android开发,linerLayout里的统计图的刷新
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了android开发,linerLayout里的统计图的刷新相关的知识,希望对你有一定的参考价值。
我在一个界面中放了一个子linerlayout,用来显示饼状图,我想点击按钮后在这个linerlayout中换一个饼状图,就是刷新数据,怎么实现啊!!
参考技术A 点击刷新后,绘制你饼状图的View.postInvalidate ()就可以了。追问这是我的界面,我想选择不同的时间段会刷新统计图,刚才试了你说的那个方法,不知道是要写在哪里啊?chartPanel = new ChartPanel(this);
chartPanel.setChart(Example4());
imageview.addView(chartPanel);这里的imageview是linerlayout型的,谢谢啦,望可以帮忙解决问题啊
我觉得是在你选择时间段的时候,触发Spinner.OnItemSelectedListener, 在该回调中更新你的图表要使用到的数据,再调用chartPanel.postInvalidate ()应该是可以的
追问试过了,还是不行,求详细指教啊
参考技术B 把你工程发 看看, 可以弄测试工程给我。追问我加你qq吧
本回答被提问者采纳五 Oracle里的统计信息
成本值的计算是根据目标SQL所涉及的表、索引、列等相关对象的统计信息,运用CBO固有的成本值计算公示计算出来的。
什么是Oracle里的统计信息:
Oracle数据库里的统计信息是这样的一组数据:它存储在数据字典里,且从多个维度描述了Oracle数据库里对象的详细信息。
Oracle数据库里的统计信息可以分为如下6种类型:
- 表的统计信息
-
- 用于描述Oracle数据库里表的详细信息,它包含了一些典型的维度,如记录数、表块(表里的数据块)的数量、平均行长度等。
-
- 索引的统计信息
-
- 用于描述Oracle数据库里的索引的详细信息,它包含了一些典型的维度,如索引的层级、叶子块的数量、聚簇因子等。
-
- 列的统计信息
-
- 用于描述Oracle数据库里列的详细信息,它包含了一些典型的维度,如列的distinct值的数量、列的null值的数量、列的最小值、列的最大值以及直方图等。
-
- 系统统计信息
-
- 用于描述Oracle数据库所在的数据库服务器的系统处理能力,它包含了CPU和I/O这两个维度,借助这些,Oralce可以更清楚地知道目标数据库服务器的实际处理能力。
-
- 数据字典统计信息
-
- 用于描述Oracle数据库里数据字典基表(如TAB$,IND$等)、数据字典基表上的索引,以及这些数据字典基表的列的详细信息。
-
- 内部对象统计信息
-
- 用于描述Oracle数据库里的一些内部表(如X$系列表)的详细信息,它的维度和普通表的统计信息的维度类似,只不过其表块的数量为0,因为X$系列表实际上只是Oracle自定义的内存结构,并不占用实际的物理存储空间。
-
5.2 Oralce里收集与查看统计信息的方法
5.2.1 收集统计信息
有两种方法:
- ANALYZE命令
- DBMS_STATS包
-
- 表、索引、列、数据字典的统计信息用两种方法都行
- 系统统计信息和内部对象统计信息只能用DBMS_STATS包来收集
5.3.1.1 用ANALYZE命令收集统计信息
5.2.1.3 ANALYZE和DBMS_STATS的区别
ANALYZE和DBMS_STATS相比存在如下缺陷:
(1)ANALYZE命令不能正确地收集分区表的统计信息,而DBMS_STATS包却可以。
(2)ANALYZE命令不能并行收集统计信息,而DBMS_STATS包却可以。
5.2.2 查看统计信息
5.4索引统计信息
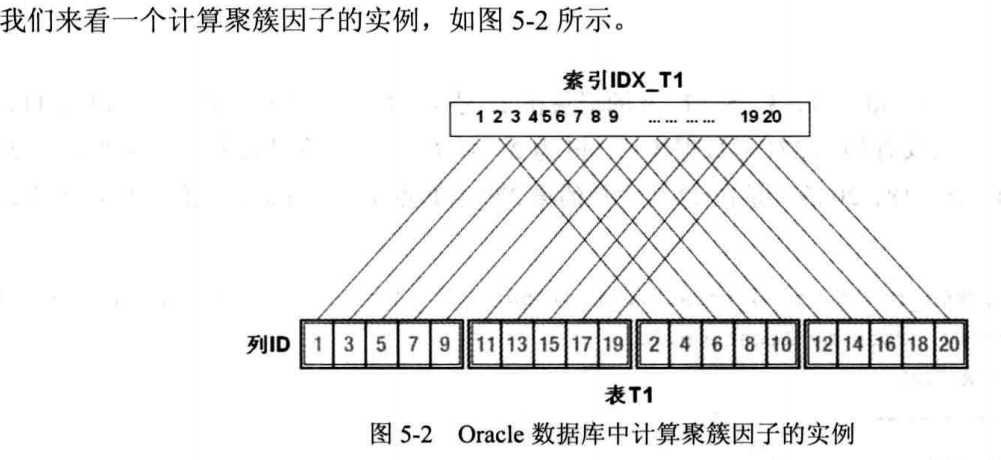
索引统计信息维度中我们需要重点关注的是BLEVEL(索引层级)、LEAF_BLOCKS(索引叶子快数量)和CLUSTERING_FACTOR(聚簇因子),它们在CBO计算访问索引成本的过程中扮演者举足轻重的作用。
5.4.2 聚簇因子的含义及重要性
聚簇因子是指按照索引键值排序的索引行和存储于对应表中数据行的存储顺序的相似程度。(就是表中列的存储顺序和索引的值存储顺序越相似越好)
如果聚簇因子低,则说明索引行和存储于对应表中数据行的存储顺序相似,相邻行所对应的rowid极有可能处于同一个表块中,即Oralce在通过索引行记录的rowid回表第一次去读取对应的表块并将该表块缓存在buffer cashe中后,当再通过相邻索引行记录的rowid回表第二次去读取对应的表块时,就不需要再产生物理I/O了,因为这次要访问的和上次已经访问过的表块是同一个块,Oracle已经将其缓存在了buffer cache中。如果聚簇因子值大,则第二次通过rowid回表的时候,可能还会产生物理I/O,因此这次要访问的和上次已经访问的表块并不是同一个块。
换句话说,聚簇因子高的索引走索引范围扫描时比相同条件下聚簇因子低的索引要耗费更多的物理I/O,所以成本会更高。
以上是关于android开发,linerLayout里的统计图的刷新的主要内容,如果未能解决你的问题,请参考以下文章
用eclipse开发android时两个文本组件总是重叠的,怎么解决