面的优化:其一扩大了集群规模,包括增强了集群拓展性,优化了调度性能,增强了容灾能力,通过差异化存储降低了存储成本;其二是利用周边生态降低应用门槛,建设配套的调度与开发平台,兼容Oracle的语法,以及集成PostgreSQL数据库以提升小数据量的分析性能。第一代平台总结起来就是,技术上主要满足离线计算需求,技术挑战主要在不断扩展和优化集群规模,单集群规模从几十台到几百台,再到几千台不断突破。
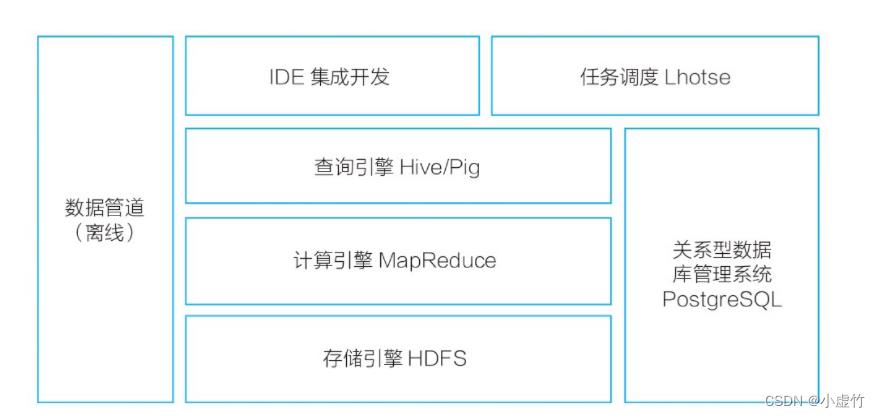
▲图2 第一代离线计算平台架构
第二代架构从2012~2014年,在承载离线计算的基础上,扩展了平台能力,支持实时计算的需求,如图3所示。

▲图3 第二代实时计算平台架构
在第一代离线计算平台基础之上,我们融合Storm和Spark构建了第二代实时计算平台。
主要的演进如下。
1)集成Spark,离线计算比Hadoop性能更高。
2)引入Storm,支持秒级/毫秒级的流式计算任务。
3)建设了实时采集系统TDBank,数据采集实现从天级(T+1)到秒级的飞跃。
4)支持资源和任务调度方面,平台支持离线与在线混合部署,任务容器化,资源管理的维度支持CPU、内存,以及网络与I/O,进一步提升了平台轻量化、敏捷性与灵活性,极大提升了平台利用率,降低了成本。
第三代架构从2015~2019年,在通用大数据计算外,开始支持机器学习、深度学习等AI场景,Big Data与AI在平台层面逐步融合,如图4所示。
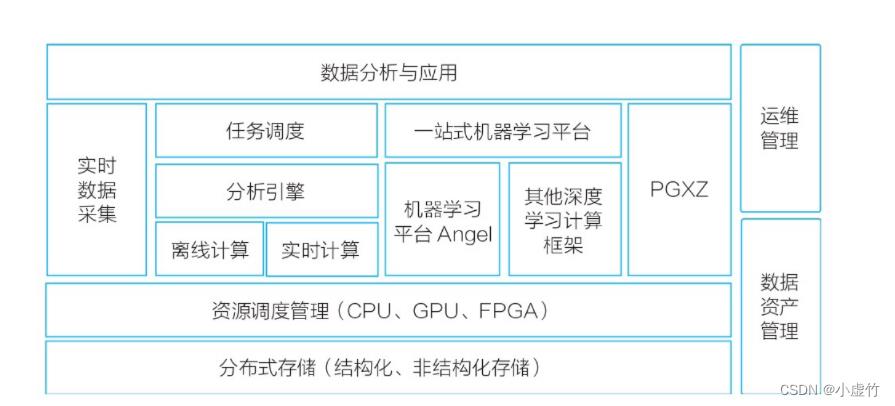
▲图4 第三代机器学习计算平台
在第二代实时计算平台基础上,自主研发了机器学习平台Angel,并以Angel为核心构建第三代机器学习计算平台生态。主要演进如下。
1)我们与北京大学合作,自主研发了高性能分布式机器学习平台。该平台支持十亿至百亿维度模型,支持数据并行及模型并行,支持在线训练。同时,它除了支持传统的机器学习之外,还扩展支持深度学习、图计算等功能,具有全栈的AI能力。它具有友好的编程接口、丰富的算法库,并在上层构建了一站式开发运营环境,支持业界多种流行计算框架。Angel于2017年6月全面开源,2018年捐献给Linux基金会,2019年12月20日从Linux基金会旗下AI领域顶级基金会—LF AI基金会(Linux Foundation Artificial Intelligence Foundation)正式毕业,成为中国首个从LF AI基金会毕业的开源项目,意味着Angel得到全球技术专家的认可,成为世界顶级的AI开源项目之一。
2)资源管理层面,除了CPU,还支持GPU、FPGA等异构设备。我们是国内比较早实现GPU虚拟化且技术比较领先的(见我们在IEEE ISPA2018发布的论文“GaiaGPU: Sharing GPUs in Container Clouds”)。
3)大数据与数据库紧密结合,使用基于PostgreSQL的分布式数据库PGXZ(后改名为TBase,并于2019年对外开源),支持HTAP(Hybrid Transaction and Analytical Processing,混合事务和分析处理),使得TDW更好地支持OLTP(On-Line Transaction Processing,联机事务处理过程)的计算。
截至2019年,腾讯大数据走过十年,并且还在不断演进中,我们正在探寻下一代计算平台之路,我们在探索批流融合,我们在探索云原生大数据,我们也在尝试AI、大数据及云计算结合和软硬件结合,我们还在研究数据湖和隐私计算等前沿技术……大数据、人工智能和云计算,正在成为支撑业务发展的基础设施,下一代,会更精彩。
本文摘编于《腾讯大数据构建之道》,经出版方授权发布。(书号:9787111710769)转载请保留文章来源。

推荐语:腾讯官方出品!腾讯大数据构建之道首次对外披露!腾讯大数据平台十年磨一剑,践行“科技向善”落地方案
以上是关于腾讯大数据总体架构图,首次对外公开的主要内容,如果未能解决你的问题,请参考以下文章