一个金蝶网址的网络爬虫
Posted 资质愚钝的我
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个金蝶网址的网络爬虫相关的知识,希望对你有一定的参考价值。
学习爬虫技术已经很久了,想着是时候写一些爬虫的心得了,首先,爬虫是什么呢?百度可得:网络爬虫是一种程序,主要用于搜索引擎,它将一个网站的所有内容与链接进行阅读,并建立相关的全文索引到数据库中,然后跳到另一个网站.样子好像一只大蜘蛛.简单来讲可以分为两个步骤:
1.获取资源
2.从资源中提取你要的东西
由于我常用的是requests+bs4,这两个模块的安装和使用可以百度下,这个很重要那接下来不多说,开始动手吧:
我们要爬取的是金蝶的一个新闻网站,http://www.kingdee.com/news/tag/%E4%BA%91%E4%B9%8B%E5%AE%B6/
打开长这个样子:
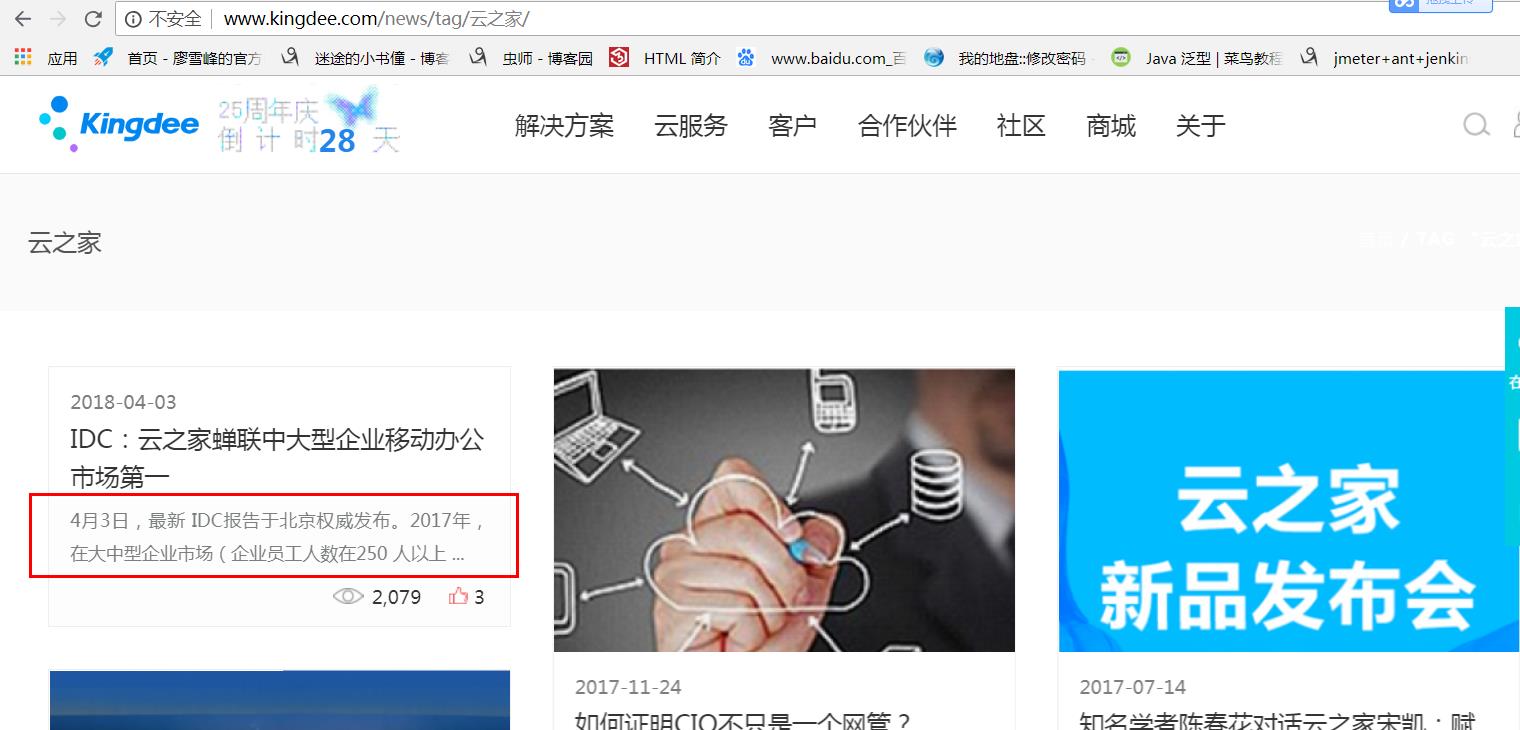
我们要爬取的就是新闻的红色方框部分(好像也不是标题,我也不知道这个叫什么,原谅我的无知),我们先来分析网页,我是chrome浏览器,按F12,在按F5,刷新网页,点击network,你会看到这个
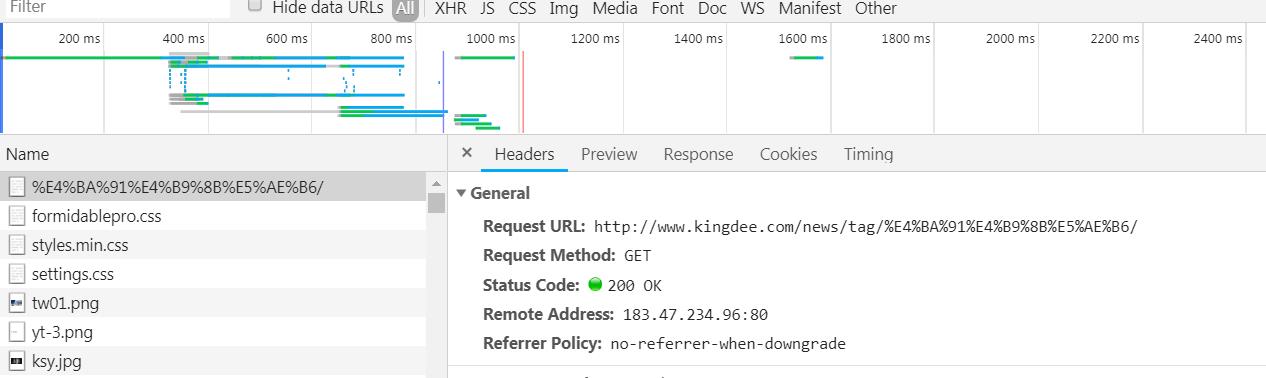
点击第一个请求,再点击response,就可以看到这个请求的响应,看看这个响应中有没有我们要的内容,怎么看?ctrl+F查找啊,我们会发现我们要的内容都在这个响应里,因此稍后我们要模拟这个请求来获取这些响应内容,再点击左上角的定位按钮,放到目标文本那里
