网页搜集系统
Posted 阿森森森
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网页搜集系统相关的知识,希望对你有一定的参考价值。
自1994年万维网出现后,互联网上的网页数量就呈指数级生长,到目前为止,短短二十余年,互联网上就有成百上千亿网页。如何在这海量的网页中搜索下载具有对特定场景有价值的网页?使用什么样的策略能保证网页不会出现重复?如何保证爬虫程序的高并发爬取?如何在网页中提取关键点等等问题,这是本篇博客重点描述的内容。
1.1 万维网结构分析
把万维网看作是一个相互连通的连通图,每个网页看作一个节点,链接看作为边,其中任意一个网页可被其它网页所链接,这种链接叫“反向链接”,这个网页也可以链接到其它网页,这种链接就叫“正向链接”。遍历网页的有两种方向,正向遍历和反向遍历,其中正向遍历是按正向链接的方向进行遍历网页,而反向遍历则是按反向链接的方向遍历网页。
研究者经实验发现,无论是正向遍历还是反向遍历,表现出来的是截然不同的效果。要么遍历到很少的一个网页集合,要么是爆炸性的遍历到上亿的网页,从实验结果中,研究者发现,万维网具有蝴蝶结型结构,如下图所示。
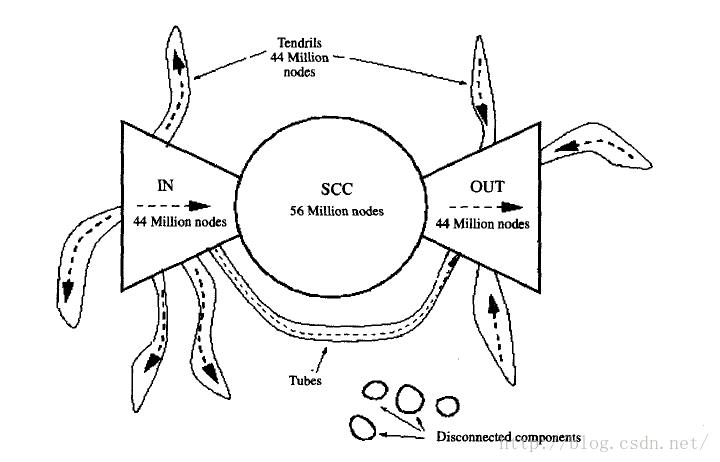
图 1-1万维网的蝴蝶结型结构[1]
此结构分为左中右三部分,其中左部的成为“目录型网页”,即常说的导航网页,从此部分出发开始采用正向遍历,可至少能遍历到全部网页的3/4,而采用反向遍历,则只能遍历到很少的一部分;中部的网页则是彼此连通的网页,此部分不管是采用正向还是反向,都大致可遍历到全部网页的3/4;右部的网页称为“权威网页”,这部分网页被中部网页所指向,这部分的网页“认可度”高,被大部分网页所引用,很明显,此部分网页的遍历与左部网页的遍历呈对称型;而“蝴蝶”的“须脚”部分,此部分的网页表现为从左部链接到其它网页,或者从左部或右部直接链接到右部,以及少部分与中部、左部或右部都没有链接,在此部分网页出发,不管采用正向遍历或是反向遍历都只能遍历到有限的很少一部分网页。
经过以上分析,我们可以得出,爬虫应尽可能从蝴蝶型的左部出发,或从中部的网页开始遍历。
1.2 网络爬虫
网络爬虫是网页搜集系统最重要的一部分之一,它是搜索引擎工作的基础。本节中将介绍网络爬虫的基础概念、分布式爬虫的架构、一些爬取网页的策略以及robots协议等。
1.2.1 爬虫概念
爬虫,它通过下载一个网页,分析其中的链接,继而去访问其它链接指向的网页,周而复始进行,直到磁盘满或人工干预,爬虫的功能归结为两点:下载网页和发现URL。
爬虫访问网页和浏览器有着相同的方式,同样也都是都是使用HTTP协议和网页服务器交互。流程主要如下[2]:
1. 客户端程序(爬虫程序)连接到一个DNS服务器上。DNS服务器将主机名转换呈IP地址,因为爬虫程序会频繁的查询DNS服务器,所以可能会造成类似于拒绝服务攻击(DOS)的副作用,所以在很多爬虫程序实现中都会增加DNS缓存,以减少很多不必要的DNS服务器查询,在商业搜索引擎中,一般都会搭建自己的DNS服务器。
2. 建立连接后,客户端会发送一个HTTP请求给网络服务器,以请求一个页面。常见的HTTP请求是GET请求,如:
GET http://www.sina.com.cn/index.htmlHTTP/1.1
该命令表示请求服务器使用HTTP 1.1协议规范1.1版本,将页面www.sina.com.cn/index.html页面返回给客户端。当然客户端也可使用POST命令访问网络服务器。同样,爬虫程序也会频繁的使用GET命令,而使用该命令后会将页面所有内容返回给客户端,在网页重访(因为很多网页会更新,所以需重访网页以得到最新的网页内容)时,尝试用HEAD命令访问服务器,该命令则是要求将网页的head部分返回给客户端,该head部分包含了网页的最后更新时间(Last-Modified)字段,在比对数据库中该网页的此字段后,就可避免大量未更新网页的下载。
