EKS 训练营-日志收集 EFK(14)
Posted wzlinux
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了EKS 训练营-日志收集 EFK(14)相关的知识,希望对你有一定的参考价值。
介绍
应用程序和系统日志可以帮助我们了解集群内部的运行情况,日志对于我们调试问题和监视集群情况也是非常有用的。而且大部分的应用都会有日志记录,对于传统的应用大部分都会写入到本地的日志文件之中。对于容器化应用程序来说则更简单,只需要将日志信息写入到 stdout 和 stderr 即可,容器默认情况下就会把这些日志输出到宿主机上的一个 JSON 文件之中,同样我们也可以通过 docker logs 或者 kubectl logs 来查看到对应的日志信息。
但是,通常来说容器引擎或运行时提供的功能不足以记录完整的日志信息,比如,如果容器崩溃了、Pod 被驱逐了或者节点挂掉了,我们仍然也希望访问应用程序的日志。所以,日志应该独立于节点、Pod 或容器的生命周期,这种设计方式被称为 cluster-level-logging,即完全独立于 Kubernetes 系统,需要自己提供单独的日志后端存储、分析和查询工具。
日志收集方案
Kubernetes 集群本身不提供日志收集的解决方案,一般来说有主要的 3 种方案来做日志收集:
-
在节点上运行一个 agent 来收集日志
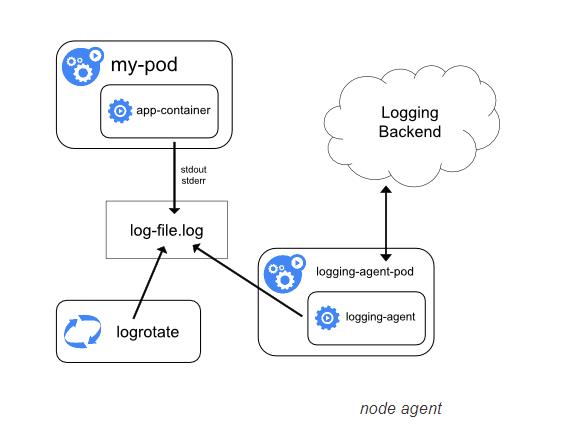
-
在 Pod 中包含一个 sidecar 容器来收集应用日志
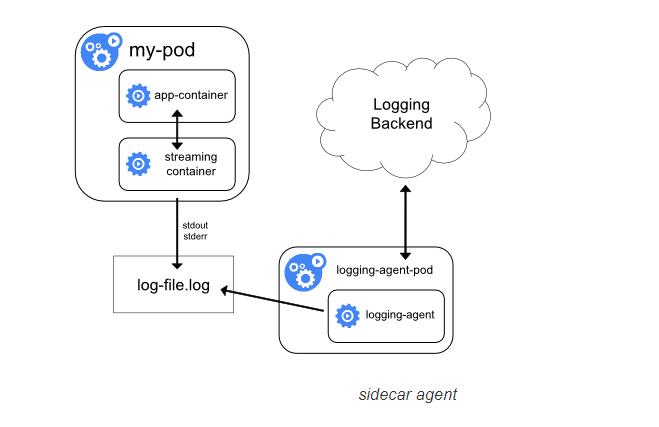
-
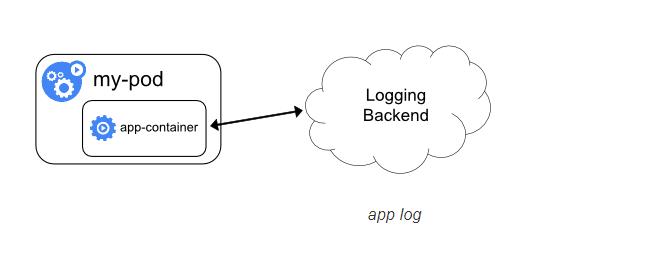
直接在应用程序中将日志信息推送到采集后端
Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch、Fluentd 和 Kibana(EFK)技术栈,也是官方现在比较推荐的一种方案。
Elasticsearch 是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大量日志数据,也可用于搜索许多不同类型的文档。
Elasticsearch 通常与 Kibana 一起部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 允许你通过 web 界面来浏览 Elasticsearch 日志数据。
Fluentd是一个流行的开源数据收集器,我们将在 Kubernetes 集群节点上安装 Fluentd,通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
Fluentd 是一个高效的日志聚合器,是用 Ruby 编写的,并且可以很好地扩展。对于大部分企业来说,Fluentd 足够高效并且消耗的资源相对较少,另外一个工具Fluent-bit更轻量级,占用资源更少,但是插件相对 Fluentd 来说不够丰富,所以整体来说,Fluentd 更加成熟,使用更加广泛,所以我们这里也同样使用 Fluentd 来作为日志收集工具。