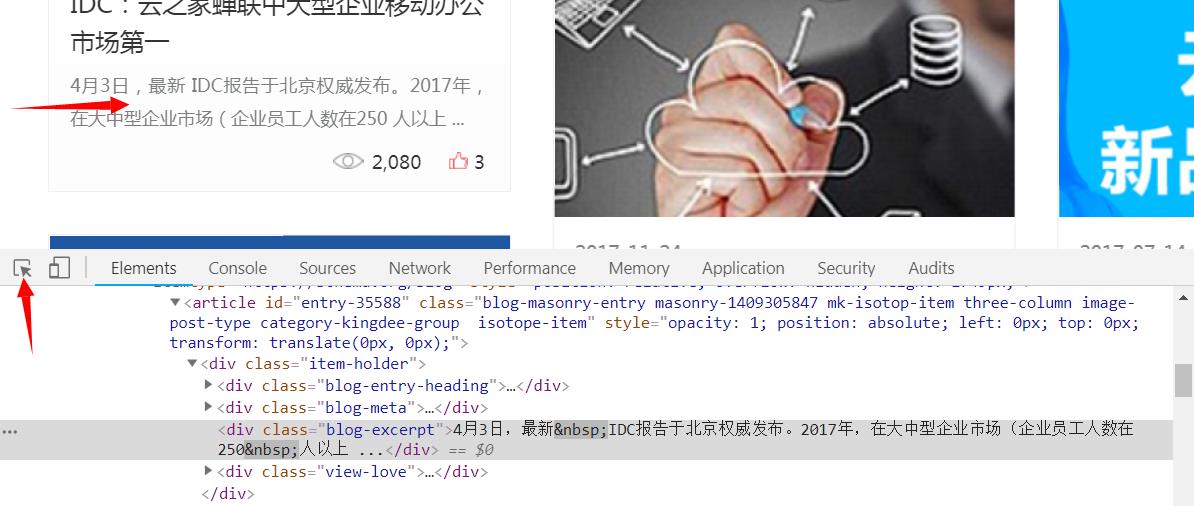
我们就可以看到目标文本在网页中位置了,通过分析网页我们会发现这样一个规则,
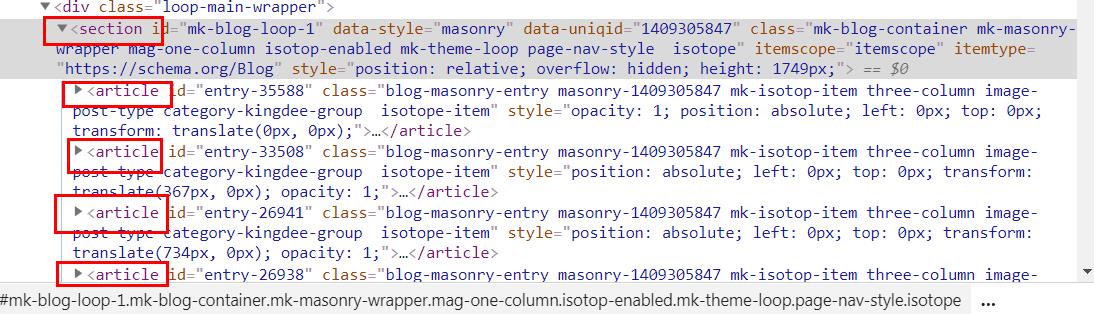
1.我们的目标文本在一个div中
2.每篇文章中都在一个artical中,每个artical中都包含我们要的div
3.一共有12篇文章,说明有12个artical块
4.所有的artical都在section块中
好的,分析完网页之后我们开始写代码:
import requests
from bs4 import BeautifulSoup
texts=[]
def get_text(url):#获取页面的目标文本
global texts
f = requests.get(url)
html = f.content.decode(\'utf-8\') #获取响应中的html代码
soup = BeautifulSoup(html, \'lxml\')
for i in soup.find_all(r\'section\', id=r\'mk-blog-loop-1\'):#获取tag名称为section,id属性为mk-blog-loop-1,返回一个列表,再遍历这个列表(实际只有一个元素)