3. 分析网页中的URL链接,将它们插入一个队列中,同时提取网页中的重要内容存储到数据库中。队列的主要特点是FIFO,每次将新发现的URL插到队列尾部,然后取得从队列头部取得下一待访问URL,这样循环反复进行,直到队列为空,这便是常说的宽度优先遍历。经过以上三个步骤便实现了一个简单的网络爬虫。但其中还有很多问题,例如:
1) 如何避免访问重复URL(访问重复URL将会导致无限循环);
2) 爬虫需遵循的Robots协议等;
3) 如何避免因频繁的访问导致网络服务器“发怒”;
4) 如何设计本课题中电子产品页面采集策略;
5) 分类器;
6) 网页格式的转换问题;
7) 如何设计网页的存储结构以及选择什么样的数据库存储海量网页页面;
8) 因为网页也会因为过期,如何设计重访网页策略;
9) 如何高效率地爬取网页(将在1.3节中讲解);
URL重复避免
避免URL重访是一个很关键的问题,如果URL重复访问,必然会导致一个无限的递归访问,直至资源穷尽。一般的策略是维护两个表:visited_table和unvisited_table,visited_table表示已访问URL的表,而unvisited_table相当于一个“任务池”,爬虫不断地从unvisited_table中取得待访问URL,这样就避免了网页的重复访问。工作步骤如下:
1. 为爬虫线程添加一个control进程,此进程主要功能是控制爬虫爬取网页,维护两个URL表等,相当于一个控制器。
2. 爬虫每次爬取网页时,从unvisited_table中取得URL,下载网页后,对网页进行一系列处理插入到数据库中,同时分析网页中的链接,将链接递交到control进程。
3. control进程在得到爬虫URL链接后,比对visited_table,看其中是否存在,若不存在,则将该URL插入到unvisited_table中,同时会返回一个URL给爬虫,爬虫继续爬取该URL。
visited_table可使用一个hash函数,则visited_table是一个bit数组。因为hash函数面临着冲突问题,所以如果有更高的精确要求,可改用Bloom Filter,Bloom Filter的原理很简单,它使用多个不同hash函数来判定,例如,初始化bit数组所有位为0,对于一个URL1,使用多个不同的hash函数计算后,将bit数组相应位置1,当判断URL2是否已访问时,对URL2同样使用hash函数计算,如果计算后,相应的bit数组为0,则表示该URL未访问,否则,若bit数组中其中任何一位为1,则表示该URL已访问, 具体的证明可参考参考文献。

图1-2 Bloom Filter工作原理示例图
正如图1-2所示,对URL2使用Bloom Filter时,有一个bit位已置1,故表示该URL已访问过。
避免网络服务器“发怒”
为何网络服务器会“发怒”?网络服务器承受不住爬虫的频繁快速的访问,如果该网络服务器性能不是很强大,它将花费所有时间处理网络爬虫的请求,而不会去处理真实用户的请求,于是它可能将该爬虫看作是DOS攻击,从而禁止爬虫的IP,所以应该避免网络服务器的“发怒”,如何处理呢?通常是在爬虫访问该服务器后,爬虫应该等待几秒,从而给网络服务器足够的时间去处理其它请求,同时爬虫也应该遵守robots协议。
robots协议
robots协议是Web站点和搜索引擎爬虫交互的一种方式,网络管理员将一个robots.txt的文件放在网站的根目录上,例如https://www.google.com/robots.txt.