我们先来配置启动一个可扩展的 Elasticsearch 集群,然后在 Kubernetes 集群中创建一个 Kibana 应用,最后通过 DaemonSet 来运行 Fluentd,以便它在每个 Kubernetes 工作节点上都可以运行一个 Pod。
创建 ES 集群
为了简便,我们这里使用 AWS 全托管的 ES 服务,服务将会开启精细访问服务,先设定几个环境变量:
# name of our elasticsearch cluster
export ES_DOMAIN_NAME="eks-logging"
# Elasticsearch version
export ES_VERSION="7.10"
# kibana admin user
export ES_DOMAIN_USER="admin"
# kibana admin password
export ES_DOMAIN_PASSWORD="Wangzan@18"创建 ES 集群
# Download and update the template using the variables created previously
mkdir ~/environment/logging/ && cd ~/environment/logging/
curl -sS https://raw.githubusercontent.com/wangzan18/jenkins-agent-k8s-cicd/master/logging/es-domain.json \\
| envsubst > ~/environment/logging/es_domain.json
# Create the cluster
aws es create-elasticsearch-domain \\
--cli-input-json file://~/environment/logging/es_domain.json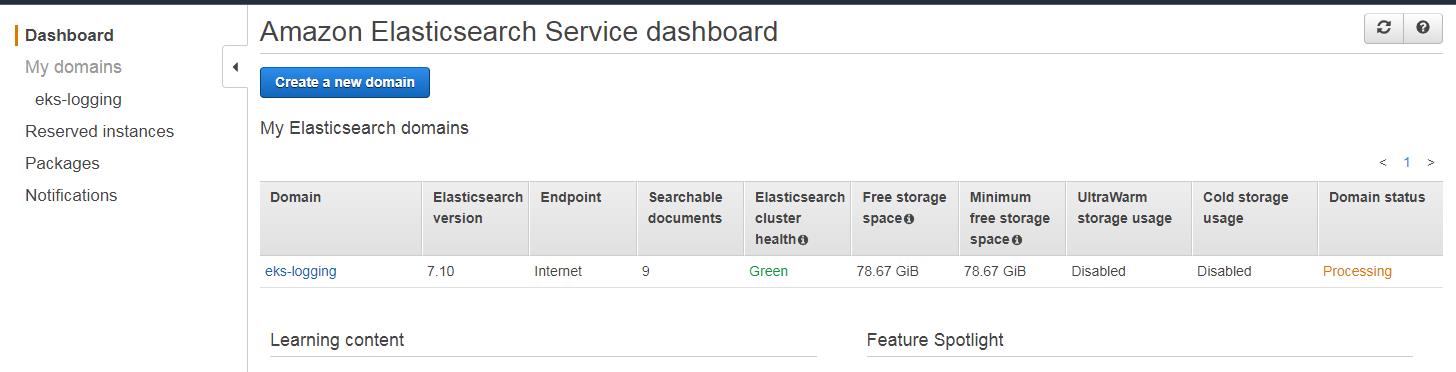
为 Fluent bit 配置 IRSA
我们为 ES 开启了精细访问控制,因为 fluent 需要向 ElasticSearch 通信,我们需要为这个 fluent 创建一个具有基本权限的 serviceAccount,这里即便给了很大的权限也是无法写入 ES 集群的,请自行替换 Resource 里面的参数。
cd ~/environment/logging/
cat <<EoF > ~/environment/logging/fluent-bit-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"es:ESHttp*"
],
"Resource": "arn:aws:es:eu-west-1:921283538843:domain/eks-logging",
"Effect": "Allow"
}
]
}
EoF
