跟着动画学习 GO 数据结构之 Go 链表
Posted 宇宙之一粟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了跟着动画学习 GO 数据结构之 Go 链表相关的知识,希望对你有一定的参考价值。
介绍
我们知道 Go 的数组和切片非常方便对数据进行访问,但是假如我们有一个长度为 5 的数组 [1, 2, 3, 4, 5],想要往其中 3 和 4 之间插入一个元素 6,就往往不是非常容易了。为啥呢?
一般解决的方法是首先创建一个长度大于 5 的新数组,因为这个数组的长度首先要能存储旧数组的数组,同时能有多余的位置存储新增加的元素 6。
这其中有个操作会很费时,就是复制操作:需要把原来数组中的数据复制到新的内存空间。
因此,我们有一个更合适的数据结构叫做链表。
链表
链表由一系列节点构成,每个节点就是一个记录。链表是一种递归的数据结构,它要么为空(null),或者是指向一个节点的引用,英文叫 Linked List。通常由许多的元素构成,这些元素也叫节点(node),节点由两部分构成:数据域和指针域。
- 数据域:数据域用来存储数据,可以存储基本数据类型如整型,也可以存储其他复杂数据类型。
- 指针域:指针域部分用来存储链表中下一个元素的地址。

节点的 UML 图如下:

节点的代码表示:
type Node struct
data int
next *Node
链表的类型
链表有很多种类型,其主要的区别是节点引用方式的区别:单向、双向、首尾连接。
单链表
单链表就是单向的,
每一个节点都有一个指向下一个节点的引用,除了最后一个节点。节点的引用部分包含下一个节点的地址。 最后一个节点的引用部分包含值 null。

双链表
双链表是双向的,双链表中的节点同时引用了链表中的上一个和下一个节点。

现实生活中一个双链表的地址就是我们的地铁的某条线路,每条线路都有一个来回,而每一个站点就是一个节点:

环形链表
这种类型类似于单向链表,只是最后一个元素引用了链表的第一个节点。 最后一个节点的链接部分包含第一个节点的地址。

- Head:Head 是一个引用,保存着链表中第一个节点的地址。
- 节点:链表中的项目称为节点。
- 值:链表的每个节点中存储的数据。