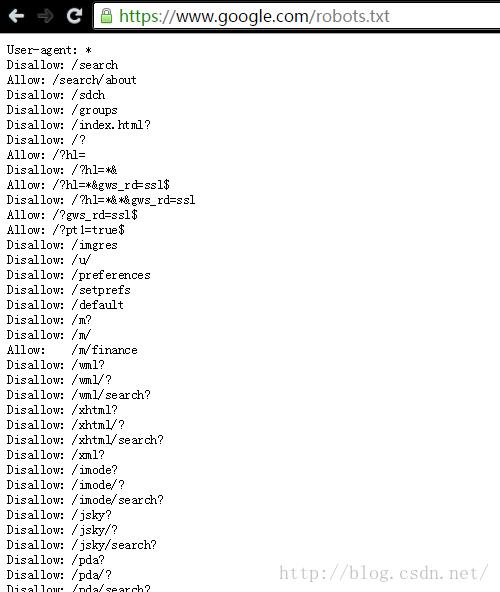
其中User-agent表示爬虫类型(如上图中的*表示所有爬虫),Disallow表示禁止该爬虫爬取的目录,Allow表示允许爬取的页面或目录,所以在具体实现搜索引擎时,还应该增加一个robots协议分析模块,严格遵守robots协议的规定只抓取Web主机允许访问的目录和网页。
页面采集策略
针对垂直搜索策略有以下两种:
1. 对整个互联网页面搜集下载,然后去除不相关页面。此种方法的缺点是将会占用大量的磁盘空间和带宽,在具体实现中不可取。
2. 第二种方式是基于这样一个事实:一个话题页面往往存在相关主题页面。其中锚文本的作用至关重要,它指示了相关链接的主题,所以在实际应用中,一个特定话题的多个权威页面都被用作种子页面。
文本分类技术。爬虫使用分类器来确定该页面是否与给定的主题相关。常用朴素贝叶斯分类器或支持向量机等。下面将简要讲解这两种分类器。
分类器
1. 朴素贝叶斯分类器
2. 支持向量机
网页格式转换
计算机中文本是以几百种相互之间不兼容的格式进行存储的。标准的文本格式包括原始文本、HTML、XML、Word以及PDF等等,如果不以正确的方式去处理,往往会出现乱码的情况,所以需要一个工具,在处理到一个新文本格式时,能将它转换成通用的格式,在本课题中,则将它转换到HTML格式即可。计算机存储文件时,还有个问题是编码问题,此问题的通用解决方案是查看网页头部的编码格式,然后以相应的编码格式读取分析。
所以,当下载到一篇网页后,首先查看头部信息:查看文本格式和编码格式,然后以相应的方法去处理即可。
网页存储问题
网页的存储面临两个问题:以什么样的格式存储网页?使用什么样的数据库?
