深度学习方法在糖尿病视网膜病变诊断中的应用
Posted lalajh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习方法在糖尿病视网膜病变诊断中的应用相关的知识,希望对你有一定的参考价值。
DR 是糖尿病 (Diabetes mellitus, DM) 的重要并发症之一, 调查显示, 其中约 1/3 的糖尿病患 者将发生 DR, 近 10% 的 DM 患者将发生威胁视力 的视网膜病变 (Vision-threatening diabetic retinopathy, VTDR), 糖尿病视网膜病已成为全球工作人群失明人数攀升的主要原因. 由于 DR 检查量增 加, 在诊断方面出现了以下问题:
1) 大量的阅片任 务, 给医生带来了极大的工作压力;
2) 医生阅片速 度慢, 患者也无法得到即时的反馈;
3) 优质医疗资 源被占用, 漏诊、误诊人数增长[2] . 因此, DR 早期诊 断面临严峻的挑战.
国际 DR 诊断标准的全球公认性以及分类明确 性为 DR 智能诊断系统的研发提供了统一标准与基 础。经过不断优化, DR 智能诊断系统逐渐达到 了专家水平, 不仅可以判断患者是否存在 DR, 还可 以对患者的病变等级进行详细划分, 并对眼部的不 同病理特征区域进行检测标识, 提高了系统的可解 释性. 部分 DR 诊断系统的输出结果不再只是给医 生做决策支持, 而是可直接为患者做出精准的诊断, 提供更详细的信息及诊断依据。
糖尿病视网膜病变病理及诊断标准
糖尿病视网膜病变由糖尿病微血管病变导致, 大致可分为血管破裂出血、释放生长因子、血管堵 塞三个环节。
1、 当人体血糖过高, 会引发微血管基底 膜增厚, 进而血管口径减小、内壁变粗糙、弹性和收 缩力减弱
2、此时, 分布在视网膜上的微血管由于十 分脆弱, 将极易破裂、出血, 并释放血管内皮生长因子
3、血管释放出的 VEGF 会刺激临近的新形成的毛细 血管, 后者由于管壁极薄, 受到轻微刺激便会破裂, 上述这几个环节循环往复, 使得视网膜受损愈加严重[4]
糖尿病视网膜病变患者在患病的不同阶段会出 现不同的病理特征, 主要包括: 微动脉瘤、出血和渗 出物 (包含硬渗出和软渗出).
视网膜微动脉瘤,出现在糖尿病视网膜早期, 同时伴随有视网膜血管异常 漏血. 渗出包括硬性渗出和软性渗出两种, 硬性渗出多由扩张的毛细血管和微血管瘤渗漏的脂质和蛋白质成分组成, 沉积于外层视网膜和视网膜下形成 边缘明确的斑; 软性深渗出则临床表现为形状不规 则、边界模糊、大小不等的棉絮或绒毛样网膜渗出 斑[5] .
若保持长期的病理状态, 部分血管会出现堵塞 或闭合, 以至营养物质无法送至视网膜, 造成眼部 的大面积损伤, 最终导致失明
根据上述病理特征, 糖尿病视网膜病变分为两 个阶段[6] :
1) 非增殖性糖尿病视网膜病变 (Non prolife rative diabetic relinopathy, NPDR). NPDR 是 DR 的早期阶段. NPDR 的诊断有助于对疾病进展 和视力丧失进行风险预测, 并确定随访的时间间隔.
2) 增殖性糖尿病视网膜病变 (prolife rative diabetic relinopathy, PDR). PDR 是 DR 的严重阶 段, 体现了广泛视网膜缺血和毛细血管闭锁导致的 血管生长反应
为了更好地区 分患者糖尿病视网膜病变的严重程度, 便于更明确 地界定病情进展[7] , 通常采用分期标准. 现行最通用 的是国际五级诊断标准. 该分类方法按照病症进展 情况分为五期: Ⅰ期 (无病症)、Ⅱ期 (轻度非增殖 期)、Ⅲ期 (中度非增值期)、Ⅳ期 (重度非增殖期)、 Ⅴ期 (增生期), 相应诊断标准如表 1 所示。

成像设备与技术
不同的成像设备拍摄出的影像数据形式不同, 从而会使影像标注方法与深度学习算法的性能产生 差异. 现阶段应用范围最广的两种成像技术为彩色眼底成像技术 (Color fundus photography, CFP) 以及光学相干断层扫描 (Optical coherence tomography, OCT) 技术.
眼底成像技术
1) 无赤光技术
在眼底成像中, 让光线通过特 制的滤光片, 以达到过滤短波光线的效果. 应用该 技术拍摄出的眼底影像会增加视网膜血管和背景的对比度, 也可以很容易地通过颜色区分脉络膜与视 网膜损害[9] . 由于该类影像所呈现的病理特征明确, 不同病理特征区分度明显, 使用该类影像作为深度 学习数据集可以有更好的效果。
2) 立体眼底成像技术.