aws iam create-policy \\
--policy-name fluent-bit-policy \\
--policy-document file://~/environment/logging/fluent-bit-policy.json创建 serviceAccount
为 fluent serviceAccount 创建 IAM 角色。
kubectl create namespace logging
eksctl create iamserviceaccount \\
--name fluent-bit \\
--namespace logging \\
--cluster my-cluster \\
--attach-policy-arn "arn:aws:iam::921283538843:policy/fluent-bit-policy" \\
--approve \\
--override-existing-serviceaccounts确认一下创建的 serviceAccount 已经 annotated 相应的角色。
kubectl -n logging describe sa fluent-bit输出如下:
Name: fluent-bit
Namespace: logging
Labels: app.kubernetes.io/managed-by=eksctl
Annotations: eks.amazonaws.com/role-arn: arn:aws:iam::921283538843:role/eksctl-my-cluster-addon-iamserviceaccount-lo-Role1-1628KE9D9FMEO
Image pull secrets: <none>
Mountable secrets: fluent-bit-token-kjqnh
Tokens: fluent-bit-token-kjqnh
Events: <none>配置 ES 访问权限
角色映射是精细访问控制的最重要的方面。精细访问控制具有一些预定义的角色来帮助您入门,但除非您将角色映射到用户,否则,向集群发出的每个请求都会以权限错误结束。
Backend roles,提供了另一种将角色映射到用户的方法。您可以将同一角色映射到单个后端角色,然后确保所有用户都具有该后端角色,而不是将同一角色映射到几十个不同的用户。后端角色可以是 IAM 角色或任意字符串。
有上面的结果我们可以知道 fluent 的 serviceAccount 的 IAM 角色为:
arn:aws:iam::921283538843:role/eksctl-my-cluster-addon-iamserviceaccount-lo-Role1-1628KE9D9FMEO因为 ES 已经创建好了,我们使用提前定义的账户和密码登陆进去,然后选择 Open Distro for Elasticsearch --> Security --> Roles --> all_access --> Mapped users --> Manage mapping 加上上面的角色。