1. 首先处理存储网页的格式问题。如果将下载后的网页直接存储到数据库,则有两个问题:
1) 每个网页平均约有70K,在磁盘上传输70K的数据会很快,可能只需要不到1毫秒的时间,但在查找时,却可能需要10毫秒,所以在打开这些零散小文件来读取文档时,需大量的时间开销,一种好的解决方案是将多个文档存储在一个单独的文件中,以一种自自定义的格式进行存储,例如:
<DOC>
<DOCNO>102933432<DOCNO>
<DOCHEADER>
http://www.sina.com.cn/index.htmltext/html 440
http/1.1200 ok
IP:221.236.31.210
Date:Wed, 02 Jan 2016 09:32:23 GMT
Content-Encoding: gzip
Last-Modified: Tue, 03 Jan 2016 01:52:09GMT
Server: nginx
Content-Length: 119201
</DOCHEADER>
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-type" content="text/html;charset=utf-8" />
<meta http-equiv="X-UA-Compatible"content="IE=edge" />
<title>新浪首页</title>
……
</html>
</DOC>
<DOC>
<DOCNO>102933433<DOCNO>
<DOCHEADER>
……
</DOCHEADER>
……
</DOC>例子中:
<DOC></DOC>标记了一篇网页的内容,其中包括了<DOCNO>、<DOCHEADER>和网页原始内容;<DOCNO></DOCNO>标记网页的编号;,<DOCHEADER></DOCHEADER>标记了网页的头部信息,此部分大多数由网络服务器返回;剩余部分为网页内容。
2) 如果数据量过大,常常会将存储的文件进行压缩以节省磁盘空间。
2. 第二个问题是存储系统的选择。存储系统可以选择关系数据库和NoSQL数据库,在主要的搜索引擎中,很少使用传统的关系数据库来存储文档,因为大量的文档数据将会压垮关系数据库系统,非关系数据库的强大分布式能力,海量数据存储能力,故障恢复能力等等促使搜索引擎中偏向于使用非关系数据库。在本课题中可以选择MongoDB或BigTable等数据库系统,它们同样也有类似于mysql强大的社区支持,开源免费等特点。
页面重访机制
因为很多网页会更新,所以需重访网页以得到最新的网页内容,来保持网页库中内容的“与时俱进”,而不同的网站更新频率也不同,这就要对网页变化进行分析建模。
研究表明,网页的变化可以归结为泊松过程模型,具体可见参考文献。
常见的重访策略有两种:
1)统一的重访策略:爬虫以同样的频率重访已经抓取的全部网页,以获得统一的更新机会,所有的网页不加区别地按照同样的频率被爬虫重访。
2)个体的重访策略:不同网页的改变频率不同,爬虫根据其更新频率来决定重访个体页面的频率。即对每一个页面都量身定做一个爬虫重访频率,并且网页的变化频率与重访频率的比率对任何个体网页来说都是相等的。
当然两种方式各有利弊,针对与本课题中电子产品的搜索,由于网页更新频率较慢,且各网页更新频率类似,所以可采用策略1.
1.3 分布式网络爬虫
前面所讲的内容大多基于单机节点之上,然而单机系统难以满足互联网上海量网页的搜索,这促使我们选择分布式构建网页搜集系统,因为网页的搜集任务基本上可看作是相互独立的任务,使用分布式系统,能大大加快网页的搜集能力。本节将主要讲解基于分布式网络爬虫的大体架构以及设计中出现的主要问题。