- 引用:节点的链接部分用于存储其他节点的引用。我们将使用“next”和“prev”来存储下一个或上一个节点的地址。
单链表的操作
链表的操作也不外乎于增删改查,再加上一些特定的操作。链表是一种动态的数据结构,数据结构栈和队列都可以用链表实现的。链表的创建、添加和删除操作很容易;当元素被动态添加时,会消耗更多的内存,因为动态数据结构并不固定。

- 遍历:像数据那样随机检索在单链表中是不可能的,因为需要遍历节点来寻找一个定位的节点。
- 增加:插入单链表可以在列表的开头或结尾,以及指定节点之后。(头插、尾插、指定位置插入)
- 删除:删除可以发生在列表的开始或结束处,以及在一个指定的节点之后。
- 判空:判断一个链表是否为空
- 获取链表长度
- 查找是否包含指定值
- 反转:面试高频题
创建单链表
定义链表的结构体:
链表的节点包含一个指向下一个节点的指针,每一个节点都保存一个数据域。
通常的做法是把数据域定义为接口 interface:
type Node struct
data interface // 数据域: 链表不要求全为相同的类型,所以利用一个接口在存储数据
next *Node // 指针域:指向下一个节点
链表通常由头节点(指向第一个节点的指针)和它的长度组成。长度域 size 存储了链表的长度,头结点 headNode 存储了链表头结点或者第一个节点(首元节点)的内存地址:
// define a ListNode in a singly linked list
type LinkedList struct
headNode *Node // 头节点
size int // 存储链表的长度
创建一个单链表:
func CreateLinkList() *LinkedList
// 创建一个空的头节点
node := new(Node)
l := new(LinkedList)
l.headNode = node
return l
链表的长度
// 返回链表的长度
func (linkedList *LinkedList) Length() int
return linkedList.Count()
func (linkedList *LinkedList) Count() int
size := 0
currNode := linkedList.headNode