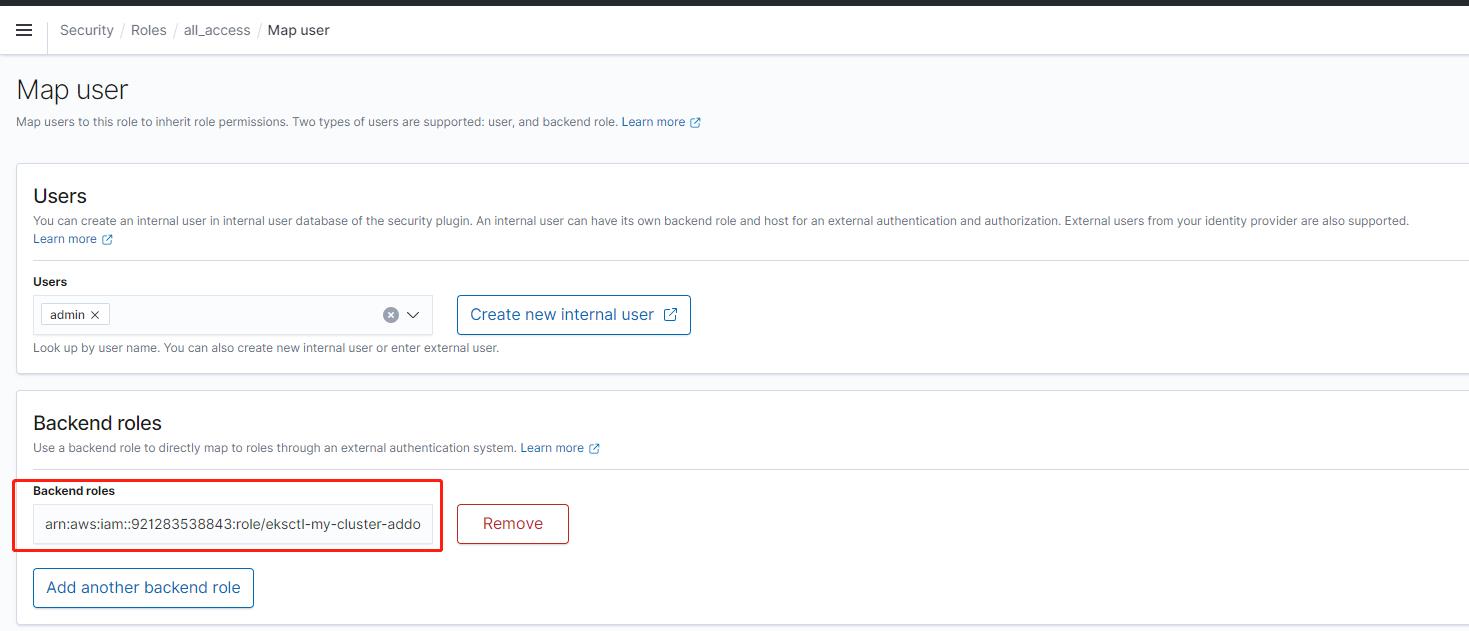
也可以使用我们定义好的账户访问 ES 接口添加权限
# We need to retrieve the Fluent Bit Role ARN
export FLUENTBIT_ROLE=$(eksctl get iamserviceaccount --cluster my-cluster --namespace logging -o json | jq \'.[].status.roleARN\' -r)
# Get the Elasticsearch Endpoint
export ES_ENDPOINT=$(aws es describe-elasticsearch-domain --domain-name ${ES_DOMAIN_NAME} --output text --query "DomainStatus.Endpoint")
# Update the Elasticsearch internal database
curl -sS -u "${ES_DOMAIN_USER}:${ES_DOMAIN_PASSWORD}" \\
-X PATCH \\
https://${ES_ENDPOINT}/_opendistro/_security/api/rolesmapping/all_access?pretty \\
-H \'Content-Type: application/json\' \\
-d\'
[
{
"op": "add", "path": "/backend_roles", "value": ["\'${FLUENTBIT_ROLE}\'"]
}
]
\'现在我们使用自己的 IAM user 打开 Console,可以看到会有下面的报错
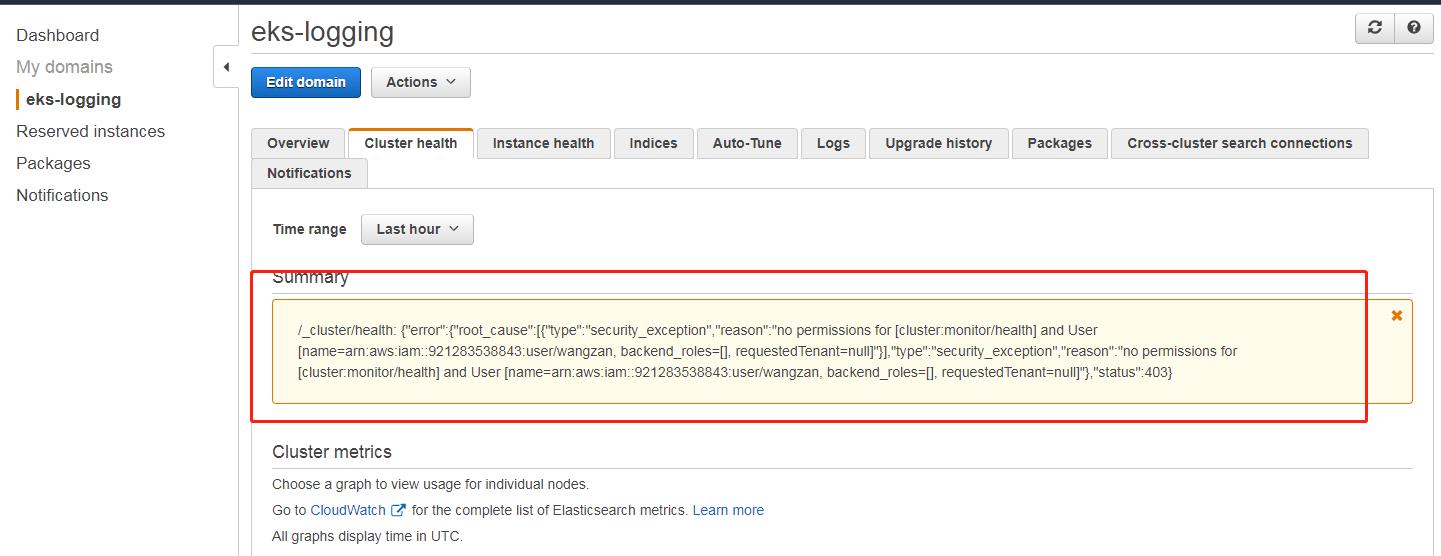
虽然我们的 IAM user 具有最高权限,但是因为开启的精细访问,这里也会显示没有权限,按照上面的方式,我们可以把自己的 IAM user 也 Map user 里面的 user。
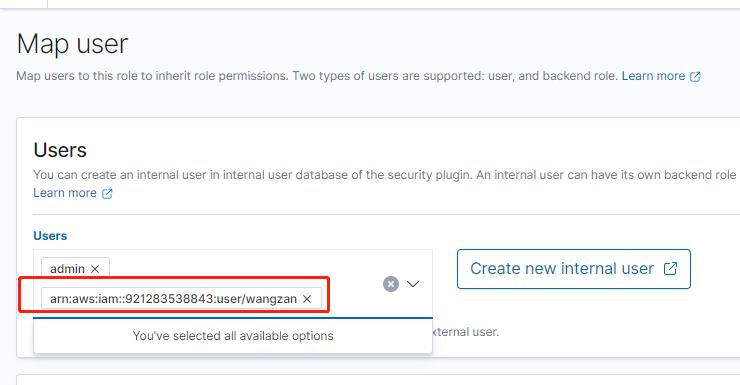
部署 fluent bit
下载 fluent bit yaml 文件,修改其中一些参数
cd ~/environment/logging
# get the Elasticsearch Endpoint
export ES_ENDPOINT=$(aws es describe-elasticsearch-domain --domain-name ${ES_DOMAIN_NAME} --output text --query "DomainStatus.Endpoint")
curl -Ss https://raw.githubusercontent.com/wangzan18/jenkins-agent-k8s-cicd/master/logging/fluentbit.yaml \\
