首次公开,阿里云开源PolarDB总体架构和企业级特性
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了首次公开,阿里云开源PolarDB总体架构和企业级特性相关的知识,希望对你有一定的参考价值。
简介:在3月2日的阿里云开源 PolarDB 企业级架构发布会上,阿里云 PolarDB 内核技术专家北侠带来了主题为《PolarDB 总体架构设计和企业级特性》的精彩演讲。
在3月2日的阿里云开源 PolarDB 企业级架构发布会上,阿里云 PolarDB 内核技术专家
北侠带来了主题为《PolarDB 总体架构设计和企业级特性》的精彩演讲。主要分享了存储计算分离架构、HTAP架构、节点高可用架构是PolarDB 可支持的三种架构,PolarDB还具备可用性、高性能、安全的企业级特性。并对PolarDB 总体架构和企业级特性进行展开分析。
直播回顾视频:开源PolarDB企业级架构重磅发布-阿里云
PDF下载: 文件下载-阿里云开发者社区
以下根据发布会演讲视频内容整理:
PolarDB 是阿里云自主研发的云原生数据库,它的源代码已经全部开源(源码仓库地址:https://github.com/ApsaraDB/PolarDB-for-PostgreSQL )。下面将为大家详细解读开源 PolarDB 的总体架构和企业级的特性。
一、PolarDB总体架构设计

PolarDB 的基础架构是云原生架构。传统数据库由主库、备库和一个 Standby节点构成,主库复制redo日志到备库。传统数据库的架构存在以下四个问题:
① 扩展性差。增加节点的时候需要先将数据完整复制,花费的时间通常是小时级别甚至更长。
② 可靠性差。主库和备库之间需要采用同步复制,会导致性能下降大概 20% 以上;如果采用异步复制,则会发生数据丢失的风险。
③ 可用性差。主库发生了故障后, HA 会切换到备库。新的备库需要回放大量 redo 日志才能进入可服务的状态,该过程可能需要分钟级别的耗时。
④ 成本高。存储成本会随着节点数目的增加而呈线性增加,此外还需要预留一些资源。
为了彻底解决以上问题,PolarDB提出了云原生的架构,将计算和存储资源解耦。
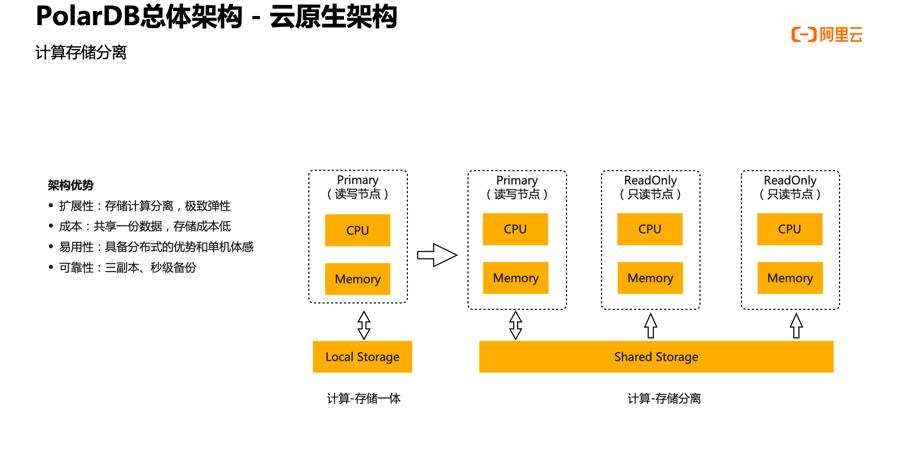
上图左侧是传统的数据库,它的 CPU 、内存、存储都在一台服务器上,称作计算存储一体化。右侧是 PolarDB 的架构,它分成了计算节点和存储节点两种类型的节点。数据存储在由存储节点构成的存储池里,各个计算节点通过高速网络读取存储池中的数据。
计算存储分离的架构的优势在于以下几个方面:
① 极致的、弹性的扩展能力:存储和计算能够分别独立地扩容。
② 降低存储成本:那么计算集群扩展到多少个,数据始终只有一份。
③ 易用性:具备分布式的优势和单机数据库的体感,因为每个计算节点都能看到所有数据。对于用户来说,任何一个计算节点就相当于是一个单机数据库。
④ 可靠性比较高:底层共享存储提供了三副本以及秒级快照的功能,为数据库的备份提供了比较便捷的方式。
PolarDB 不仅设计研发了计算存储分离的架构,还在在数据库的模块栈上进行了大量优化。

