机器学习-kNN-寻找最好的超参数
Posted taoke2016
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习-kNN-寻找最好的超参数相关的知识,希望对你有一定的参考价值。
一 、超参数和模型参数
- 超参数:在算法运行前需要决定的参数
- 模型参数:算法运行过程中学习的参数
- kNN算法没有模型参数
- kNN算法中的k是典型的超参数
寻找好的超参数
- 领域知识
- 经验数值
- 实验搜索
二、通过sklearn中的数据集进行测试
import numpy as np from sklearn import datasets # 装载sklearn中的手写数字数据集 digits = datasets.load_digits() x = digits.data y = digits.target from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier # 将数据分成训练数据集合测试数据集, # 测试数据集占全部数据的20%, # 设置随机种子为666 x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state = 666) # 设置k为3 knn_clf = KNeighborsClassifier(n_neighbors=3) # 训练数据模型 knn_clf.fit(x_train,y_train) # 通过测试数据计算预测结果准确率,并打印出来 print(knn_clf.score(x_test,y_test))
输出结果:0.9888888888888889
三、考虑距离?不考虑距离?
kNN存在一种平票的情况,就是距离最近的k个点中相应类的数量相等,这是需要考虑距离了。
import numpy as np from sklearn import datasets digits = datasets.load_digits() x = digits.data y = digits.target from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state = 666) best_method = ‘‘ best_score = 0.0 best_k = -1 for method in [‘uniform‘,‘distance‘]: for k in range(1,11): knn_clf = KNeighborsClassifier(n_neighbors=k,weights=method) knn_clf.fit(x_train,y_train) score = knn_clf.score(x_test,y_test) if score > best_score: best_method = method best_score = score best_k = k print(‘best_method = %s‘%best_method) print(‘best_k = %d‘%best_k) print(‘best_score = %f‘%best_score)
运行结果:
best_method = uniform
best_k = 4
best_score = 0.991667
四、搜索 明可夫斯基距离 相应的p
欧拉距离,曼哈顿距离,明可夫斯基距离
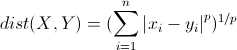
由上可以获取一个超参数p。
%%time import numpy as np from sklearn import datasets digits = datasets.load_digits() x = digits.data y = digits.target from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state = 666) best_p = ‘‘ best_score = 0.0 best_k = -1 # for method in [‘uniform‘,‘distance‘]: for k in range(1,11): for p in range(1,6): knn_clf = KNeighborsClassifier(n_neighbors=k,weights="distance",p=p) knn_clf.fit(x_train,y_train) score = knn_clf.score(x_test,y_test) if score > best_score: best_p = p best_score = score best_k = k print(‘best_p = %s‘%best_p) print(‘best_k = %d‘%best_k) print(‘best_score = %f‘%best_score)
运行结果:
best_p = 2
best_k = 3
best_score = 0.988889
Wall time: 47.5 s
四、网格搜索kNN最好的参数
sklearn中通过网格搜索可以更快更全面的搜索更好的参数。
import numpy as np from sklearn import datasets digits = datasets.load_digits() x = digits.data y = digits.target from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state = 666) knn_clf = KNeighborsClassifier(n_neighbors=4,weights=‘uniform‘) knn_clf.fit(x_train,y_train) knn_clf.score(x_test,y_test) param_grid = [ { ‘weights‘:[‘uniform‘], ‘n_neighbors‘:[i for i in range(1,11)] }, { ‘weights‘:[‘distance‘], ‘n_neighbors‘:[i for i in range(1,11)], ‘p‘:[i for i in range(1,6)] } ] knn_clf = KNeighborsClassifier() from sklearn.model_selection import GridSearchCV grid_search = GridSearchCV(knn_clf,param_grid) # 需要运行2-5分钟,保持耐心 grid_search.fit(x_train,y_train)
grid_search.best_estimator_ # 最佳的参数对象 grid_search.best_score_ # 准确率 grid_search.best_params_ # 最佳的参数 #为计算机分配资源,输出搜索信息,n_jobs:分配计算机核数,-1位有多少用多少,verbose:为打印信息的等级,值越大,信息越多 grid_search = GridSearchCV(knn_clf,param_grid,n_jobs=-1,verbose=10) grid_search.fit(x_train,y_train)
五、更多的距离定义
- 向量空间余弦相似度 Cosine Similarity
- 调整余弦相似度 Adjusted Cosine Similarity
- 皮尔森相关系数 Pearson Correlation Coefficient
- Jaccard相似系数 Jaccard Coefficient
以上是关于机器学习-kNN-寻找最好的超参数的主要内容,如果未能解决你的问题,请参考以下文章