| envsubst > ~/environment/logging/fluentbit.yaml可以查看文件清单,确认一下要部署的资源,然后我们进行部署:
kubectl apply -f ~/environment/logging/fluentbit.yaml部署的为 DaemonSet,每个 node 上面都会部署一个 fluent 来收取日志。
wangzan:~/environment/logging $ kubectl --namespace=logging get pods
NAME READY STATUS RESTARTS AGE
fluent-bit-cfqrn 1/1 Running 0 60s
fluent-bit-cnfbl 1/1 Running 0 60s
fluent-bit-n46wq 1/1 Running 0 60s
fluent-bit-zhbxn 1/1 Running 0 60sKibana 可视化
登陆到 Kibana 系统之后,我们选择 Kibana ---> Discover,选择创建 index。
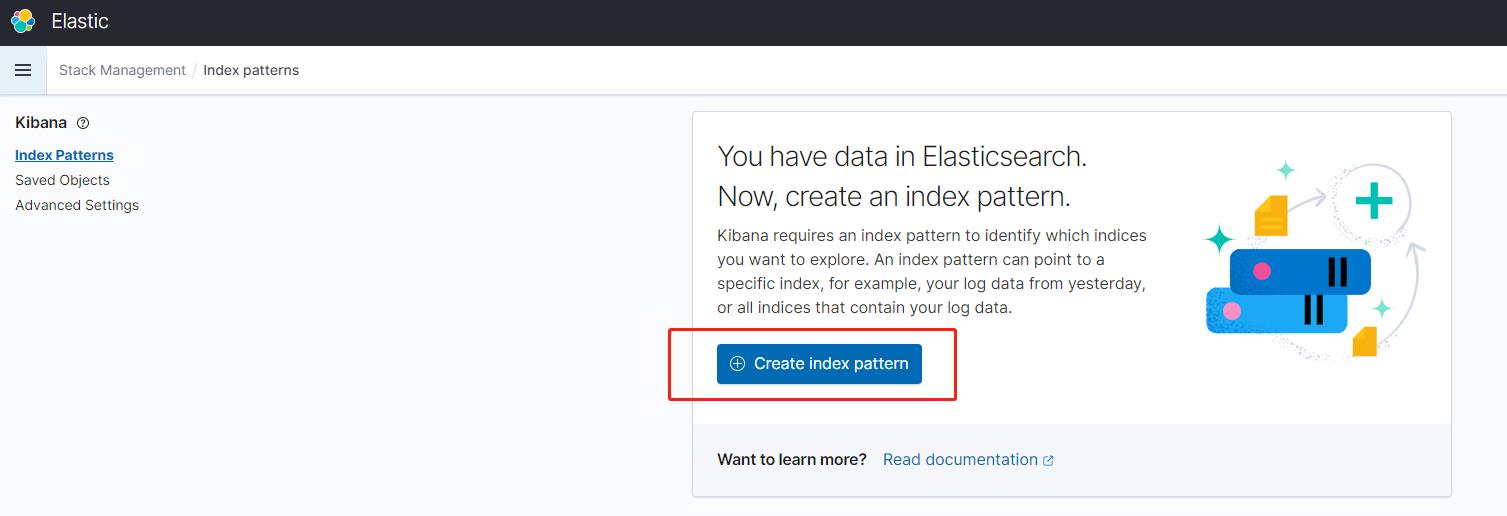
输入 index pattern 的名字,然后点击下一步
我们选择 @timestamp
然后再点击 Discover,就可以看到日志了。
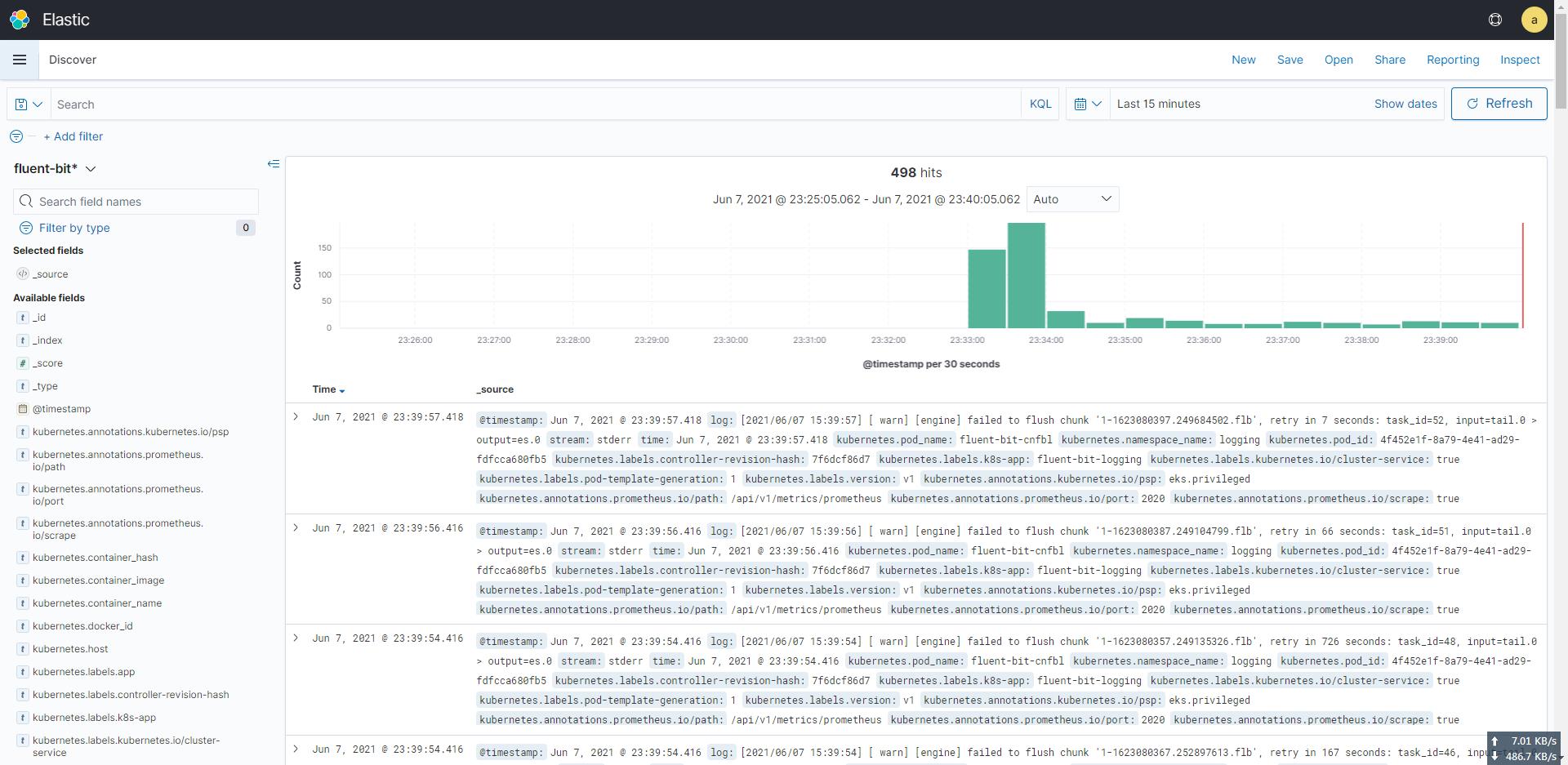
问题处理
我们在 ES 的界面中,可以看到大量的 fluent bit 的错误报告,内容如下:
[2021/06/17 01:46:35] [ warn] [engine] failed to flush chunk \'1-1623894315.231527444.flb\', retry in 359 seconds: task_id=1825, input=tail.0 > output=es.0我们再去查看 fluent bit 的 Pod ,查看报错日志,会有一个 400 错误,尽量查看新创建的 Pod:
"index": {
"_index": "fluent-bit",
"_type": "_doc",
"_id": "TUx4E3oB4v1-EVN7WM4m",
"status": 400,
"error": {
"type": "mapper_parsing_exception",
"reason": "Could not dynamically add mapping for field [app.kubernetes.io/name]. Existing mapping for [kubernetes.labels.app] must be of type object but found [text]."
}
}我们看到,当 fluent bit 去动态创建 mapping 的时候,无法创建,我们再去查看一下 ES 的 mapping。
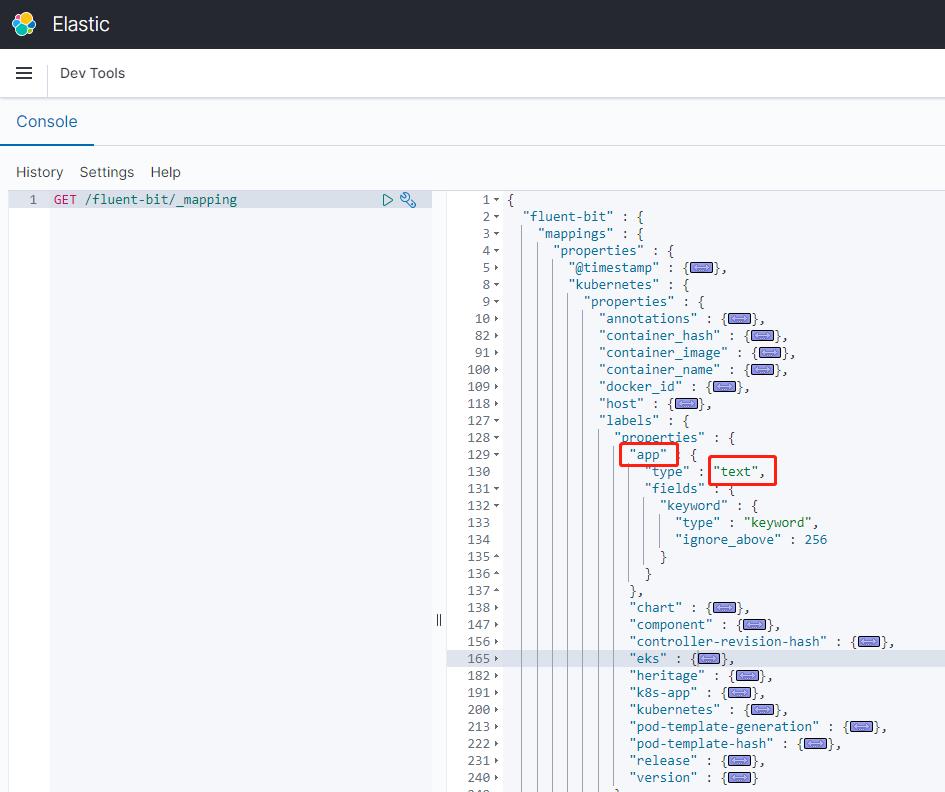
这里的 app 类型为 text,无法被创建,为什么会出现这样的问题呢?