for currNode != nil
size++
currNode = currNode.next
return size
链表判空
func (linkedList *LinkedList) isNull() bool
return linkedList.size == 0
插入元素
- 头插
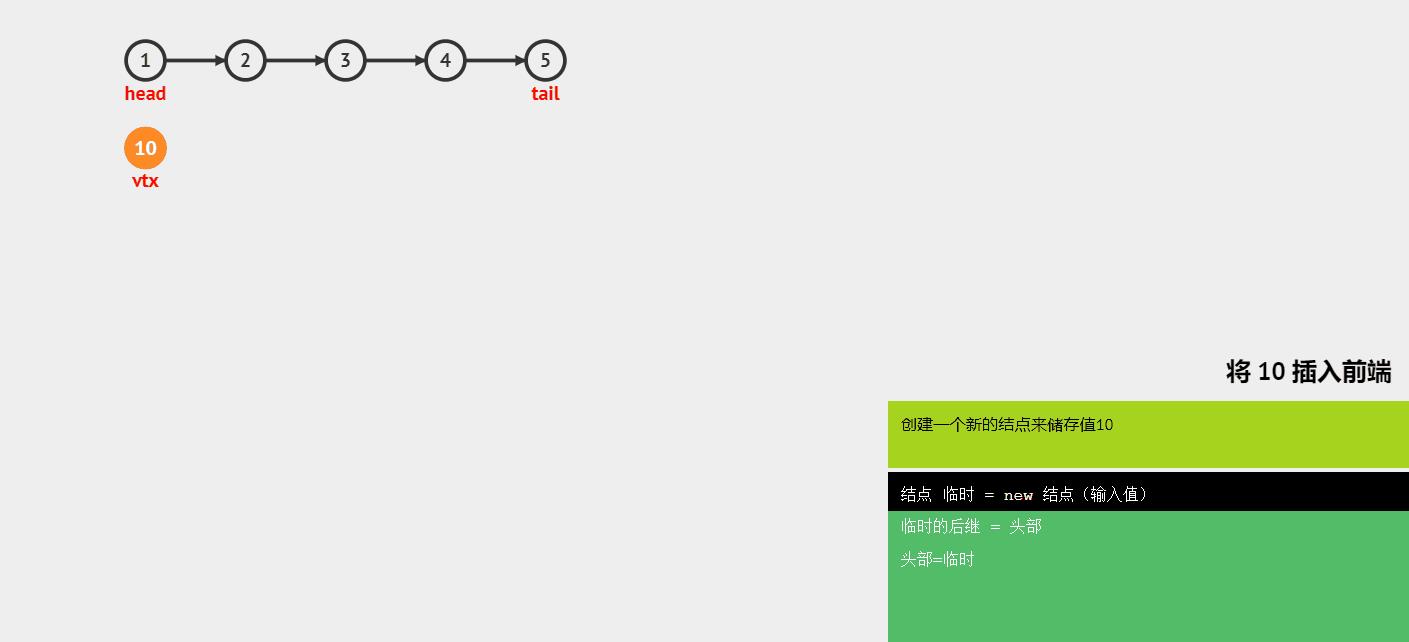
- 中间插入
图解:
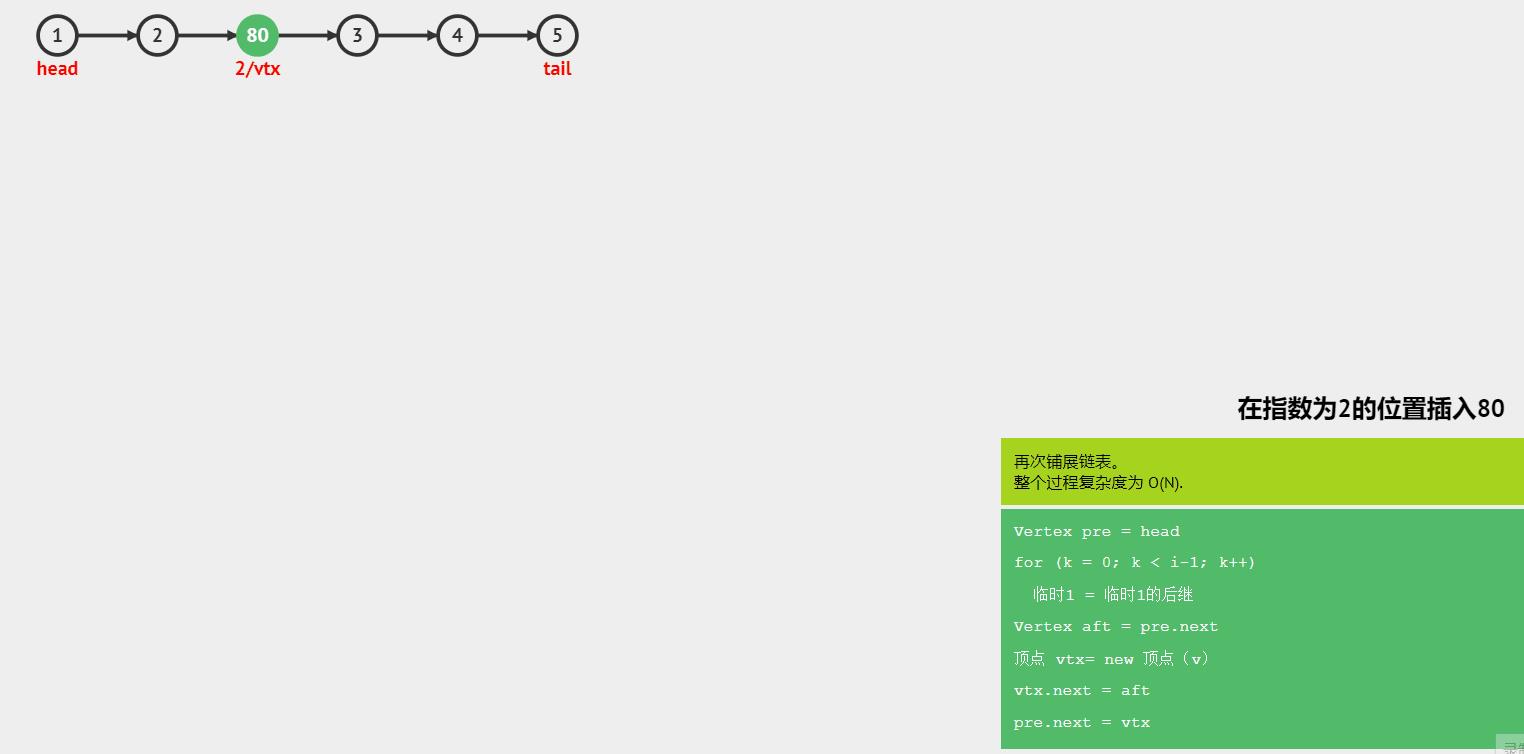
函数如下:
// Insert adds an item at position i
func (linkedList *LinkedList) Insert(pos int, v interface)
// 先检查待插入的位置是否正确
if pos < 1 || pos > linkedList.size+1
fmt.Println("Index out of bounds")
newNode := &Nodedata: v
var prev, current *Node
prev = nil
current = linkedList.headNode
for pos > 1
prev = current
current = current.next
pos = pos - 1
if prev != nil
prev.next = newNode
newNode.next = current
else
newNode.next = current
linkedList.headNode = newNode
linkedList.size++
- 尾插
图解:
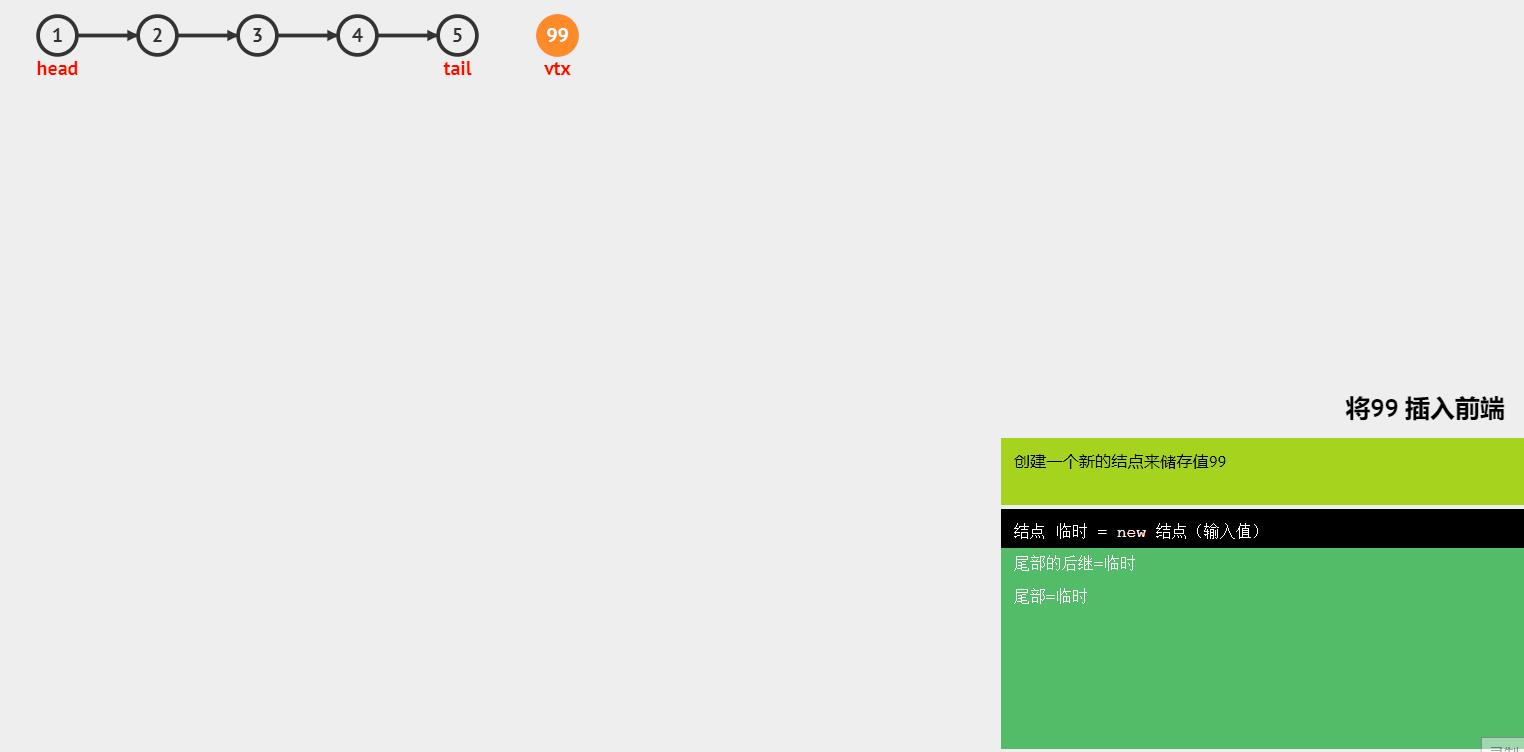
函数如下:
func (linkedList *LinkedList) Append(v interface)
node := &Nodedata: v
if linkedList.isNull()
linkedList.headNode = node
else
currNode := linkedList.headNode
for currNode.next != nil
currNode = currNode.next
currNode.next = node