在图1-1中可看到,搜集器中对应了一个控制器,在分布式搜集系统中,将会出现多个搜集器控制器对,然后再有一个总控制器,如下图所示:
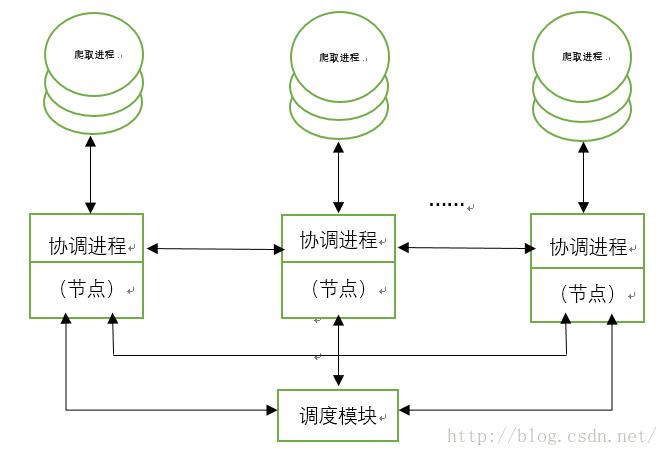
图1-4分布式Web搜集系统
如图1-4即为网页搜集系统的总体分布式结构,图1-4介绍如下:
1.3.1 抓取进程
抓取进程的工作示意图如下:
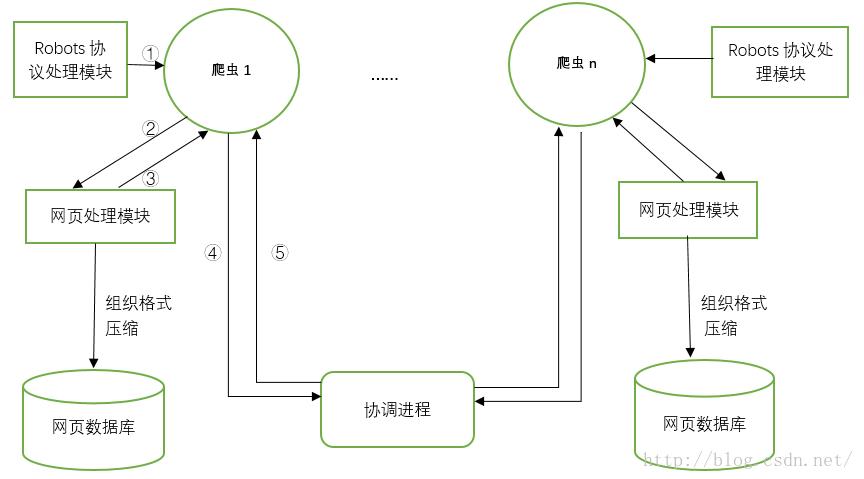
图1-5 爬取进程示意流程图
注:一个爬取进程内会有多个爬取线程。
图1-5解释如下:
a. 首先爬取线程爬取URL时,先由Robots协议模块判断是否在网页服务器允许爬取的URL内,若是,则转到b,否则转到c;
b. 爬取线程将爬取到的网页递交给网页处理模块,网页处理模块会分析网页内的链接,并将网页内容组织成一定格式(3.2.1节)等,将组织后的内容压缩后插入到网页数据库中,并向爬取线程返回网页内的的所有链接内容;
c. 爬取线程将网页处理模块的所有链接(若未爬取,则为空)和当前URL递交到协调进程;
d. 协调进程向该爬取线程返回下一待爬取URL,回到a。步骤b中,组织网页即为将多个网页组织在一块,正如1.2.1节所述,然后将组织后的内容压缩处理后插入到数据库中。
1.3.2 协调进程
协调进程的设计是关键,其中涉及到为爬取进程分配URL,处理非本区域URL,管理爬虫线程等等工作。
协调进程从0开始编号,直到n-1,其中n为爬虫主机数,各个协调进程管理自己所属的URL,即为以下策略:
设URLs = URL1,URL2, …, URLn,即URLs为所有URL的集合,定义HOST(URL)为一个网页地址的域名部分,通常对应某台Web服务器,例如:URL = http://www.scie.uestc.edu.cn/main.php?action=viewTeacher,则HOST(URL)= http://www.scie.uestc.edu.cn,所采取的策略是建立一个HOST(URL)到[n]之间的映射,一旦一个HOST(URL)映射到了某一搜集节点,该节点就要负责HOST(URL)下面所有页面的收集。映射函数可采用散列函数。每个协调进程同时维护还要维护两张表,正如3.2.1节所述,visited_table和unvisited_table,协调进程工作的具体伪码流程如下[2]:
for(;;)
begin
a. 等待从其它节点传来的一个URL,或者它所管辖的抓取进程返回一个URL及相关links。
b. 若得到其它节点传来的一个URL
b.1 看URL是否已经出现在visited_table中,若没有,则将URL放到unvisited_table中;
c. 若得到从抓取进程返回的URL,取得超链接links;
c.1 从unvisited_table中分给给该抓取进程一个新的URL,并将返回的URL放到visited_table中;
c.2 并对每个超链接符号串HOST(link)进行模n散列,得到某个整数I;
c.3 对每一个超链接link及其对应整数i:
c. 3.1 如果本节点编号为i,执行b.1的动作
c. 3.2 否则,将link发给节点i
end上述伪代码即为协调进程工作算法,详细解释如下:
步骤a中协调进程中,只会处理属于本节点区域的URL,所以它会等待两个事件:其它节点传来属于本节点的URL和本节点上爬取进程传来的爬取的URL及相关links:
当此事件是其它节点传来URL,则首先需要验证该URL是否已经访问过(使用hash函数在visited_table中比较,正如1.2.1节所述),若未访问过,则插入到unvisited_table中供爬取进程爬取;
当此事件是本节点的爬取进程爬取的URL和相关links时(其中的相关links即为网页处理模块已分析出的网页内容中的链接),则协调进程会给该爬取进程分配下一待爬取URL。然后协调进程会分析相关links,对链接中的URL作散列操作,若散列的结果为本协调进程的编号时,则执行b.1操作,即判断该URL是否已经访问,若已访问,则丢弃,否则,则插入到unvisited_table中;当散列的结果不是本协调进程时,则发送给相应的协调进程。
1.3.3 调度模块
调度模块的工作就是维护系统内所有登记进程的信息,包括它们的IP地址和端口号,当任何一个协调进程的信息有所变化时,该模块负责将更新的信息转送给其它协调进程。
调度模块是网页搜集系统可扩展性的关键,它会为各协调进程分配URL,正如上一节中所述。系统扩展性体现在于:当其中一个协调进程模块因某种原因而崩掉时,调度模块会将该协调进程的信息分配到其它协调进程模块。
1.4 小结
本章内容主要讲解了电子产品网页搜集系统的组成、关键问题和设计细节。最开始引出一个网络爬虫的概念,然后叙述网络爬虫需要考虑的一系列问题,例如避免URL重复、格式转换、存储等等,因为单机系统难以适应海量网页的抓取,接着文章讲解了分布式网页搜集系统的系统架构结束了本章的内容,当然,实际设计系统时,还会在这些内容上根据实际情况进行取舍。
参考文献
[1] 潘雪峰, 花贵春, 梁斌. 走进搜索引擎.2011.5. 电子工业出版社.[2] W.BruceCroft, Donald Metzler, Trevor Strohman等. 2010.2. 搜索引擎: 信息检索实践. 北京:机械工业出版社.
[3] 李晓明, 闫宏飞, 王继民等. 2012. 搜索引擎: 原理, 技术与系统. 北京:科学出版社.
[4] https://en.wikipedia.org/wiki/Web_search_engine.
[5] https://en.wikipedia.org/wiki/Hash_function.
[6] https://en.wikipedia.org/wiki/Bloom_filter.
[7] Bloom,Burton H. (1970), "Space/Time Trade-offs in Hash Coding with AllowableErrors", Communications of the ACM 13 (7):422–426, doi:10.1145/362686.362692
[8] https://en.wikipedia.org/wiki/Naive_Bayes_classifier.
[9] https://en.wikipedia.org/wiki/Support_vector_machine.
[10] CHO, J. AND GARCIA-MOLINA, H.2000a, Estimating frequency of change. ACM Transactions on Internet Technology,Vo1.3, No.3, 2003.8.
[11] https://en.wikipedia.org/wiki/NoSQL
[12] https://en.wikipedia.org/wiki/Rabin_fingerprint
以上是关于网页搜集系统的主要内容,如果未能解决你的问题,请参考以下文章