我们去查看一下部署的 Pod,发现其中有些 Pod 同时有如下的一些 lable:
app.kubernetes.io/name:
app.kubernetes.io/instance:
app:一般来说,若您没有特别设定,当数据写入 ES 的时候,该 index 的 index mapping 便会自动被建立,并且随着数据格式的改变动态地调整 index mapping,因为有 app 这个 label,创建了如上的 mapping,当再创建含有”kubernetes.labels.app.kubernetes.io/name” 的栏位数据写入时, ES无法动态地将”kubernetes.labels.app” 由 text 转为 object,因此出现 http 400 mapper_parsing_exception 这样的错误信息。
小测试
我们可以对 ES Dev Tools 进行一下测试,我们手动写入一份数据:
PUT fluent-bit-test-001/_doc/1
{
"kubernetes":
{
"labels":
{
"app":"test"
}
}
}然后查看一下 ES 自动创建的 Index mapping。
GET /fluent-bit-test-001/_mapping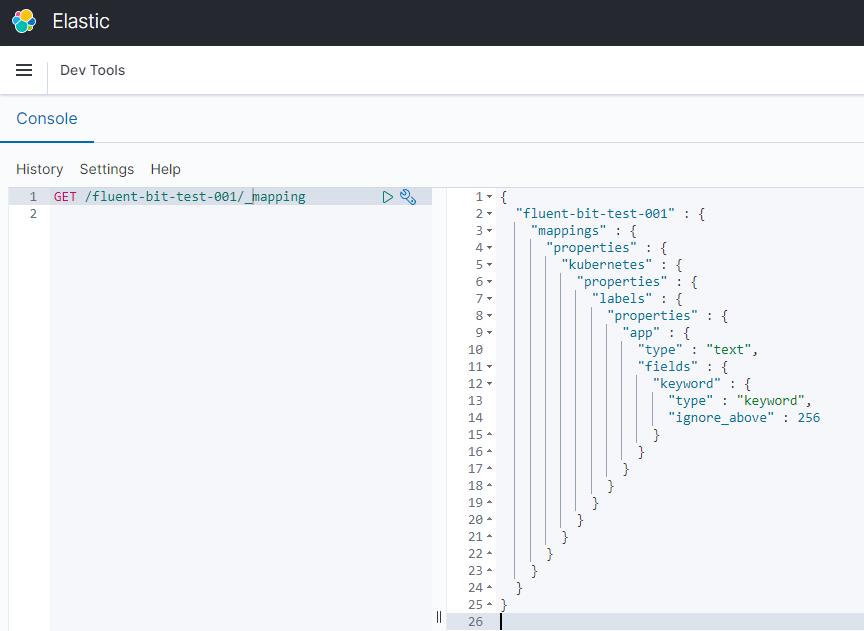
若我再写一笔数据至fluent-bit-test-001。
PUT fluent-bit-test-001/_doc/2
{
"kubernetes":
{
"labels":
{
"app-test":"test"
}
}
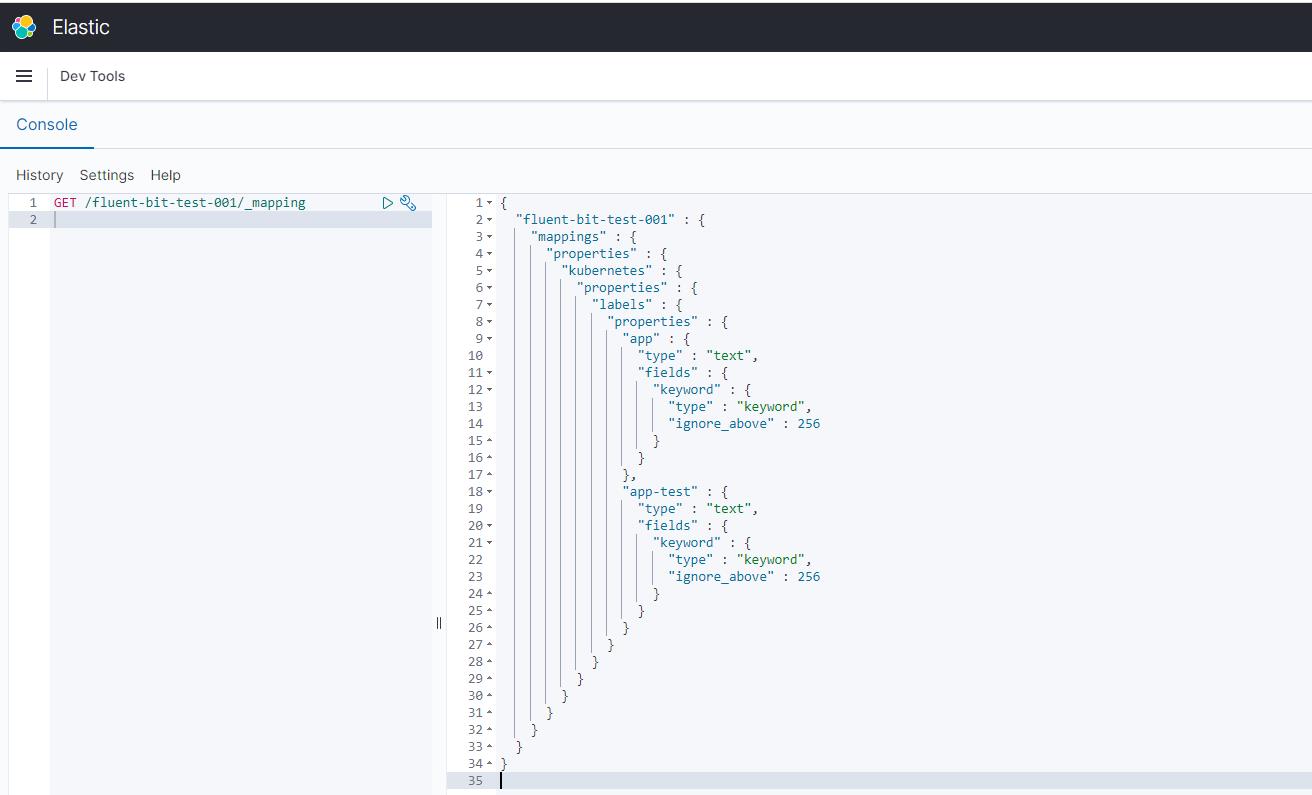
}此时该索引的mapping便随之更动如下:
{
"fluent-bit-test-001" : {
"mappings" : {
"properties" : {
"kubernetes" : {
"properties" : {
"labels" : {
"properties" : {
"app" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"app-test" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
}
}
}
}
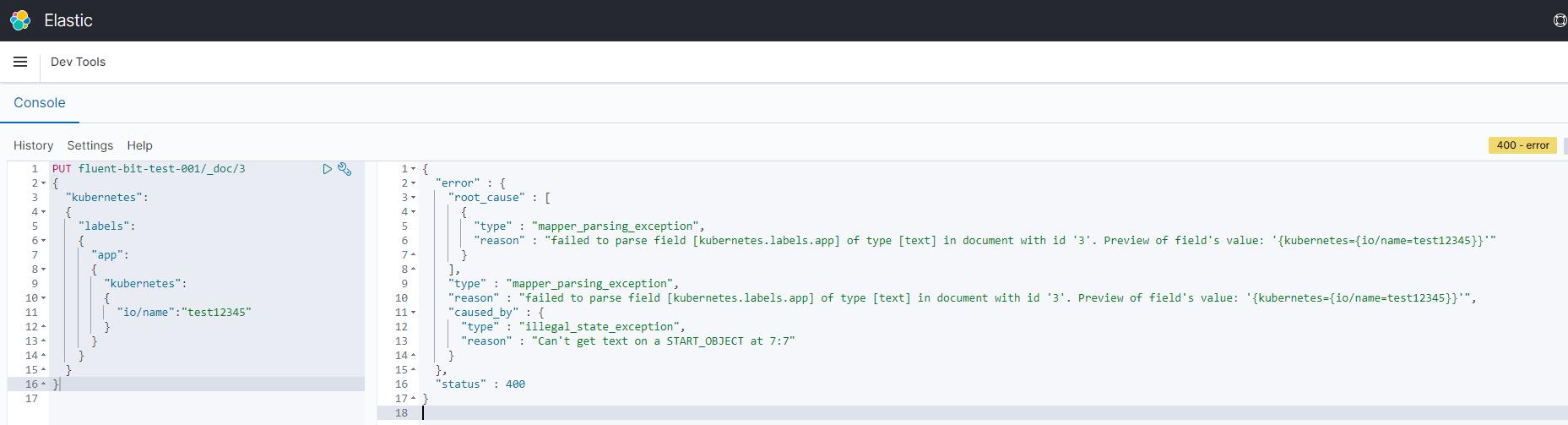
那么我们去重现一下上面的问题,写入如下数据
PUT fluent-bit-test-001/_doc/3
{
"kubernetes":
{
"labels":
{
"app":
{
"kubernetes":
{
"io/name":"test12345"
}
}
}
}
}便会出现http 400 mapper_parsing_exception error. 又“kubernetes.labels.app” 无法同时为text及object 型态。
解决办法