linkedList.size++
遍历元素
假设 head 指针指向链表的第一个节点,为了遍历整个链表,我们需要进行如下几步操作:
- 跟随每个指针
- 随着每次遍历,记录下每个节点的数据(或者 count 计数)
- 当最后一个指针为空
nil时,停止遍历
图解如下:

函数如下:
func (linkedList *LinkedList) Traverse()
if linkedList.isNull()
fmt.Println("The LinkedList is empty")
currNode := linkedList.headNode
for currNode != nil
fmt.Printf("%v -> ", currNode.data)
currNode = currNode.next
fmt.Println()
删除元素
- 头部删除
图解

函数如下:
func (linkedList *LinkedList) DeleteFirst() interface
if linkedList.isNull()
fmt.Println("deleteFirst: List is empty")
data := linkedList.headNode.data
linkedList.headNode = linkedList.headNode.next
linkedList.size--
return data
- 中间删除
图解:
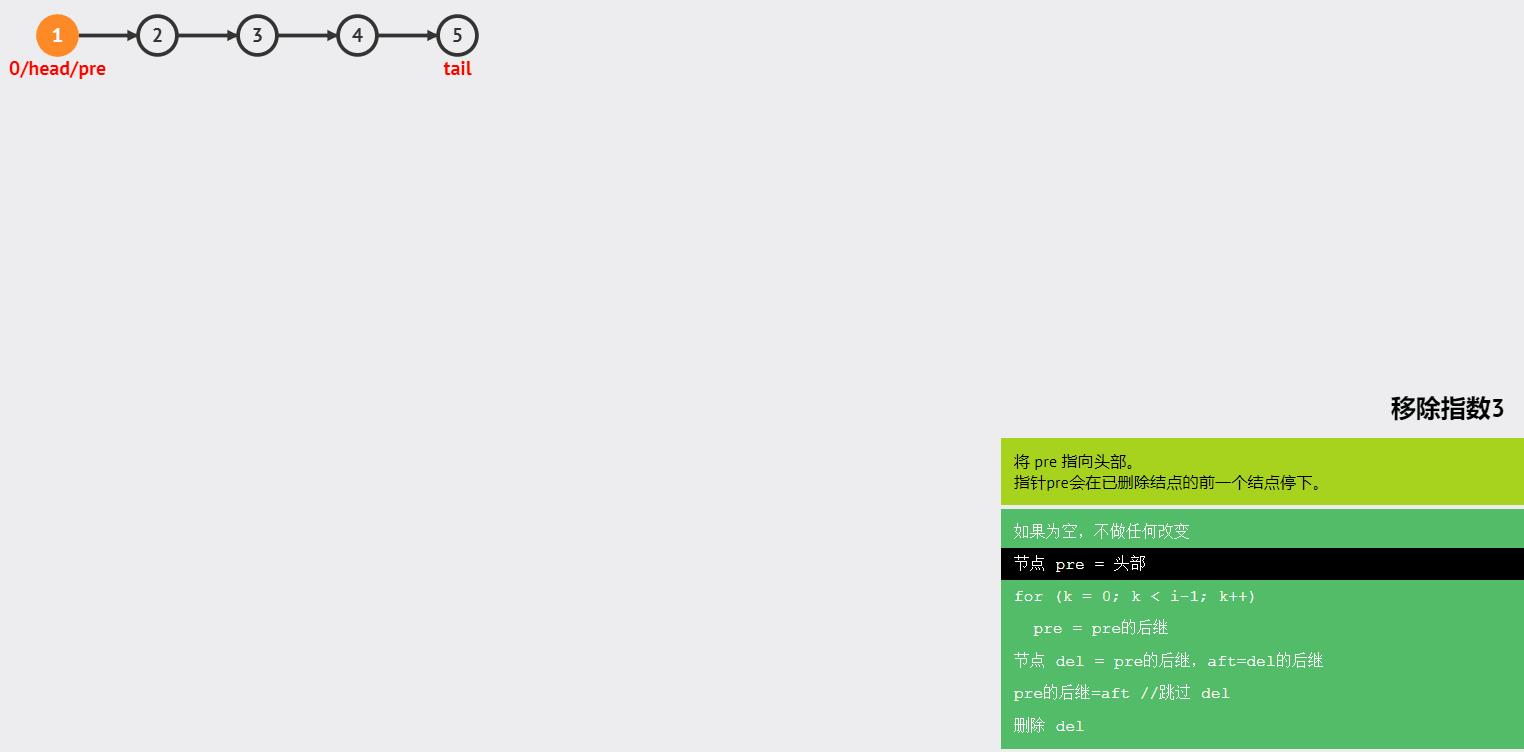
函数如下:
func (linkedList *LinkedList) Delete(pos int) interface
if pos < 1 || pos > linkedList.size+1
fmt.Println("delete: Index out of bounds")
var prev, current *Node
prev = nil
current = linkedList.headNode
p := 0
if pos == 1
linkedList.headNode = linkedList.headNode.next
else
for p != pos-1
p = p + 1
prev = current
