网页搜集系统
Posted 阿森森森
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网页搜集系统相关的知识,希望对你有一定的参考价值。
自1994年万维网出现后,互联网上的网页数量就呈指数级生长,到目前为止,短短二十余年,互联网上就有成百上千亿网页。如何在这海量的网页中搜索下载具有对特定场景有价值的网页?使用什么样的策略能保证网页不会出现重复?如何保证爬虫程序的高并发爬取?如何在网页中提取关键点等等问题,这是本篇博客重点描述的内容。
1.1 万维网结构分析
把万维网看作是一个相互连通的连通图,每个网页看作一个节点,链接看作为边,其中任意一个网页可被其它网页所链接,这种链接叫“反向链接”,这个网页也可以链接到其它网页,这种链接就叫“正向链接”。遍历网页的有两种方向,正向遍历和反向遍历,其中正向遍历是按正向链接的方向进行遍历网页,而反向遍历则是按反向链接的方向遍历网页。
研究者经实验发现,无论是正向遍历还是反向遍历,表现出来的是截然不同的效果。要么遍历到很少的一个网页集合,要么是爆炸性的遍历到上亿的网页,从实验结果中,研究者发现,万维网具有蝴蝶结型结构,如下图所示。
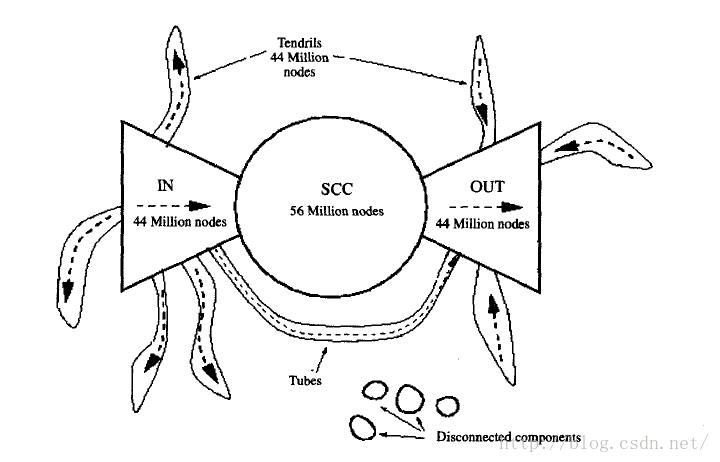
图 1-1万维网的蝴蝶结型结构[1]
此结构分为左中右三部分,其中左部的成为“目录型网页”,即常说的导航网页,从此部分出发开始采用正向遍历,可至少能遍历到全部网页的3/4,而采用反向遍历,则只能遍历到很少的一部分;中部的网页则是彼此连通的网页,此部分不管是采用正向还是反向,都大致可遍历到全部网页的3/4;右部的网页称为“权威网页”,这部分网页被中部网页所指向,这部分的网页“认可度”高,被大部分网页所引用,很明显,此部分网页的遍历与左部网页的遍历呈对称型;而“蝴蝶”的“须脚”部分,此部分的网页表现为从左部链接到其它网页,或者从左部或右部直接链接到右部,以及少部分与中部、左部或右部都没有链接,在此部分网页出发,不管采用正向遍历或是反向遍历都只能遍历到有限的很少一部分网页。
经过以上分析,我们可以得出,爬虫应尽可能从蝴蝶型的左部出发,或从中部的网页开始遍历。
1.2 网络爬虫
网络爬虫是网页搜集系统最重要的一部分之一,它是搜索引擎工作的基础。本节中将介绍网络爬虫的基础概念、分布式爬虫的架构、一些爬取网页的策略以及robots协议等。
1.2.1 爬虫概念
以上是关于网页搜集系统的主要内容,如果未能解决你的问题,请参考以下文章