眼底相机通过分光镜或 者通过不同角度的两次拍摄, 生成左右并列的图像 再通过立体镜识图, 得到立体成像[10] . 该类影像包 含隆起与凹陷的特征信息, 在进行深度学习时, 可 以通过该类信息进行更好的病征识别.
3) 共聚焦激光扫描技术.
全景数码摄像设备通 过共聚焦光学原理, 拍摄出更大视角的眼底图像. 这有利于检测位于边缘的病变特征. 另外, 眼底镜的镜头、光源特性等都会影响成 像的效果, 以至于影响深度学习的效果.
光学相干断层扫描技术
光学相干断层扫描技术是一种新型层析成像技 术, 能无损、快速地获得样品的高分辨断层图像, 它 可以对材料及生物系统内部微观结构进行高分辨率 横断面层析成像[11] . 它在眼科领域与传统成像技术 相比有以下几个优势:
1) 能获得人眼内各个断层的图像, 增大了医师 所获取的信息量;
2) 具有更高的分辨率, 医师可以对眼部某一特 定部位进行研究和分析[12] ;
3) 传统的眼底相机成像利用的是光的阻断特 性, 而 OCT 是利用了光的散射特性, 这可以获取与 传统眼底相机不同的信息;
4) 成像设备体积小;
5) 短时间内可获取大量数据
成像设备的发展趋势
从整体上来说, 成像设备的发展有两大趋势: 高技术化与便携化.
印度 Remidio 公司
2 基于深度学习的 DR 智能诊断系统 发展现状
2.1 最新发展现状
2.1.1 学术界进展
2.1.2 产业界进展
题. 2018 年 4 月, 世界首个获批用于 5 期 范家伟等: 深度学习方法在糖尿病视网膜病变诊断中的应用 987 DR 诊断的人工智能 (Artificial intelligence, AI) 产品 IDx-DR 美国上市
印度 Remidio 公司研发出了高质量便携式视网膜 成像设备 FOP (Fundus on phone)
2018 年 6 月, 中国第一个投入使 用的 AI 医疗机器人—— “嵩岳”医生
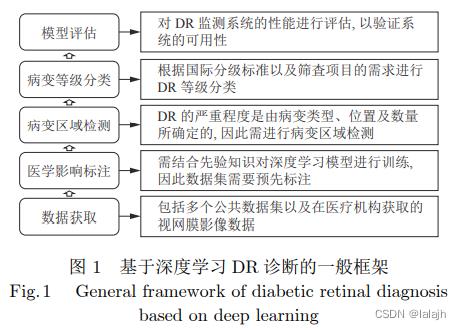
2.2 基于深度学习 DR 诊断的一般框架
DR 诊断的一般框架包括数据获取、医学影像 标注、病灶区域检测、病变等级分类及模型评估等 步骤. 如图 1 所示.
3 数据集及医学图像标注
3.1 公共数据集
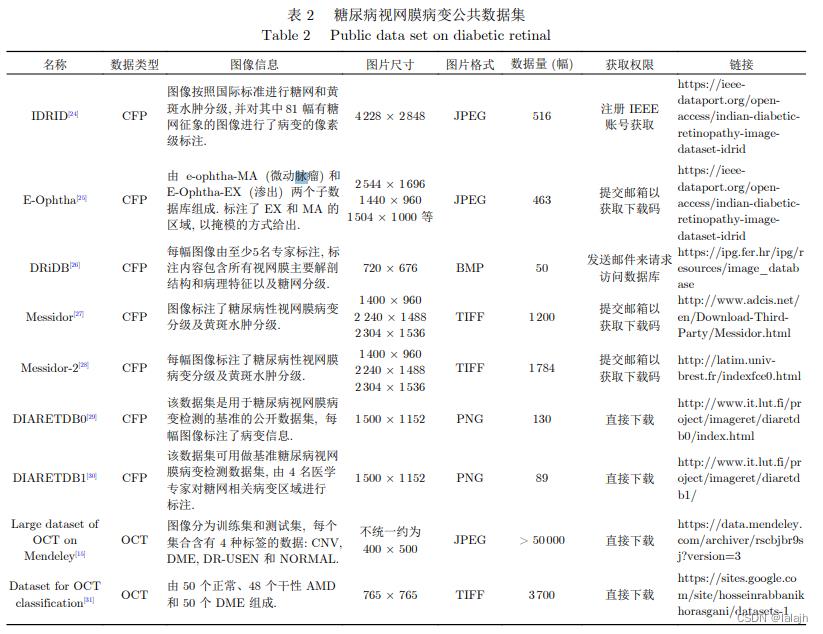
获得训练样本最直接的方式是直接使用公共数 据集, 不同数据集在仪器设备、拍摄角度、患病情况、 标注情况、图像样式、图像尺寸等方面都有较大的 区别, 开发者可根据自己不同的需求选用合适的数 据集. 详细内容如表 2 所示.
3.2 数据集的使用及数据预处理
在开发过程中, 通常会使用多种数据集. 因此 解决不同源数据集的成像差异成为一个重要的问 题. 差异主要表现为两点, 即设备差异和人种差异.