for j in i.find_all(r\'article\'): ##获取tag名称为artical,返回一个列表,再遍历这个列表(实际有12元素)
texts.append(j.find_all(r\'div\', class_="blog-excerpt")[0].string) #找到tag名称为div,class属性为blog-excerpt,返回一个列表,因为只有一个元素,所有直接拿第一个就可以
get_text(http://www.kingdee.com/news/tag/%E4%BA%91%E4%B9%8B%E5%AE%B6/)
print(texts)
结果如下:

我们会发现上面的结果是正确的,但是红色方框中的内容不对,这是一个空格符,把它去掉就ok
a=[]
for i in texts:
a.append(\'\'.join(i.split()))
print(a)
好的,到目前为止,这个网络爬虫就可以了,比较简单,但是我们还是来总结下过程
1.利用浏览器开发工具F12来确定我们的目标文本在哪个请求里
2.分析我们的目标在网页中的结构
3.模拟浏览器的请求来获取响应内容
4.解析我们需要的内容
这个过程需要我们对bs4和requests等模块很熟悉,可以查看他们的文档,还有网页和Http请求的知识,总之用到的东西比较多,这是比较简单的爬虫,还有其他的类型和方法,以后有时间会和大家分享的!
以上是关于一个金蝶网址的网络爬虫的主要内容,如果未能解决你的问题,请参考以下文章