调整 prod labels 的 key 值的 naming 规则,举例来说,若 labels 的 Key 已经有 app 这样的 key 值了,就不要有后续 app.kubernetes.io/name 这样的 Key 值。
我看了一下,同时有这两个 label 的 Pod 基本就是 ebs,efs,我们去修改他们的 deployment,删掉这些 app 这个标签。
更改 ebs-csi-controller
kubectl delete deploy ebs-csi-controller -n kube-system
kubectl apply -f https://raw.githubusercontent.com/wangzan18/jenkins-agent-k8s-cicd/master/logging/ebs-csi-controller.yaml -n kube-systemebs-csi-node
kubectl delete daemonset ebs-csi-node -n kube-system
kubectl apply -f https://raw.githubusercontent.com/wangzan18/jenkins-agent-k8s-cicd/master/logging/ebs-csi-node.yaml -n kube-systemebs-snapshot-controller
kubectl delete statefulset ebs-snapshot-controller -n kube-system
kubectl apply -f https://raw.githubusercontent.com/wangzan18/jenkins-agent-k8s-cicd/master/logging/ebs-snapshot-controller.yaml -n kube-systemefs-csi-controller
kubectl delete deploy efs-csi-controller -n kube-system
kubectl apply -f https://raw.githubusercontent.com/wangzan18/jenkins-agent-k8s-cicd/master/logging/efs-csi-controller.yaml -n kube-systemefs-csi-node
kubectl delete daemonset efs-csi-node -n kube-system
kubectl apply -f https://raw.githubusercontent.com/wangzan18/jenkins-agent-k8s-cicd/master/logging/efs-csi-node.yaml -n kube-system然后查看命令,看看还有哪些 Pod 是带有 app 这个标签的。
kubectl get pod -n kube-system -l app --show-labels发现只有一个 cluster-autoscaler,我们修改最后一个 Pod。