在事务层,实现了 CSN 快照来代替传统的事务快照;在日志层,实现了 LogIndex 这样核心的数据结构,解决了在计算存储分离架构下遇到的特有的过去页面以及未来页面的数据问题,同时实现了延迟回放和并行回放;在缓存层,实现了常驻的 BufferPool 和多版本页面;在存储层,实现了 DirectIO 模型页面的预读和预扩展的能力。
此外,用户还经常需要对 TP 事务的数据进行复杂的分析查询,比如在夜里做汇总报表和对账。此类查询一般都是一些非常复杂的 SQL ,但并发不高,是典型的 OLAP 场景。
最初 PolarDB 的计算存储分离架构在处理这类复杂的 SQL 时,只能由单个计算节点来计算,无法发挥出计算集群的整体算力,同时也没有办法发挥出存储池大带宽的特性。

当时业界的解决方案通常有两类:
① 在原有的 TP 系统外面部署一套 AP 系统,将 TP 的事务数据通过日志导入到 AP 系统。此方案存在的问题在于两个系统之间的延迟比较高,会导致数据的新鲜度不高。另外,部署一套独立的 AP 系统会导致存储和运维的成本增加。
② 在原有的 TP 系统上就地执行 AP 查询,但这势必会造成 TP 和 AP 两种业务互相影响。另外, AP 系统也没有办法做弹性的扩展。
因此, PolarDB 研发了一个基于共享存储的分布式计算引擎,这也是业界首创的解决方案。该方案具备以下优势:
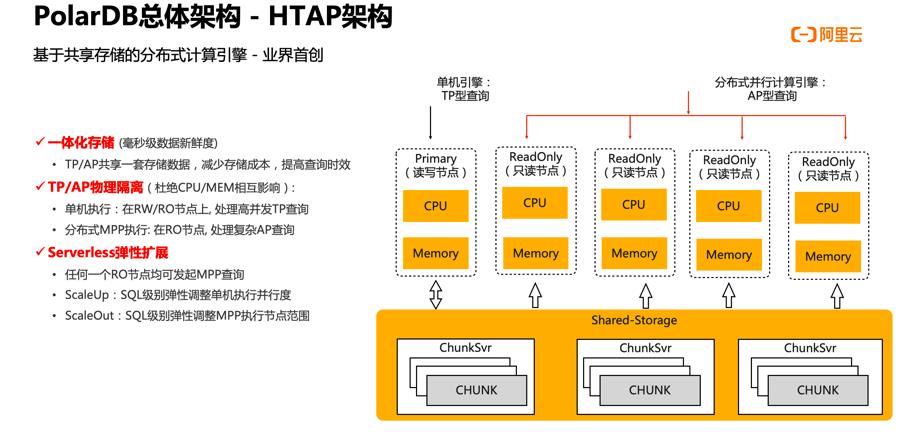
① 它是一个一体化的存储方案,TP 和 AP 共用一份存储在共享存储上数据。相比于两套系统,它减少了存储成本,同时也提供了毫秒级的数据新鲜度,即在 TP 系统里插入了一条数据,在 IP 系统里可以以毫秒级的速度查询到。
② TP 和 IP 是物理隔离、互相不影响的。由部分计算节点执行单机的引擎来处理高并发的 TP 查询,由另外一部分节点执行分布式的查询引擎来处理复杂的 AP 查询。
③ 具备弹性扩展能力。系统面度一些复杂的 SQL 时,出现算力不够的情况,即可快速增加计算节点,新的节点也可以迅速增加到分布式的计算引擎的集群里。
相比于传统的 OLAP 系统,它是一个即时生效的系统,不需要做数据的重分布和重打散,性能上有了巨大的提升。

在共享存储上实现一个完备的分布式计算引擎需要实现以下几个模块:
① 分布式优化器。优化器会根据数据分布特征生成一个分布式的执行计划数。PolarDB 是基于 GPORCA 优化器框架做的二次开发,在开发过程中,需要让优化器感知到数据是共享的。GPORCA优化器框架是基于 share-nothing ,因此应用到 PolarDB 势必要增加很多规则转换。
② 分布式执行器。为了实现分布式执行器,需要实现一整套完整的并行化的算子。比如在做数据扫描的时候,因为在 PolarDB里底层数据是共享的,各个计算节点在做顺序扫描的时候就需要做扫描算字的并行化。这些算子最后会组装成火山执行模型。
③ 事务一致性。由于分布式执行跨了多个计算节点,需要使用统一的数据位点和快照来进行事务的可见性判断,才能保证各个节点查询到的数据是全值一致性的数据。
④ SQL 全兼容。为了使新的分布式计算引擎能够被用户的业务使用,还需要对 SQL 的标准进行大量兼容性的开发工作。