1) 设备差异
由于不同数据源所使用眼底设备不同, 在成像 分辨率、成像广度、色彩还原能力等方面有所差异. 因此为消除此类差异, 需要对图像进行预处理, 大 体分为以下两步: a) 尺寸归一化; b) 图像增强.
尺寸归一化可以将图像处理成相同规格; 图像增强技术能够增强病理特征,减弱不同成像设备光照强度、 色彩等方面的差异.。
现阶段图像增强技术已经发展的较为完善, 例 如以灰度变换、直方图均衡, 空域滤波为代表的空域增强技术; 以高斯滤波、巴特沃思滤波为代表的频域增强技术。
灰度变换通过对图像三个通道的灰度值分别进 行线性或非线性变换, 增大相邻像素的对比差. 直方图均衡通过对灰度直方图的变换, 达到增大局部 对比度的效果, 这些方法都达到了增强病症区域与 正常区域区别的效果, 使得模型可以获取更加明确 的特征.。频域增强技术通过低通滤波器, 过滤掉高 频的噪声, 在图像中表现为去掉了高亮的光斑, 使 得图像更加平滑.
2) 人种差异
不同人种的视网膜颜色特征、结构特征几乎无解剖学差异, 其差异主要体现为虹膜的颜色. 如果 期望在不同人种都有更好的泛化能力, 可以通过增 加各个人种的眼底数据集来实现. 中山大学团队[16] 搜集了不同国家和地区的不同人种的眼底照片, 标 注后用于模型的训练, 该模型在各个人种上都表现 出了很好的泛化能力。
3.3 图像标注
图像标注是医学影像智能诊断系统落地过程中 至关重要的一环, 它决定了 AI 算法的性能上限。
由 于公共数据集数据量相对不足, 在训练过程中难以 满足开发者的需求. 因此如何获得高质量的数据集, 如何科学合理的安排和进行标注成为首要问题。
3.3.1 标注工具
1) PC 机 + 电子病历.
2) 专业标注工具.
3) AI 辅助 + 专业标注工具
3.3.2 标注流程
由于每位专家可能只对一种或几种病灶特征比 较熟悉, 并且专家标准略有差异, 因此标注过程需 要统一的标准化流程以及经验丰富的专家团队, 以 下列举了三种标注流程。
1) 分级标注
2) 交叉标注
3) 众包标注
4 糖尿病视网膜病灶区域检测
4.1 病灶区域分割模型
4.1.1 Encoder-decoder 架构
对糖尿病视网膜病灶区域检测所应用的模型大 多是以 Encoder-decoder 架构为基础. 编码器通常 是以分类网络如 VGGNet[38]、ResNet[39] 等进行下采 样得到特征图 (Feature map); 解码器对特征图进 行上采样恢复目标细节和相应的空间维度, 最后将结果与标注影像像素进行匹配, 反复训练调整参数. 此处介绍两种比较流行的网络架构。
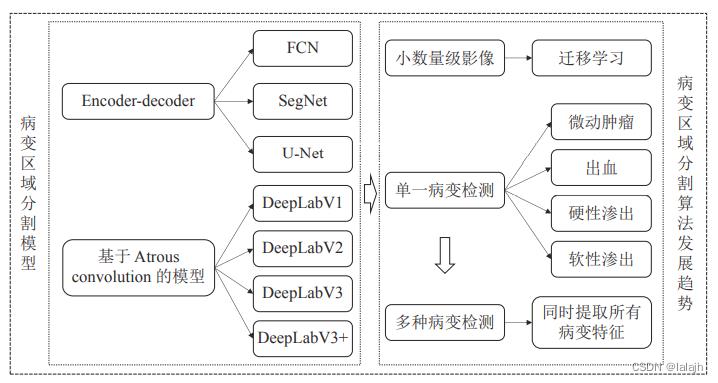
4.1.2 基于 Atrous convolution 的模型
基于 Atrous convolution 的模型解决了训练过 程中特征分辨率降低、图像多尺度、卷积模型平移 不变性的问题, 在糖尿病视网膜病灶区域检测中基于 Atrous convolution 的模型解决了训练过 程中特征分辨率降低、图像多尺度、卷积模型平移 不变性的问题, 在糖尿病视网膜病灶区域检测中。
4.2 迁移学习
训练深度神经网络需要大量的标注数据, 而医 学领域数据集的构建成本非常高, 因此需要一种在 有限数据资源下满足深度神经网络训练的方法.
其中, 解决这个问题的一种方法是数据增强, 通过对图像进行旋转、平移、裁剪等达到增大数据集的目的, 但是迄今为止使用的数据增强技术并没有创建真正的样本, 所以有待继续发展. 另外一种常用的有效的方法就是直接迁移学习[48] .
4.3 病灶区域检测相关研究
5 糖尿病视网膜病变等级分类
6 基于 OCT 影像的眼部疾病诊断
7 模型评估
以上是关于深度学习方法在糖尿病视网膜病变诊断中的应用的主要内容,如果未能解决你的问题,请参考以下文章
Python基于逻辑回归的糖尿病视网膜病变检测(数据集messidor_features.arff)