天马行空云计算-Hardware&Hypervisor介绍
Posted angie_hawk7
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了天马行空云计算-Hardware&Hypervisor介绍相关的知识,希望对你有一定的参考价值。
天马行空云计算系列一介绍了总体抽象视图,本篇展开Hardware&Hypervisor 介绍。如下是介绍大纲:
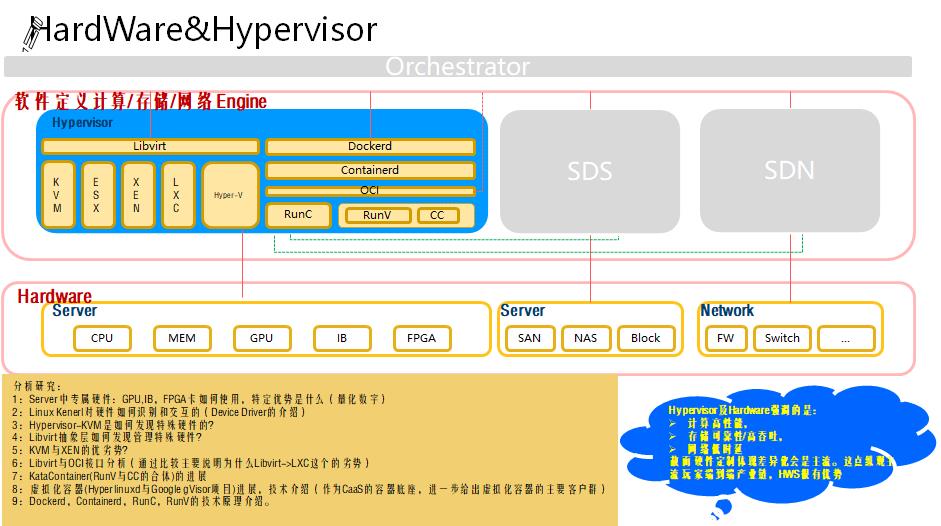
本篇将基于上述架构从如下方面介绍说明
Linux设备驱动
因为上述提到的一些硬件资源如GPU等,所以先介绍下操作系统是如何管理硬件的。
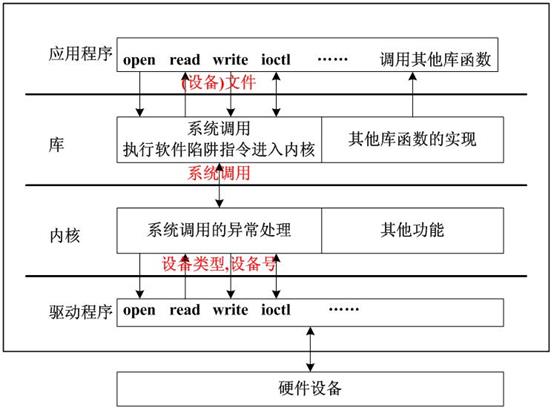
操作系统是个中军统帅,允许各种硬件往上集成,那么自然的其需要可以发号军令的权利。所以Linux内核为了管理各种硬件设备,制定了一套软件体系(驱动模型)。各种硬件基于驱动模型提供驱动程序,以被调遣使用。实际就是操作系统指定了一套接口,各硬件去实现这套接口即可。(面向对象的多态)。然而硬件厂商发现这个接口的实现实在过于复杂,成本很高,所以操作系统就提供了一套模型驱动的东东,内核抽象了模型如字符,块,网络 设备等概念,然后将设备的电源管理,热插拔,生命周期等基于这套统一模型实现了,然后对硬件说,好了,你基于这套模型实现你的接口吧。相当于面向对象语言中操作系统内核提供了几个父抽象类,各硬件驱动就是继承类。 设备驱动模型的目的是简化驱动开发。
故而什么是驱动?可以理解为操作系统内核为了使能硬件设备所指定的一套软件标准,而硬件厂商遵守这套标准实现具体的东东。
GPU
GPU详见百科。几个关键信息:
- 显卡的心脏:GPU
- 专为执行复杂的数学和几何计算而设计。
- GPU将CPU从图形处理任务解放出来,使得CPU聚焦执行系统任务,提升计算机整体性能。
- GPU散热大,需要安装散热器或风扇等