PolarDB 除了能够以计算存储分离的方式运行在一个共享存储的设备上,也能支持三节点高可用的模式。此模式可以不需要依赖共享存储的设备,以本地盘的模式来运行。
首先,节点之间通过 X-Paxos 算法来对 redo 日志进行复制,以保证在region 内部能够提低延迟同时 RP=0 的可用性。
其次,借助X-Paxos算法的复制实现了自动 failover 当leader 节点宕机时,无需 DBA 人员介入,算法能够自动选出一个新的 leader 来自动恢复。
此外,还可以借助 X-Paxos 算法实现集群成员变更。与此同时,PolarDB还实现了 log 节点(即节点上只有 redo 日志没有数据页),可以通过用两个正常的节点加上一个 log 节点,实现2.5副本的方式,降低成本。
在跨region场景下,通过 log 节点实现了两地三中心的高可用部署方式。如上图, region1 是一个独立的X-Paxos 三节点高可用的模式, region2 是一个独立的 DB 部署,并在同城的另一个机房里去部署一个 log 节点。那么 region 1 和同城 log 节点之间可以采用同步复制或异步复制,而由于是在同一个城市内部,延迟也比较低,这样即实现了两地三中心的高可用的部署方式。
系统还兼容了原生的流复制和逻辑复制,用户可以在下游部署一套自己的标准的 PostgreSQL 数据库来消费上游的 redo 日志。

对于前文提到的三个 PolarDB 架构,用户可以根据业务场景对其进行自由组合来使用。比如通过云原生+HTAP组合,可以满足对弹性、 TP 和 AP 都有需求的业务。并且,三种架构的自由组合是在一套二进制里实现的,用户只需要在配置文件里面进行简单的配置,即可实现这三套架构的自由组合。
二、PolarDB企业级特性

PolarDB 的企业级特性有四个方面。
① 架构上的支持,前文已经进行了详细的讲解,此处不再赘述。
② 高性能。
- 1) PolarDB 实现了 CSN 快照和WAL日志的流水线,解决了高并发下临界区的问题。
- 2) 实现了预读和预扩展、RelSizeCache以及 CLOG 的优化。那么这些优化是针对DirectIO 模型下 IO 的优化。存储计算分离之后,存储的每一个 IO 都需要通过网络去访问后端的存储池,与原生场景下存在一些差异,因此需要对其进行大量的优化工作。
- 3) 研发了logIndex 核心数据结构,它记录了每个页面历史上发生的redo日志。它不仅能解决在计算存储分离下特有的过去页面和未来页面数据正确性的问题,还解决了 PB 数据库特有的半写问题。
③ 高可用。
- 1) 实现了 DataMax ,它提供了 log 模式来支持两地三中心的部署,还实现了 Online Promote 、延迟回放和并行回放。这三个大的功能优化了崩溃恢复的速度,缩短了 DB 进程崩溃时的不可用时间。
- 2) 实现了常驻BufferPool ,DB 进程重启后, buffer 需要重新初始化,而目前的机器配置会导致 buffer 越来越大,进而使得buffer 的初始化需要耗费大量时间。
- 3) 提供了Replication Slot 解决了 DB failover时slot 的丢失问题。它借助共享存储,将 slot 的信息存储到共享存储上,以此解决了复制槽丢失的问题。
- 4) 实现了算子级别的内存控制,为每个算子的内存设置了一个上限,避免了因单个算子内存过多而导致整个 DB 进程崩溃。
④ 安全。PolarDB 提供了透明加密的功能,保证存储在盘上的数据是加密后的数据。目前透明加密支持 AES 128位 和 AES 256位 以及国密 SM4 的加密算法。
三、PolarDB开源社区
PolarDB已经开源至 github 。源码仓库地址:https://github.com/ApsaraDB/PolarDB-for-PostgreSQL

在开源的过程中,我们坚持的策略就是100% 兼容社区标准的 PostgreSQL, 保证用户能够从标准的单机PostgreSQL 无缝迁移到 PolarDB 上。其次,我们将所有组件全部开源,包括PolarDB内核、PolarDB分布式文件系统和PolarDB云管控,并承诺开源的代码与公有云上的代码完全一致。

开放云代码的同时,我们还提供了丰富的文档和视频资料,比如架构原理文档、核心功能文档、快速入门文档。
本文为阿里云原创内容,未经允许不得转载。
以上是关于首次公开,阿里云开源PolarDB总体架构和企业级特性的主要内容,如果未能解决你的问题,请参考以下文章
阿里云数据库开源发布:PolarDB HTAP的功能特性和关键技术
阿里云数据库开源发布:PolarDB三节点高可用的功能特性和关键技术
阿里云PolarDB数据库将云原生进行到底!业内首次实现三层池化