cluster-autoscaler
kubectl -n kube-system edit deployment.apps/cluster-autoscaler
kubectl apply -f https://raw.githubusercontent.com/wangzan18/jenkins-agent-k8s-cicd/master/logging/cluster-autoscaler-autodiscover.yaml -n kube-system
kubectl -n kube-system \\
annotate deployment.apps/cluster-autoscaler \\
cluster-autoscaler.kubernetes.io/safe-to-evict="false"
deployment.apps/cluster-autoscaler annotated现在已经没有使用 app 标签的 Pod 了,我们下一步需要重建 ES 的 Index,我们适当的修改 fluent bit 的配置文件,在输出里面,添加一些参数,使得每天生成一个 Index,这样可以提升检索速度,记得把 yaml 下载下来,修改为自己的 ES 地址。
kubectl delete -f fluentbit.yaml
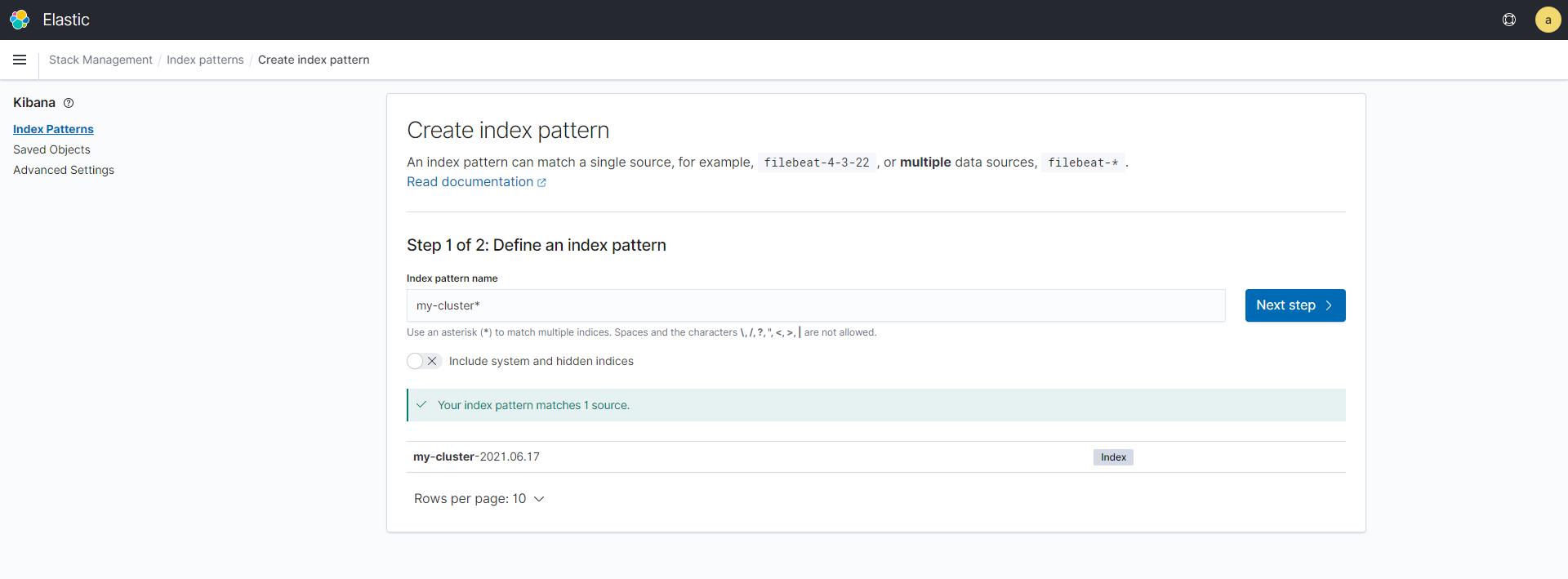
kubectl apply -f https://raw.githubusercontent.com/wangzan18/jenkins-agent-k8s-cicd/master/logging/fluent-bit.yaml重新添加 Index pattern
清理资源
cd ~/environment/
kubectl delete -f ~/environment/logging/fluentbit.yaml
aws es delete-elasticsearch-domain \\
--domain-name ${ES_DOMAIN_NAME}
eksctl delete iamserviceaccount \\
--name fluent-bit \\
--namespace logging \\
--cluster my-cluster \\
--wait
aws iam delete-policy \\
--policy-arn "arn:aws:iam::921283538843:policy/fluent-bit-policy"
kubectl delete namespace logging
rm -rf ~/environment/logging
unset ES_DOMAIN_NAME
unset ES_VERSION
unset ES_DOMAIN_USER
unset ES_DOMAIN_PASSWORD
unset FLUENTBIT_ROLE
unset ES_ENDPOINT
欢迎大家扫码关注,获取更多信息

以上是关于EKS 训练营-日志收集 EFK(14)的主要内容,如果未能解决你的问题,请参考以下文章