GPU 与 CPU 性能比较
理解 GPU 和 CPU 之间区别的一种简单方式是比较它们如何处理任务。CPU 由专为顺序串行处理而优化的几个核心组成,而 GPU 则拥有一个由数以千计的更小、更高效的核心(专为同时处理多重任务而设计)组成的大规模并行计算架构。
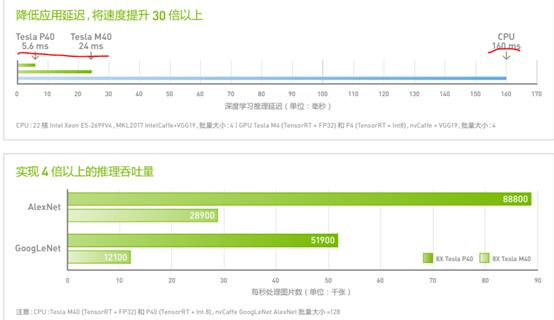
如下为Navida的Tesla 系列的性能测试数据,可对比CPU的性能:
每个 GPU 可带来 47 TOPS(万亿次运算/秒)的推理性能和 INT8 运算能力,使得一台配备 8 个 Tesla P40 的 服务器可提供相当于超过 140 台 CPU 服务器的性能。 随着模型的准确性和复杂性越来越高,CPU 已经无法再提供互动用户体验。Tesla P40 可在 极其复杂的模型中实现实时响应,能够降低延迟,将性能提升为 CPU 的 30 倍以上。
研发制造商
|
Intel |
英特尔的GPU基本为集成显卡芯片,用于英特尔的主板和英特尔的CPU |
唯一的独显芯片:Intel 740,其它均为集成到CPU或者芯片组 |
|
NAVIDA |
最大的独显芯片生产销售商 |
移动设备:Tegra 超级计算:Tesla Quadro |
|
AMD |
世界第二大独立显卡芯片生产销售商 |
FirePro系列 |
|
Matrox |
|
与Navida,AMD主打3D领域,Matrox当前是聚焦于工程专用领域的2D:CAD方面显卡芯片。 |
关于GPU的使用场景与优势详见:https://www.nvidia.cn/page/home.html
Linux相关配置使用
1:GPU生产厂商提供了对应的Linux驱动以及相关的管理库,例如Navida。可以通过nvida-smi指令来监视GPU的信息
2:查看服务器的设备硬件的标准指令:lspci 。例如lspci | grep -i vga 查看是否存在GPU。
特定厂商的硬件设备,需要从其官网下载操作系统的驱动程序,这样操作系统这个大介质才能使能GPU硬件。
GPU虚拟化
http://www.cnblogs.com/sammyliu/p/5179414.html 这篇文章讲解的真是透彻,本人就不搬砖了。
总结下几点:
- 远端API方法:性能损耗严重
- GPU设备仿真:需要在Guest客户机中提供仿真程序,转发到Hypervisor上物理GPU调用
- PaaS-through透传:一对一,一对多(中介):透传技术能带来几乎和物理设备同等的性能,但是它也带来了一些局限性。设备透传带来的一个问题体现在实时迁移方面。实时迁移 是指一个 VM 在迁移到一个新的物理主机期间暂停迁移,然后又继续迁移,该 VM 在这个时间点上重新启动
- 全虚拟化,每个虚拟机拥有一个虚拟的GPU实例,多个虚拟机共享一个物理GPU。
上述博文作者写作时间较早,截止当前补充下GPU在KVM虚拟化场景下的支持进展
Linux4.10内核中对VFIO添加了Mediated Device(vfio-mdev) Interface,用来支持Intel GVT-g, NVIDIA vGPU,并提供统一的框架。具体作用为通过软件调度的方式在Host与Guest之间提供一个中间的mediated device来允许Guest虚拟机访问Host中的物理GPU。

VFIO:VFIO是一套用户态驱动框架,可用于编写高效用户态驱动;在虚拟化情景下,亦可用来在用户态实现device passthrough。通过VFIO访问硬件并无新意,VFIO可贵之处在于第一次向用户态开放了IOMMU接口,能完全在用户态配置IOMMU,将DMA地址空间映射进而限制在进程虚拟地址空间之内。这对高性能用户态驱动以及在用户态实现device passthrough意义重大
- 向用户态提供访问硬件设备的接口。
- 向用户态提供配置IOMMU的接口
VFIO由平台无关的接口层与平台相关的实现层组成。接口层将服务抽象为IOCTL命令,规化操作流程,定义通用数据结构,与用户态交互。实现层完成承诺的服务。据此,可在用户态实现支持DMA操作的高性能驱动。在虚拟化场景中,亦可借此完全在用户态实现device passthrough。
而AMD也与今年发布了KVM MxGPU虚拟化方案。
关于KVM支持GPU虚拟化的详细介绍:

Libvirt-GPU虚拟化使用。
由上文可知,KVM虚拟化是已经支持了vGPU,根据本篇开始的引导架构图,上层使用时通过libvirt抽象层的(事实上Hypervisor的标准化接口)。那么libvirt是否支持和如何使用呢?
Libvirt支持和使用详见:
https://www.redhat.com/archives/libvir-list/2016-August/msg00939.html
- 发现设备。GPU设备在初始化的时候,其驱动会注册到media框架。mdev_supported_types类型的系统文件才会可用。Libvirt会查询此文件。
2. 创建和销毁设备
3. 启动和停止设备
4. 启动QEMU/VM
5. -device vfio-pci,sysfsdev=/sys/bus/mdev/devices/$mdev_UUID,id=vgpu0
6. Shutdown sequence
7. VM Reset
8. 热插拔
以上是关于天马行空云计算-Hardware&Hypervisor介绍的主要内容,如果未能解决你的问题,请参考以下文章
胡立军:从Gartner“Hype Cycle”看 RPA发展走向
禁止光盘优盘自动播放(Shell Hardware Detection服务)