current = current.next
if current != nil
prev.next = current.next
linkedList.size--
return current.data
- 尾部删除
图解:
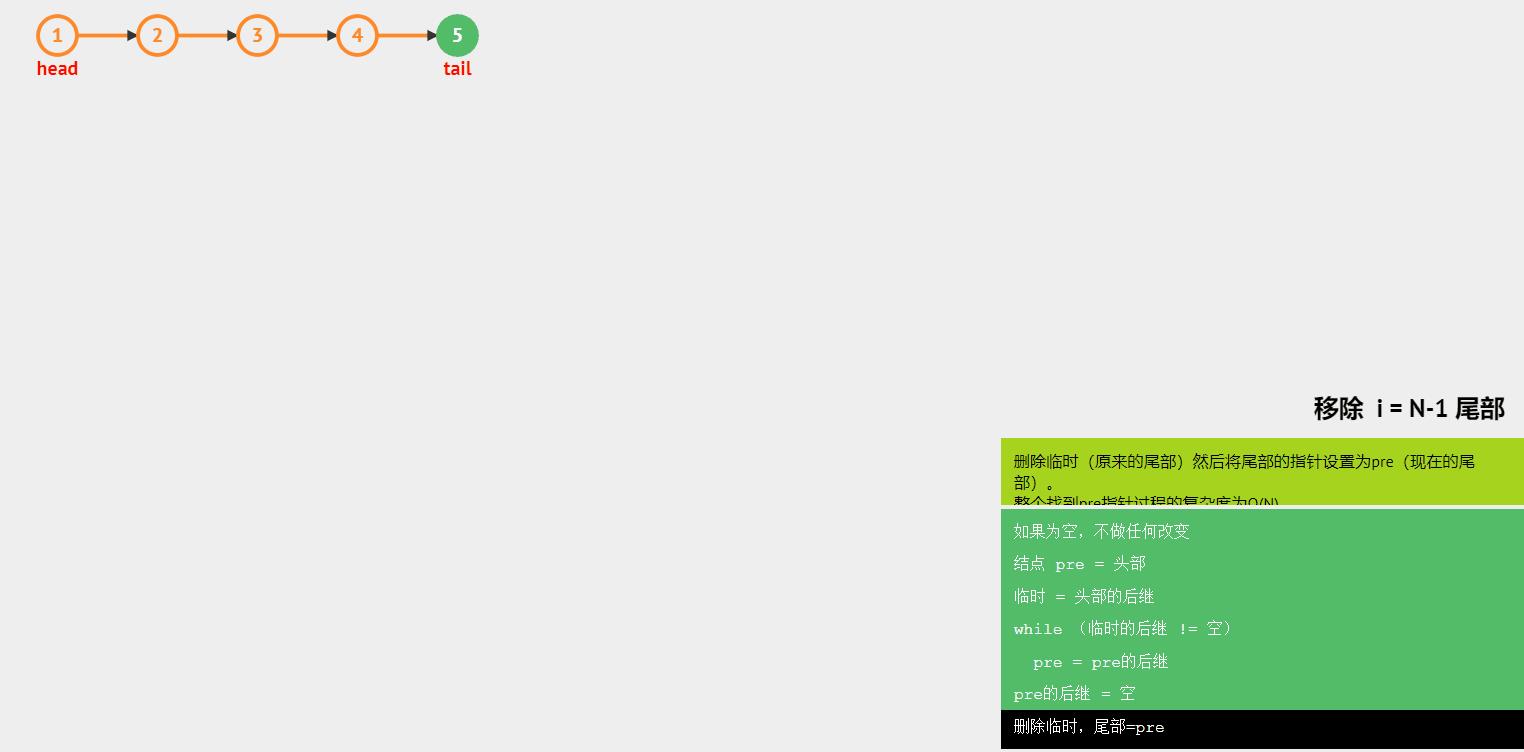
函数如下:
func (linkedList *LinkedList) DeleteLast() interface
if linkedList.isNull()
fmt.Println("deleteLast: List is empty")
var prev *Node
current := linkedList.headNode
for current.next != nil
prev = current
current = current.next
if prev != nil
prev.next = nil
else
linkedList.headNode = nil
linkedList.size--
return current.data
总结
好了有了上述函数,我们可以汇总到一起来检验我们的函数是否正确,创建一个 main.go 文件:
package main
import "fmt"
type Node struct
data interface
next *Node
type LinkedList struct
headNode *Node // 头节点
size int // 存储链表的长度
func CreateLinkList() *LinkedList
// 创建一个空的头节点
node := new(Node)
l := new(LinkedList)
l.headNode = node
return l
// 返回链表的长度
func (linkedList *LinkedList) Length() int
return linkedList.Count()
func (linkedList *LinkedList) Count() int
size := 0
currNode := linkedList.headNode
for currNode != nil
size++
currNode = currNode.next
return size
func (linkedList *LinkedList) isNull() bool
return linkedList.size == 0
func (linkedList *LinkedList) Traverse()
if linkedList.isNull()
fmt.Println("The LinkedList is empty")
currNode := linkedList.headNode
for currNode != nil
fmt.Printf("%v -> ", currNode.data)
currNode = currNode.next
fmt.Println()
return
func (linkedList *LinkedList) InsertHead(v interface)
node := &Nodedata: v
if linkedList.isNull()
linkedList.headNode = node
linkedList.size++
return
else
node.next = linkedList.headNode
linkedList.headNode = node
linkedList.size++
return
func (linkedList *LinkedList) Append(v interface)
node := &Nodedata: v
if linkedList.isNull()
linkedList.headNode = node
else
currNode := linkedList.headNode
for currNode.next != nil
currNode = currNode.next
currNode.next = node
linkedList.size++
// Insert adds an item at position i
func (linkedList *LinkedList) Insert(pos int, v interface)
// 先检查待插入的位置是否正确
if pos < 1 || pos > linkedList.size+1
跟着动画学 Go 数据结构之 Go 实现栈#私藏项目实操分享#